Публикуем расшифровку видеозаписи выступления Алексея Гончарука (Apache Ignite PMC Member и Главный архитектор GridGain) на митапе Apache Ignite сообщества в Петербурге 29 марта. Загрузить слайды можно по ссылке.
Участников сообщества Apache Ignite часто спрашивают: «Сколько нужно узлов и памяти для того, чтобы загрузить такой-то объем данных?» Об этом и я хочу сегодня поговорить. Забегая вперёд: такое прогнозирование пока что является достаточно сложной, нетривиальной задачей. Для этого нужно немного разбираться в устройстве Apache Ignite. Также я расскажу, как упросить себе задачу прогнозирования, и какие можно применять оптимизации.
Итак, очень часто к нам приходят пользователи и говорят: «У нас есть данные, представленные в виде файлов. Сколько нужно памяти, чтобы транслировать эти данные в Apache Ignite?».
При такой постановке ответить на вопрос практически невозможно, потому что разные форматы файлов транслируются в совершенно разные модели. К примеру, файл может быть сжат. А если он не сжат в какой-то классический бинарный вид, но может дедуплицирование данных, значит файл сжат в неявном виде.
Также не стоит забывать, что Apache Ignite обеспечивает быстрый доступ к данным по различным ключам либо SQL-индексам, поэтому в дополнение к данным, которые лежат в файле, мы строим дополнительные индексы, с которыми связаны дополнительные расходы. Так что в общем случае неверно говорить, что единичный индекс добавит какой-то процент от общего объема данных, поскольку индексируемое поле может иметь разный размер. То есть неправильно выделять на индекс фиксированный процент памяти.
Давайте переформулируем задачу. Мы говорим, что наша модель состоит из нескольких типов, и хорошо понимаем структуру каждого типа. Более того, если в модели есть поля вариативного размера, скажем, строковые, то можем примерно оценить минимальный и максимальный размер данных, а также распределение размеров во всему набору данных. Исходя из того, сколько у нас типов данных и какой объём информации по каждому типу, мы будем планировать количество памяти и дисков.
Эмпирический подход может быть немного неточен, но, с точки зрения пользователя, не требует какого-то глубокого погружения в структуру системы. Суть подхода в следующем.
Берёте репрезентативную выборку данных и загружаете в Apache Ignite. Во время загрузки наблюдаете за увеличением размера хранилища. На определённых объёмах можно делать «отсечки», чтобы потом линейно экстраполировать и спрогнозировать необходимый объём хранилища для всего набора данных.
Здесь обычно задают хороший вопрос: «Какой должна быть репрезентативная выборка?»
Однажды мы генерировали выборку случайным образом. Но оказалось, что генератор собрал данные таким образом, что в набор входили остатки от деления при генерировании. В какой-то момент выяснилось, что наши случайные строки, которые должны были иметь равномерное распределение, на самом деле этого распределения не имели. Поэтому, когда будете оценивать объём хранилища, убедитесь, что в репрезентативной выборке действительно выполняются распределения, которыми вы оперируете.
Также обратите внимание на разброс размеров ваших объектов. Если вы предполагаете, что они будут одинаковой длины, то, в целом, для репрезентативной выборки достаточно небольшого количества объектов. Чем больше вариативность, чем больше комбинаций размеров полей, тем большую выборку нужно будет загрузить, чтобы понять зависимость. По своему опыту скажу, что зависимость начинает проясняться где-то с миллиона объектов, которые грузятся в одну партицию на один узел.
За чем именно нужно следить в ходе загрузки репрезентативной выборки? Если вы работаете с persistence, можно смотреть на объем файлов, которые у вас получаются. Или можете просто включить метрики данных региона, метрики в конфигурации Apache Ignite и через MX Bean мониторить увеличение памяти, делая «отсечки» и строя график.
В данном случае мы пройдём по всем стадиям изменения структуры данных, которые претерпевает ваш объект при сохранении в Apache Ignite, а также посмотрим на окружающие структуры данных, которые могут увеличивать потребление памяти. Когда мы поймем, какие происходят изменения и какие структуры данных меняются, мы сможем достаточно точно оценить количество памяти, необходимое для загрузки данных.
