Многие знают Минко Гечева (rhyme.com) по книге «Switching to Angular» и по тексту «Angular Performance-Checklist», помогающему Angular-разработчикам оптимизировать свои проекты. На нашей декабрьской конференции HolyJS 2017 Moscow он тоже развивал тему Angular-производительности, выступив с докладом «Faster Angular applications». А теперь на основе этого выступления мы подготовили хабрапост, переведя все на русский. Добро пожаловать под кат! А если предпочитаете англоязычную видеозапись выступления, прилагаем и ее тоже:
Сегодня мы поговорим о производительности во время исполнения. В случае с одностраничными приложениями обычно речь идет либо о сетевой производительности, либо производительности в рантайме.
В первом случае обычно пытаются сократить количество HTTP-запросов или передаваемых по сети данных. В этом направлении есть много исследований. Например, над этим бьется коллектив Google Closure Compiler, достигая цели более эффективным удалением неиспользуемого кода и минификацией кода. Также у нас есть различные алгоритмы сжатия, и в команде webpack тоже ставят подобные цели. Наконец, в Angular CLI пытаются совместить лучшее из разных подходов и дают очень хорошо инкапсулированные сборки.
Однако в том, что касается производительности во время исполнения, развития немного. Здесь всё в наших собственных руках, нет сторонней «волшебной палочки», по мановению которой наше приложение станет работать быстрее. Есть несколько возможных подходов к проблеме, сегодня я расскажу о более общих решениях, зачастую применимых не только к Angular.
Чтобы проиллюстрировать эти решения, я написал «простое бизнес-приложение». В нем я попытался воспроизвести как можно больше проблем с производительностью, которые я встретил на протяжении последних месяцев. В итоге получился совершенно жуткий продукт, который мы попытаемся как-то улучшить.

В нашем максимально упрощенном приложении можно добавлять новых работников, представлять их в списке и рассчитывать для них некоторое значение. У нас будет два списка сотрудников: для отдела продаж и для R&D-отдела. В оба можно добавлять новые элементы. Уже имеющиеся элементы представлены в списке, где видно имя и некоторое числовое значение (предположим, это оценка работы сотрудника). Также есть поле ввода имени нового сотрудника. При добавлении сотрудника мы можем просто взять откуда-то число, высчитать что-то и отобразить все на экране.
Структура приложения состоит из AppComponent (охватывающего приложение целиком) и двух EmployeeListComponent (по одному на каждый список).
Вот шаблон EmployeeListComponent:

Здесь обратите внимание на элемент input. В нем используется синтаксис формата «ящик с бананами» (вначале квадратные скобки, затем круглые), чтобы установить двустороннюю привязку данных между свойством label, объявленном в контроллере EmployeeListComponent, и текстовым полем.
Кроме того, в EmployeeListComponent происходит итерация по списку сотрудников в массиве данных, и для каждого сотрудника создается элемент списка. Для каждого элемента мы отображаем имя сотрудника и рассчитываем числовое значение при помощи метода calculate(), определенного в классе EmployeeListComponent.
Теперь взглянем на сам этот класс:

Тут есть несколько важных вещей. Для начала, в нем не хранится состояние, он получает все необходимые данные (массив EmployeeData[]) на вход от родительского компонента. Таким образом, этот родительский компонент, AppComponent, выступает в роли Container Component в Redux.
Кроме того, в классе EmployeeListComponent есть метод calculate(), единственная задача которого — передать выполнение функции, вычисляющей числа Фибоначчи. На первый взгляд, числа Фибоначчи здесь неудобно использовать, однако у них есть ряд важных преимуществ. Во-первых, метод их расчета всем известен, нет необходимости объяснять сложную работу подходящей примеру функции. Можно было бы заменить на стандартное отклонение или еще что-то подобное.

Во-вторых, эту функцию можно реализовать крайне неэффективным образом, как мы это видим на экране. У нас есть два рекурсивных вызова, и для каждого числа Фибоначчи у нас будет происходить перерасчет всех предыдущих заново. Таким образом, здесь я искусственно замедлил работу приложения, чтобы был лучше виден эффект последующей оптимизации.
Итак, у нас есть приложение с компонентом самого приложения, и с двумя компонентами списков. Каждый из элементов в списке требует много вычислительной мощности.
Попробуем использовать в этом приложении некоторые реальные данные. У нас будет два списка, содержащие в общей сложности 140 элементов. В этом случае при вводе новых имен набор текста оказывается крайне замедлен. Вряд ли пользователям может понравиться такая работа приложения. Но почему настолько медленно? Профилировать эту проблему достаточно легко с помощью Chrome DevTools. Сделав это, мы выясняем, что наша функция расчета чисел Фибоначчи вызывается очень часто. Мы можем узнать точное количество вызовов, добавив в эту функцию логирование.

Оказывается, при каждом нажатии клавиши пользователем происходит перерасчет всего дерева компонентов по меньшей мере дважды (один раз при нажатии и один — при отпускании клавиши). Так что мы перерасчитываем все уже полученные ранее значения при каждом нажатии.
Вот как выглядит эта ситуация с точки зрения дерева компонентов. При каждом нажатии клавиши происходит изменение сначала в AppComponent. Поскольку обнаружение изменений в Angular работает как поиск в глубину, будет также вызвано обнаружение изменений в EmployeeListComponent, и затем в каждом из элементов работников. Для каждого из этих элементов будет пересчитано их числовое значение. Затем произойдет такой же обход второго EmployeeListComponent.
Всё это крайне неэффективно. Как правило, мы не хотим пересчитывать числовые значения для каждого элемента в массиве, такое мы хотели бы только при появлении нового массива. Вот если происходит передача нового массива из AppComponent в EmployeeListComponent, тогда можно высчитывать. Есть мысли, как это лучше всего сделать?
Например, можно использовать стратегию OnPush. Благодаря ей обнаружение изменений будет запускаться только при появлении новых входных данных у компонента. Когда Angular при проверке ссылок обнаруживает появление новых входных данных, в компонентах будет выполнено обнаружение изменений. То есть, если у нас есть дерево компонентов, когда корневой компонент получает новые данные, мы обновляем всю ветку, начиная с этого компонента. Мы чуть позже посмотрим, как это выглядит.
Обратимся за помощью к функциональному программированию и попробуем представить, что EmployeeListComponent — это функция. Входные данные для компонента — это входные аргументы функции, а изображение на экране — результат функции. Продемонстрирую свою мысль с помощью псевдокода.

