DevConf 2018 уже на следующей неделе! В прошлом году Юрий Насретдинов провел интересный обзор перспективных систем хранения данных для highload. Видео с докладом доступно на странице доклада. А для хабра-читателей предлагаю краткий пересказ.
 В начале расскажу как нужно подходить к выбору технологии для highload-проекта.
В начале расскажу как нужно подходить к выбору технологии для highload-проекта.
Приведу примеры успешных технологий.

MySQL и MongoDB начинали с очень простых, дубовых, решений, которые просто работают и имеют понятные недостатки.
Для какого юзкейса был создан Tarantool? Представьте, что у вас социальная сеть и данные пользователей размазаны по сотне mysql-серверов. При этом, юзеры расшардены по user id. Пользователь вбивает свой email и хочет авторизоваться.

Очевидный выход — шардить юзеров по email. Но, у людей есть еще и номер телефона, по которому он тоже хочет авторизоваться. Соответственно, второй очевидный выход — некая база данных, быстрая, которая содержит в себе соответствия email => userId, телефон => userId и желательно, чтобы такая база была персистентная. Но на тот момент таких баз данных не было, как один из вариантов на тот момент — складывать это все в мемкеш. Но допустим, операция добавления нового поля для поиска userId будет весьма непростой. С мемкешом проблем довольно много, но по крайней мере он выдерживает большую нагрузку на чтение и на запись.
Итак, Tarantool. Хранит все данные в памяти. И, одновременно, на диске. По заверениям разработчиков, выдерживает 1 миллион запросов в секунду на процессорное ядро. Разрабатывается в mail.ru. Константин Осипов, один из разработчиков Tarantool, раньше разрабатывал MySQL.

Процесс обработки запросов в Tarantool имеет конвейерную архитектуру. Множество клиентов запрашивают сервер Tarantool. Все эти запросы сохраняются в очередь, в I/O thread. Потом он через некоторые промежутки времени передает их на выполнение. Таким образом блокировка execution thread идет на довольно маленькое время.

Отдельно стоит упомянуть персистентность. Если кто использует redis с персистентностью, то наверняка замечает, что редис «залипает» на довольно длительный промежуток времени в тот момент, когда идет процесс создания форка. У Tarantool другая модель. До версии 1.6.7 он часть памяти держал в shared регионе и при форке она не копируется. И пока форкнутый child пишется на диск, parent знает, что этот кусок памяти трогать нельзя. С версии 1.6.7 они вообще отказались от форка. Они поддерживают, можно сказать, механизм виртуальной памяти в user-space. User-space memory address translation. Вместо создания форк-процесса создается thread, который пробегается по снэпшоту памяти в user-space и записывает на диск консистентный снэпшот.
Для каких ситуаций подходит Tarantool:
Когда не стоит его использовать:
Создан Яндексом как раз для аналитики. Для систем подобных Яндекс.Аналитике нужны были базы данных:
На тот момент продукта, удовлетворяющим всем трем критериям, не было. Возможные решения:
Яндекс сначала использовал MySQL. но потом написал ClickHouse — распределенную СУБД для аналитики, которая хранит данные по колонкам, оптимизирована для HDD(SSD — довольно дорогие) и исключительно быстрая(может сканировать до миллиарда записей в секунду). Она уже протестирована в продакшене Яндекса. ClickHouse поддерживает только вставку и запрос данных. Нет удаления и редактирования.

Данные хранятся по месячным партициям. В каждой партиции данные упорядочены по возрастанию первичного ключа. «Первичный ключ» в данном случае не очень правильно, поскольку не гарантируется его уникальность.

Чтобы можно было быстрее искать по первичному ключу в ClickHouse используются файлы «засечек», где раз в какое-то количество записей делаются засечки со значением первичного ключа и где он находится. Это позволяет с малым количеством операций с диском выполнять запросы с range первичного ключа.
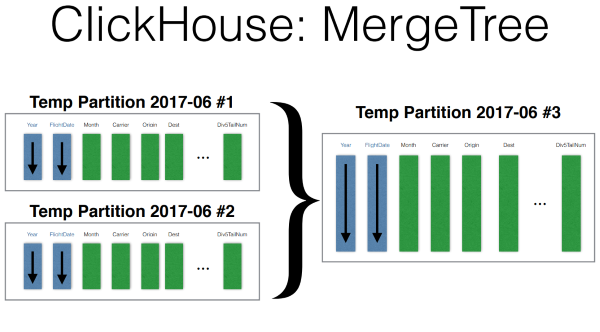
Insert происходит так. Данные пишутся во временную партицию, отсортированно. После чего, фоновым процессом, когда запись на какое-то время останавливается, происходит merge эти партиций.
Возможности ClickHouse:
Сценарии использования:
Когда не использовать:

