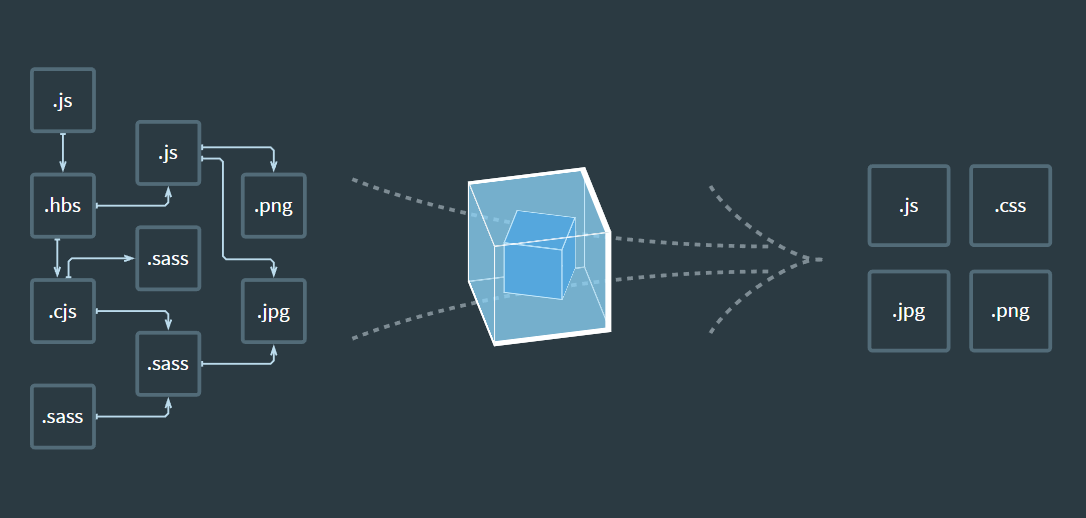
После прочтения ряда статей (например, этой) решил перейти на современный подход с использованием Node.js при написании простых сайтов с подхода «динозавров». Ниже представлен разбор примера сборки простого статического сайта с помощью Webpack 4. Статья написана, так как инструкции с решением моей задачи не нашел: пришлось собирать всё по кусочкам.
Постановка задачи
Сайт представляет собой простой набор HTML-страниц со своим CSS стилями и файлом JavaScript. Необходимо написать проект, который бы собирал наш сайт из исходников:
- из SASS (точнее SCSS) файлов формируется один CSS файл;
- из различных JavaScript библиотек и пользовательского кода формируется один JavaScript файл;
- HTML страницы собираются с помощью шаблонизатора, где содержимое шапки и футера можно разнести по отдельным файлам.
В собранном сайте не должны использоваться React, Vue.js.
При выборе технологий выбираются по возможности наиболее популярные на данный момент. По этой причине отказался и от Grunt и Gulp в пользу Webpack, хотя, если честно, синтаксис Gulp мне понравился больше своим однообразием.
Для примера будет сверстано несколько страничек на базе Bootstrap 4. Но это только для примера.
Предполагается, что Node.js установлен (в Windows просто скачивается установщик и устанавливается в стиле «далее, далее»), и вы умеете работать с командной строкой.
Update. Нужно получить набор готовых HTML страниц, которые можно залить на хостинг без дополнительных настроек (например, на GitHub Pages) или открыть локально на компьютере.