В константе f мы сохраняем ссылку на EmployeeListComponent (теперь это функция), в константе data — входные аргументы (данные одного сотрудника).

Для начала осуществляем вызов функции с ее изначальными входными данными, и тут Angular выполнит обнаружение изменений. Поскольку до этого значением было undefined, сравнив data и undefined, Angular увидит изменение значения входных данных.

Но добавление нового элемента в список уже вызовет функцию с тем же аргументом, что и раньше: мы будем модифицировать структуру данных, на которую указывает та же константа data. Поэтому Angular не запустит обнаружение изменений.

Тем не менее, обнаружение изменений произойдет, если мы отправим во входном аргументе функции копию массива: там ссылка изменится.
Значит ли это, что каждый раз, когда нам необходимо обнаружение изменений, нам нужно копировать массив целиком? По нескольким причинам это было бы крайне неэффективно. Во-первых, это было бы крайне неоптимальное использование памяти. Для каждого обнаружения изменений нам нужно вначале выделить память под весь новый массив, а затем сборщику мусора нужно будет освободить ее. Во-вторых, это неэффективно с точки зрения вычислений. Временная сложность такого алгоритма по меньшей мере O(n).
В отношении обоих этих вещей разумнее будет воспользоваться чем-либо наподобие Immutable.js. Это набор различных неизменяемых структур данных с двумя очень важными свойствами.
Во-первых, мы не можем изменять ни одну уже существующую структуру данных. Вместо этого вызовы, которые должны были бы изменить такую структуру данных, получают новую ссылку на нее с уже примененными изменениями.
Во-вторых, мы не копируем структуру данных целиком: новый экземпляр этой структуры по возможности будет использовать элементы старой.

Вот какой рефакторинг нам надо провести. Во-первых, мы поменяли содержимое методов add() и remove(). В add() при выполнении процедуры unshift(), в которой элемент переводится в начало списка, мы получаем новый список. То же самое в методе remove(), вызов splice() возвращает нам новый список.
Кроме этих двух методов, нам необходимо поменять ссылку на список. Иначе мы не могли бы оповестить EmployeeListComponent, что входные данные поменялись. Таким образом, выходные значения add() и remove() должны быть присвоены свойству list в AppComponent.
Запустим приложение и посмотрим, насколько быстрее теперь все получилось. Мы же тут оптимизировали, должно было стать лучше… Хм, приложение работает по-прежнему очень медленно. Возможно, стало быстрее прежнего, но все равно впечатления у пользователя вряд ли будут хорошо.
Чтобы измерить, насколько быстрее стало работать приложение, я написал несколько сквозных тестов и запустил их на Angular Benchpress.

Благодаря ним мы видим, что приложение ускорило работу как минимум вдвое. Этого, однако, недостаточно. Причина неудовлетворительной работы в том, что при вводе текста по-прежнему запускается обнаружение изменений. Хорошая новость в том, что теперь оно запускается только в одном из двух списков, но даже в нем оно не нужно, поскольку ни одно из числовых значений не поменялось.
Посмотрим, как теперь выглядит работа приложения с точки зрения дерева компонентов. При каждом нажатии клавиши мы несколько раз вызываем обнаружение изменений в AppComponent, EmployeeListComponent, и в каждом из отдельных компонентов. При этом мы не делаем вызовов ко второму списку. Но почему вообще происходит обнаружение изменений, ведь не было обращений ни к одному из вызовов, изменяющих структуру данных списка?
Причина заключается в определенных характеристиках обнаружения изменений OnPush, не слишком хорошо задокументированных.

Суть в том, что обнаружение изменений OnPush запускается не только при смене входных данных, а еще и тогда, когда в соответствующем компоненте триггерится событие.
Зная эту особенность, мы теперь можем провести рефакторинг кода. В этом есть своя позитивная сторона, поскольку мы заодно сможем улучшить разделение ответственности в нашем приложении и сделать дерево компонентов стройнее. Сделаем в EmployeeListComponent два дочерних компонента: NameInputComponent и ListComponent.
Первый из них будет отвечать только за хранение текущего значения строки ввода и за вызов события. Во втором будет производится вычисление функции, и там будет использоваться обнаружение изменений OnPush.
После этих изменений в коде приложение стало работать значительно быстрее. Как именно осуществляется работа приложения теперь? К сожалению, при нажатии пользователем клавиши обнаружение изменений по-прежнему вызывается в AppComponent, и затем в обоих экземплярах EmployeeListComponent. Но на этот раз в дочерних компонентах EmployeeListComponent обнаружение изменений уже не вызывается. Дело в том, что у ListComponent используется обнаружение изменений OnPush, а событие происходит в области EmployeeListComponent, т. е. в родительском компоненте EmployeeList. Скорость печати увеличивается на несколько порядков.

Однако и этого нам недостаточно. Еще одна возможная оптимизация касается добавления элементов. При создании нового элемента мы вызываем операцию добавления к неизменяемому списку, поэтому создается новый список и передается на вход в EmployeeListComponent. Это вызывает обнаружение изменений. То есть при вводе текста теперь все быстро, но при добавлении элемента по-прежнему происходит ненужное повторное вычисление числового значения во всех этих компонентах.
Чтобы решить эту проблему, надо обратиться к нашей функции вычисления чисел Фибоначчи. Мы сегодня уже упоминали чистые функции, и это одна из них. Хорошая новость в том, что чистые функции встречаются и среди по-настоящему полезных в наших приложениях вещей, вроде вычисления стандартного отклонения.
У чистых функций есть два очень важных свойства. Во-первых, у них нет побочных эффектов, то есть не осуществляется никаких вызовов через сеть, не происходит логирования, и так далее. Во-вторых, повторный вызов функции с такими же аргументами дает идентичный результат. В мире функционального программирования это и получило название «pure function».
И это очень важная концепция. В Angular есть «чистые пайпы» (pure pipes) и «грязные пайпы» (impure pipes, т. е. пайпы с внутренним состоянием). Они, как правило, используются для обработки данных. Чистые пайпы обычно форматируют данные, пример «чистого» — DatePipe.
Грязные пайпы хранят внутри определенное состояние, как, например, AsyncPipe. Разница между этими двумя случаями в том, что Angular выполняет чистый пайп, только когда обнаруживает, что изменился его аргумент. Как правило, выражения с чистыми пайпами рассматриваются Angular как не имеющие побочных эффектов, референциально прозрачные. Это понятие из функционального программирования, чтобы лучше его понять, взглянем на код, созданный компилятором Angular для шаблона с чистыми и грязными пайпами.

