
Первая и вторая часть «Оценка ThunderX2 от Cavium: сбылась мечта об Arm сервере».
SPECjbb 2015 – это тест Java Business Benchmark, который используется для оценки производительности серверов, на которых работают типичные Java-приложения. Он использует новейшие функции Java 7 и XML, messanging with security.

Обратите внимание, что мы обновили версию SPECjbb 1.0 до версии 1.01.

Мы протестировали SPECjbb с четырьмя группами инжекторов транзакций и бэк-эндов. Причина, по которой мы используем тест Multi JVM, заключается в том, что он более приближен к реальным условиям: несколько виртуальных машин на сервере — распространенная практика, особенно на серверах с более 100 потоками. Версия Java — OpenJDK 1.8.0_161.
Каждый раз, когда мы публикуем результаты SPECjbb, получаем комментарии о том, что наши показатели слишком низкие. Поэтому мы решили потратить немного больше времени и уделить внимание различным настройкам.
В производственных условиях настройка должна быть простой и, желательно, не слишком специфичной для машины. С этой целью мы применили два вида настроек. Первая из них — очень простая настройка для измерения производительности «из коробки», чтобы разместить все на сервере с 128 ГБ оперативной памяти:
Для второй настройки, в поисках наилучшего показателя пропускной способности, играли с «-XX: + AlwaysPreTouch», «-XX: -UseBiasedLocking» и «specjbb.forkjoin.workers». «+ AlwaysPretouch» перед запуском обнуляет все страницы памяти, что снижает влияние производительности на новые страницы. «-UseBiasedLockin» отключает baised блокировку, которая по умолчанию включена. Biased locking отдает приоритет потоку, который уже загрузил contended данные в кэш. Обратная сторона Biased locking — достаточно сложные дополнительные процессы (Rebias), которые могут снизить производительность, в случае неверно выбранной стратегии.
График ниже демонстрирует максимальные показатели производительности для нашего теста MultiJVM SPECJbb.

ThunderX2 достигает показателей от 80 до 85% производительности Xeon 8176. Этого показателя вполне достаточно, чтобы превзойти Xeon 6148. Что интересно, системы Intel и Cavium разными путями достигают своих лучших результатов. В случае Dual ThunderX2 мы использовали:
В то время как система Intel достигла наилучшей производительности, оставив при этом смещенную блокировку (по умолчанию). Мы заметили, что система Intel — вероятно, из-за относительно «нечетного» количества потоков — имеет немного более низкую среднюю нагрузку на процессор (несколько процентов) и больший L3-кэш, что делает предвзятую блокировку хорошей стратегией для этой архитектуры.
Наконец, у нас есть Critical-jOPS, который измеряет пропускную способность по ограничениям времени ответа.
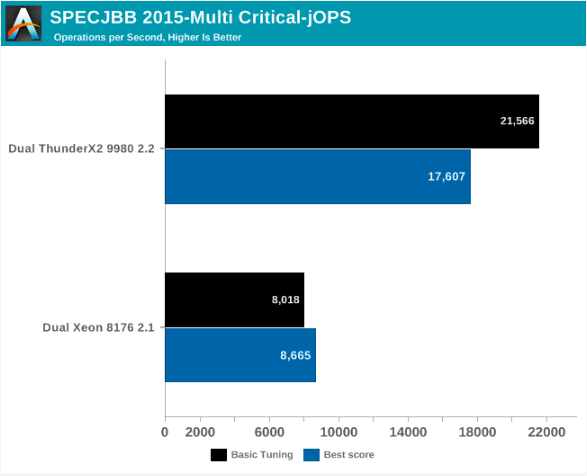
При активном использовании большого количества потоков вы можете получить значительно больше Critical-jOPS, увеличив распределение ОЗУ на JVM. Удивительно, но система Dual ThunderX2 — с ее более высоким количеством потоков и более низкой тактовой частотой – показывает лучшее время, обеспечивая высокую пропускную способность, сохраняя при этом 99-процентное время отклика на определенный предел.
Увеличение heap size помогает Intel немного закрыть промежуток (до x2), но за счет пропускной способности (от -20% до -25%). Похоже, что чип Intel нуждается в большей настройке, чем в ARM. Чтобы исследовать это дальше, мы обратились к «Transparant Huge Pages» (THP).
