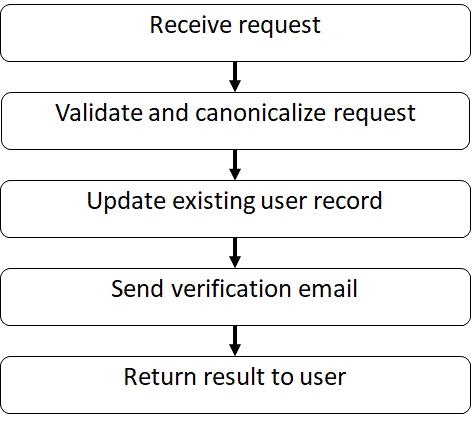
Как пользователь я хочу изменить ФИО и email в системе.
Для реализации этой простой пользовательской истории мы должны получить запрос, провести валидацию, обновить существующую запись в БД, отправить подтверждение на email пользователю и вернуть ответ браузеру. Код будет выглядеть примерно одинаково на C#:
string ExecuteUseCase() { var request = receiveRequest(); validateRequest(request); canonicalizeEmail(request); db.updateDbFromRequest(request); smtpServer.sendEmail(request.Email); return "Success"; }
и F#:
let executeUseCase = receiveRequest >> validateRequest >> canonicalizeEmail >> updateDbFromRequest >> sendEmail >> returnMessage
Отклоняясь от счастливого пути

Дополним историю:
Как пользователь я хочу изменить ФИО и email в системе
И увидеть сообщение об ошибке, если что-то пойдет не так.
Что же может пойти не так?