Мы применяем к переменной birthday вначале чистый пайп date, а затем грязный impureDate. На экране показаны два разных результата. Поначалу тут сложно разобраться. Загадочные символы в начале выражения нас не интересуют, они нужны только для того, чтобы разработчики не пользовались этими импортами.
Важная для нас часть следует за ними. _ck() — это проверка, в ней текущее значение date будет сравнено с предыдущим, и, если значение отличается, будет вызван метод date.transform(). Если же изменений нет, будет возвращен предыдущий результат, хранящийся в кэше. В случае же с impureDate просто будет вызван метод impureDate.transform().
Таким образом, референциальная прозрачность означает, что семантика выражения никак не поменяется, если вместо этого выражения подставить его выходное значение. Побочные эффекты будут незначительны.

Основываясь на этом принципе, я инкапсулировал нашу функцию Фибоначчи в написанном мной классе CalculatePipe, просто делегировав вычисление функции fibonacci. Кроме того, нам нужно будет поменять шаблон. Вместо метода calculate мы в нем будем использовать пайп.
Теперь попробуем протестировать приложение: в Benchpress будет происходить многократное добавление и удаление нового пользователя. Видно, что приложение работает уже достаточно быстро. Производительность увеличилась на несколько порядков.

Хочу рассказать еще о двух оптимизациях. Первая касается эффективности рендеринга. Попробуем отобразить в нашем приложении 1000 элементов одновременно. В реальном приложении мы этого делать, конечно, не будем — для таких ситуаций существует виртуальная прокрутка или разбивка на страницы. Но здесь мы попробуем оптимизировать работу иначе.
Предположим, наше приложение уже оптимизировано разными способами. Удален неиспользуемый код, пакет весит 50 килобайт, мы скачиваем его за 100 миллисекунд. Но отрисовка изображения занимает по меньшей мере 8 секунд. Несмотря на то, что наша сетевая производительность отличная, пользователь по-прежнему останется недоволен.
Взглянем на наши данные. В них мы видим дублирующиеся значения. Существует по несколько экземпляров функции Фибоначчи с аргументами 27, 28 и 29.

Благодаря чистым пайпам у нас происходит некоторое кэширование, однако эти значения всё равно рассчитываются многократно. К счастью, все наши примеры находятся в небольшом промежутке. Можно попробовать сделать систему глобального кэширования. Чистые пайпы создают кэш только для отдельного выражения. Мы увидим, в чем разница между таким подходом и настоящим кэшированием при помощи мемоизации.
Мемоизация, которую мы будем использовать, возможна только для чистых функций. Её использование достаточно просто:

Через require('lodash.memoize') мы получаем функцию memoize, и затем вызываем ее. Она создаст необходимую нам функцию Фибоначчи. При каждом вызове этой созданной функции ее входной аргумент и результат будут записываться в таблицу соответствий. Больше нам ничего не понадобится. Мы видим, что теперь приложение отображается за 6.7 секунд, до этого эти операции заняли 9.5 секунд. Для такой небольшой оптимизации это неплохо.
Сравним чистые пайпы и мемоизацию. В первом случае, когда Angular обнаруживает, что мы пытаемся вызвать 27 | calculate, выполнение делегируется функции fibonacci(27). При дальнейшем обходе списка каждый раз, когда делается вызов 27 | calculate, будет выполнена та же операция, поскольку кэширование происходит только локальное.
Однако при следующем обнаружении изменений Angular не будет пересчитывать результат, если аргументы calculate не поменялись. Таким образом, для каждого следующего выполнения обнаружения изменений наша оптимизация будет работать.

В случае с мемоизацией все будет выглядеть несколько иначе. Вначале мы вызовем 27 | calculate, произойдет вычисление числа Фибоначчи, и в кэш будет записано число 27 и выходное значение функции Фибоначчи. При всех следующих вызовах 27 | calculate результат будет взят из кэша. Экономия времени очевидна.

Итак, начинают выявляться некоторые общие тенденции. С концептуальной точки зрения обнаружение изменений OnPush и мемоизация похожи. И там, и там мы имеем референциальную прозрачность. Если представить дерево компонентов как выражение, как абстрактное синтаксическое дерево, к нему также можно применить оптимизации, пользующиеся референциальной прозрачностью. Однако в обоих случаях работать это всё будет только с последними входными данными.
Попробуем провести несколько более продвинутую оптимизацию. Для этого нам потребуется обратиться к некоторым внутренним API Angular. Если вы с ними не знакомы, не переживайте, я постараюсь рассказать о них как можно более подробно.
Около 90% разработки софта сводится к требованию представить пользователю список элементов. В Angular для этой цели используется директива NgForOf. Попытаемся оптимизировать ее в соответствии с нашими потребностями. Вот как она работает:

В ней есть конструктор, который принимает на вход объект типа IterableDiffers. А вот как выглядит сам класс IterableDiffers:

В классе этого объекта только конструктор и метод find(). Конструктор принимает на вход коллекцию IterableDifferFactory[], а метод find() принимает на вход любую коллекцию (список, двоичное дерево поиска или что-либо другое).
Затем в этом методе происходит поиск среди всех имеющихся фабрик той, которая поддерживает полученную на вход структуру данных. Если нужная фабрика находится, метод ее возвращает. Больше здесь ничего не происходит.
Взглянем еще на 3 интерфейса:

В IterableDifferFactory метод supports() я только что описал, а также в нем есть метод create, принимающий на вход функцию trackByFunction. С последней вы, возможно, знакомы по директиве NgFor, там она тоже есть. Метод create возвращает экземпляр интерфейса IterableDiffer.
IterableDiffer — абстракция, принимающая на вход структуру данных и хранящая некоторое состояние. Ее назначение — сравнивать два экземпляра одной структуры данных. Метод diff() возвращает количество отличий между двумя экземплярами (назовем их А и Б), то есть количество элементов, которые надо добавить к А, чтобы получить Б, количество элементов, которые необходимо отнять от А, и количество элементов, поменявших места.
Наконец, функция TrackByFunction. Я подробно расскажу о ней чуть позже. Вначале давайте рассмотрим взаимоотношения между описанными структурами.