Обычно для ЦП редко кто-то переигрывает другого в factor 3, но мы решились исследовать вопрос глубже. Самым очевидным кандидатом был «Огромные страницы», или как все, кроме сообщества Linux, называет его «Большие страницы» («Large Pages».)
Каждый современный процессор кэширует сопоставления виртуальной и физической памяти в своих TLB. «Обычный» размер страницы составляет 4 КБ, поэтому с 1536 элементами ядро Skylake может кэшировать около 6 МБ на ядро. За последние 15 лет емкость DRAM выросла от нескольких ГБ до сотен ГБ, а следовательно и промахи TLB стали доставлять беспокойство. Промах TLB довольно дорого стоит — необходимо несколько обращений к памяти, чтобы прочитать несколько таблиц и наконец-то найти физический адрес.
Все современные процессоры поддерживают большие страницы. В x86-64 (Intel и AMD) популярная опция — 2 МБ, также доступна 1 ГБ страница. Между тем большая страница на ThunderX2 составляет не менее 0,5 ГБ. Использование больших страниц уменьшает количество промахов TLB (хотя количество записей в TLB обычно значительно ниже для больших страниц), уменьшает количество обращений к памяти, необходимых при промахе TLB.
Тем не менее прошло время, прежде чем Linux поддержал эту функцию удобным для работы способом. Фрагментация памяти, конфликтующие и трудно настраиваемые настройки, несовместимости и особенно очень запутывающие имена вызвали массу проблем. Фактически, многие поставщики программного обеспечения по-прежнему советуют администраторам серверов отключать большие страницы.
С этой целью давайте посмотрим, что произойдет, если мы включим Transparent Huge Pages и сохраним лучшие настройки, которые обсуждались ранее.

В целом, для Max-jOPs влияние производительности не является чем-то захватывающим; на самом деле это небольшой регресс. Xeon теряет около 1% своей пропускной способности, ThunderX2 — около 5%.
Перейдем к рассмотрению метрики Critical-jOPS, где пропускная способность измеряется как 99 процентиль ограничения времени отклика.

Огромное различие! Вместо поражения, система Intel выходит за пределы показателей ThunderX2. Тем не менее следует сказать, что производительность с 4 КБ страницами, по-видимому, является серьезной слабостью в архитектуре Intel.
Последний в списке, но не по значению, нашем арсенале есть тест Apache Spark. Apache Spark является детищем Big Data processing. Ускорение приложений Big Data остается приоритетным проектом в университетской лаборатории, в которой я работаю (лаборатория Sizing Servers Lab University University of West-Flanders), поэтому мы подготовили ориентир, который использует многие функции Spark и основан на использовании в реальном мире.

Тест описан на схеме выше. Мы начинаем с 300 ГБ сжатых данных, собранных из CommonCrawl. Эти сжатые файлы представляют собой большое количество веб-архивов. Мы разархивируем данные «на лету», чтобы избежать длительного ожидания, которое в основном связано с устройством хранения. Затем мы извлекаем значимые текстовые данные из архивов, используя библиотеку Java «BoilerPipe». Используя Инструмент обработки естественного языка Stanford CoreNLP, мы извлекаем из текста сущности («слова, которые означают что-то»), а затем подсчитываем, какие URL-адреса имеют наибольшее вхождение этих объектов. Алгоритм Alternating Lessest Square используется, чтобы рекомендовать, какие URL-адреса являются наиболее интересными для определенного субъекта.
Чтобы добиться лучшего масштабирования, мы запускаем 4 исполнителя. Исследователь Эсли Хейваерт переконфигурировал тест Spark, чтобы он мог работать на Apache Spark 2.1.1.
Вот результаты:

(*) EPYC и Xeon E5 V4 являются более старыми, работают на Kernel 4.8 и немного старшей Java 1.8.0_131 вместо 1.8.0_161. Хотя мы ожидаем, что результаты будут очень похожими на ядре 4.13 и Java 1.8.0_161, поскольку мы не увидели большой разницы в Skylake Xeon между этими двумя настройками.
Обработка данных очень параллельна и очень интенсивно нагружает процессор, но для фаз «тасования» требуется много взаимодействий с памятью. Время, затрачиваемое на коммуникацию с устройством хранения, незначительно. Фаза ALS не масштабируется по многим потокам, но составляет менее 4% от общего времени тестирования.