Предпосылки создания такие же как и у Tarantool. Есть база пользователей, размазанная по серверам. И нужно искать, например по email или телефону. Но если Tarantool в нашем примере выступает в виде такого высокоуровневого индекса к шардам базы данных, то CockroachDB предлагает хранить все у себя.
Возможные решения до CockroachDB:
Google Cloud Spanner
Authorizer + ручной шардинг(как мы уже рассматривали с Tarantool)
MongoDB, Cassandra — не поддерживают распределенные уникальные индексы.
Изначально CockroachDB создавался как распределенный Key-Value Storage, но текущие реалии подсказывают, что новая Key-Value база данных мало кому нужна. Все хотят SQL. Он поддерживает SQL, JOIN, транзакции, ACID, уникальные индексы, автоматический шардинг. Создан авторами Google Spanner. Написан на Go. Почти с первого раза прошел тестирование Jepsen. И уже используется в продакшене в Baidu.
Как же реляционная модель ложится на Key-Value хранилище? Вручную это можно организовать довольно просто. Я приведу сильно упрощенный вариант. В CockroachDB это все немного сложнее. Ключи получаются довольно простые — имя таблицы/значение первичного ключа/имя поля.

Вторичные индексы тоже довольно понятные. Еще один ключ с именем индекса. В случае неуникального индекса — вместе со значением первичного ключа.