В директиве NgForOf происходит инъекция IterableDiffers в качестве аргумента конструктору. IterableDiffer используется в ней для обнаружения расхождений между текущим объектом, по которому происходит итерация, и его предыдущим значением. IterableDiffers используют коллекцию фабрик, создающих, в свою очередь, IterableDiffer. Этот последний использует TrackByFn, чтобы определить, по каким характеристикам мы будем сравнивать друг с другом элементы в коллекции.
Взглянем на то, как NgForOf использует differ.

Он вызывает метод diff() с текущим значением коллекции, по которой происходит итерация, и сравнивает его с предыдущей версией коллекции. Если обнаруживаются изменения, они применяются к DOM.
Посмотрим, как все это будет работать с IterableDiffers и конкретной функцией trackBy:

У нас есть функция trackBy, которая возвращает идентификатор предоставленного элемента. И у нас есть две коллекции, a и b. Они обе являются списками, и в них находятся только элементы.
IterableDiffer вначале сравнит первый элемент из a с первым элементом из b, и, поскольку у них одинаковые идентификаторы, IterableDiffer придет к выводу, что элементы идентичны. То же произойдет со вторыми элементами. Обратите внимание, что здесь имена работников отличаются. Для IterableDiffer это не имеет значения. Для него важны только идентификаторы. Однако идентификаторы отличаются, как в случае с третьими элементами в каждом списке, IterableDiffer заключит, что элементы отличаются. Поэтому он выдаст результат, в котором будет значиться, что последний элемент из a был удален, и заменен последним элементом из b.
IterableDiffer проверяет извне, изменилась ли структура данных. Он пользуется ей, как потребитель. Но ведь структуре данных лучше знать, изменилась она или нет. Попробуем реализовать собственную структуру данных DifferableList, вдохновленную другой концепцией из функционального программирования. В ней будет вестись учет происходящих с ней изменений.

Для этого мы воспользуемся LinkedList (хранящимся в переменной changes), поскольку он дает слегка большую производительность, чем Array, а произвольный доступ к элементам нам не нужен.
Сами данные мы будем хранить в неизменяемом списке Immutable.js. При необходимости модификации мы будем вносить изменения в список changes.
Мы, в сущности, применяем шаблон «декоратор» к неизменяемому списку. Кроме того, мы реализуем шаблон «итератор», чтобы Angular мог обходить эту структуру данных.
Таким образом, мы создали структуру данных, оптимизированную под Angular. Однако differ по умолчанию нам лучшей производительности не обеспечит.

Мы можем использовать специальный differ, где будет происходить постоянная проверка на наличие изменений в структуре данных. Поэтому обходить ее каждый раз целиком нет необходимости. Вместо этого можно просто работать со свойством changes.
Для этих изменений потребуется небольшой рефакторинг. Нам просто потребуется расширить существующий набор IterableDiffers.

Описанная структура данных сделана по общему принципу неизменяемых структур данных — это вновь понятие из функционального программирования. Они позволяют делать весьма необычные вещи: путешествовать во времени, создавать новые вселенные как ответвления существующих. Рекомендую на это взглянуть.