ThunderX2 обеспечивает 87% производительности от вдвое более дорогого EPYC 7601. Так как этот показатель хорошо масштабируется с количеством ядер, мы можем оценить, что Xeon 6148 наберет около 4.8. на Apache Spark Таким образом, в то время как ThunderX2 не может реально угрожать Xeon Platinum 8176, он дает то же, что и Gold 6148 и его брат за куда меньшие деньги.
Подытожив все, наши тесты SPECInt показывают, что ядра ThunderX2 все еще имеют некоторые недостатки. Наше первое негативное впечатление заключается в том, что код интенсивного ветвления — особенно в сочетании с обычными промахами L3-кэша (высокая задержка DRAM) — работает довольно медленно. Таким образом, будут частные случаи, когда ThunderX2 не лучший выбор.
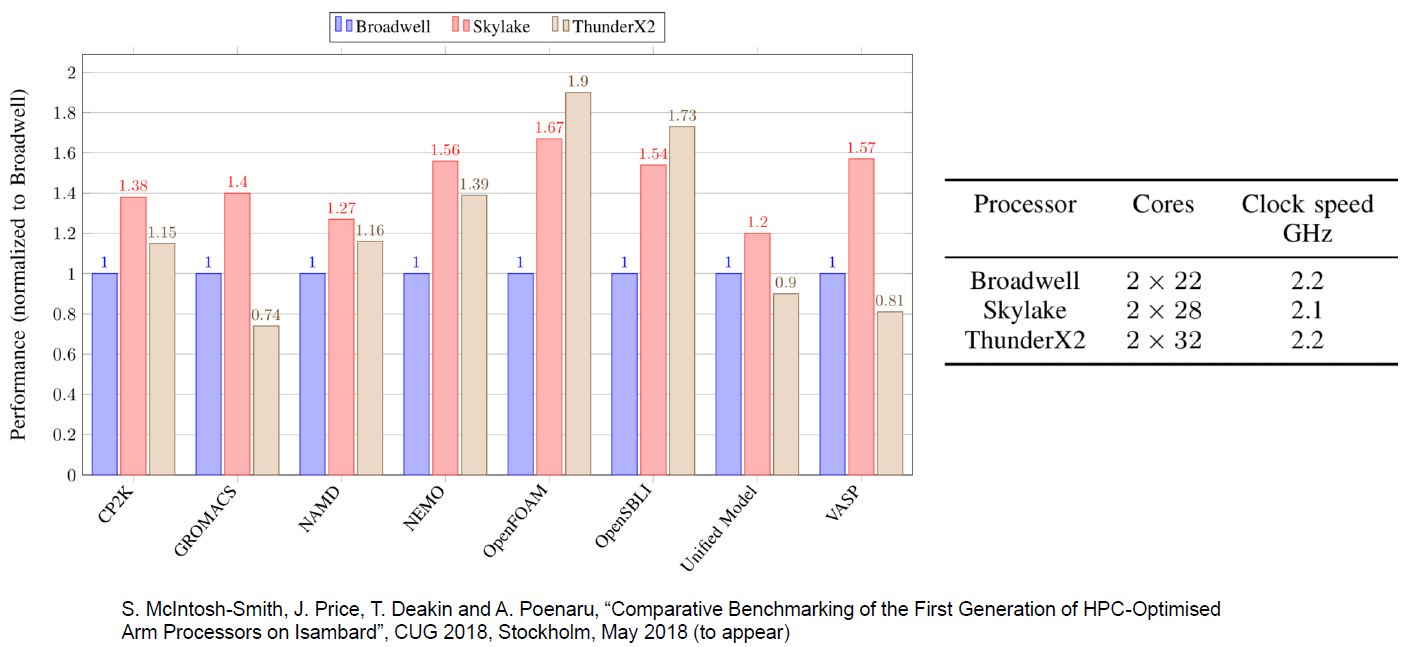
Однако, помимо некоторых нишевых рынков, мы вполне уверены, что ThunderX2 станет солидным исполнителем. Например, измерения производительности, выполненные нашими коллегами из Бристольского университета, подтверждают наше предположение, что интенсивные рабочие нагрузки HPC, такие как OpenFoam (CFD) и NAMD.run, действительно хорошо работают на ThunderX2
По итогам раннего тестирования программного обеспечения сервера, которое мы успели сделать, мы можем быть приятно удивлены. Производительность за доллар ThunderX2 как на Java Server (SPECJbb), так и на обработке больших данных — сейчас — безусловно, лучшая на рынке серверов. Мы должны повторно протестировать процессор AMD EPYC и золотую версию нынешнего поколения (Skylake) Xeon, но при этом 80-90% производительности процессора 8176 за одну четверть его стоимости будет очень сложно превзойти.
