
Сейчас происходит процесс демократизации искусственного интеллекта — технология, которая недавно считалась привилегией ограниченного числа крупных компаний, становится все более доступной для отдельных специалистов.
За последние годы появилось большое количество моделей, созданных и обученных профессионалами с использованием большого количества данных и огромных вычислительных мощностей. Многие из этих моделей находятся в открытом доступе, и любой может использовать их для решения своих задач совершенно бесплатно.
В этой статье мы разберем, как предобученные нейронные сети могут быть использованы для решения задачи классификации изображений, и оценим плюсы их использования.
Предсказание класса растения по фото
В качестве примера мы рассмотрим задачу классификации изображений из конкурса LifeCLEF2014 Plant Identification Task. Задача заключается в том, чтобы предсказать таксономический класс растения, основываясь на нескольких его фотографиях.
Для обучения нам доступно 47815 изображений растений, каждое из которых принадлежит к одному из 500 классов. Необходимо построить модель, которая будет возвращать список наиболее вероятных классов растения. Позиция верного класса растения в списке предсказанных классов (ранг) определяет качество системы.
Эта задача моделирует реальный жизненный сценарий, где человек пытается идентифицировать растение, изучая его отдельные части (стебель, лист, цветок и др.)
Модель на входе получает “наблюдение” — набор фотографий одного и того же растения, сделанный в один и тот же день, при помощи одного и того же устройства, при одинаковых погодных условиях. В качестве примера можно взять изображение, предоставленное организаторами конкурса:
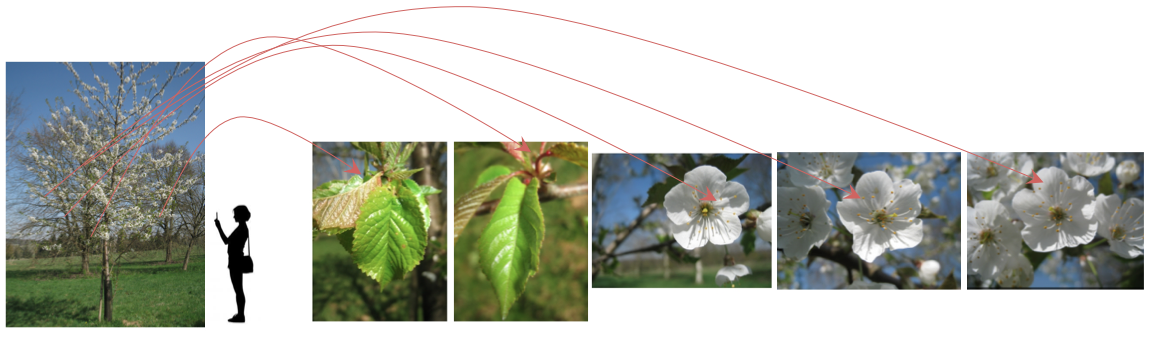
Поскольку качество и количество фотографий варьируется от пользователя к пользователю, организаторы предложили метрику, которая будет учитывать способность системы выдавать верные предсказания для отдельных пользователей. Таким образом, первичный показатель качества определяется как следующая средняя оценка S:

где
 — количество пользователей, которые имеют хотя бы одно фото в тестовой выборке,
— количество пользователей, которые имеют хотя бы одно фото в тестовой выборке,  — число уникальных растений, которые сфотографировал пользователь ,
— число уникальных растений, которые сфотографировал пользователь ,  — значение от 0 до 1, рассчитывается как обратное число от ранга верного класса растения в списке наиболее вероятных классов.
— значение от 0 до 1, рассчитывается как обратное число от ранга верного класса растения в списке наиболее вероятных классов. В рамках конкурса было запрещено использование любых внешних источников данных, включая предобученные нейронные сети. Мы намеренно проигнорируем это ограничение, чтобы продемонстрировать, как можно улучшить классификатор с помощью предобученных моделей.
Решение
Для решения задачи мы будем использовать нейронные сети, которые обучались на 1.2 миллионах изображений из базы данных ImageNet. Изображения содержат объекты, относящиеся к 1000 разных классов, такие как компьютер, стол, кот, собака и другие объекты, с которыми мы часто встречаемся в повседневной жизни.