После последнего рефакторинга наша производительность выросла где-то на 30%.
Обнаружение изменений OnPush не всегда ведет себя так, как мы этого ожидаем. Обнаружение изменений вызывается для поддерева данного компонента не только, когда меняются входные данные этого компонента, но и когда в этом компоненте происходит событие.
Кроме того, мы узнали, в чем отличие чистых пайпов от мемоизации, и в чем отличие соответствующих механизмов кэширования. Разобрались с понятиями чистоты и референциальной прозрачности, взятыми из функционального программирования.
Наконец, посмотрели, как работают объекты Differ и функция TrackByFn. И запомнили, что использование других TrackByFn, отличающихся от данной по умолчанию, может только понизить производительность.
В качестве заключения можно сказать, что нет чудодейственного средства для оптимизации производительности. Нужно очень хорошо понимать, как устроено дерево компонентов и данные, с которыми мы работаем, и, исходя из этого, применять оптимизации, специфичные для нашего приложения. И, конечно, надо применять решения, предлагаемые нам Computer Science.
Вот несколько полезных ссылок:
По ним можно более подробно познакомиться с описанными темами. В первой статье описывается обнаружение изменений OnPush в Angular, во второй говорится о чистых пайпах и референциальной прозрачности, в третьей — про Angular Differs. Кроме того, есть несколько более подробный вариант чеклиста производительности Angular. Там описано, как можно настраивать обнаружение изменений.
Сегодня мы поговорим о производительности во время исполнения. В случае с одностраничными приложениями обычно речь идет либо о сетевой производительности, либо производительности в рантайме.
В первом случае обычно пытаются сократить количество HTTP-запросов или передаваемых по сети данных. В этом направлении есть много исследований. Например, над этим бьется коллектив Google Closure Compiler, достигая цели более эффективным удалением неиспользуемого кода и минификацией кода. Также у нас есть различные алгоритмы сжатия, и в команде webpack тоже ставят подобные цели. Наконец, в Angular CLI пытаются совместить лучшее из разных подходов и дают очень хорошо инкапсулированные сборки.
Однако в том, что касается производительности во время исполнения, развития немного. Здесь всё в наших собственных руках, нет сторонней «волшебной палочки», по мановению которой наше приложение станет работать быстрее. Есть несколько возможных подходов к проблеме, сегодня я расскажу о более общих решениях, зачастую применимых не только к Angular.
Чтобы проиллюстрировать эти решения, я написал «простое бизнес-приложение». В нем я попытался воспроизвести как можно больше проблем с производительностью, которые я встретил на протяжении последних месяцев. В итоге получился совершенно жуткий продукт, который мы попытаемся как-то улучшить.
В нашем максимально упрощенном приложении можно добавлять новых работников, представлять их в списке и рассчитывать для них некоторое значение. У нас будет два списка сотрудников: для отдела продаж и для R&D-отдела. В оба можно добавлять новые элементы. Уже имеющиеся элементы представлены в списке, где видно имя и некоторое числовое значение (предположим, это оценка работы сотрудника). Также есть поле ввода имени нового сотрудника. При добавлении сотрудника мы можем просто взять откуда-то число, высчитать что-то и отобразить все на экране.
Структура приложения состоит из AppComponent (охватывающего приложение целиком) и двух EmployeeListComponent (по одному на каждый список).
Вот шаблон EmployeeListComponent:
Здесь обратите внимание на элемент input. В нем используется синтаксис формата «ящик с бананами» (вначале квадратные скобки, затем круглые), чтобы установить двустороннюю привязку данных между свойством label, объявленном в контроллере EmployeeListComponent, и текстовым полем.
Кроме того, в EmployeeListComponent происходит итерация по списку сотрудников в массиве данных, и для каждого сотрудника создается элемент списка. Для каждого элемента мы отображаем имя сотрудника и рассчитываем числовое значение при помощи метода calculate(), определенного в классе EmployeeListComponent.
Теперь взглянем на сам этот класс:
Тут есть несколько важных вещей. Для начала, в нем не хранится состояние, он получает все необходимые данные (массив EmployeeData[]) на вход от родительского компонента. Таким образом, этот родительский компонент, AppComponent, выступает в роли Container Component в Redux.
Кроме того, в классе EmployeeListComponent есть метод calculate(), единственная задача которого — передать выполнение функции, вычисляющей числа Фибоначчи. На первый взгляд, числа Фибоначчи здесь неудобно использовать, однако у них есть ряд важных преимуществ. Во-первых, метод их расчета всем известен, нет необходимости объяснять сложную работу подходящей примеру функции. Можно было бы заменить на стандартное отклонение или еще что-то подобное.
Во-вторых, эту функцию можно реализовать крайне неэффективным образом, как мы это видим на экране. У нас есть два рекурсивных вызова, и для каждого числа Фибоначчи у нас будет происходить перерасчет всех предыдущих заново. Таким образом, здесь я искусственно замедлил работу приложения, чтобы был лучше виден эффект последующей оптимизации.
Итак, у нас есть приложение с компонентом самого приложения, и с двумя компонентами списков. Каждый из элементов в списке требует много вычислительной мощности.
Попробуем использовать в этом приложении некоторые реальные данные. У нас будет два списка, содержащие в общей сложности 140 элементов. В этом случае при вводе новых имен набор текста оказывается крайне замедлен. Вряд ли пользователям может понравиться такая работа приложения. Но почему настолько медленно? Профилировать эту проблему достаточно легко с помощью Chrome DevTools. Сделав это, мы выясняем, что наша функция расчета чисел Фибоначчи вызывается очень часто. Мы можем узнать точное количество вызовов, добавив в эту функцию логирование.
Оказывается, при каждом нажатии клавиши пользователем происходит перерасчет всего дерева компонентов по меньшей мере дважды (один раз при нажатии и один — при отпускании клавиши). Так что мы перерасчитываем все уже полученные ранее значения при каждом нажатии.
Вот как выглядит эта ситуация с точки зрения дерева компонентов. При каждом нажатии клавиши происходит изменение сначала в AppComponent. Поскольку обнаружение изменений в Angular работает как поиск в глубину, будет также вызвано обнаружение изменений в EmployeeListComponent, и затем в каждом из элементов работников. Для каждого из этих элементов будет пересчитано их числовое значение. Затем произойдет такой же обход второго EmployeeListComponent.