- ФИО может оказаться пустым, а email – не корректным
- пользователь с таким id может быть не найден в БД
- во время отправки письма с подтверждением SMTP-сервер может не ответить
- ...
Добавим код обработки ошибок
string ExecuteUseCase() { var request = receiveRequest(); var isValidated = validateRequest(request); if (!isValidated) { return "Request is not valid" } canonicalizeEmail(request); try { var result = db.updateDbFromRequest(request); if (!result) { return "Customer record not found" } } catch { return "DB error: Customer record not updated" } if (!smtpServer.sendEmail(request.Email)) { log.Error "Customer email not sent" } return "OK"; }
Вдруг вместо 6 мы получили 18 строк кода с ветвлениями и большей вложенностью, что сильно ухудшило читаемость. Каким будет функциональный эквивалент этого кода? Он выглядит абсолютно также, но теперь в нем есть обработка ошибок. Можете мне не верить, но, когда мы доберемся до конца, вы убедитесь, что это действительно так.
Архитектура запрос-ответ в императивном стиле
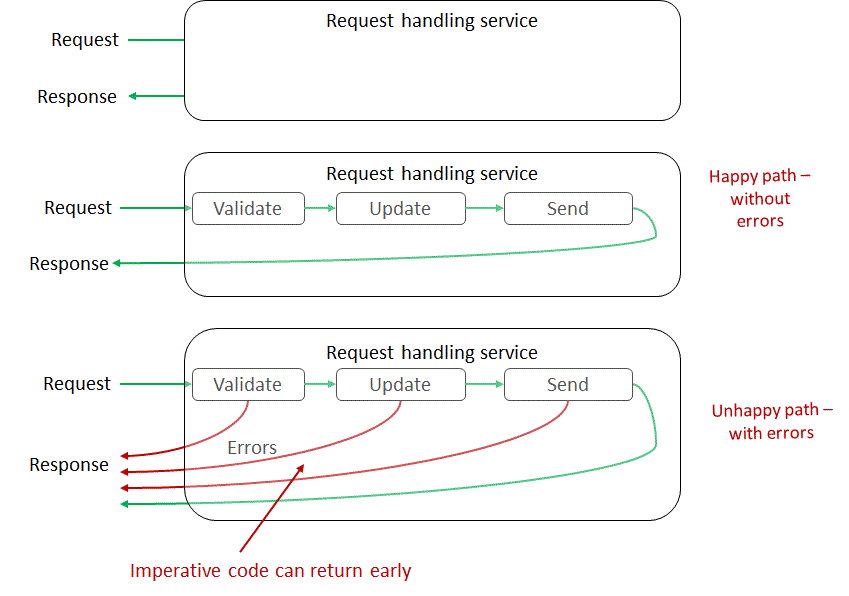
У нас есть запрос, ответ. Данные передаются по цепочке от одного метода к другому. Если происходит ошибка мы просто используем early return.
Архитектура запрос-ответ в функциональном стиле
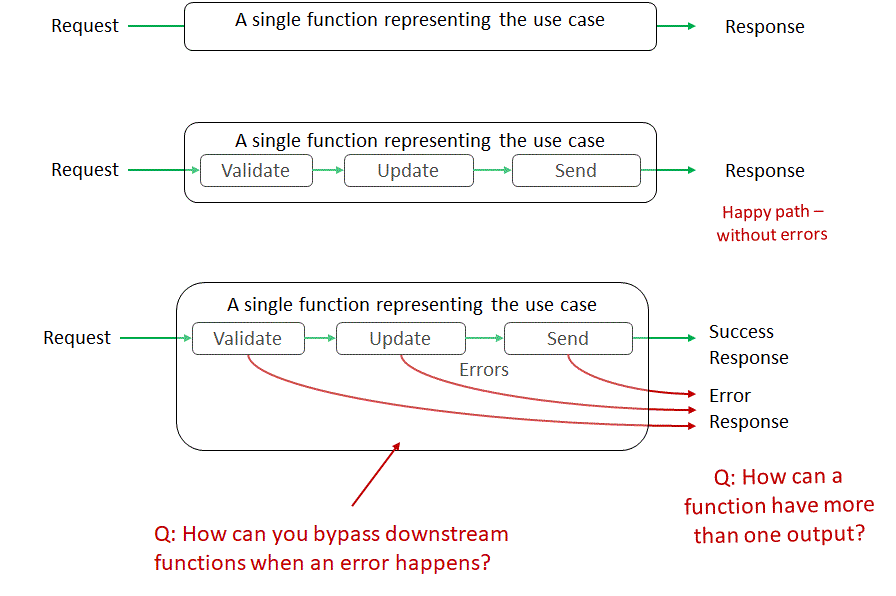
На «счастливом пути» все абсолютно также. Мы используем композицию функций, чтобы передать и обработать сообщение по цепочке. Но если что-то идет не так, мы должны передать сообщение об ошибки в качестве возвращаемого значения из функции. Итак, у нас две проблемы:
- как проигнорировать оставшиеся функции в случае ошибки?
- как вернуть четыре значения вместо одного (по одному возвращаемому значению на каждый тип ошибки)?
Как функция может возвращать больше одного значения?
В функциональных ЯП широко распространены типы-объединения. С их помощью можно моделировать несколько возможных состояний в рамках одного типа. У функции остается одно возвращаемое значение, но теперь оно принимает одно из четырех возможных значений: успех или тип ошибки. Осталось только обобщить данных подход. Объявим тип Result, состоящий из двух возможных значений
Success и Failure и добавим generic-аргумент с данными.type Result<'TEntity> = | Success of 'TEntity | Failure of string
Функциональный дизайн

- Каждый вариант использования реализуется с помощью одной функции
- Функции возвращают объединение из
SuccessиFailure - Функция для обработки варианта использования создана с помощью композиции более мелких функций, каждая из которых соответствует одному шагу преобразования данных
- Ошибки на каждом шаге будут скомбинированы так, чтобы возвращать одно значение
Как обрабатывать ошибки в функциональном стиле?