В качестве базовых архитектур мы выбрали VGG16, VGG19, ResNet50 и InceptionV3. Эти сети были натренированы на огромном количестве изображений и уже умеют распознавать простейшие объекты, поэтому можно надеяться, что они помогут нам создать достойную модель для классификации растений.
Итак, начнем с… препроцессинга изображений, как же без этого.
Препроцессинг изображений
Препроцессинг изображений — это предварительная обработка изображений. Основной целью предобработки, в нашем случае, является выявление наиболее важной части изображения и удалении ненужного шума.
Мы будем использовать те же методы предобработки, что и победители соревнования (IBM Research team), но с небольшими изменениями.
Все изображения в обучающем сете можно разделить на категории в зависимости от части растения, изображенного на них: Entire (растение целиком), Branch (ветвь), Flower (цветок), Fruit (фрукт), LeafScan (скан листа), Leaf (лист), Stem (стебель). Для каждой из этих категорий был подобран свой наиболее подходящий метод предварительной обработки.
Обработка Entire и Branch изображений
Мы не будем изменять Entire и Branch изображения, поскольку зачастую большая часть изображения содержит полезную информацию, которую мы не хотим потерять.
Пример Entire изображений
 |
 |
Пример Branch изображений
 |
 |
Обработка Flower и Fruit изображений
Для обработки Flower и Fruit изображений мы будем использовать один и тот же метод:
- конвертируем изображение в черно-белое;
- применяем фильтр Гаусса с параметром a = 2.5;
- используем метод активных контуров для поиска наиболее важной части изображения;
- описываем прямоугольник вокруг границы.
Пример обработки Flower изображения
 |
 |
Пример обработки Fruit изображения
 |
 |
Обработка LeafScan изображений
Просмотрев фотографии LeafScan, можно заметить, что в большинстве случаев лист находится на светлом фоне. Мы нормализуем изображение белым цветом:
- сперва конвертируем изображение в черно-белое и применяем Otsu-метод, чтобы рассчитать пороговое значение;
- все пиксели, значения которых меньше порогового значения, окрашиваем в белый цвет.
Пример обработки LeafScan изображений
 |
 |
Обработка Leaf изображений
Обычно в Leaf изображениях лист находится в центре, а его контур немного отступает от краев изображения. Для препроцессинга таких фото будем использовать следующий метод:
- вырезаем по 1/10 изображения слева, справа, снизу и сверху;
- конвертируем изображение в черно-белое;
- применяем фильтр Гаусса с параметром a = 2;
- используем метод активных контуров, чтобы посчитать границу наиболее важной области;
- описываем прямоугольник вокруг полученной границы.
Пример обработки Leaf изображений
 |
 |
Обработка Stem изображений
Стебель обычно находится в центре изображения. Для обработки Stem изображений будем использовать следующий алгоритм:
- удаляем по ⅕ части изображения слева, справа, снизу и сверху;
- конвертируем изображение в черно-белое;
- применяем фильтр Гаусса с параметром a = 2;
- используем метод активных контуров, чтобы посчитать границу наиболее важной области изображения;
- описываем прямоугольник вокруг полученной границы.
Пример обработки Stem изображений
 |
 |
Теперь все готово для построения классификатора.
Как мы строили классификатор изображений на основе предобученной нейронной сети
Модель будем строить при помощи Keras с TensorFlow в качестве бэк-энда. Keras — мощная библиотека машинного обучения, предназначенная для работы с нейронными сетями, которая позволяет строить всевозможные модели: от простых, таких как перцептрон, до очень сложных сетей, предназначенных для обработки видео. И что очень важно в нашем случае, Keras позволяет использовать предобученные нейронные сети и оптимизировать модели как с помощью CPU, так и GPU.
ШАГ 1
Сперва мы загружаем предобученную модель без полносвязных слоев и к ее выходу применяем операцию пулинга (pooling). В нашем случае лучшие результаты показал “средний” пулинг (GlobalAveragePooling), его и возьмем для построения модели.
Затем мы прогоняем изображения из тренировочного сета через полученную сеть, а полученные признаки сохраняем в файл. Немного позже вы увидите, зачем это нужно.