Данные хранятся довольно тривиальным способом, но мне он кажется очень правильным. Глобальный отсортированный Key-Value map разбит на регионы, которые база старается поддерживать примерно в 64 Мб. Каждый из этих регионов отреплицирован на несколько узлов и один из этих узлов для региона является Raft-лидером, т.е. вся запись(вероятно и чтение тоже) идет в него. Теперь представим, что какая-то нода выпала. Raft позволяет достаточно быстро выбрать нового лидера для каждого региона. Таким образом, и запись и чтение будут доступны.
Одной из главных фич является поддержка распределенных транзакций. Когда необходимо транзакционно поменять данные на нескольких узлах. Реализованы они так. Есть системная таблица со списком транзакций. При модификации значения какого-то ключа, рядом добавляется ключ с номером транзакции. При чтении такого ключа смотрится таблица транзакций, закоммичена она или нет и выбирается нужное значение. При успешном коммите значения заменяются на конечные. Неудавшиеся транзакции чистит «сборщик мусора».
В будущем CockroachDB вполне может быть использован как главная база данных большого проекта. Сейчас же пока рано, поскольку 1.0 релиз вышел совсем недавно.
Когда не использовать:
Как вы могли заметить из описания алгоритма распределенных транзакций CockroachDB процесс этот не быстрый. Если в проекте требуется низкая latency или высокий Queries per second — не стоит. Запись также не самая быстрая.
Если вам не нужна строгая консистентность. Хотя для распределенной базы данных это довольно важный фактор. Условно, если вам нужно послать сообщение от одного пользователя к другому, то записи о нем должны появиться и на сервере автора сообщения и на сервере того, кому это сообщение отправлено, и желательно это сделать атомарно.
В заключении хочу сказать, что каждый инструмент надо выбирать с умом, четко понимая решаемые им задачи и его ограничения. Не слушайте меня и проверяйте все сами.
В этом году тоже довольно интересная секция Storage. Приходите делиться опытом. Хабрачитателям скидка.
- В первую очередь, должно быть понимание как оно работает. Не только сильные, но и слабые стороны.
- Знание как это мониторить и бэкапить. Без хороших инструментов для этого, эту технологию рано использовать в продакшене.
- Рано или поздно системы «падают»(это нормальная, штатная ситуация) и нужно знать что делать в этом случае.
Приведу примеры успешных технологий.
MySQL и MongoDB начинали с очень простых, дубовых, решений, которые просто работают и имеют понятные недостатки.
Tarantool
Для какого юзкейса был создан Tarantool? Представьте, что у вас социальная сеть и данные пользователей размазаны по сотне mysql-серверов. При этом, юзеры расшардены по user id. Пользователь вбивает свой email и хочет авторизоваться.
Очевидный выход — шардить юзеров по email. Но, у людей есть еще и номер телефона, по которому он тоже хочет авторизоваться. Соответственно, второй очевидный выход — некая база данных, быстрая, которая содержит в себе соответствия email => userId, телефон => userId и желательно, чтобы такая база была персистентная. Но на тот момент таких баз данных не было, как один из вариантов на тот момент — складывать это все в мемкеш. Но допустим, операция добавления нового поля для поиска userId будет весьма непростой. С мемкешом проблем довольно много, но по крайней мере он выдерживает большую нагрузку на чтение и на запись.
Итак, Tarantool. Хранит все данные в памяти. И, одновременно, на диске. По заверениям разработчиков, выдерживает 1 миллион запросов в секунду на процессорное ядро. Разрабатывается в mail.ru. Константин Осипов, один из разработчиков Tarantool, раньше разрабатывал MySQL.
Процесс обработки запросов в Tarantool имеет конвейерную архитектуру. Множество клиентов запрашивают сервер Tarantool. Все эти запросы сохраняются в очередь, в I/O thread. Потом он через некоторые промежутки времени передает их на выполнение. Таким образом блокировка execution thread идет на довольно маленькое время.
Отдельно стоит упомянуть персистентность. Если кто использует redis с персистентностью, то наверняка замечает, что редис «залипает» на довольно длительный промежуток времени в тот момент, когда идет процесс создания форка. У Tarantool другая модель. До версии 1.6.7 он часть памяти держал в shared регионе и при форке она не копируется. И пока форкнутый child пишется на диск, parent знает, что этот кусок памяти трогать нельзя. С версии 1.6.7 они вообще отказались от форка. Они поддерживают, можно сказать, механизм виртуальной памяти в user-space. User-space memory address translation. Вместо создания форк-процесса создается thread, который пробегается по снэпшоту памяти в user-space и записывает на диск консистентный снэпшот.
Для каких ситуаций подходит Tarantool:
- У вас много читающих/пишущих клиентов.
- Много мелкого чтения/записи.
- Когда у вас есть необходимость в некоем центральном хранилище и рабочий набор влезает в память. Tarantool пока не поддерживает шардинг.
- Желание писать хранимые процедуры. Tarantool поддерживает их на Lua.
- Авторизация, сессии, счетчики.
Когда не стоит его использовать:
- Если нужны: автоматический шардинг и failover, Raft/Paxos, длинные транзакции.
- Мало клиентов и требование минимальной latency. Из-за конвейерной архитектуры latency будет больше, чем минимально возможная.
- Рабочий набор не влезает в память. Костя Осипов только что рассказывал о новом движке Винил для Tarantool, но я рекомендую вам его проверить сначала.
- Ну и мое личное мнение: Tarantool не подходит для задач аналитики. Не смотря на то, что данные он держит все в памяти, но держит он их не так, как надо для этих задач.
