Designing Schemaless, Uber Engineering’s Scalable Datastore Using MySQL
By Jakob Holdgaard Thomsen
January 12, 2016
https://eng.uber.com/schemaless-part-one/

Проектирование Schemaless хранилища данных Uber Engineering с использованием MySQL. Это первая часть из трех частей серии статей о Schemaless хранилище данных.
В Project Mezzanine мы описали, как мы перенесли данные о поездках Uber из одного экземпляра Postgres в Schemaless — наше высокопроизводительное и надежное хранилище данных. В этой статье описывается его архитектура, роль в инфраструктуре Uber и история проектирования.
Борьба за новую базу данных
В начале 2014 года у нас исчерпывались ресурсы базы данных из-за увеличения количества поездок. Каждый новый город, каждая новая поездка вели нас к пропасти, пока однажды мы не поняли, что инфраструктура Uber не сможет функционировать к концу года — мы просто не могли хранить достаточное количество данных о поездках с помощью Postgres. Наша задача состояла в том, чтобы изменить технологии баз данных в Uber, задача, которая заняла много месяцев, и к решению которой мы привлекли большое коичество инженеров из наших офисов по всему миру.
Но постойте, зачем строить масштабируемое хранилище данных, когда существует множество коммерческих решений и решений с открытым исходным кодом? У нас было пять ключевых требований к нашему новому хранилищу данных:
Наше хранилище данных должно было иметь возможность линейно наращивать емкость, добавлением новых серверов, чего не хватало в нашей установке Postgres. Добавление новых серверов должно как увеличивать доступное дисковое пространство, так и уменьшать время отклика системы.
Нам нужна высокая доступность хранилища данных при записи. Ранее мы реализовали простой буферный механизм с Redis, поэтому, если запись в Postgres прошла со сбоем, мы могли повторить попытку позже, так как поездка была сохранена в Redis. В тот промежуток времени, когда запись была сохранена в Redis и еще не была сохранена в Postgres, мы теряли функциональность, такую как выставление счетов. Досадно, но, по крайней мере, мы не потеряли поездку! Со временем Uber вырос, а наше решение на основе Redis не масштабируемо. Schemaless хранилище данных должно было поддерживать механизм, аналогичный нашему решению с Redis, но обеспечивать read-your-write consistency.
Нам нужен способ обмена сообщениями с зависимыми компонентами. В работающей на тот момент системе, мы работали с зависимыми компонентами последовательно в рамках одного процесса (например, биллинг, аналитика и т. д.). Это был процесс, подверженный ошибкам: если какой-либо шаг процесса не удавался, нам приходилось повторять попытку с самого начала, даже если некоторые шаги процесса были успешными. Это не масштабировалось, поэтому мы хотели разбить процессы на изолированные подчиненные процессы, которые запускались бы в ответ на изменение данных. У нас уже была асинхронная система сообщений, основанная на Kafka 0.7. Но мы не смогли запустить ее без потери данных, поэтому мы приветствовали бы новую систему, которая имела нечто подобное, но могла работать без потери данных.
Нам нужны вторичные индексы. Мы отходили от Postgres, однако, новое хранилище данных должно было поддерживать индексы на уровне Postgres, что позволило бы так же эффективно выполнять поиск по вторичным индексам.
Нам нужна абсолютно надежная система, так как она содержит критически важные данные о поездке. Если в 3 часа утра нам скажут, что наше хранилище данных не отвечает на запросы и наш бизнес разрушен, будет ли у нас оперативная информация, чтобы быстро его восстановить?