ШАГ 2
Мы могли бы заморозить все слои предобученной сети, добавить поверх нее свою полносвязную сеть, а затем обучать полученную модель, однако мы не будем этого делать, так как в этом случае нам придется на каждой эпохе все изображения прогонять через предобученную сеть, а это занимает очень много времени. Чтобы сэкономить время, мы используем те признаки, которые мы сохранили на предыдущем шаге, для того, чтобы на них обучить полносвязную сеть.
На данном этапе не забудьте разделить тренировочный сет на две части: обучающее множество, на котором будем обучаться, и валидационное множество, на котором будем считать ошибку, чтобы корректировать веса. Данные можно разделить в отношении 3 к 1.
Давайте более подробно рассмотрим архитектуру полносвязной сети, которую мы будем обучать. После ряда экспериментов было выяснено, что одна из лучших архитектур имеет следующую структуру:
- 3 плотных слоя по 512 нейронов. За каждым dense-слоем идет Dropout-слой, с параметром 0.5. Это значит, что в каждом слое на каждом проходе сети мы случайным образом выбрасываем сигналы примерно половины нейронов;
- выходной слой представляет собой softmax на 500 классов;
- в качестве функции потерь мы используем categorical cross-entropy, а оптимизируем сеть при помощи Adam;
- также было замечено, что использование функции selu (scaled exponential unit) вместо relu в качестве функции активации помогает сети сходиться быстрее.
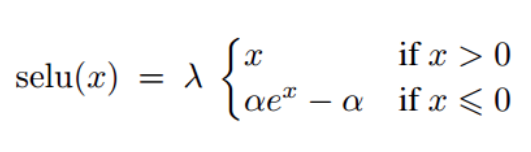
Полезная информация:
- при описанном методе обучения мы не сможем использовать аугментацию (трансформацию изображений: повороты, сжатие, добавление шума и др.), но так как полученная на этом шаге модель является лишь промежуточным результатом в процессе создания конечной модели, для нас это ограничение не является критичным;
- такие сети обучаются очень быстро, и мы можем вручную определить необходимое количество эпох;
- в нашем случае нейронной сети требовалось от 40 до 80 эпох для сходимости;
переобучение или недообучение модели не должно нас сильно волновать, поскольку у нас еще будет шанс это исправить.
ШАГ 3
На этом шаге мы добавляем обученную полносвязную сеть поверх предобученной модели. Функцию потерь оставляем без изменений, а для обучения сети будем использовать другой оптимизатор.
Предобученная нейронная сеть уже выучила много абстрактных и общих признаков, и чтобы не сбить найденные веса, мы будем тренировать сеть с очень маленькой скоростью обучения. Такие оптимизаторы как Adam и RMSProp сами подбирают скорость обучения, в нашем случае выбранная скорость может оказаться слишком высокой, поэтому они нам не подходят. Чтобы иметь возможность самим задавать скорость обучения, мы будем использовать классический SGD-оптимизатор.
Чтобы улучшить качество итогового классификатора, нужно помнить следующее:
- уменьшайте скорость обучения на плато, чтобы слишком сильно не уйти в сторону минимума (ReduceLROnPlateau callback);
- если на протяжении нескольких эпох ошибка на валидационных данных не уменьшается, то стоит прекратить обучение (EarlyStopping callback);
- обычно дообучение моделей занимает много времени и когда мы закрываем .ipynb-файлы, весь динамический вывод теряется. Я рекомендую сохранять информацию об обучении в файл (CSVLogger callback), чтобы в дальнейшем можно было проанализировать, как проходит обучение модели.
Вместо стандартного progress bar я предпочитаю использовать TQDMNotebookCallback. Это напрямую не влияет на результат, но с ним намного приятнее смотреть за обучением моделей.
Аугментация данных
Поскольку на заключительном шаге мы обучаем сеть целиком, здесь мы можем использовать аугментацию. Но вместо стандартного ImageDataGenerator из Keras мы будем использовать Imgaug — библиотеку, которая предназначена для аугментирования изображений. Важной особенностью Imgaug является то, что можно явно указать, с какой вероятностью преобразование должно быть применено к изображению. Кроме того, в этой библиотеке имеется большое разнообразие преобразований, есть возможность объединять преобразования в группы, и выбирать, какую из групп применить. Примеры можно найти по ссылке выше.