Проанализируем операцию cash put при записи в Apache Ignite. Данные проходят через 4 стадии преобразований:
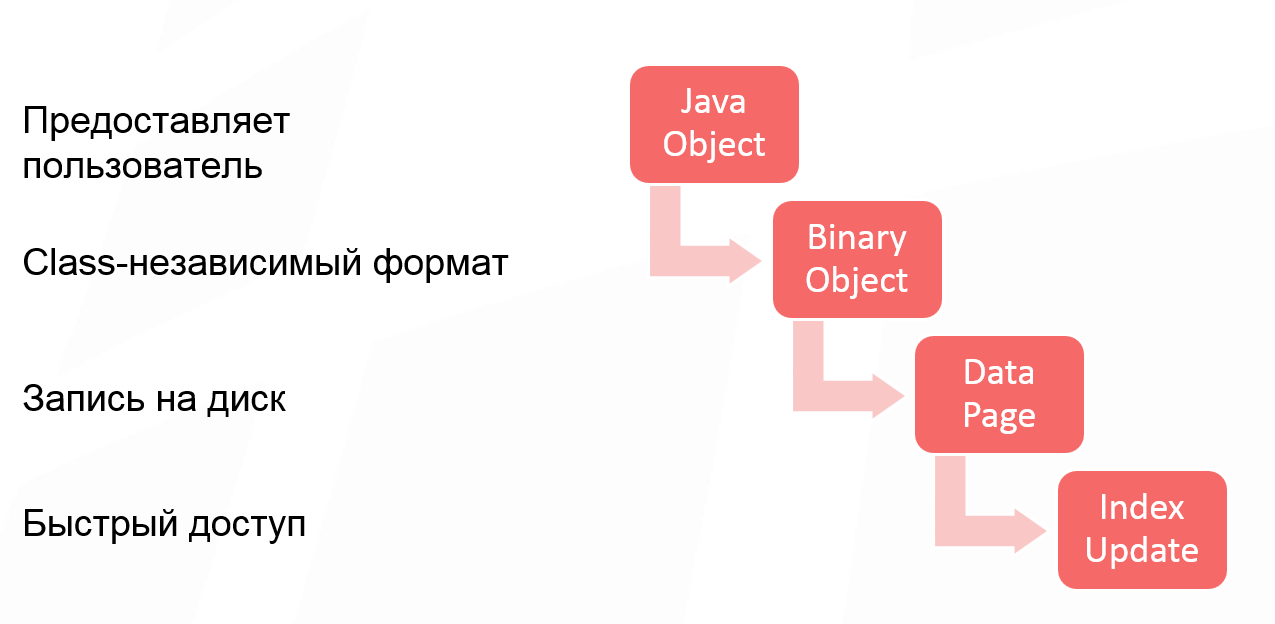
Первая стадия опциональная, потому что некоторые пользователи работают с классом и передают в Apache Ignite Java-объект. Некоторые пользователи создают бинарный объект напрямую, поэтому первая стадия конвертации объекта пропускается. Но если вы работаете с Java-объектами, то это первая трансформация, которую претерпевает объект.
После конвертации Java-объекта в бинарный объект у нас получается класс-независимый формат. Суть его в том, что вы можете оперировать бинарными объектами в кластере, не имея описания классов. Это позволяет вам изменять структуру класса и выполнять так называемый роллинг изменения структуры объектов. То есть ваша модель растет, изменяется, и вы получаете возможность работать со своими данными не меняя классы, не разворачивая их в кластере.
Третья стадия изменений, вносящая дополнительный overhead — запись на диск. Единицей работы с диском традиционно является страница. И начиная с Apache Ignite 2.0 мы перешли на страничную архитектуру. Это означает, что у каждой страницы есть опциональные заголовки, какие-то метаданные, которые тоже занимают место при записи объектов в страницу.
И последний кусочек, который тоже необходимо учитывать — обновление индекса. Даже если вы не используете SQL, в Apache Ignite у вас есть быстрый доступ по ключу. Это основной API кэша Apache Ignite. Поэтому всегда строится индекс первичного ключа, и на него тоже тратится место.
Это наш бинарный объект:

Не будем сильно углубляться в структуру, в общем виде её можно представить как некий заголовок, потом поля, наши существенные данные и футер. Заголовок бинарного объекта занимает 24 байта. Возможно, это много, но столько необходимо для поддержки изменяемости объектов без классов.
Если модель данных, которые вы кладете в кэш, предполагает какую-то развесистую внутреннюю структуру, то, возможно, стоит посмотреть, нельзя ли заинлайнить какие-то маленькие объекты в ваш исходный большой объект? В принципе, такой инлайнинг будет вам экономить по 24 байта на объект, что при достаточно большой развесистости модели дает существенный прирост.
Размер футера зависит от флага compactFooter, который позволяет записывать структуру объекта в дополнительные метаданные. То есть вместо того, чтобы писать порядок полей в самом объекте, мы их сохраняем отдельно. И если compactFooter равен true, то футер будет очень маленьким. Но при этом Apache Ignite совершает дополнительные действия для сохранения и поддержки этих метаданных. Если же compactFooter равен false, то объект является самодостаточным и его структуру можно считать без дополнительных метаданных.
На данный момент в нашем публичном API нет метода, возвращающего размер бинарного объекта. Поэтому если вам это очень интересно, можете сделать хак и привести объект к имплементации, тогда увидите его размер. Я думаю, в Apache Ignite 2.5 мы добавим метод, который позволит получить размер объекта.
Как я уже сказал, единицей работы с диском является страница. Это сделано для оптимизации чтения и записи на диск. Но при этом накладывает ограничения на внутреннюю архитектуру Apache Ignite, поскольку любые структуры данных, которые будут сохраняться на диск, также должны работать со страницами.
Иными словами, из кирпичиков-страниц строится любая структуры данных, будь то дерево или freelist. Страницы ссылаются друг на друга по уникальному идентификатору. По этому же уникальному идентификатору мы можем за константное время определить файл, из которого эти страницы можно считать, с какого смещения будет считана из этого файла та или иная страница.
Единичный раздел, который разбит на множество страниц, можно представить в виде вот такой схемы:

Стартовая метастраница позволяет достигнуть любой другой страницы. Они делятся на разные типы, которых достаточно много, но для упрощения примера скажу, что у нас есть:
Зачем это нужно, мы поговорим чуть ниже.