Если у вас есть очень умный друг, отлично разбирающийся в ФП у вас может состоятся диалог вроде такого:
- Я хотел бы использовать композицию функций, но мне не хватает удобного способа обработки ошибок
- О, это просто. Тебе нужна монада
- Звучит сложно. А что такое монада?
- Монада – это просто моноид в категории эндофункторов.
- ???
- В чем проблема?
- Я не знаю, что такое эндофунктор
- Это просто. Функтор – это гомоморфизм между категориями. А эндофунктор – это просто функтор, отображающий категорию на саму себя
- Ну конечно! Теперь все стало ясно...
Далее в оригинале идет непереводимая игра слов, на основеMaybe(может быть) иEither(или то или другое).MaybeиEither– это также названия монад. Если вам по душе английский юмор и вы тоже считаете терминологию ФП чересчур «академической» обязательно посмотрите оригинальный доклад.
Связь с монадой Either и композицией Клейсли
Любой поклонник Haskell заметит, что описанный мной подход является монадой
Either, специализированной типом списка ошибок для «левого» (Left) случая. В Haskell мы могли бы записать так:type Result a b = Either [a] (b,[a])
Конечно-же я не пытаюсь выдать себя за изобретателя данного подхода, хотя и претендую на авторство глупой аналогии с железной дорогой. Так почему же я не использовал стандартную терминологию Haskell? Во-первых, это не очередное руководство по монадам. Вместо этого основной фокус смещен на решение конкретной проблемы обработки ошибок. Большинство людей, начинающих изучение F# не знакомы с монадами, поэтому я предпочитаю менее пугающий, более визуальный и интуитивный для многих подход.
Во-вторых, я убежден, что подход от частного к общему более эфективен: гораздо проще взбираться на следующий уровень абстракции, когда хорошо разобрался в текущем. Я был бы не прав, если бы назвал свой «двухколейный» подход монадой. Монады – сложнее и я не хочу вдаваться в монадические законы в этом материале.
В-третьих,
Either – слишком общая концепция. Я хотел бы представить рецепт, а не инструмент. Рецепт приготовления хлеба, в котором написано «просто воспользуйтесь мукой и духовкой» не слишком полезен. Абсолютно также бесполезно руководство по обработке ошибок в стиле «просто воспользуйтесь bind и Either». Поэтому я предлагаю комплексный подход, включающий в себя целый набор техник:- Список специализированных типов-ошибок, вместо просто
Either String a bind (>>=)для композиции монадических функций в pipeline- композиция Клейсли (
>=>) для композиции монадических функций - функции
mapиfmapдля интеграции немонадических функций в pipeline - функция
teeдля интеграции функций, возвращающихunit(аналогvoidв F#) - маппинг исключений в коды ошибок
&&&для комбинирования монадических функций в параллельной обработке (например, для валидации)- преимущества использования кодов ошибок в Domain Driven Design (DDD)
- очевидные расширения для логгирования, доменных событий, компенсаторных транзакций и другое
Надеюсь, что это вам понравится больше, чем просто «воспользуйтесь монадой Either».
Аналогия с железной дорогой

Мне нравится представлять функцию как железнодорожные пути и тоннель трансформации. Если у нас есть две функции, одна преобразующая яблоки в бананы (
apple → banana), а другая бананы в вишни (banana → cherry), объединив их мы получим функции преобразования яблок в вишни (apple → cherry). С точки зрения программиста нет разницы получена эта функция с помощью композиции или написана вручную, главное – ее сигнатура.Развилка
Но у нас немного другой случай: одно значение на входе и два возможных – на выходе: одна ветка для успешного завершения и одна – для ошибки. В «железнодорожной» терминологии нам потребуется развилка.
Validate и UpdateDb – такие функции-развилки. Мы можем объединять их друг с другом. Добавим к Validate и UpdateDb функцию SendEmail. Я называю это «двухколейная модель». Некоторые предпочитают называть этот подход к обработке ошибок «монадой Either», но мне больше нравится мое название (хотя бы потому что в нем нет слова «монада»).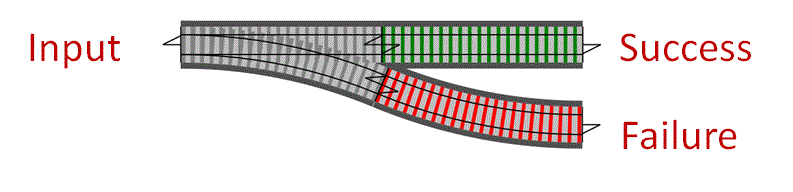
Теперь есть «одноколейные» и «двухколейные» функции. По отдельности и те, и другие компонуются, но они не компонуются друг с другом. Для этого нам потребуется небольшой «адаптер». В случае успеха, вызываем функцию и передаем ей значение, а в случае ошибки просто передаем значение ошибки дальше без изменений. В ФП такая функция называется
bind.
bind