Для аугментации мы выбираем те преобразования, которые могут происходить в реальной жизни, например, зеркальное отражение фото (по горизонтали), повороты, увеличение, зашумление, изменение яркости и контрастности. Если вы хотите использовать большое количество преобразований, то очень важно не применять их одновременно, поскольку для сети будет очень сложно извлечь полезную информацию из фото.
Я предлагаю разбить преобразования на несколько групп и применять каждую из них с заданной вероятностью (у каждого может быть разная вероятность). Также я рекомендую аугментировать изображения в 80% случаях, тогда сеть сможет увидеть и реальное изображения. Учитывая то, что обучение занимает нескольких десятков эпох, есть очень большой шанс, что сеть увидит каждое изображение в оригинале.
Учет пользовательских оценок фотографий
В метаданных к каждому изображений есть оценка качества (средняя оценка пользователей, показывающая, насколько хорошо изображение подходит для классификации). Мы предположили, что изображения с оценкой 1 и 2 достаточно шумные, и хотя они могут содержать полезную информацию, в итоге они могут негативно повлиять на качество классификатора. Эту гипотезу мы проверили при обучении InceptionV3. Изображений с оценкой 1 в тренировочном сете оказалось совсем немного, всего 1966, поэтому мы решили не использовать их при обучении. В результате, сеть обучалась лучше на изображениях с рейтингом выше единицы, поэтому я рекомендую вам внимательно относиться к качеству изображений в тренировочном наборе.
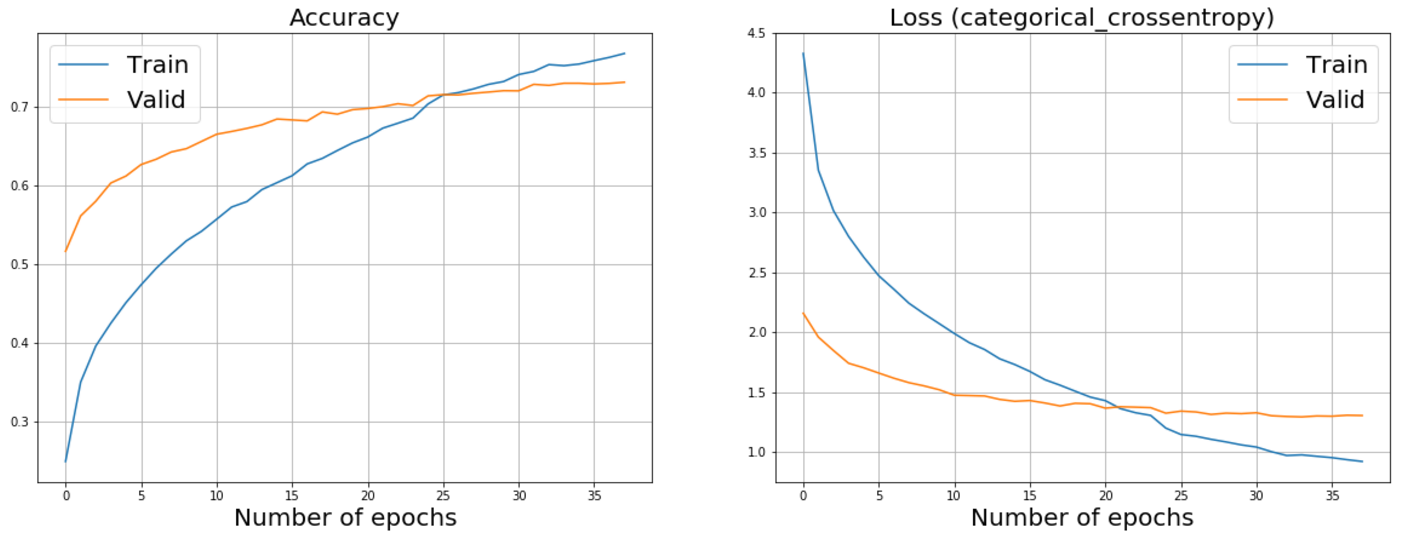
Ниже можно видеть графики дообучения ResNet50 и InceptionV3. Забегая немного вперед, скажу, что именно эти сети помогли нам достигнуть наилучших результатов.