Начнем со страницы данных. Этот блок принимает наш ключ и значение, когда мы записываем данные в Apache Ignite. Сначала берётся страница данных, которая сможет вместить нашу информацию, и в неё записываются данные. Когда ссылка на них получена, записывается информация в индекс.
Страница данных имеет табличную организацию. В начале есть таблица, которая содержит смещение до пар ключ-значение. Сами пары ключ-значение пишутся в обратном порядке. Самая первая запись расположена в конце страницы. Это сделано для того, чтобы было удобнее работать со свободным местом. Вы спросите, зачем было так усложнять? Почему нельзя писать данные сразу на страницу и ссылаться по смещению внутри страницы? Это сделано для дефрагментации страницы.

Если здесь удалить запись № 2, то образуются две свободные зоны. Вполне возможно, что запись № 3 в будущем понадобится передвинуть вправо, чтобы вместить сюда более крупную запись. И если у нас есть непрямая адресация, то вы просто меняете смещение соответствующей записи в таблице. При этом внешняя ссылка, которая ссылается на эту страницу, остается константной.
Строка может быть фрагментирована в том смысле, что её размер будет больше размера страницы. В этом случае мы возьмем пустую страницу и в нее запишем хвостовую часть строки, а остаток — в страницу данных.
Помимо ключа и значения в страницу данных записывается и вспомогательная информация для корректной работы системы, например, номер версии. Если у вас используется expire policy, туда же пишется expiry time. В общем случае дополнительные метаданные занимают 35 байт. После того, как вы узнали размер бинарного объекта и ключа, вы добавляете 35 байт и получаете объём конкретной записи в странице данных. И затем высчитываете, сколько записей умещается в странице.
Может оказаться, что в странице данных останется свободное место, в которое не поместится ни одна из записей. Тогда в метриках вы увидите fill-фактор, который не равен 1.
И пара слов о процедуре записи. Допустим, у вас была пустая страница и вы в нее записали какие-то данные. Свободного места осталось много. Неправильно будет просто выкинуть страницу, чтобы она где-то валялась и больше не использовалась.
Информация о том, в каких страницах есть свободное место, которое имеет смысл учитывать, хранится в структуре данных «свободный список» (freelist). Если в данной реализации и в данный момент страница содержит меньше 8 байтов, она во freelist не попадает, потому что не будет такой пары ключ-значение, которая поместилась бы в 8 байтов.
После того, как мы разобрались со страницами данных и оценили их количество, можно оценить количество индексных страниц, которые нам понадобятся.
Любой индекс Apache Ignite представляет собой B-дерево. Это означает, что на нижнем — самом широком — уровне находятся ссылки на абсолютно все пары ключ-значение. Индекс начинается с корневой страницы. На каждой из внутренних страниц есть ссылки на нижерасположенный уровень.
У индекса, который является первичным ключом, размер элемента, записываемого в индексную страницу, составляет 12 байтов. В зависимости от того, на какую страницу вы смотрите, — на внутреннюю или на лист, — у вас будет различное количество максимальных элементов. Если возьметесь за такую численную оценку, то посмотреть количество максимальных элементов можно в коде. Для первичного индекса размер ссылки всегда фиксирован и равен 12 байтам. Чтобы грубо подсчитать максимальное количество элементов страницы, вы можете поделить размер страницы (по умолчанию 4 мегабайта) на 12 байтов.
С учетом роста дерева можно считать, что каждая страница будет заполнена от 50 % до 75 %, в зависимости от порядка загрузки данных. Учитывая, что нижний уровень дерева содержит все элементы, вы также можете оценить количество страниц, необходимое для хранения индекса.
Что касается SQL-индексов — или вторичных, — то здесь размер элемента, сохраняемого в странице, зависит от сконфигурированного inline size. Нужно очень внимательно проанализировать модель данных, чтобы вычислить количество индексных страниц.
Много вопросов вызывает дополнительное потребление памяти на единичную партицию. Чтобы запустить пустой кэш, в котором в каждой из партиций записано буквально по одному элементу, требуется существенный объем памяти. Дело в том, что при такой структуре все необходимые метаданные должны быть инициализированы для каждой партиции.
<иллюстрация>
Количество партиций по умолчанию равно 1024, поэтому если вы запускаете один узел и начинаете писать по одному элементу в каждую партицию, то у вас сразу инициализируется очень большое количество метастраниц, за счет чего получаются такие большие первоначальные накладные расходы по памяти.
При эмпирическом подходе вы будете грузить достаточно большое количество данных, и расход памяти на партицию становится менее заметен. Но его стоит учитывать для более точной оценки. Если сложить накладные расходы по памяти на партицию, на все страницы данных и индексные страницы, то можно достаточно точно посчитать необходимы объём памяти.
Как можно облегчить жизнь пользователя в будущем? Apache Ignite движется в сторону SQL-систем, и есть много идей по уменьшению накладных расходов.
Можно поменять бинарный формат, чтобы уменьшить размер заголовка. Если перейти на более строго типизированную структуру данных в каком-либо из кэшей, но не получится перемешивать объекты, но зато снизится объём потребляемой памяти.