В качестве дополнительной выгоды для Cavium и ThunderX2, нужно упомянуть, что в 2018 году экосистема Arm Linux уже зрелая; специализированные ядра Linux и другие инструменты больше не нужны. Вы просто устанавливаете сервер Ubuntu, Red Hat или Suse, и вы можете автоматизировать развертывание и установку программного обеспечения из стандартных хранилищ. Это значительное улучшение по сравнению с тем, что мы пережили, когда был запущен ThunderX. Еще в 2016 году простая установка из обычных хранилищ Ubuntu могла вызвать проблемы.
Итак, в целом, ThunderX2 является очень мощным соперником. Это может быть даже более опасно для EPYC AMD, чем для Skylake Xeon от Intel благодаря тому, что и Cavium и AMD конкурируют за одну и ту же группу клиентов, учитывая возможность отказа от Intel. Это связано с тем, что клиенты, которые инвестировали в дорогостоящее корпоративное программное обеспечение (Oracle, SAP), менее чувствительны к стоимости на стороне оборудования, поэтому они значительно реже переходят на новую аппаратную платформу. И эти люди инвестировали последние 5 лет в Intel, поскольку это был единственный вариант.
Это, в свою очередь, означает, что те, кто является более гибким и чувствительным к цене, например, хостинг и облачные провайдеры, теперь смогут выбрать альтернативный сервер Arm с отличным соотношением «производительность за доллар». И с HP, Cray, Pengiun, Gigabyte, Foxconn и Inventec, предлагающими системы, основанные на ThunderX2, нет недостатка в качественных поставщиках.
Короче говоря, ThunderX2 является первым SoC, который способен конкурировать с Intel и AMD на рынке серверов центрального процессора. И это приятный сюрприз: наконец, появилось решение для серверов Arm!
Спасибо, что остаетесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас оформив заказ или порекомендовав знакомым, 30% скидка для пользователей Хабра на уникальный аналог entry-level серверов, который был придуман нами для Вас: Вся правда о VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps от $20 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
Dell R730xd в 2 раза дешевле? Только у нас 2 х Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 ТВ от $249 в Нидерландах и США! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5-2650 v4 стоимостью 9000 евро за копейки?
Производительность Java
SPECjbb 2015 – это тест Java Business Benchmark, который используется для оценки производительности серверов, на которых работают типичные Java-приложения. Он использует новейшие функции Java 7 и XML, messanging with security.
Обратите внимание, что мы обновили версию SPECjbb 1.0 до версии 1.01.
Мы протестировали SPECjbb с четырьмя группами инжекторов транзакций и бэк-эндов. Причина, по которой мы используем тест Multi JVM, заключается в том, что он более приближен к реальным условиям: несколько виртуальных машин на сервере — распространенная практика, особенно на серверах с более 100 потоками. Версия Java — OpenJDK 1.8.0_161.
Каждый раз, когда мы публикуем результаты SPECjbb, получаем комментарии о том, что наши показатели слишком низкие. Поэтому мы решили потратить немного больше времени и уделить внимание различным настройкам.
- Настройки ядра, такие как тайминги планировщика задач, очистка кэша страницы
- Отключение энергосберегающих функций, ручная настройка поведения c-state.