График дообучения ResNet50
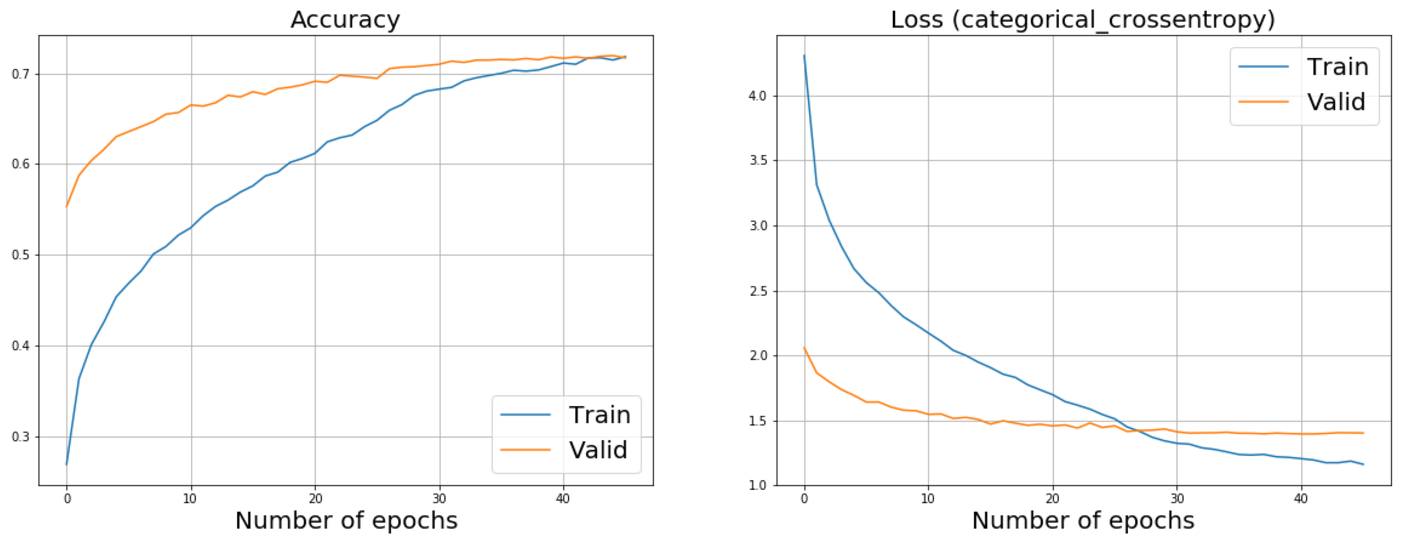
График дообучения InceptionV3
Test time augmentation
Еще один способ, который помог увеличить качество классификатора — предсказание на аугментированных данных (test-time augmentation, TTA). Этот способ заключается в том, чтобы делать предсказания не только для изображений в тестовом наборе, но и для их аугментаций.
Например, возьмем пять наиболее реалистичных преобразований, применим их к изображениям и будем получим предсказания уже не для одной картинки, а для шести. После этого усредним полученный результат. Обратите внимание, что все аугментированные изображения получены в результате одного преобразования (одно изображение — одно преобразование).
Пример аугментации на предсказании

Результаты
Результаты проделанной работы представлены в таблице ниже.
Будем использовать 4 метрики: основную метрику, предложенную организаторами, а также 3 top-метрики — Top 1, Top 3, Top 5. Top-метрики, также как и основная, применяются к наблюдению (набору фотографий с одинаковым Observation Id), а не к отдельному изображению.