Структура проекта
Общая структура проекта представлена ниже:
. ├── dist - папка, куда будет собираться сайт ├─┬ src - папка с исходниками сайта │ ├── favicon - папка с файлами иконок для сайта │ ├── fonts - папка со шрифтами │ ├─┬ html - папка заготовок HTML страниц │ │ ├── includes - папка с встраиваемыми шаблонами (header, footer) │ │ └── views - папка с самими HTML страницами │ ├── img - папка с общими изображениями (логотип, иконки и др.) │ ├── js - папка с JavaScript файлами │ ├── scss - папка с SСSS файлами │ └── uploads - папка с файлами статей (картинки, архивы и др.) ├── package.json - файл настроек Node.js └── webpack.config.js - файл настроек Webpack
. ├── dist ├─┬ src │ ├─┬ favicon │ │ └── favicon.ico │ ├─┬ fonts │ │ └── Roboto-Regular.ttf │ ├─┬ html │ │ ├─┬ includes │ │ │ ├── footer.html │ │ │ └── header.html │ │ └─┬ views │ │ ├── index.html │ │ └── second.html │ ├─┬ img │ │ └── logo.svg │ ├─┬ js │ │ └── index.js │ ├─┬ scss │ │ └── style.scss │ └─┬ uploads │ └── test.jpg ├── package.json └── webpack.config.js
Под favicon выделена целая папка, так как в современном web обычным одним ico файлом не обойтись. Но для примера используется только этот один файл.
Спорным решением может показаться разделение картинок на две папки: img и uploads. Но здесь использовал идеологию расположения файлов из Wordpress. На мой взгляд, кидать все изображения в одну папку — не очень хорошая идея.
Для работы с проектом использую Visual Studio Code, которым очень доволен. Особенно мне нравится, что командная строка встроена в программу и вызывается через Ctrl + `.
Сделаем болванку Node.js проекта. Для этого создадим папку нашего проекта с вышеописанной структурой и перейдем в неё в командной строке, где вызовем команду для создания файла package.json.
npm init
На все вопросы можно просто отвечать, нажимая Enter, если заполнять подробную информацию не хочется.
Установим три общих пакета, которые нам потребуются в любом случае: webpack, webpack-cli (работу с командной строкой в webpack вынесли в отдельный пакет) и webpack-dev-server (для запуска локального сервера, чтобы в браузере сразу отображались сохраненные изменения проекта).
npm install webpack webpack-cli webpack-dev-server --save-dev
{ "name": "static-site-webpack-habr", "version": "1.0.0", "description": "", "main": "index.js", "scripts": { "test": "echo \"Error: no test specified\" && exit 1" }, "license": "ISC", "devDependencies": { "webpack": "^4.1.1", "webpack-cli": "^2.0.11", "webpack-dev-server": "^3.1.1" } }
Также создастся файл package-lock.json, который вообще не трогаем. Но в git репозиторий добавлять этот файл нужно, в отличии от папки node_modules, которую нужно прописать в файле .gitignore, если пользуетесь git.
Собираем JavaScript
Так как Webpack создан в первую очередь для сборки js файлов, то эта часть будем самой простой. Чтобы можно было писать javascript в современном виде ES2015, который не поддерживается браузерами, поставим пакеты babel-core, babel-loader, babel-preset-env.
npm install babel-core babel-loader babel-preset-env --save-dev
После создаем файл настроек webpack.config.js с таким содержимым:
const path = require('path'); module.exports = { entry: [ './src/js/index.js', ], output: { filename: './js/bundle.js' }, devtool: "source-map", module: { rules: [{ test: /\.js$/, include: path.resolve(__dirname, 'src/js'), use: { loader: 'babel-loader', options: { presets: 'env' } } }, ] }, plugins: [ ] };
В разделе entry (точки входа) указываем, какой js файл будем собирать, в разделе output указываем путь в папке dist, куда будем помещаться собранный файл. Обратите внимание, что в webpack 4 в пути output саму папку dist указывать не нужно! И да, как же мне не нравится, что в одном файле webpack в одних случаях нужно писать относительный путь, в других случаях относительный путь в специальной папке, в третьих случаях нужен уже абсолютный путь (например, его получаем этой командой path.resolve(__dirname, 'src/js')).
Также указано значение параметра devtool, равное: source-map, что позволит создавать карты исходников для js и css файлов.