Второе решение — группировать в страницах объекты одного типа и выделять заголовок или его часть. В этом случае Apache Ignite будет самостоятельно дедуплицировать данные уже на уровне страницы.
Ещё одна разумная идея: реализовать настраиваемый порог учета данных во freelist. Если вы понимаете, что страницы будут фрагментироваться таким образом, что в них будет оставаться 100 байт, а ваши данные меньше 100 байт никогда не бывают, то имеет смысл подкрутить freelist, чтобы страницы туда не попадали и не расходовали место в этом самом freelist.
Активно обсуждается и выполняемое системой сжатие данных на уровне страницы, прозрачное для пользователя. Есть некоторые технические сложности, но в общем случае вы будете жертвовать производительностью в пользу более компактного размещения данных.
И последняя, очень востребованная оптимизация — калькулятор ёмкости кластера. Большой вопрос в том, что будет являться входом для такой утилиты. Видится такая схема: пользователь загружает в калькулятор структуру объектов, указывает, сколько строчек планирует загрузить, а калькулятор говорит, какой объем памяти необходим с учётом всех индексов и внутренних накладных расходов Apache Ignite.
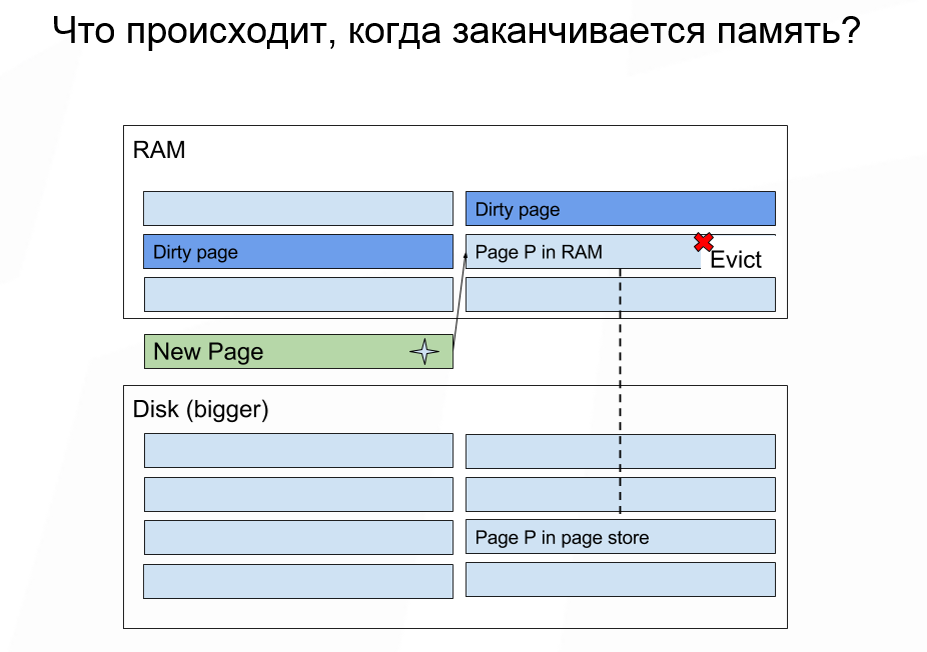
Сколько нам нужно выделить памяти, при условии, что объем сохраняемых данных больше, чем объем имеющейся памяти? Если у вас заканчивается память, то Apache Ignite поступает приблизительно также, как ОС: выкидывает некоторые данные из памяти и подгружает необходимые. Некоторые данные выкинуть нельзя, но для большинства случаев это не важно.
Здесь нужно помнить, что сам вид страницы не подразумевает запись. Выкидывание данных из памяти стоит дёшево. А последующее чтение данных, для которых произошел промах с диска — операция дорогая. В большинстве случаев самая важная характеристика, на которую стоит обращать внимание, это сколько IOPS может выдавать ваш диск. Если вы работаете с облачным развёртыванием, то узнать количество IOPS очень легко.
Например, запуская и монтируя образ в Amazon, вы среди дисков можете выбрать те, у которых указана скорость записи в Мб/сек. Но, по нашему опыту, куда полезней знать IOPS. Так как мы оперируем страницами, то, по факту, IOPS — это максимальное количество операций чтения или записи, которые мы можем выполнить на диске за единицу времени.
Как выбирается страница, которая будет выкинута из памяти? Сейчас это делается по алгоритму random LRU. Apache Ignite содержит в памяти страницу, которая хранит отображение того самого идентификатора страницы на конкретный физический адрес в памяти, где лежат данные. Когда нам нужно выкинуть какую-то из страниц, мы берем из этой таблицы n случайных страниц и выбираем самую старую. Она не всегда будет самая старая в абсолютном смысле. Но чаще всего мы будем попадать в одну n-ную часть, где n — количество образцов, которые мы выбираем.
На сегодняшний день алгоритм random LRU не устойчив к полному сканированию, но у нас уже есть реализация алгоритма random LRU 2, который используется в Apache Ignite для другой задачи. А когда мы применим random LRU 2 для вытеснения страниц, проблема устойчивости к полному сканированию будет решена.