В свете вышеизложенного мы проанализировали преимущества и потенциальные ограничения некоторых альтернативных широко используемых систем, таких как Cassandra, Riak, MongoDB и т. д. В целях иллюстрации ниже приведена диаграмма, показывающая различные комбинации возможностей различных систем (прим. в таблице автор не приводит наименования конкретных продуктов):
| Линейная расширяемость | Доступность для записи | Обмен сообщениями | Вторичные индексы | Надежность | |
| Продукт 1 | ✓ | ✓ | ✗ | (✓) | ✗ |
| Продукт 2 | ✓ | ✓ | ✗ | (✓) | (✓) |
| Продукт 3 | ✓ | ✗ | ✗ | (✓) | ✗ |
В то время как все три системы линейно расширяемы добавлением новых серверов, только две из них имеют высокую доступность при записи. Ни одно из решений не реализует из коробки обмен сообщениями, поэтому нам пришлось бы реализовывать его на уровне приложения. Все они имеют индексы, но если вы собираетесь индексировать множество разных значений, запросы становятся медленными, так как они используют команду scatter-gather для опроса всех узлов (шардов).
Наконец, наше решение в конечном итоге определялось надежностью, поскольку мы должны хранить критически важные для работы бизнеса данные о поездке. Некоторые существующие решения могут надежно функционировать в теории. Но есть ли у нас оперативные знания для немедленной реализации их самых полных возможностей? Ведь многое зависит не только от технологии, которую мы используем, но и от тех людей, которые были в нашей команде.
Следует отметить, что, поскольку мы рассматривали эти варианты более двух лет назад и обнаружили, что ни один из них не применим в случае использования хранилища данных о поездках, мы с успехом применили как Cassandra, так и Riak в других областях нашей инфраструктуры, и мы используем их в производстве для обслуживания миллионов пользователей.
В Schemaless мы надежны
Поскольку ни один из вышеперечисленных вариантов не соответствовал нашим требованиям в соответствии с временными рамками, которые мы имели, мы решили создать свою собственную систему, максимально упрощенную для работы, применяя уроки масштабирования, полученные от других. Дизайн вдохновлен Friendfeed, и акцент делался на операционную сторону, вдохновленную Pinteres.
Мы пришли к выводу, о необходимости проектирования хранилища типа key-value, которое позволяет сохранять любые данные JSON без строгой проверки схемы (отсюда и название schemaless). Оно было реализовано на MySQL сервере, распределенном на шарды, с буферизацией записи для обеспечения отказоустойчивости, и publish-subscribe обмен сообщениями об изменении данных, который основан на вызове триггеров. Наконец, Schemaless хранилище данных поддерживает глобальные индексы.
Модель данных Schemaless
Schemaless — это append-only разреженная трехмерная hash map, похожая на Google’s Bigtable. Самый маленький объект данных в Schemaless называется ячейкой и неизменен. После записи он не может быть изменен или удален. Ячейка является объектом JSON (BLOB), доступ к которому можно получить при помощи ключа строки, имени столбца и ссылочного ключа, называемого ref key. Ключ строки — это UUID, имя столбца — это строка, а ссылочный ключ — целое число.
Вы можете представить ключ строки в качестве первичного ключа в реляционной базе данных и имя столбца в виде столбца реляционной базы данных. Однако в Schemaless нет предопределенной или принудительной схемы, и для строк не предопределены имена столбцов. Фактически, имена столбцов полностью определяются приложением. Ссылочный ключ ref key используется для версионирования ячеек. Поэтому, если ячейку необходимо обновить, вы должны написать новую ячейку с более высоким ключом ref key (последняя ячейка имеет самой высокий ref key). Ключ ref key также можно использовать как индекс в массиве, но обычно он используется для версионирования. Способ использования ref key определяется приложением.
Обычно приложения группируют связанные данные в один и тот же столбец, и все ячейки в каждом столбце имеют примерно одну и ту же схему на стороне приложения. Эта группировка — отличный способ объединить данные, которые меняются вместе, и позволяет приложению быстро изменять схему без простоя на стороне базы данных. Ниже приведен пример этого.