Для обработки конкретных файлов (по расширению, по месторасположению) в webpack создаются правила в разделе rules. Сейчас у нас там стоит правило, что все js файлы пропускаем через транслятор Babel, который преобразует наш новомодный ES2015 в стандартный javascript вариант, понятный браузерам.
В нашем тестовом примере мы верстаем наши странице на Boostrap 4. Поэтому нам нужно будет установить три пакета: bootstrap, jquery, popper.js. Второй и третий пакет мы устанавливаем по требованию Bootstrap.
npm install bootstrap jquery popper.js --save
Обратите внимание на то, что эти три пакета нам нужны именно для самого сайта, а не для его сборки. Поэтому эти пакеты мы устанавливаем с флагом --save, а не --save-dev.
Теперь можно приступить к написанию нашего index.js файла:
import jQuery from 'jquery'; import popper from 'popper.js'; import bootstrap from 'bootstrap'; jQuery(function() { jQuery('body').css('color', 'blue'); });
В качестве примера пользовательского кода js просто перекрасили цвет текста на синий.
Теперь можно перейти к сборке js файла. Для этого в файле package.json в разделе scripts пропишем следующие npm скрипты:
"scripts": { "dev": "webpack --mode development", "build": "webpack --mode production", "watch": "webpack --mode development --watch", "start": "webpack-dev-server --mode development --open" },
Теперь при запуске в командной строке строчки npm run dev произойдет сборка проекта (css и html файлы потом также будут собираться этой командой), и в папке /dist/js появятся файлы bundle.js и bundle.js.map.
При запуске команды npm run build также произойдет сборка проекта, но уже итоговая (с оптимизацией, максимальной минимизацией файла), которую можно выкладывать на хостинг.
При запуске npm run watch запускается режим автоматического просмотра изменений файлов проекта с автоматическим допостроением измененных файлов. Да, чтобы в командной строке отключить этот режим (например, чтобы можно было написать другие команды) можно нажать Ctrl + C (как минимум в PowerShell).
При запуске npm run start запустится локальный сервер, который запустит html страницу и также будет отслеживать изменения в файлах. Но пока этой командой не пользуемся, так как сборку html страниц не добавили.
Режим построения проекта создает или переписывает файлы в папке dist. Но во время разработки проекта при разных сборках файлы могут переименовываться, удаляться. И Webpack не будет следить, чтобы уже ненужные файлы, оставшиеся после предыдущих сборок, удалялись из папки dist. Поэтому добавим еще один пакет clean-webpack-plugin, который будет очищать папку dist перед каждой сборкой проекта.
Update 2018.04.11. Пришлось отказаться от clean-webpack-plugin. Почему? Когда запускаешь сервер через команду npm run start (webpack-dev-server --mode development --open), то webpack компилирует файлы автоматом, не сохраняя их в папку dist. И это нормально. Но при этом папка dist очищается из-за наличия clean-webpack-plugin. В результате в режиме работы локального сервера папка dist пустует, что негативно сказывается на работе с git (только в случае, если вы в git репозиторий сохраняется сборку проекта, как и я): после каждого запуска сервера появляется куча изменений из-за удаленных файлов. Было бы хорошо, чтобы очистка папки dist происходила только при полноценной сборке, например, npm run build-and-beautify (об этой команде ниже). Плагин clean-webpack-pluginнастроить нужным способом не смог. Поэтому использую другой плагин del-cli, который не связан с webpack и работает отдельно.
npm install del-cli --save-dev
Внесем изменения в файл package.json.