Вытеснение страниц существенно влияет на задержку при единичной операции в кэше. Худшая ситуация: у вас был какой-то малоиспользуемый SQL-индекс или регион в кэше, и получилось так, что абсолютно все страницы этого региона были вытеснены на диск, то есть выкинуты из памяти. Если вы обратитесь к какому-то ключу, который будет обращаться ко всем n страницам, они будут последовательно читаться с диска. И нам нужно минимизировать объём возможного чтения с диска.
Начиная с Apache Ignite 2.3 появилась возможность разделять кэши по разным data-регионам. Если вы знаете, что у вас есть подмножество горячих данных, и вы наверняка будете с ними работать, а также есть подмножество данных, которое является историческим, то имеет смысл эти подмножества разделить по разным data-регионам.
Также для определения пропорции диск/память всегда нужно следить не за медианой или средним временем доступа при единичной операции в кэше, а за перцентилями, потому что они являются наиболее полным способом представления информации.
При худшем развитии событий, в одном проценте случаев задержка будет существенно выше, потому что страницы приходится считывать с диска. Если вы будете смотреть просто на среднее, то никогда не заметите эту особенность. Если вам важны строгие SLA, то просто необходимо анализировать перцентили при определении пропорции.
Последняя вещь, которую стоит упомянуть: не запускайте много узлов Apache Ignite с включенным persistence на одном и том же физическом носителе. Поскольку физически диск один, количество IOPS делится между узлами Apache Ignite. Мало того, что вы делите пропускную способность между узлами, вдобавок к этому каждый из узлов может исчерпать ёмкость по IOPS, и поведение всего кластера станет непредсказуемым.
Если по каким-то причинам хочется запустить несколько узлов Apache Ignite на одной машине, то обязательно следите за тем, чтобы физические хранилища для узлов были разные. Это в дополнение к рекомендации выносить Write-Ahead Log на отдельный физический носитель.
Не стоит использовать сеть с пропускной способностью меньше 1 гигабита. Сегодня мало у кого есть сети с меньшей пропускной способностью. Выбор CPU очень сильно зависит от профиля нагрузки, от количества индексов. Здесь стоит вернуться к эмпирическому подходу и просто сгенерировать профиль нагрузки, ожидаемой для вашего приложения, и аккуратно мониторить все показатели системы. Если вы видите, что какой-то из ресурсов полностью исчерпан, то имеет смысл его добавить.
Мы приветствуем любые вопросы или идеи по улучшению Apache Ignite.
Присоединяйтесь к нашим встречам в Москве и Санкт-Петербурге.
Участников сообщества Apache Ignite часто спрашивают: «Сколько нужно узлов и памяти для того, чтобы загрузить такой-то объем данных?» Об этом и я хочу сегодня поговорить. Забегая вперёд: такое прогнозирование пока что является достаточно сложной, нетривиальной задачей. Для этого нужно немного разбираться в устройстве Apache Ignite. Также я расскажу, как упросить себе задачу прогнозирования, и какие можно применять оптимизации.
Итак, очень часто к нам приходят пользователи и говорят: «У нас есть данные, представленные в виде файлов. Сколько нужно памяти, чтобы транслировать эти данные в Apache Ignite?».
При такой постановке ответить на вопрос практически невозможно, потому что разные форматы файлов транслируются в совершенно разные модели. К примеру, файл может быть сжат. А если он не сжат в какой-то классический бинарный вид, но может дедуплицирование данных, значит файл сжат в неявном виде.
Также не стоит забывать, что Apache Ignite обеспечивает быстрый доступ к данным по различным ключам либо SQL-индексам, поэтому в дополнение к данным, которые лежат в файле, мы строим дополнительные индексы, с которыми связаны дополнительные расходы. Так что в общем случае неверно говорить, что единичный индекс добавит какой-то процент от общего объема данных, поскольку индексируемое поле может иметь разный размер. То есть неправильно выделять на индекс фиксированный процент памяти.
Давайте переформулируем задачу. Мы говорим, что наша модель состоит из нескольких типов, и хорошо понимаем структуру каждого типа. Более того, если в модели есть поля вариативного размера, скажем, строковые, то можем примерно оценить минимальный и максимальный размер данных, а также распределение размеров во всему набору данных. Исходя из того, сколько у нас типов данных и какой объём информации по каждому типу, мы будем планировать количество памяти и дисков.
Эмпирический подход
Эмпирический подход может быть немного неточен, но, с точки зрения пользователя, не требует какого-то глубокого погружения в структуру системы. Суть подхода в следующем.
Берёте репрезентативную выборку данных и загружаете в Apache Ignite. Во время загрузки наблюдаете за увеличением размера хранилища. На определённых объёмах можно делать «отсечки», чтобы потом линейно экстраполировать и спрогнозировать необходимый объём хранилища для всего набора данных.
Здесь обычно задают хороший вопрос: «Какой должна быть репрезентативная выборка?»
Однажды мы генерировали выборку случайным образом. Но оказалось, что генератор собрал данные таким образом, что в набор входили остатки от деления при генерировании. В какой-то момент выяснилось, что наши случайные строки, которые должны были иметь равномерное распределение, на самом деле этого распределения не имели. Поэтому, когда будете оценивать объём хранилища, убедитесь, что в репрезентативной выборке действительно выполняются распределения, которыми вы оперируете.