let bind switchFunction = fun twoTrackInput -> match twoTrackInput with | Success s -> switchFunction s | Failure f -> Failure f // ('a -> Result<'b>) -> Result<'a> -> Result<'b>
Как видите эта функция очень проста: всего несколько строчек кода. Обратите внимание на сигнатуру функции. Сигнатуры очень важны в ФП. Первый аргумент – это «адаптер», второй аргумент – это входное значение в двухколейной модели и на выходе – также значение в двухколейной модели. Если вы увидите эту сигнатуру с любыми другими типами: с
list, asynс, feature или promise, перед вами все тот же bind. Функция может называться по-другому, например SelectMany в LINQ, но суть не меняется.Валидация
 Например, есть три правила валидации. Мы можем «сцепить» несколько правил валидации с помощью
Например, есть три правила валидации. Мы можем «сцепить» несколько правил валидации с помощью bind (чтобы преобразовать каждую из них к «двухколейной модели») и композиции функций. Вот и весь секрет обработки ошибок. let validateRequest = bind nameNotBlank >> bind name50 >> bind emailNotBlank
Теперь у нас есть «двухколейная» функция, принимающая на вход запрос и возвращающая ответ. Мы можем использовать ее в качестве строительного блока для других функций.
Часто
bind обозначается с помощью оператора >>=. Он заимствован из Haskell. В случае использования >>= код будет выглядеть следующим образом:let (>>=) twoTrackInput switchFunction = bind switchFunction twoTrackInput let validateRequest twoTrackInput = twoTrackInput >>= nameNotBlank >>= name50 >>= emailNotBlank
При использовании
bind проверка типов работает также, как и прежде. Если у вас были компонуемые функции, то они останутся компонуемыми после применения bind. Если функции не были компонуемыми, то bind не сделает их таковыми.Итак, база для обработки ошибок следующая: преобразуем функции к «двухколейной модели» с помощью
bind и объединяем их с помощью композиции. Двигаемся по зеленой колее пока все хорошо или сворачиваем на красную в случае ошибки.Но это еще не все. Нам потребуется вписать в эту модель
- одноколейные функции без ошибок
- тупиковые функции
- функции, выбрасывающие исключения
- управляющие функции
Одноколейные функции без ошибок

let canonicalizeEmail input = { input with email = input.email.Trim().ToLower() }
Функция
canonicalizeEmail – очень простая. Она обрезает лишние пробелы и преобразует email к нижнему регистру. В ней не должно быть ошибок и исключений (кроме NRE). Это просто преобразование строки.Проблема в том, что мы научились компоновать с помощью
bind только двухколейные функции. Нам потребуется еще один адаптер. Этот адаптер называется map (Select в LINQ).let map singleTrackFunction twoTrackInput = match twoTrackInput with | Success s -> Success (singleTrackFunction s) | Failure f -> Failure f // map : ('a -> 'b) -> Result<'a> -> Result<'b>
map – более слабая функция чем bind, потому что map можно создать с помощью bind, но не наоборот.
Тупиковые функции

let updateDb request = // do something // return nothing at all
Тупиковые функции – это операции записи в духе fire & forget: вы обновляете значение в БД или пишете файл. У них нет возвращаемого значения. Они также не компонуются с двухколейными функциями. Все, что нам нужно это получить входное значение, выполнить «тупиковую» функцию и передать значение дальше по цепочке. По аналогии с
bind и map объявим функции tee (иногда ее называют tap).let tee deadEndFunction oneTrackInput = deadEndFunction oneTrackInput oneTrackInput // tee : ('a -> unit) -> 'a -> 'a