Пример: Хранение данных о поезке Schemaless
Прежде чем мы погрузимся в то, как мы моделируем поездку в Schemaless, давайте посмотрим на анатомию поездки в Uber. Данные о поездке генерируются в разные моменты времени, например: окончание поездки, оплата поездки, и эти различные части информации поступают асинхронно. Диаграмма ниже представляет собой упрощенный поток, когда происходят разные части поездки Uber:

На диаграмме показана упрощенная версия нашего потока событий. * обозначает части, которые являются необязательными и могут присутствовать несколько раз.
Поездка связывается водителем, который выполняет заказ клиента, и имеет отметку времени для его начала и конца. Эта информация представляет собой базовую (расчетную) поездку, и из этого мы вычисляем стоимость поездки (тариф), которая является тарифом для клиента. После окончания поездки нам, возможно, придется скорректировать тариф. Мы можем добавить к поездке примечания, учитывая отзывы от клиента или от водителя (отмечено звездочкой на диаграмме выше). Или, возможно, клиенту придется сделать несколько попыток оплатить поездку платежной картой, если одна из его карт заблокирована. Поток событий в Uber — это процесс, управляемый данными. По мере того, как данные становятся доступными или добавляются в ходе поездки, будет выполняться определенный набор процессов. Некоторая информация, такая как оценка качества выполнения услуги (считается частью заметок на приведенной выше диаграмме), может наступить через несколько дней после завершения поездки.
Итак, как мы сопоставляем приведенную выше модель поездки с Schemaless?
Модель данных поездки
Будем использовать курсив для обозначения UUID и заглавные буквы для обозначения имен столбцов, в таблице ниже показана модель данных для упрощенной версии нашего хранилища поездок. У нас есть две поездки (UUIDs trip_uuid1 и trip_uuid2) и четыре столбца (BASE, STATUS, NOTES и FARE ADJUSTMENT). Каждая ячейка представлена блоком с числом и объектом JSON (сокращенно {...}). Блоки показаны с наложением для представления версионности.
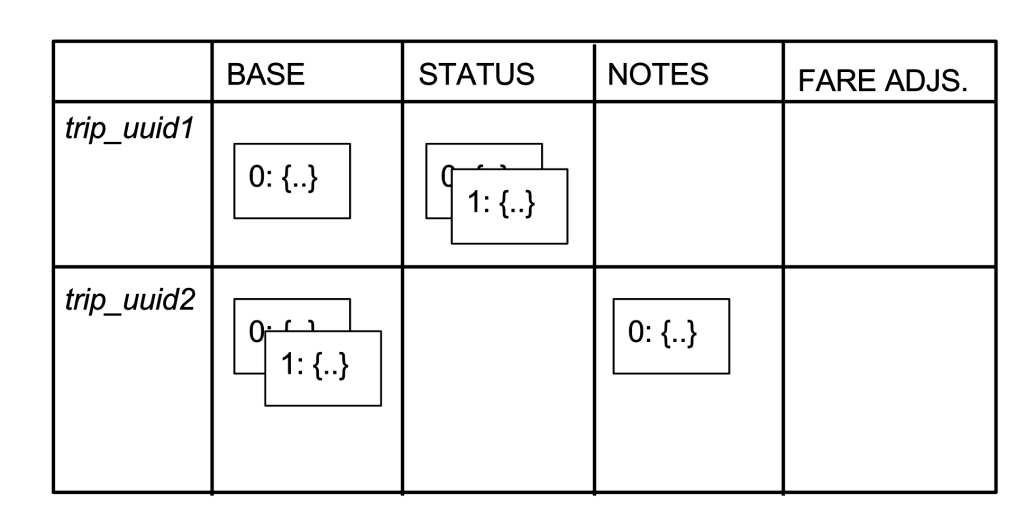
trip_uuid1 имеет три ячейки: одну в столбце BASE, две в столбце STATUS и ни одной в столбце FARE ADJUSTMENTs. trip_uuid2 имеет две ячейки в столбце BASE, одну в столбце NOTES, а также в столбце FARE ADJUSTMENTS. Для Schemaless столбцы не отличаются; поэтому семантика столбцов определяется приложением, которое в этом случае является сервисом Mezzanine.