Также обратите внимание на разброс размеров ваших объектов. Если вы предполагаете, что они будут одинаковой длины, то, в целом, для репрезентативной выборки достаточно небольшого количества объектов. Чем больше вариативность, чем больше комбинаций размеров полей, тем большую выборку нужно будет загрузить, чтобы понять зависимость. По своему опыту скажу, что зависимость начинает проясняться где-то с миллиона объектов, которые грузятся в одну партицию на один узел.
За чем именно нужно следить в ходе загрузки репрезентативной выборки? Если вы работаете с persistence, можно смотреть на объем файлов, которые у вас получаются. Или можете просто включить метрики данных региона, метрики в конфигурации Apache Ignite и через MX Bean мониторить увеличение памяти, делая «отсечки» и строя график.
Численная оценка
В данном случае мы пройдём по всем стадиям изменения структуры данных, которые претерпевает ваш объект при сохранении в Apache Ignite, а также посмотрим на окружающие структуры данных, которые могут увеличивать потребление памяти. Когда мы поймем, какие происходят изменения и какие структуры данных меняются, мы сможем достаточно точно оценить количество памяти, необходимое для загрузки данных.
Проанализируем операцию cash put при записи в Apache Ignite. Данные проходят через 4 стадии преобразований:
Первая стадия опциональная, потому что некоторые пользователи работают с классом и передают в Apache Ignite Java-объект. Некоторые пользователи создают бинарный объект напрямую, поэтому первая стадия конвертации объекта пропускается. Но если вы работаете с Java-объектами, то это первая трансформация, которую претерпевает объект.
После конвертации Java-объекта в бинарный объект у нас получается класс-независимый формат. Суть его в том, что вы можете оперировать бинарными объектами в кластере, не имея описания классов. Это позволяет вам изменять структуру класса и выполнять так называемый роллинг изменения структуры объектов. То есть ваша модель растет, изменяется, и вы получаете возможность работать со своими данными не меняя классы, не разворачивая их в кластере.
Третья стадия изменений, вносящая дополнительный overhead — запись на диск. Единицей работы с диском традиционно является страница. И начиная с Apache Ignite 2.0 мы перешли на страничную архитектуру. Это означает, что у каждой страницы есть опциональные заголовки, какие-то метаданные, которые тоже занимают место при записи объектов в страницу.
И последний кусочек, который тоже необходимо учитывать — обновление индекса. Даже если вы не используете SQL, в Apache Ignite у вас есть быстрый доступ по ключу. Это основной API кэша Apache Ignite. Поэтому всегда строится индекс первичного ключа, и на него тоже тратится место.
Это наш бинарный объект:
Не будем сильно углубляться в структуру, в общем виде её можно представить как некий заголовок, потом поля, наши существенные данные и футер. Заголовок бинарного объекта занимает 24 байта. Возможно, это много, но столько необходимо для поддержки изменяемости объектов без классов.
Если модель данных, которые вы кладете в кэш, предполагает какую-то развесистую внутреннюю структуру, то, возможно, стоит посмотреть, нельзя ли заинлайнить какие-то маленькие объекты в ваш исходный большой объект? В принципе, такой инлайнинг будет вам экономить по 24 байта на объект, что при достаточно большой развесистости модели дает существенный прирост.
Размер футера зависит от флага compactFooter, который позволяет записывать структуру объекта в дополнительные метаданные. То есть вместо того, чтобы писать порядок полей в самом объекте, мы их сохраняем отдельно. И если compactFooter равен true, то футер будет очень маленьким. Но при этом Apache Ignite совершает дополнительные действия для сохранения и поддержки этих метаданных. Если же compactFooter равен false, то объект является самодостаточным и его структуру можно считать без дополнительных метаданных.
На данный момент в нашем публичном API нет метода, возвращающего размер бинарного объекта. Поэтому если вам это очень интересно, можете сделать хак и привести объект к имплементации, тогда увидите его размер. Я думаю, в Apache Ignite 2.5 мы добавим метод, который позволит получить размер объекта.
Страничная архитектура
Как я уже сказал, единицей работы с диском является страница. Это сделано для оптимизации чтения и записи на диск. Но при этом накладывает ограничения на внутреннюю архитектуру Apache Ignite, поскольку любые структуры данных, которые будут сохраняться на диск, также должны работать со страницами.
Иными словами, из кирпичиков-страниц строится любая структуры данных, будь то дерево или freelist. Страницы ссылаются друг на друга по уникальному идентификатору. По этому же уникальному идентификатору мы можем за константное время определить файл, из которого эти страницы можно считать, с какого смещения будет считана из этого файла та или иная страница.
Единичный раздел, который разбит на множество страниц, можно представить в виде вот такой схемы:
Стартовая метастраница позволяет достигнуть любой другой страницы. Они делятся на разные типы, которых достаточно много, но для упрощения примера скажу, что у нас есть:
- страницы данных, которые хранят данные;
- индексные страницы, которые позволяют построить дерево индекса;
- вспомогательные страницы для таких структур, как freelist или метаданные.
Зачем это нужно, мы поговорим чуть ниже.
Начнем со страницы данных. Этот блок принимает наш ключ и значение, когда мы записываем данные в Apache Ignite. Сначала берётся страница данных, которая сможет вместить нашу информацию, и в неё записываются данные. Когда ссылка на них получена, записывается информация в индекс.