Функции, выбрасывающие исключения
 Вы, наверное, уже заметили, что начал вырисовываться определенный «паттерн». Особенно функции, работающие с вводом / выводом. Сигнатуры таких методов лгут, потому что кроме успешного завершения, они могут выбросить исключение, создавая таким образом дополнительные exit points. Из сигнатуры этого не видно, вам нужно ознакомиться с документацией, чтобы знать какие исключения выбрасывает та или иная функция.
Вы, наверное, уже заметили, что начал вырисовываться определенный «паттерн». Особенно функции, работающие с вводом / выводом. Сигнатуры таких методов лгут, потому что кроме успешного завершения, они могут выбросить исключение, создавая таким образом дополнительные exit points. Из сигнатуры этого не видно, вам нужно ознакомиться с документацией, чтобы знать какие исключения выбрасывает та или иная функция.Исключения не подходят для этой «двухколейной» модели. Давайте обработаем их: функция
SendEmail выглядит безопасной, но она может выбросить исключение. Добавим еще один «адаптер» и обернем все такие функции в try / catch-блок.“Do or do not, there is no try” — даже Йода не рекомендует использовать исключения для control flow. Много интересного на эту тему в докладе Exceptional Exceptions Адама Ситника (на английском языке).
Управляющие функции

В таких функциях вам просто необходимо реализовать дополнительную логику, например, логгирование только успешных операций или ошибок, или и того и другого. Ничего сложного, делаем по аналогии с предыдущими случаями.
Собираем все вместе