В процессе работы мы попробовали объединить результаты нескольких моделей, чтобы еще больше улучшить качество классификатора (все модели брались с одинаковым весом). Последние три строки в таблице показывают лучшие результаты, полученные при объединении моделей.
| Модель | Сеть | Целевая метрика (rank) | Top 1 | Top 3 | Top 5 | Эпохи | TTA |
|---|---|---|---|---|---|---|---|
| 1 | VGG16 | 0.549490 | 0.454194 | 0.610442 | 0.665546 | 49 | Нет |
| 2 | VGG16 | 0.553820 | 0.458732 | 0.612600 | 0.666996 | 49 | Да |
| 3 | VGG19 | 0.559978 | 0.468980 | 0.620219 | 0.671253 | 62 | Нет |
| 4 | VGG19 | 0.563019 | 0.470534 | 0.619303 | 0.676396 | 62 | Да |
| 5 | ResNet50 | 0.573424 | 0.489943 | 0.627836 | 0.682585 | 46 | Нет |
| 6 | ResNet50 | 0.581954 | 0.495962 | 0.638806 | 0.688938 | 46 | Да |
| 7 | InceptionV3 | 0.528063 | 0.495962 | 0.666928 | 0.716630 | 38 | Нет |
| 8 | InceptionV3 | 0.615734 | 0.535675 | 0.671392 | 0.723992 | 38 | Да |
| 9 | Объединение моделей 1, 3, 5, 7 | 0.63009 | 0.549993 | 0.677204 | 0.721084 | - | - |
| 10 | Объединение моделей 2, 4, 6, 8 | 0.635100 | 0.553577 | 0.680857 | 0.727824 | - | - |
| 11 | Объединение моделей 2, 6, 8 | 0.632564 | 0.551064 | 0.684839 | 0.730051 | - | - |
Модель победителей соревнования показала результат 0.471 по целевой метрике. Она представляет собой сочетание статистических методов и нейронной сети, обученной лишь на тех изображениях растений, которые были предоставлены организаторами.
Наша модель, которая в качестве основы использует предобученную нейронную сеть InceptionV3, достигает результата 0.60785 по целевой метрике, улучшая результат победителей конкурса на 29%.
При использовании аугментации на тестовых данных, результат по целевой метрике увеличивается до 0.615734, но в то же время скорость работы модели падает примерно в 6 раз.
Мы можем пойти еще дальше и объединить результаты работы нескольких сетей. Такой подход позволяет добиться результата 0.635100 по целевой метрике, но при этом скорость очень сильно падает, и в реальной жизни такая модель может найти применение лишь там, где скорость работы не является ключевым фактором, например, в различных исследованиях в лабораториях.
Существующие модели не всегда могут верно определить класс растение, в этом случае можем быть полезно знать список из наиболее вероятных видов растения. Для того чтобы измерить способность модели выдавать истинный класс растения в списке наиболее вероятных классов, мы используем top-метрики. Например, по метрике Top 5 доученная сеть InceptionV3 показала результат 0.716630. Если же объединить несколько моделей и применить TTA, то можно улучшить результат до 0.730051.
Я описал, как нам удалось улучшить качество модели, используя предобученные нейронные сети, но, конечно, в этой статье описана лишь часть доступных способов.
Я рекомендую попробовать и другие подходы, которые выглядят достаточно перспективными:
- использование более точных методов для предобработки изображений;
- модификация архитектуры полносвязных слоев;
- изменение функции активации для плотных слоев;
- использование только наиболее качественных изображений для обучения (например, с оценкой выше 2);
- исследование распределения классов в обучающем множестве, и использование параметра class_weight при обучении.
Итог
Дообучение нейронных сетей, которые были натренированы на более чем 1 миллионе изображений, позволило значительно улучшить решение, представленное победителями конкурса. Наш подход показал, что предобученные модели могут значительно улучшить качество в задачах классификации изображений, особенно в ситуациях, когда отсутствует достаточное количество данных для обучения. Даже если ваша базовая модель не имеет ничего общего с решаемой задачей, она все равно может оказаться полезной, поскольку уже умеет узнавать самые простые объекты окружающего мира.
Наиболее важные шаги, которые помогли добиться таких результатов:
- использование Imgaug для аугментации изображений (эта библиотека содержит больше трансформаций, чем ImageDataGenerator из Keras, кроме того, есть возможность объединять преобразования в группы);
- на каждой эпохе обучения аугментировалось 80% изображений;
- использование предсказаний на аугментированных данных (TTA);
- уменьшение скорости обучения на плато;
- остановка обучения если значение функции потерь на валидационных данных не уменьшается на протяжении нескольких эпох;
- обучение модели на изображениях с оценкой больше 1.
Желаю вам удачи в ваших экспериментах!