Страница данных имеет табличную организацию. В начале есть таблица, которая содержит смещение до пар ключ-значение. Сами пары ключ-значение пишутся в обратном порядке. Самая первая запись расположена в конце страницы. Это сделано для того, чтобы было удобнее работать со свободным местом. Вы спросите, зачем было так усложнять? Почему нельзя писать данные сразу на страницу и ссылаться по смещению внутри страницы? Это сделано для дефрагментации страницы.
Если здесь удалить запись № 2, то образуются две свободные зоны. Вполне возможно, что запись № 3 в будущем понадобится передвинуть вправо, чтобы вместить сюда более крупную запись. И если у нас есть непрямая адресация, то вы просто меняете смещение соответствующей записи в таблице. При этом внешняя ссылка, которая ссылается на эту страницу, остается константной.
Строка может быть фрагментирована в том смысле, что её размер будет больше размера страницы. В этом случае мы возьмем пустую страницу и в нее запишем хвостовую часть строки, а остаток — в страницу данных.
Помимо ключа и значения в страницу данных записывается и вспомогательная информация для корректной работы системы, например, номер версии. Если у вас используется expire policy, туда же пишется expiry time. В общем случае дополнительные метаданные занимают 35 байт. После того, как вы узнали размер бинарного объекта и ключа, вы добавляете 35 байт и получаете объём конкретной записи в странице данных. И затем высчитываете, сколько записей умещается в странице.
Может оказаться, что в странице данных останется свободное место, в которое не поместится ни одна из записей. Тогда в метриках вы увидите fill-фактор, который не равен 1.
И пара слов о процедуре записи. Допустим, у вас была пустая страница и вы в нее записали какие-то данные. Свободного места осталось много. Неправильно будет просто выкинуть страницу, чтобы она где-то валялась и больше не использовалась.
Информация о том, в каких страницах есть свободное место, которое имеет смысл учитывать, хранится в структуре данных «свободный список» (freelist). Если в данной реализации и в данный момент страница содержит меньше 8 байтов, она во freelist не попадает, потому что не будет такой пары ключ-значение, которая поместилась бы в 8 байтов.
После того, как мы разобрались со страницами данных и оценили их количество, можно оценить количество индексных страниц, которые нам понадобятся.
Любой индекс Apache Ignite представляет собой B-дерево. Это означает, что на нижнем — самом широком — уровне находятся ссылки на абсолютно все пары ключ-значение. Индекс начинается с корневой страницы. На каждой из внутренних страниц есть ссылки на нижерасположенный уровень.
У индекса, который является первичным ключом, размер элемента, записываемого в индексную страницу, составляет 12 байтов. В зависимости от того, на какую страницу вы смотрите, — на внутреннюю или на лист, — у вас будет различное количество максимальных элементов. Если возьметесь за такую численную оценку, то посмотреть количество максимальных элементов можно в коде. Для первичного индекса размер ссылки всегда фиксирован и равен 12 байтам. Чтобы грубо подсчитать максимальное количество элементов страницы, вы можете поделить размер страницы (по умолчанию 4 мегабайта) на 12 байтов.
С учетом роста дерева можно считать, что каждая страница будет заполнена от 50 % до 75 %, в зависимости от порядка загрузки данных. Учитывая, что нижний уровень дерева содержит все элементы, вы также можете оценить количество страниц, необходимое для хранения индекса.
Что касается SQL-индексов — или вторичных, — то здесь размер элемента, сохраняемого в странице, зависит от сконфигурированного inline size. Нужно очень внимательно проанализировать модель данных, чтобы вычислить количество индексных страниц.
Много вопросов вызывает дополнительное потребление памяти на единичную партицию. Чтобы запустить пустой кэш, в котором в каждой из партиций записано буквально по одному элементу, требуется существенный объем памяти. Дело в том, что при такой структуре все необходимые метаданные должны быть инициализированы для каждой партиции.
<иллюстрация>
Количество партиций по умолчанию равно 1024, поэтому если вы запускаете один узел и начинаете писать по одному элементу в каждую партицию, то у вас сразу инициализируется очень большое количество метастраниц, за счет чего получаются такие большие первоначальные накладные расходы по памяти.
При эмпирическом подходе вы будете грузить достаточно большое количество данных, и расход памяти на партицию становится менее заметен. Но его стоит учитывать для более точной оценки. Если сложить накладные расходы по памяти на партицию, на все страницы данных и индексные страницы, то можно достаточно точно посчитать необходимы объём памяти.
Оптимизации
Как можно облегчить жизнь пользователя в будущем? Apache Ignite движется в сторону SQL-систем, и есть много идей по уменьшению накладных расходов.
Можно поменять бинарный формат, чтобы уменьшить размер заголовка. Если перейти на более строго типизированную структуру данных в каком-либо из кэшей, но не получится перемешивать объекты, но зато снизится объём потребляемой памяти.
Второе решение — группировать в страницах объекты одного типа и выделять заголовок или его часть. В этом случае Apache Ignite будет самостоятельно дедуплицировать данные уже на уровне страницы.
Ещё одна разумная идея: реализовать настраиваемый порог учета данных во freelist. Если вы понимаете, что страницы будут фрагментироваться таким образом, что в них будет оставаться 100 байт, а ваши данные меньше 100 байт никогда не бывают, то имеет смысл подкрутить freelist, чтобы страницы туда не попадали и не расходовали место в этом самом freelist.