Мы объединили функции
Validate, Canonicalize, UpdateDb и SendEmail. Осталась одна проблема. Браузер не понимает «двухколейной модели». Теперь необходимо снова вернуться к «одноколейной» модели. Добавляем функцию returnMessage. Возвращаем http-код 200 и JSON случае успеха или BadRequest и сообщение, в случае ошибки.let executeUseCase = receiveRequest >> validateRequest >> updateDbFromRequest >> sendEmail >> returnMessage
Итак, я и обещал, что код без обработки ошибок будет идентичен коду с обработкой ошибок. Признаюсь, я немного схитрил и объявил новые функции в другом пространстве имен, оборачивающие функции слева в
bind.Расширяем фреймворк
- Учитываем возможные ошибки при проектировании
- Параллелизация
- Доменные события
Учитываем возможные ошибки при проектировании
Я хочу особо отметить, что обработка ошибок входит в состав требований к ПО. Мы концентрируемся только на успешных сценариях. Нужно уровнять успешные сценарии и ошибки в правах.
let validateInput input = if input.name = "" then Failure "Name must not be blank" else if input.email = "" then Failure "Email must not be blank" else Success input // happy path type Result<'TEntity> = | Success of 'TEntity | Failure of string
Рассмотрим нашу функцию валидации. Мы используем строки для ошибок. Это отвратительная идея. Введем специальные типы для ошибок. В F# обычно вместо enum используется union type. Объявим тип ErrorMessage. Теперь в случае ошибки появления новой ошибки нам придется добавить еще один вариант в ErrorMessage. Это может показаться обузой, но я думаю, что это, наоборот, хорошо, потому что такой код является самодокументируемым.
let validateInput input = if input.name = "" then Failure NameMustNotBeBlank else if input.email = "" then Failure EmailMustNotBeBlank else if (input.email doesn't match regex) then Failure EmailNotValid input.email else Success input // happy path type ErrorMessage = | NameMustNotBeBlank | EmailMustNotBeBlank | EmailNotValid of EmailAddress
Представьте, что вы работаете с унаследованным кодом. Вы в общих чертах представляете, как должна работать система, но вы не знаете точно, что может пойти не так. Что, если бы у вас был файл, описывающий все возможные ошибки? И что более важно, это не просто текст, а код, так что эта информация актуальна.
Такой подход очень похож на checked exceptions в Java. Стоит отметить, что они не взлетели.
Если вы практикуете DDD, то вы можете строить коммуникацию с бизнес-пользователями на основе этого кода. Вам придется задавать вопросы о том, как следует обработать ту или иную ситуацию, что в свою очередь заставит вас и бизнес-пользователей рассмотреть больше вариантов использования еще на этапе проектирования.
После того как мы заменили строки на типы ошибок нам придется доработать функцию
retrunMessage, чтобы преобразовать типы в строки.let returnMessage result = match result with | Success _ -> "Success" | Failure err -> match err with | NameMustNotBeBlank -> "Name must not be blank" | EmailMustNotBeBlank -> "Email must not be blank" | EmailNotValid (EmailAddress email) -> sprintf "Email %s is not valid" email // database errors | UserIdNotValid (UserId id) -> sprintf "User id %i is not a valid user id" id | DbUserNotFoundError (UserId id) -> sprintf "User id %i was not found in the database" id | DbTimeout (_,TimeoutMs ms) -> sprintf "Could not connect to database within %i ms" ms | DbConcurrencyError -> sprintf "Another user has modified the record. Please resubmit" | DbAuthorizationError _ -> sprintf "You do not have permission to access the database" // SMTP errors | SmtpTimeout (_,TimeoutMs ms) -> sprintf "Could not connect to SMTP server within %i ms" ms | SmtpBadRecipient (EmailAddress email) -> sprintf "The email %s is not a valid recipient" email
Логика конвертации может быть контекстно-зависимой. Это сильно облегчает задачу интернационализации: вместо того, чтобы искать разбросанные по всей кодовой базы строки вам достаточно внести изменение в одну функцию, прямо перед передачей управления в слой UI. Резюмируя можно сказать, что такой подход дает следующие преимущества:
- документация для всех случаев, в которых что-то пошло не так
- типо-безопасно, не может устареть
- раскрывает скрытые требования к систиеме
- упрощает модульное тестирование
- упрощает интернационализацию
Параллелизация

В примере с валидацией последовательная модель уступает в удобстве использования параллельной: вместо того, чтобы получать ошибку валидации на каждое поле удобнее получить разом все ошибки и исправить их одновременно.
Если вы можете применить операцию к паре и получить в результате объект того же тип, то вы можете применить такие операции и к спискам. Это свойство моноидов. Для более глубоко понимания темы вы можете ознакомиться со статьей «моноид без слез».
Доменные события

В ряде случаев бывает необходимо передать дополнительную информацию. Это не ошибки, просто что-то, представляющее дополнительный интерес в контексте операции. Мы можем добавить эти сообщения к возвращаемому значению «успешного пути».
За рамками данной статьи
- Обработка ошибок, пересекающих границы сервисов
- Асинхронная модель
- Компенсаторные транзакции
- Логгирование
Резюме. Обработка ошибок в функциональном стиле

- Создаем тип
Result. КлассическийEitherеще более абстрактный и содержит свойстваLeftиRight. Мой типResultлишь более специализирован. - Используем bind для преобразования функций к «двухколейной модели»
- Используем композицию для сцепления отдельных функций между собой
- Рассматриваем коды ошибок как объекты первого класса
Ссылки
- Исходный код с примером доступен на github
- Статья на Хабре по мотивам доклада с реализацией на C#
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Что вы используете для работы с ошибками
24.18%монады22
70.33%исключения64
35.16%коды ошибок32
5.49%другое (в комментариях)5
Проголосовал 91 пользователь. Воздержались 37 пользователей.