В Mezzanine ячейки базы BASE содержат базовую информацию о поездке, такую как UUID водителя и время поездки. Столбец STATUS содержит текущий статус оплаты поездки, в который мы вставляем новую ячейку для каждой попытки выставить счет. (Попытка не удалась, если у кредитной карты не было достаточных средств или карточка заблокирована). Столбец NOTES содержит ячейку, если есть заметки, которые оставил водитель или диспетчер. Наконец, столбец FARE ADJUSTMENTs содержит ячейки, если тариф за поездки был скорректирован.
Мы используем такую структуру столбцов, чтобы избежать состояние гонки и минимизировать объем данных, которые необходимо записать при обновлении. Столбец BASE записывается, когда поездка завершена, и, как правило, только один раз. Столбец STATUS записывается, когда мы пытаемся оплатить поездку, которая происходит после записи данных в столбце BASE и может произойти несколько раз, если был сбой при оплате счета. Столбец NOTES также может быть написан несколько раз в некоторый момент после записи BASE, но он полностью отделен от записи столбца STATUS. Аналогично, столбец FARE ADJUSTMENTS записывается только в том случае, если тариф за проезд изменен, например, из-за неэффективного маршрута.
Сквозные триггеры
Ключевой особенностью Schemaless являются триггеры, которые позволяют получать уведомления об изменениях в экземпляре Schemaless. Поскольку ячейки неизменяемы и добавляются новые версии, каждая ячейка также представляет собой изменение или версию, позволяя значениям в экземпляре рассматриваться как журнал изменений. Для данного экземпляра можно прослушивать эти изменения и запускать на них функции, очень похожие на шины сообщений, такую как Kafka.
Schemaless триггеры делают Schemaless надежным источником данных, потому что, помимо прямого доступа к данным, система сообщений может использовать функцию триггера для мониторинга и запуска любого прикладного кода (аналогичная система — DataBus от LinkedIn), разделяя процессы создания данных и их обработку.
Среди других вариантов использования, Uber использует триггеры Schemaless для выставления счета, когда столбец BASE записывается в экземпляр Mezzanine. В приведенном выше примере, когда написан столбец BASE для trip_uuid1, наша биллинговая служба, которая запускается в столбце BASE, выбирает эту ячейку и будет пытаться провести оплату поездки, через платежную карту. Результат оплаты через платежную карту, будь то успех или неудача, записывается в Mezzanine в столбце STATUS. Таким образом, биллинговая служба отделена от создания поездки, а Schemaless выступает в качестве асинхронной шины сообщений.

Индексы для удобного доступа
Наконец, Schemaless поддерживает индексы, определенные по полям в объектах JSON. Индекс запрашивается через эти предопределенные поля, чтобы найти ячейки, которые соответствуют параметрам запроса. Запрос этих индексов эффективен, потому что для запроса индекса требуется обращение только к одному шарду, чтобы найти набор ячеек для возврата. Фактически, запросы могут быть дополнительно оптимизированы, поскольку Schemaless позволяет денормализовать данные ячейки, записав их непосредственно в индекс. Наличие денормализованных данных в индексе означает, что для запроса индекса требуется только один шард для запроса индекса и получения информации. Фактически, мы обычно рекомендуем пользователям Schemaless денормализовать часто запрашиваемые данные, в индексы, в дополнение к тому, чтобы получить ячейку непосредственно через ключ строки.