{ ... "scripts": { ... "clear": "del-cli dist" }, ... }
Сборка CSS файла
CSS файл будем собирать из SCSS файлов, под которые у нас зарезервирована папка src/scss. В ней создадим файл style.scss, например, со следующим содержимым:
$font-stack: -apple-system, BlinkMacSystemFont,Roboto,'Open Sans','Helvetica Neue',sans-serif; @import "~bootstrap/scss/bootstrap"; @font-face { font-family: 'Roboto'; font-style: normal; font-weight: 400; src: url(../fonts/Roboto-Regular.ttf); } body { font-family: $font-stack; #logo { width: 10rem; } .container { img { width: 20rem; } } }
Обратите внимание на то, что стили Bootstrap подключаем не через его CSS файл, а через SСSS (@import "node_modules/bootstrap/scss/bootstrap"@import "~bootstrap/scss/bootstrap";), который позволит в случае надобности переписать те или иные свойства библиотеки, использовать его миксины и др. Но что печалит. Если при сборке js файла при подключении js файла Bootstrap библиотеки Webpack знает, где находятся нужные файлы, то при подключении стилей нужно указывать путь к папке в node_modules.
Для обработки css файлов нам будут нужны следующие модули: node-sass, sass-loader, css-loader и extract-text-webpack-plugin (говорят, что в следующей версии Webpack в последнем плагине надобность отпадет).
Важно! На момент написания статьи плагин extract-text-webpack-plugin в стабильной версии не умеет работать с Webpack 4. Поэтому нужно устанавливать его beta версию через @next:
npm install node-sass sass-loader css-loader extract-text-webpack-plugin@next --save-dev
Надеюсь, что вскоре можно будет устанавливать все плагины по нормальному:
npm install node-sass sass-loader css-loader extract-text-webpack-plugin --save-dev
В webpack.config.js добавим следующие изменения:
... const ExtractTextPlugin = require("extract-text-webpack-plugin"); ... module.exports = { entry: [ ... './src/scss/style.scss' ], ... module: { rules: [{ ... { test: /\.(sass|scss)$/, include: path.resolve(__dirname, 'src/scss'), use: ExtractTextPlugin.extract({ use: [{ loader: "css-loader", options: { sourceMap: true, minimize: true, url: false } }, { loader: "sass-loader", options: { sourceMap: true } } ] }) }, ] }, plugins: [ new ExtractTextPlugin({ filename: './css/style.bundle.css', allChunks: true, }), ... ] };
Обратите внимание на то, что в точках входа entryмы добавили новый входной файл style.scss, но выходной файл указали не в output, а в вызове плагина ExtractTextPlugin в разделе plugins. Включаем поддержку карт источников sourceMap для пакетов sass-loader и css-loader.
Также можно заметить, что тут нет пакета style-loader, который чаще всего упоминается при работе с css в Webpack. Данный пакет встраивает css код в файл HTML, что может быть удобно для одностраничных приложений, но никак не для многостраничного.
И самый спорный момент. Для пакета css-loader мы добавили параметр url, равный false. Зачем? По умолчанию url=true, и если Webpack при сборке css находит ссылки на внешние файлы: фоновые изображения, шрифты (например, в нашем случае есть ссылка на файл шрифта url(../fonts/Roboto-Regular.ttf)), то он эти файлы попросит как-то обработать. Для этого используют чаще всего пакеты file-loader (копирует файлы в папку сборки) или url-loader (маленькие файлы пытается встроить в HTML код). При этом прописанные относительные пути к файлам в собранном css могут быть изменены.
Но с какой проблемой столкнулся на практике. Есть у меня папка src/scss с SСSS кодом. Есть папка src/img с картинками, на которые ссылаются в SСSS коде. Всё хорошо. Но, например, мне потребовалось подключить на сайт стороннюю библиотеку (например, lightgallery). SCSS код у неё располагается в папке node_modules/lightgallery/src/sass, который ссылается на картинки из папки node_modules/lightgallery/src/img через относительные пути. И если добавить стили библиотеки в наш style.scss, то file-loader будет искать картинки библиотеки lightgallery в моей папке src/img, а не там, где они находятся. И побороть я это не смог.
Update. С последней проблемой можно справиться, как подсказал Odrin, с помощью пакета resolve-url-loader и file-loader.