Всё это крайне неэффективно. Как правило, мы не хотим пересчитывать числовые значения для каждого элемента в массиве, такое мы хотели бы только при появлении нового массива. Вот если происходит передача нового массива из AppComponent в EmployeeListComponent, тогда можно высчитывать. Есть мысли, как это лучше всего сделать?
Например, можно использовать стратегию OnPush. Благодаря ей обнаружение изменений будет запускаться только при появлении новых входных данных у компонента. Когда Angular при проверке ссылок обнаруживает появление новых входных данных, в компонентах будет выполнено обнаружение изменений. То есть, если у нас есть дерево компонентов, когда корневой компонент получает новые данные, мы обновляем всю ветку, начиная с этого компонента. Мы чуть позже посмотрим, как это выглядит.
Обратимся за помощью к функциональному программированию и попробуем представить, что EmployeeListComponent — это функция. Входные данные для компонента — это входные аргументы функции, а изображение на экране — результат функции. Продемонстрирую свою мысль с помощью псевдокода.
В константе f мы сохраняем ссылку на EmployeeListComponent (теперь это функция), в константе data — входные аргументы (данные одного сотрудника).
Для начала осуществляем вызов функции с ее изначальными входными данными, и тут Angular выполнит обнаружение изменений. Поскольку до этого значением было undefined, сравнив data и undefined, Angular увидит изменение значения входных данных.
Но добавление нового элемента в список уже вызовет функцию с тем же аргументом, что и раньше: мы будем модифицировать структуру данных, на которую указывает та же константа data. Поэтому Angular не запустит обнаружение изменений.
Тем не менее, обнаружение изменений произойдет, если мы отправим во входном аргументе функции копию массива: там ссылка изменится.
Значит ли это, что каждый раз, когда нам необходимо обнаружение изменений, нам нужно копировать массив целиком? По нескольким причинам это было бы крайне неэффективно. Во-первых, это было бы крайне неоптимальное использование памяти. Для каждого обнаружения изменений нам нужно вначале выделить память под весь новый массив, а затем сборщику мусора нужно будет освободить ее. Во-вторых, это неэффективно с точки зрения вычислений. Временная сложность такого алгоритма по меньшей мере O(n).
Immutable
В отношении обоих этих вещей разумнее будет воспользоваться чем-либо наподобие Immutable.js. Это набор различных неизменяемых структур данных с двумя очень важными свойствами.
Во-первых, мы не можем изменять ни одну уже существующую структуру данных. Вместо этого вызовы, которые должны были бы изменить такую структуру данных, получают новую ссылку на нее с уже примененными изменениями.
Во-вторых, мы не копируем структуру данных целиком: новый экземпляр этой структуры по возможности будет использовать элементы старой.
Вот какой рефакторинг нам надо провести. Во-первых, мы поменяли содержимое методов add() и remove(). В add() при выполнении процедуры unshift(), в которой элемент переводится в начало списка, мы получаем новый список. То же самое в методе remove(), вызов splice() возвращает нам новый список.
Кроме этих двух методов, нам необходимо поменять ссылку на список. Иначе мы не могли бы оповестить EmployeeListComponent, что входные данные поменялись. Таким образом, выходные значения add() и remove() должны быть присвоены свойству list в AppComponent.
Запустим приложение и посмотрим, насколько быстрее теперь все получилось. Мы же тут оптимизировали, должно было стать лучше… Хм, приложение работает по-прежнему очень медленно. Возможно, стало быстрее прежнего, но все равно впечатления у пользователя вряд ли будут хорошо.
Чтобы измерить, насколько быстрее стало работать приложение, я написал несколько сквозных тестов и запустил их на Angular Benchpress.
Благодаря ним мы видим, что приложение ускорило работу как минимум вдвое. Этого, однако, недостаточно. Причина неудовлетворительной работы в том, что при вводе текста по-прежнему запускается обнаружение изменений. Хорошая новость в том, что теперь оно запускается только в одном из двух списков, но даже в нем оно не нужно, поскольку ни одно из числовых значений не поменялось.
Посмотрим, как теперь выглядит работа приложения с точки зрения дерева компонентов. При каждом нажатии клавиши мы несколько раз вызываем обнаружение изменений в AppComponent, EmployeeListComponent, и в каждом из отдельных компонентов. При этом мы не делаем вызовов ко второму списку. Но почему вообще происходит обнаружение изменений, ведь не было обращений ни к одному из вызовов, изменяющих структуру данных списка?
Причина заключается в определенных характеристиках обнаружения изменений OnPush, не слишком хорошо задокументированных.
Суть в том, что обнаружение изменений OnPush запускается не только при смене входных данных, а еще и тогда, когда в соответствующем компоненте триггерится событие.
Зная эту особенность, мы теперь можем провести рефакторинг кода. В этом есть своя позитивная сторона, поскольку мы заодно сможем улучшить разделение ответственности в нашем приложении и сделать дерево компонентов стройнее. Сделаем в EmployeeListComponent два дочерних компонента: NameInputComponent и ListComponent.
Первый из них будет отвечать только за хранение текущего значения строки ввода и за вызов события. Во втором будет производится вычисление функции, и там будет использоваться обнаружение изменений OnPush.
После этих изменений в коде приложение стало работать значительно быстрее. Как именно осуществляется работа приложения теперь? К сожалению, при нажатии пользователем клавиши обнаружение изменений по-прежнему вызывается в AppComponent, и затем в обоих экземплярах EmployeeListComponent. Но на этот раз в дочерних компонентах EmployeeListComponent обнаружение изменений уже не вызывается. Дело в том, что у ListComponent используется обнаружение изменений OnPush, а событие происходит в области EmployeeListComponent, т. е. в родительском компоненте EmployeeList. Скорость печати увеличивается на несколько порядков.
Однако и этого нам недостаточно. Еще одна возможная оптимизация касается добавления элементов. При создании нового элемента мы вызываем операцию добавления к неизменяемому списку, поэтому создается новый список и передается на вход в EmployeeListComponent. Это вызывает обнаружение изменений. То есть при вводе текста теперь все быстро, но при добавлении элемента по-прежнему происходит ненужное повторное вычисление числового значения во всех этих компонентах.