ClickHouse
Создан Яндексом как раз для аналитики. Для систем подобных Яндекс.Аналитике нужны были базы данных:
- Эффективные и линейно-масштабируемые.
- Аналитика в реалтайме.
- Бесплатная и open-source.
На тот момент продукта, удовлетворяющим всем трем критериям, не было. Возможные решения:
- MySQL(MyISAM) — быстрая запись, медленное чтение
- Vertica, Exasol — платные
- Hadoop — на запись работает, но чтение не realtime.
Яндекс сначала использовал MySQL. но потом написал ClickHouse — распределенную СУБД для аналитики, которая хранит данные по колонкам, оптимизирована для HDD(SSD — довольно дорогие) и исключительно быстрая(может сканировать до миллиарда записей в секунду). Она уже протестирована в продакшене Яндекса. ClickHouse поддерживает только вставку и запрос данных. Нет удаления и редактирования.
Данные хранятся по месячным партициям. В каждой партиции данные упорядочены по возрастанию первичного ключа. «Первичный ключ» в данном случае не очень правильно, поскольку не гарантируется его уникальность.
Чтобы можно было быстрее искать по первичному ключу в ClickHouse используются файлы «засечек», где раз в какое-то количество записей делаются засечки со значением первичного ключа и где он находится. Это позволяет с малым количеством операций с диском выполнять запросы с range первичного ключа.
Insert происходит так. Данные пишутся во временную партицию, отсортированно. После чего, фоновым процессом, когда запись на какое-то время останавливается, происходит merge эти партиций.
Возможности ClickHouse:
- SQL, ограниченные JOIN.
- Репликация и работа в кластере. Поддерживается, но надо постараться.
- 17(наверняка уже больше) алгоритмов выполнения Group by.
- Materialized views, global JOIN's.
- Выборки с сэмплированием. Когда можно оптимально прочитать только часть данных. Например, только для определенного юзера в Яндекс.Аналитике.
Сценарии использования:
- Задачи realtime-аналитики.
- Time-series — github.com/yandex/graphouse
- Хранение сырых данных, которых ClickHouse умеет очень быстро агрегировать. Показы, клики, логи, etc.
Когда не использовать:
- OLTP-задачи(нет транзакций)
- Работа с деньгами(нет транзакций)
- Хранение агрегированных данных(нет смысла)
- Map/Reduce задачи.(многие из них прекрасно решаются с помощью SQL)
- Полнотекстовый поиск(не предназначен)
CockroachDB
Предпосылки создания такие же как и у Tarantool. Есть база пользователей, размазанная по серверам. И нужно искать, например по email или телефону. Но если Tarantool в нашем примере выступает в виде такого высокоуровневого индекса к шардам базы данных, то CockroachDB предлагает хранить все у себя.
Возможные решения до CockroachDB:
Google Cloud Spanner
Authorizer + ручной шардинг(как мы уже рассматривали с Tarantool)
Изначально CockroachDB создавался как распределенный Key-Value Storage, но текущие реалии подсказывают, что новая Key-Value база данных мало кому нужна. Все хотят SQL. Он поддерживает SQL, JOIN, транзакции, ACID, уникальные индексы, автоматический шардинг. Создан авторами Google Spanner. Написан на Go. Почти с первого раза прошел тестирование Jepsen. И уже используется в продакшене в Baidu.
Как же реляционная модель ложится на Key-Value хранилище? Вручную это можно организовать довольно просто. Я приведу сильно упрощенный вариант. В CockroachDB это все немного сложнее. Ключи получаются довольно простые — имя таблицы/значение первичного ключа/имя поля.
Вторичные индексы тоже довольно понятные. Еще один ключ с именем индекса. В случае неуникального индекса — вместе со значением первичного ключа.
Данные хранятся довольно тривиальным способом, но мне он кажется очень правильным. Глобальный отсортированный Key-Value map разбит на регионы, которые база старается поддерживать примерно в 64 Мб. Каждый из этих регионов отреплицирован на несколько узлов и один из этих узлов для региона является Raft-лидером, т.е. вся запись(вероятно и чтение тоже) идет в него. Теперь представим, что какая-то нода выпала. Raft позволяет достаточно быстро выбрать нового лидера для каждого региона. Таким образом, и запись и чтение будут доступны.
Одной из главных фич является поддержка распределенных транзакций. Когда необходимо транзакционно поменять данные на нескольких узлах. Реализованы они так. Есть системная таблица со списком транзакций. При модификации значения какого-то ключа, рядом добавляется ключ с номером транзакции. При чтении такого ключа смотрится таблица транзакций, закоммичена она или нет и выбирается нужное значение. При успешном коммите значения заменяются на конечные. Неудавшиеся транзакции чистит «сборщик мусора».
В будущем CockroachDB вполне может быть использован как главная база данных большого проекта. Сейчас же пока рано, поскольку 1.0 релиз вышел совсем недавно.
Когда не использовать:
Как вы могли заметить из описания алгоритма распределенных транзакций CockroachDB процесс этот не быстрый. Если в проекте требуется низкая latency или высокий Queries per second — не стоит. Запись также не самая быстрая.
Если вам не нужна строгая консистентность. Хотя для распределенной базы данных это довольно важный фактор. Условно, если вам нужно послать сообщение от одного пользователя к другому, то записи о нем должны появиться и на сервере автора сообщения и на сервере того, кому это сообщение отправлено, и желательно это сделать атомарно.
В заключении хочу сказать, что каждый инструмент надо выбирать с умом, четко понимая решаемые им задачи и его ограничения. Не слушайте меня и проверяйте все сами.
В этом году тоже довольно интересная секция Storage. Приходите делиться опытом. Хабрачитателям скидка.