... module.exports = { ... module: { rules: [ ... { test: /\.(png|jpg|gif)$/, use: [ { loader: 'file-loader', options: {name: 'img/[name].[ext]'} } ] }, { test: /\.(sass|scss)$/, include: path.resolve(__dirname, 'src/scss'), use: ExtractTextPlugin.extract({ use: [{ loader: "css-loader", options: { sourceMap: true, minimize: true//, //url: false } }, { loader: "resolve-url-loader" }, { loader: "sass-loader", options: { sourceMap: true } } ] }) } ... ] }, ... };
То есть пакет resolve-url-loader вместо относительных путей ставит пути, которые webpack поймет. А уже file-loader будет копировать нужные файлы. Проблема в свойстве name в file-loader. Если его указать как name: '[path]/[name].[ext]', то в моей примере в папке dist появится папка dist\node_modules\lightgallery\src\img, в которой уже находятся изображения. Нет, в css будут прописаные верные пути до этой папки, но это будет не красиво. Поэтому лучше название файла указывать без пути (например name: 'img/[name].[ext]'). Правда, тогда все картинки пойдут в одну папку — не всегда это будет полезно.
Поэтому установкой url=false говорим, что все ссылки на файлы в SCSS коде не трогаем, пути не меняем, никакие файлы не копируем и не встраиваем: с ними разберемся потом отдельно. Возможно, это решение плохое, и вы предложите более правильный подход.
Сборка HTML страниц
Перейдем к самому веселому: к сборке HTML страниц, где у меня возникли самые большие трудности.
Для сборки HTML страниц будем использовать плагин html-webpack-plugin, который поддерживает различные виды шаблонизаторов. Также нам потребуются пакет raw-loader.
npm install html-webpack-plugin raw-loader --save-dev
В качестве шаблонизатора HTML будем использовать шаблонизатор по умолчанию lodash. Вот так будет выглядеть типичная HTML страница до сборки:
<% var data = { title: "Заголовок | Проект", author: "Harrix" }; %> <%= _.template(require('./../includes/header.html'))(data) %> <p>text</p> <%= _.template(require('./../includes/footer.html'))(data) %>
Вначале в переменной data прописываем все наши переменные страницы, которые хотим использовать на этой странице. Потом встраиваем шаблоны шапки и футера через _.template(require()).
Важное уточнение. В статьях про сборку HTML страниц через html-webpack-plugin обычно подключают встраиваемые шаблоны просто через команду:
require('html-loader!./../includes/header.html')
Но при этом в этих встраиваемых шаблонах синтаксис lodash работать не будет (я так и не понял, почему так происходит). И данные из переменной data туда не передадутся. Поэтому принудительно говорим webpack, что мы встраиваем именно шаблон, который надо обработать как lodash шаблон.
Теперь мы можем использовать полноценные lodash синтаксис в встраиваемых шаблонах. В коде файла header.html ниже через <%=title%> печатаем заголовок статьи.
<!doctype html> <html lang="ru"> <head> <meta charset="utf-8"> <meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no"> <link rel="shortcut icon" href="favicon/favicon.ico"> <link rel="stylesheet" href="css/style.bundle.css"> <title><%=title%></title> </head> <body> <header><img src="img/logo.svg" id="logo"></header>
В пакете html-webpack-plugin есть возможность генерировать несколько HTML страниц:
plugins: [ new HtmlWebpackPlugin(), // Generates default index.html new HtmlWebpackPlugin({ // Also generate a test.html filename: 'test.html', template: 'src/assets/test.html' }) ]
Но прописывать для каждой страницы создание своего экземпляра плагина точно не есть хорошо. Поэтому автоматизируем этот процесс, найдя все HTML файлы в папке src/html/views и создадим для них свои версии new HtmlWebpackPlugin().