Чтобы решить эту проблему, надо обратиться к нашей функции вычисления чисел Фибоначчи. Мы сегодня уже упоминали чистые функции, и это одна из них. Хорошая новость в том, что чистые функции встречаются и среди по-настоящему полезных в наших приложениях вещей, вроде вычисления стандартного отклонения.
У чистых функций есть два очень важных свойства. Во-первых, у них нет побочных эффектов, то есть не осуществляется никаких вызовов через сеть, не происходит логирования, и так далее. Во-вторых, повторный вызов функции с такими же аргументами дает идентичный результат. В мире функционального программирования это и получило название «pure function».
И это очень важная концепция. В Angular есть «чистые пайпы» (pure pipes) и «грязные пайпы» (impure pipes, т. е. пайпы с внутренним состоянием). Они, как правило, используются для обработки данных. Чистые пайпы обычно форматируют данные, пример «чистого» — DatePipe.
Грязные пайпы хранят внутри определенное состояние, как, например, AsyncPipe. Разница между этими двумя случаями в том, что Angular выполняет чистый пайп, только когда обнаруживает, что изменился его аргумент. Как правило, выражения с чистыми пайпами рассматриваются Angular как не имеющие побочных эффектов, референциально прозрачные. Это понятие из функционального программирования, чтобы лучше его понять, взглянем на код, созданный компилятором Angular для шаблона с чистыми и грязными пайпами.
Мы применяем к переменной birthday вначале чистый пайп date, а затем грязный impureDate. На экране показаны два разных результата. Поначалу тут сложно разобраться. Загадочные символы в начале выражения нас не интересуют, они нужны только для того, чтобы разработчики не пользовались этими импортами.
Важная для нас часть следует за ними. _ck() — это проверка, в ней текущее значение date будет сравнено с предыдущим, и, если значение отличается, будет вызван метод date.transform(). Если же изменений нет, будет возвращен предыдущий результат, хранящийся в кэше. В случае же с impureDate просто будет вызван метод impureDate.transform().
Таким образом, референциальная прозрачность означает, что семантика выражения никак не поменяется, если вместо этого выражения подставить его выходное значение. Побочные эффекты будут незначительны.
Основываясь на этом принципе, я инкапсулировал нашу функцию Фибоначчи в написанном мной классе CalculatePipe, просто делегировав вычисление функции fibonacci. Кроме того, нам нужно будет поменять шаблон. Вместо метода calculate мы в нем будем использовать пайп.
Теперь попробуем протестировать приложение: в Benchpress будет происходить многократное добавление и удаление нового пользователя. Видно, что приложение работает уже достаточно быстро. Производительность увеличилась на несколько порядков.
Оптимизация отрисовки
Хочу рассказать еще о двух оптимизациях. Первая касается эффективности рендеринга. Попробуем отобразить в нашем приложении 1000 элементов одновременно. В реальном приложении мы этого делать, конечно, не будем — для таких ситуаций существует виртуальная прокрутка или разбивка на страницы. Но здесь мы попробуем оптимизировать работу иначе.
Предположим, наше приложение уже оптимизировано разными способами. Удален неиспользуемый код, пакет весит 50 килобайт, мы скачиваем его за 100 миллисекунд. Но отрисовка изображения занимает по меньшей мере 8 секунд. Несмотря на то, что наша сетевая производительность отличная, пользователь по-прежнему останется недоволен.
Взглянем на наши данные. В них мы видим дублирующиеся значения. Существует по несколько экземпляров функции Фибоначчи с аргументами 27, 28 и 29.
Благодаря чистым пайпам у нас происходит некоторое кэширование, однако эти значения всё равно рассчитываются многократно. К счастью, все наши примеры находятся в небольшом промежутке. Можно попробовать сделать систему глобального кэширования. Чистые пайпы создают кэш только для отдельного выражения. Мы увидим, в чем разница между таким подходом и настоящим кэшированием при помощи мемоизации.
Мемоизация, которую мы будем использовать, возможна только для чистых функций. Её использование достаточно просто:
Через require('lodash.memoize') мы получаем функцию memoize, и затем вызываем ее. Она создаст необходимую нам функцию Фибоначчи. При каждом вызове этой созданной функции ее входной аргумент и результат будут записываться в таблицу соответствий. Больше нам ничего не понадобится. Мы видим, что теперь приложение отображается за 6.7 секунд, до этого эти операции заняли 9.5 секунд. Для такой небольшой оптимизации это неплохо.
Сравним чистые пайпы и мемоизацию. В первом случае, когда Angular обнаруживает, что мы пытаемся вызвать 27 | calculate, выполнение делегируется функции fibonacci(27). При дальнейшем обходе списка каждый раз, когда делается вызов 27 | calculate, будет выполнена та же операция, поскольку кэширование происходит только локальное.
Однако при следующем обнаружении изменений Angular не будет пересчитывать результат, если аргументы calculate не поменялись. Таким образом, для каждого следующего выполнения обнаружения изменений наша оптимизация будет работать.
В случае с мемоизацией все будет выглядеть несколько иначе. Вначале мы вызовем 27 | calculate, произойдет вычисление числа Фибоначчи, и в кэш будет записано число 27 и выходное значение функции Фибоначчи. При всех следующих вызовах 27 | calculate результат будет взят из кэша. Экономия времени очевидна.
Итак, начинают выявляться некоторые общие тенденции. С концептуальной точки зрения обнаружение изменений OnPush и мемоизация похожи. И там, и там мы имеем референциальную прозрачность. Если представить дерево компонентов как выражение, как абстрактное синтаксическое дерево, к нему также можно применить оптимизации, пользующиеся референциальной прозрачностью. Однако в обоих случаях работать это всё будет только с последними входными данными.
Попробуем провести несколько более продвинутую оптимизацию. Для этого нам потребуется обратиться к некоторым внутренним API Angular. Если вы с ними не знакомы, не переживайте, я постараюсь рассказать о них как можно более подробно.
Около 90% разработки софта сводится к требованию представить пользователю список элементов. В Angular для этой цели используется директива NgForOf. Попытаемся оптимизировать ее в соответствии с нашими потребностями. Вот как она работает:
В ней есть конструктор, который принимает на вход объект типа IterableDiffers. А вот как выглядит сам класс IterableDiffers:
В классе этого объекта только конструктор и метод find(). Конструктор принимает на вход коллекцию IterableDifferFactory[], а метод find() принимает на вход любую коллекцию (список, двоичное дерево поиска или что-либо другое).
Затем в этом методе происходит поиск среди всех имеющихся фабрик той, которая поддерживает полученную на вход структуру данных. Если нужная фабрика находится, метод ее возвращает. Больше здесь ничего не происходит.
Взглянем еще на 3 интерфейса:
В IterableDifferFactory метод supports() я только что описал, а также в нем есть метод create, принимающий на вход функцию trackByFunction. С последней вы, возможно, знакомы по директиве NgFor, там она тоже есть. Метод create возвращает экземпляр интерфейса IterableDiffer.
IterableDiffer — абстракция, принимающая на вход структуру данных и хранящая некоторое состояние. Ее назначение — сравнивать два экземпляра одной структуры данных. Метод diff() возвращает количество отличий между двумя экземплярами (назовем их А и Б), то есть количество элементов, которые надо добавить к А, чтобы получить Б, количество элементов, которые необходимо отнять от А, и количество элементов, поменявших места.
Наконец, функция TrackByFunction. Я подробно расскажу о ней чуть позже. Вначале давайте рассмотрим взаимоотношения между описанными структурами.
В директиве NgForOf происходит инъекция IterableDiffers в качестве аргумента конструктору. IterableDiffer используется в ней для обнаружения расхождений между текущим объектом, по которому происходит итерация, и его предыдущим значением. IterableDiffers используют коллекцию фабрик, создающих, в свою очередь, IterableDiffer. Этот последний использует TrackByFn, чтобы определить, по каким характеристикам мы будем сравнивать друг с другом элементы в коллекции.
Взглянем на то, как NgForOf использует differ.
Он вызывает метод diff() с текущим значением коллекции, по которой происходит итерация, и сравнивает его с предыдущей версией коллекции. Если обнаруживаются изменения, они применяются к DOM.
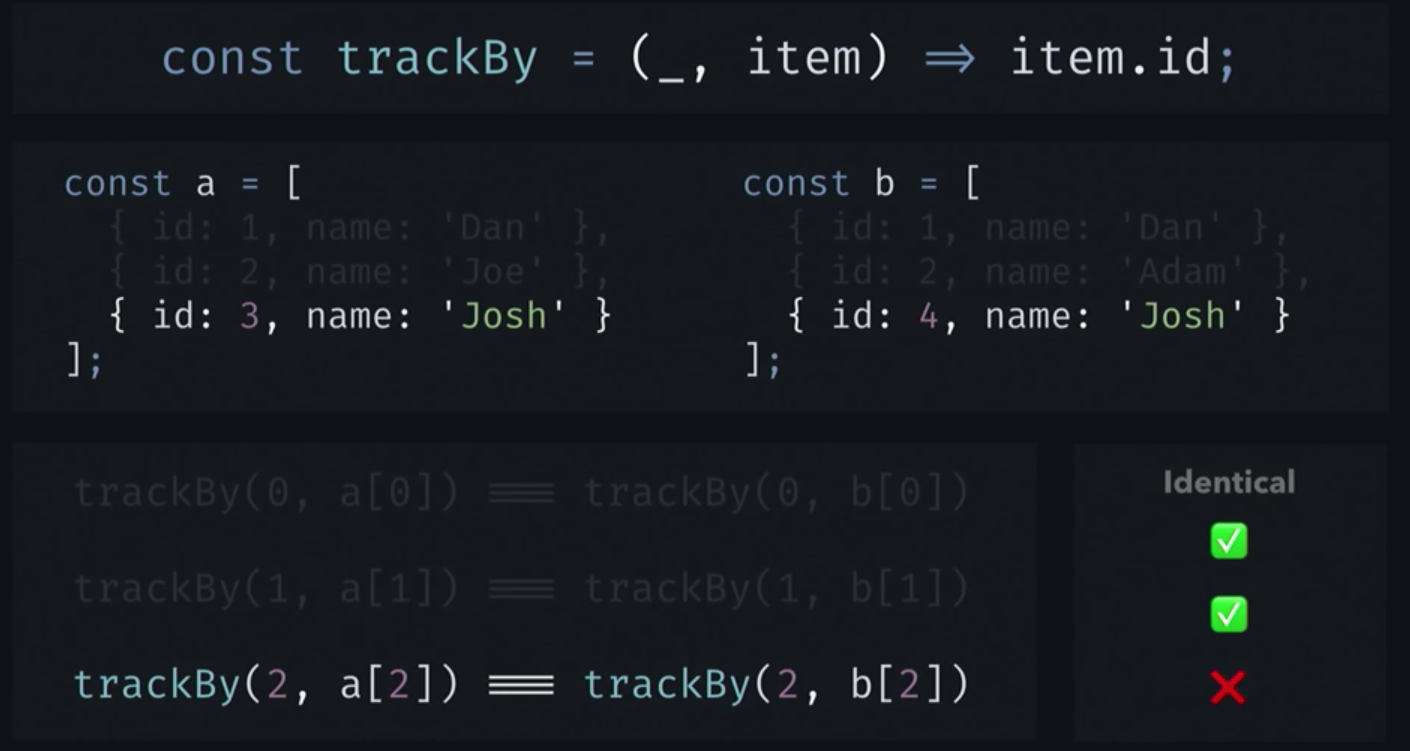
Посмотрим, как все это будет работать с IterableDiffers и конкретной функцией trackBy:
У нас есть функция trackBy, которая возвращает идентификатор предоставленного элемента. И у нас есть две коллекции, a и b. Они обе являются списками, и в них находятся только элементы.
IterableDiffer вначале сравнит первый элемент из a с первым элементом из b, и, поскольку у них одинаковые идентификаторы, IterableDiffer придет к выводу, что элементы идентичны. То же произойдет со вторыми элементами. Обратите внимание, что здесь имена работников отличаются. Для IterableDiffer это не имеет значения. Для него важны только идентификаторы. Однако идентификаторы отличаются, как в случае с третьими элементами в каждом списке, IterableDiffer заключит, что элементы отличаются. Поэтому он выдаст результат, в котором будет значиться, что последний элемент из a был удален, и заменен последним элементом из b.
IterableDiffer проверяет извне, изменилась ли структура данных. Он пользуется ей, как потребитель. Но ведь структуре данных лучше знать, изменилась она или нет. Попробуем реализовать собственную структуру данных DifferableList, вдохновленную другой концепцией из функционального программирования. В ней будет вестись учет происходящих с ней изменений.
Для этого мы воспользуемся LinkedList (хранящимся в переменной changes), поскольку он дает слегка большую производительность, чем Array, а произвольный доступ к элементам нам не нужен.
Сами данные мы будем хранить в неизменяемом списке Immutable.js. При необходимости модификации мы будем вносить изменения в список changes.
Мы, в сущности, применяем шаблон «декоратор» к неизменяемому списку. Кроме того, мы реализуем шаблон «итератор», чтобы Angular мог обходить эту структуру данных.
Таким образом, мы создали структуру данных, оптимизированную под Angular. Однако differ по умолчанию нам лучшей производительности не обеспечит.
Мы можем использовать специальный differ, где будет происходить постоянная проверка на наличие изменений в структуре данных. Поэтому обходить ее каждый раз целиком нет необходимости. Вместо этого можно просто работать со свойством changes.
Для этих изменений потребуется небольшой рефакторинг. Нам просто потребуется расширить существующий набор IterableDiffers.
Описанная структура данных сделана по общему принципу неизменяемых структур данных — это вновь понятие из функционального программирования. Они позволяют делать весьма необычные вещи: путешествовать во времени, создавать новые вселенные как ответвления существующих. Рекомендую на это взглянуть.
После последнего рефакторинга наша производительность выросла где-то на 30%.
Повторим пройденное
Обнаружение изменений OnPush не всегда ведет себя так, как мы этого ожидаем. Обнаружение изменений вызывается для поддерева данного компонента не только, когда меняются входные данные этого компонента, но и когда в этом компоненте происходит событие.
Кроме того, мы узнали, в чем отличие чистых пайпов от мемоизации, и в чем отличие соответствующих механизмов кэширования. Разобрались с понятиями чистоты и референциальной прозрачности, взятыми из функционального программирования.
Наконец, посмотрели, как работают объекты Differ и функция TrackByFn. И запомнили, что использование других TrackByFn, отличающихся от данной по умолчанию, может только понизить производительность.
В качестве заключения можно сказать, что нет чудодейственного средства для оптимизации производительности. Нужно очень хорошо понимать, как устроено дерево компонентов и данные, с которыми мы работаем, и, исходя из этого, применять оптимизации, специфичные для нашего приложения. И, конечно, надо применять решения, предлагаемые нам Computer Science.
Вот несколько полезных ссылок:
- mgv.io/ng-cd — Angular’s OnPush Change Detection Strategy
- mgv.io/ng-pure — Pure Pipes and Referential Transparency
- mgv.io/ng-diff — Understanding Angular Differs
- mgv.io/ng-perf-checklist — Angular Performance Checklist
- mgv.io/ng-checklist-video — Angular Performance Checklist
По ним можно более подробно познакомиться с описанными темами. В первой статье описывается обнаружение изменений OnPush в Angular, во второй говорится о чистых пайпах и референциальной прозрачности, в третьей — про Angular Differs. Кроме того, есть несколько более подробный вариант чеклиста производительности Angular. Там описано, как можно настраивать обнаружение изменений.
Минутка рекламы. Если вам понравился этот доклад с предыдущей HolyJS, обратите внимание: уже 19-20 мая пройдёт HolyJS 2018 Piter. А ещё обратите внимание на то, что с 1 мая цена билета возрастет, так что сейчас самое время принять решение!