Активно обсуждается и выполняемое системой сжатие данных на уровне страницы, прозрачное для пользователя. Есть некоторые технические сложности, но в общем случае вы будете жертвовать производительностью в пользу более компактного размещения данных.
И последняя, очень востребованная оптимизация — калькулятор ёмкости кластера. Большой вопрос в том, что будет являться входом для такой утилиты. Видится такая схема: пользователь загружает в калькулятор структуру объектов, указывает, сколько строчек планирует загрузить, а калькулятор говорит, какой объем памяти необходим с учётом всех индексов и внутренних накладных расходов Apache Ignite.
Определение пропорции диск/память
Сколько нам нужно выделить памяти, при условии, что объем сохраняемых данных больше, чем объем имеющейся памяти? Если у вас заканчивается память, то Apache Ignite поступает приблизительно также, как ОС: выкидывает некоторые данные из памяти и подгружает необходимые. Некоторые данные выкинуть нельзя, но для большинства случаев это не важно.
Здесь нужно помнить, что сам вид страницы не подразумевает запись. Выкидывание данных из памяти стоит дёшево. А последующее чтение данных, для которых произошел промах с диска — операция дорогая. В большинстве случаев самая важная характеристика, на которую стоит обращать внимание, это сколько IOPS может выдавать ваш диск. Если вы работаете с облачным развёртыванием, то узнать количество IOPS очень легко.
Например, запуская и монтируя образ в Amazon, вы среди дисков можете выбрать те, у которых указана скорость записи в Мб/сек. Но, по нашему опыту, куда полезней знать IOPS. Так как мы оперируем страницами, то, по факту, IOPS — это максимальное количество операций чтения или записи, которые мы можем выполнить на диске за единицу времени.
Как выбирается страница, которая будет выкинута из памяти? Сейчас это делается по алгоритму random LRU. Apache Ignite содержит в памяти страницу, которая хранит отображение того самого идентификатора страницы на конкретный физический адрес в памяти, где лежат данные. Когда нам нужно выкинуть какую-то из страниц, мы берем из этой таблицы n случайных страниц и выбираем самую старую. Она не всегда будет самая старая в абсолютном смысле. Но чаще всего мы будем попадать в одну n-ную часть, где n — количество образцов, которые мы выбираем.
На сегодняшний день алгоритм random LRU не устойчив к полному сканированию, но у нас уже есть реализация алгоритма random LRU 2, который используется в Apache Ignite для другой задачи. А когда мы применим random LRU 2 для вытеснения страниц, проблема устойчивости к полному сканированию будет решена.
Вытеснение страниц существенно влияет на задержку при единичной операции в кэше. Худшая ситуация: у вас был какой-то малоиспользуемый SQL-индекс или регион в кэше, и получилось так, что абсолютно все страницы этого региона были вытеснены на диск, то есть выкинуты из памяти. Если вы обратитесь к какому-то ключу, который будет обращаться ко всем n страницам, они будут последовательно читаться с диска. И нам нужно минимизировать объём возможного чтения с диска.
Начиная с Apache Ignite 2.3 появилась возможность разделять кэши по разным data-регионам. Если вы знаете, что у вас есть подмножество горячих данных, и вы наверняка будете с ними работать, а также есть подмножество данных, которое является историческим, то имеет смысл эти подмножества разделить по разным data-регионам.
Также для определения пропорции диск/память всегда нужно следить не за медианой или средним временем доступа при единичной операции в кэше, а за перцентилями, потому что они являются наиболее полным способом представления информации.
При худшем развитии событий, в одном проценте случаев задержка будет существенно выше, потому что страницы приходится считывать с диска. Если вы будете смотреть просто на среднее, то никогда не заметите эту особенность. Если вам важны строгие SLA, то просто необходимо анализировать перцентили при определении пропорции.
Последняя вещь, которую стоит упомянуть: не запускайте много узлов Apache Ignite с включенным persistence на одном и том же физическом носителе. Поскольку физически диск один, количество IOPS делится между узлами Apache Ignite. Мало того, что вы делите пропускную способность между узлами, вдобавок к этому каждый из узлов может исчерпать ёмкость по IOPS, и поведение всего кластера станет непредсказуемым.
Если по каким-то причинам хочется запустить несколько узлов Apache Ignite на одной машине, то обязательно следите за тем, чтобы физические хранилища для узлов были разные. Это в дополнение к рекомендации выносить Write-Ahead Log на отдельный физический носитель.
Планирование CPU и пропускной способности сети
Не стоит использовать сеть с пропускной способностью меньше 1 гигабита. Сегодня мало у кого есть сети с меньшей пропускной способностью. Выбор CPU очень сильно зависит от профиля нагрузки, от количества индексов. Здесь стоит вернуться к эмпирическому подходу и просто сгенерировать профиль нагрузки, ожидаемой для вашего приложения, и аккуратно мониторить все показатели системы. Если вы видите, что какой-то из ресурсов полностью исчерпан, то имеет смысл его добавить.
Мы приветствуем любые вопросы или идеи по улучшению Apache Ignite.
Присоединяйтесь к нашим встречам в Москве и Санкт-Петербурге.