Для этого в файле webpack.config.js внесем следующие изменения:
... const HtmlWebpackPlugin = require('html-webpack-plugin'); const fs = require('fs') function generateHtmlPlugins(templateDir) { const templateFiles = fs.readdirSync(path.resolve(__dirname, templateDir)); return templateFiles.map(item => { const parts = item.split('.'); const name = parts[0]; const extension = parts[1]; return new HtmlWebpackPlugin({ filename: `${name}.html`, template: path.resolve(__dirname, `${templateDir}/${name}.${extension}`), inject: false, }) }) } const htmlPlugins = generateHtmlPlugins('./src/html/views') module.exports = { module: { ... { test: /\.html$/, include: path.resolve(__dirname, 'src/html/includes'), use: ['raw-loader'] }, ] }, plugins: [ ... ].concat(htmlPlugins) };
Функция generateHtmlPlugins будет осуществлять поиск всех HTML страниц. Обратите внимание, что в коде функции есть настройка inject: false, которая говорит Webpack, что не нужно встраивать ссылки на js и css файл в HTML код самостоятельно: мы сделаем всё сами вручную в шаблонах header.html и footer.html.
Также нужно отметить, что встраиваемые шаблоны обрабатываются плагином raw-loader (содержимое файла просто загрузить как текст), а не html-loader, как чаще всего предлагают. И также, как в случае с CSS, не использую пакеты file-loader или url-loader.
И остается последний необязательный момент для работы с HTML. JavaScript файл и CSS файл у нас будут минимифицроваться. А вот HTML файлы хочу, наоборот, сделать красивыми и не минифицировать. Поэтому после сборки всех HTML файлов хочется пройтись по ним каким-то beautify плагином. И тут меня ждала подстава: не нашел способа как это сделать в Webpack. Проблема в том, что обработать файлы нужно после того, как будут вставлены встраиваемые шаблоны.
Нашел пакет html-cli, который может это сделать независимо от Webpack. Но у него 38 установок в месяц. То есть это означает два варианта: либо никому не нужно приводить к красивому внешнему виду HTML файлы, либо есть другое популярное решение, о котором я не знаю. А ради только одной этой функции Gulp прикручивать не хочется.
Устанавливаем этот плагин:
npm install html-cli --save-dev
И в файле package.json прописываем еще два скрипта, которые после работы Webpack будут приводить к красивому внешнему виду HTML файлы с установкой табуляции в два пробела.
"scripts": { "build-and-beautify": "del-cli dist && webpack --mode production && html dist/*.html --indent-size 2", "beautify": "html dist/*.html --indent-size 2" },
Update 2018.04.11 Обратите внимание на то, что в команду build-and-beautify я добавил еще del-cli dist, который очищает папку dist перед сборкой.
Поэтому для итоговой сборки рекомендую использовать не команду *npm run build, а команду npm run build-and-beautify.
Копирование оставшихся файлов
Мы сгенерировали js, css файлы, HTML страницы. Остались файлы изображений, шрифтов и др., которые мы не трогали и сознательно не копировали через file-loader или url-loader. Поэтому скопируем все оставшиеся папки через плагин copy-webpack-plugin:
npm install copy-webpack-plugin --save-dev
В файле webpack.config.js внесем изменения:
... const CopyWebpackPlugin= require('copy-webpack-plugin'); ... module.exports = { ... plugins: [ ... new CopyWebpackPlugin([{ from: './src/fonts', to: './fonts' }, { from: './src/favicon', to: './favicon' }, { from: './src/img', to: './img' }, { from: './src/uploads', to: './uploads' } ]), ]... };
Всё. Теперь командой npm run build-and-beautify собираем проект и в папке dist появится собранный статический сайт.