В качестве примера для Mezzanine у нас есть индекс, который позволяет нам находить поездки заданного водителя. Также мы денормализовали время создания поездки и город, где была проведена поездка. Это позволяет находить все поездки для водителя в городе за определенный промежуток времени. Ниже мы приводим определение индекса driver_partner_index в формате YAML, который является частью хранилища данных поездок и определен над столбцом BASE (пример аннотируется комментариями с использованием стандартного #).
table: driver_partner_index # Name of the index.
datastore: trips # Name of the associated datastore
column_defs:
– column_key: BASE # From which column to fetch from.
fields: # The fields in the cell to denormalize
– { field: driver_partner_uuid, type: UUID}
– { field: city_uuid, type: UUID}
– { field: trip_created_at, type: datetime}
Используя этот индекс, мы можем найти поездки для данного driver_partner_uuid, отфильтрованные по city_uuid, и/или trip_created_at. В этом примере мы используем только поля из столбца BASE, но Schemaless поддерживает денормализацию данных из нескольких столбцов, что будет содержать несколько записей в приведенном выше списке column_def.
Как упоминалось, у Schemaless есть эффективные индексы, реализованные путем шардирования индексов на основе шардированного поля. Поэтому единственным требованием для шардированного индекса является то, что одно из полей в индексе обозначается как шардированное поле (в приведенном выше примере это будет driver_partner_uuid, поскольку он является первым заданным). Шардированное поле определяет, какой шард должен записывать или читать индекс. Для этого нам и нужно определять шардированное поле при запросе индекса. Это означает, что во время запроса нам нужно запросить всего один шард для извлечения записей индекса. Важное требование к шардированному полю состоит в том, что оно должно обеспечивать хорошее распределение данных по шардам. Наилучшим образом подходят UUID, идентификаторы города являются менее предпочтительными, а поля статусов (перечисления) принесут скорее вред, чем пользу.
За исключением шардированных полей, Schemaless поддерживает запросы на равенство, неравенство и диапазон запросов для фильтрации, а также поддерживает выбор только подмножества полей в индексе и извлечение определенных или всех столбцов для ключа строки, на который указывают записи индекса. В настоящее время шардированное поле должно быть неизмеяемым, что позволяет Schemaless однозанвчно определить шард на котором расположены данные. Но мы изучаем, как сделать его изменяемым без издержек производительности.
Наши индексы согласованы в конечном счете (eventually consistent). Всякий раз, когда мы пишем данные в ячейку, мы также обновляем записи индекса, но это не происходит в одной транзакции. Ячейки и записи индекса обычно не относятся к одному и тому же шарду. Поэтому, если бы мы реализовывали согласованные индексы, нам нужно было бы ввести двухфазный коммит при записи, что повлекло бы значительные накладные расходы. В результате с eventually consistent индексами мы избегаем накладных расходов, но пользователи Schemaless могут видеть устаревшие данные в индексах. Большую часть времени отставание значительно ниже 20 мс между изменениями ячеек и соответствующими изменениями индекса.
Резюме
Мы представили обзор модели данных, триггеров и индексов, которые являются ключевыми функциями, которые определяют Schemaless — основной компонент нашего механизма хранения данных о поездке. В будущих сообщениях мы рассмотрим еще несколько функций Schemaless, чтобы проиллюстрировать, как он стал добрым помощником в инфраструктуре Uber: больше об архитектуре, использовании MySQL в качестве шарда и о том, как мы обрабатываем ошибки обеспечивая надежность работы мобильного приложения.
Часть 2: Архитектура схемы
Часть 3: Использование триггеров в Schemaless
Jakob Thomsen is a software engineer and tech lead on the Schemaless project and works at the Uber Engineering office in Aarhus, Denmark. See our talk at Facebook’s second annual @Scale conference in September 2015 for more info on Schemaless.
Photo Credits for Header: “anim1069” by NOAA Photo Library licensed under CC-BY 2.0. Image cropped for header dimensions and color corrected.
Header Explanation: Since Schemaless is built using MySQL, we introduce the series using a dolphin striking a similar pose but with opposite orientation to the MySQL logo.