Итоговые файлы
{ "name": "static-site-webpack-habr", "version": "1.0.0", "description": "HTML template", "main": "src/index.js", "scripts": { "dev": "webpack --mode development", "build": "webpack --mode production", "build-and-beautify": "del-cli dist && webpack --mode production && html dist/*.html --indent-size 2", "watch": "webpack --mode development --watch", "start": "webpack-dev-server --mode development --open", "beautify": "html dist/*.html --indent-size 2", "clear": "del-cli dist" }, "dependencies": { "bootstrap": "^4.1.0", "jquery": "^3.3.1", "popper.js": "^1.14.3" }, "devDependencies": { "babel-core": "^6.26.0", "babel-loader": "^7.1.3", "babel-preset-env": "^1.6.1", "copy-webpack-plugin": "^4.5.0", "css-loader": "^0.28.11", "del-cli": "^1.1.0", "extract-text-webpack-plugin": "^4.0.0-beta.0", "html-cli": "^1.0.0", "html-webpack-plugin": "^3.2.0", "node-sass": "^4.8.3", "raw-loader": "^0.5.1", "sass-loader": "^6.0.6", "webpack": "^4.5.0", "webpack-cli": "^2.0.14", "webpack-dev-server": "^3.1.3" } }
const path = require('path'); const ExtractTextPlugin = require("extract-text-webpack-plugin"); const CopyWebpackPlugin = require('copy-webpack-plugin'); const HtmlWebpackPlugin = require('html-webpack-plugin'); const fs = require('fs') function generateHtmlPlugins(templateDir) { const templateFiles = fs.readdirSync(path.resolve(__dirname, templateDir)); return templateFiles.map(item => { const parts = item.split('.'); const name = parts[0]; const extension = parts[1]; return new HtmlWebpackPlugin({ filename: `${name}.html`, template: path.resolve(__dirname, `${templateDir}/${name}.${extension}`), inject: false, }) }) } const htmlPlugins = generateHtmlPlugins('./src/html/views'); module.exports = { entry: [ './src/js/index.js', './src/scss/style.scss' ], output: { filename: './js/bundle.js' }, devtool: "source-map", module: { rules: [{ test: /\.js$/, include: path.resolve(__dirname, 'src/js'), use: { loader: 'babel-loader', options: { presets: 'env' } } }, { test: /\.(sass|scss)$/, include: path.resolve(__dirname, 'src/scss'), use: ExtractTextPlugin.extract({ use: [{ loader: "css-loader", options: { sourceMap: true, minimize: true, url: false } }, { loader: "sass-loader", options: { sourceMap: true } } ] }) }, { test: /\.html$/, include: path.resolve(__dirname, 'src/html/includes'), use: ['raw-loader'] }, ] }, plugins: [ new ExtractTextPlugin({ filename: './css/style.bundle.css', allChunks: true, }), new CopyWebpackPlugin([{ from: './src/fonts', to: './fonts' }, { from: './src/favicon', to: './favicon' }, { from: './src/img', to: './img' }, { from: './src/uploads', to: './uploads' } ]), ].concat(htmlPlugins) };
<% var data = { title: "Заголовок | Проект", author: "Harrix" }; %> <%= _.template(require('./../includes/header.html'))(data) %> <div class="container"> <p>Первая страница.</p> <p><img src="uploads/test.jpg"></p> </div> <%= _.template(require('./../includes/footer.html'))(data) %>
<!doctype html> <html lang="ru"> <head> <meta charset="utf-8"> <meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no"> <link rel="shortcut icon" href="favicon/favicon.ico"> <link rel="stylesheet" href="css/style.bundle.css"> <title><%=title%></title> </head> <body> <header><img src="img/logo.svg" id="logo"></header>
<footer><%=author%></footer> <script src="js/bundle.js"></script> </body> </html>
<!doctype html> <html lang="ru"> <head> <meta charset="utf-8"> <meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no"> <link rel="shortcut icon" href="favicon/favicon.ico"> <link rel="stylesheet" href="css/style.bundle.css"> <title>Заголовок | Проект</title> </head> <body> <header><img src="img/logo.svg" id="logo"></header> <div class="container"> <p>Первая страница.</p> <p><img src="uploads/test.jpg"></p> </div> <footer>Harrix</footer> <script src="js/bundle.js"></script> </body> </html>
Исходники
Ссылка на репозиторий с рассмотренным проектом.