- Установка вентиляторов на максимальную скорость (потратим много энергии в пользу парочки дополнительных очков производительности)
- Отключение функций RAS (например, memory scrub)
- Многочисленные настройки различных параметров Java… Нереально, ведь каждый раз при запуске приложения на разных машинах (что довольно часто происходит в облачной среде) дорогостоящие специалисты должны проводить настройку параметров под конкретную машину, что, к тому же, может привести к остановке приложения на других машинах
- Настройка очень специфичных для SKU настроек NUMA и привязок ЦП. Миграция между двумя разными SKU в одном кластере может привести к серьезным проблемам с производительностью
В производственных условиях настройка должна быть простой и, желательно, не слишком специфичной для машины. С этой целью мы применили два вида настроек. Первая из них — очень простая настройка для измерения производительности «из коробки», чтобы разместить все на сервере с 128 ГБ оперативной памяти:
"-server -Xmx24G -Xms24G -Xmn16G"Для второй настройки, в поисках наилучшего показателя пропускной способности, играли с «-XX: + AlwaysPreTouch», «-XX: -UseBiasedLocking» и «specjbb.forkjoin.workers». «+ AlwaysPretouch» перед запуском обнуляет все страницы памяти, что снижает влияние производительности на новые страницы. «-UseBiasedLockin» отключает baised блокировку, которая по умолчанию включена. Biased locking отдает приоритет потоку, который уже загрузил contended данные в кэш. Обратная сторона Biased locking — достаточно сложные дополнительные процессы (Rebias), которые могут снизить производительность, в случае неверно выбранной стратегии.
График ниже демонстрирует максимальные показатели производительности для нашего теста MultiJVM SPECJbb.
ThunderX2 достигает показателей от 80 до 85% производительности Xeon 8176. Этого показателя вполне достаточно, чтобы превзойти Xeon 6148. Что интересно, системы Intel и Cavium разными путями достигают своих лучших результатов. В случае Dual ThunderX2 мы использовали:
'-server -Xmx24G -Xms24G -Xmn16G -XX:+AlwaysPreTouch -XX:-UseBiasedLockingВ то время как система Intel достигла наилучшей производительности, оставив при этом смещенную блокировку (по умолчанию). Мы заметили, что система Intel — вероятно, из-за относительно «нечетного» количества потоков — имеет немного более низкую среднюю нагрузку на процессор (несколько процентов) и больший L3-кэш, что делает предвзятую блокировку хорошей стратегией для этой архитектуры.
Наконец, у нас есть Critical-jOPS, который измеряет пропускную способность по ограничениям времени ответа.
При активном использовании большого количества потоков вы можете получить значительно больше Critical-jOPS, увеличив распределение ОЗУ на JVM. Удивительно, но система Dual ThunderX2 — с ее более высоким количеством потоков и более низкой тактовой частотой – показывает лучшее время, обеспечивая высокую пропускную способность, сохраняя при этом 99-процентное время отклика на определенный предел.
Увеличение heap size помогает Intel немного закрыть промежуток (до x2), но за счет пропускной способности (от -20% до -25%). Похоже, что чип Intel нуждается в большей настройке, чем в ARM. Чтобы исследовать это дальше, мы обратились к «Transparant Huge Pages» (THP).
Производительность Java: большие страницы
Обычно для ЦП редко кто-то переигрывает другого в factor 3, но мы решились исследовать вопрос глубже. Самым очевидным кандидатом был «Огромные страницы», или как все, кроме сообщества Linux, называет его «Большие страницы» («Large Pages».)
Каждый современный процессор кэширует сопоставления виртуальной и физической памяти в своих TLB. «Обычный» размер страницы составляет 4 КБ, поэтому с 1536 элементами ядро Skylake может кэшировать около 6 МБ на ядро. За последние 15 лет емкость DRAM выросла от нескольких ГБ до сотен ГБ, а следовательно и промахи TLB стали доставлять беспокойство. Промах TLB довольно дорого стоит — необходимо несколько обращений к памяти, чтобы прочитать несколько таблиц и наконец-то найти физический адрес.
Все современные процессоры поддерживают большие страницы. В x86-64 (Intel и AMD) популярная опция — 2 МБ, также доступна 1 ГБ страница. Между тем большая страница на ThunderX2 составляет не менее 0,5 ГБ. Использование больших страниц уменьшает количество промахов TLB (хотя количество записей в TLB обычно значительно ниже для больших страниц), уменьшает количество обращений к памяти, необходимых при промахе TLB.
Тем не менее прошло время, прежде чем Linux поддержал эту функцию удобным для работы способом. Фрагментация памяти, конфликтующие и трудно настраиваемые настройки, несовместимости и особенно очень запутывающие имена вызвали массу проблем. Фактически, многие поставщики программного обеспечения по-прежнему советуют администраторам серверов отключать большие страницы.
С этой целью давайте посмотрим, что произойдет, если мы включим Transparent Huge Pages и сохраним лучшие настройки, которые обсуждались ранее.
В целом, для Max-jOPs влияние производительности не является чем-то захватывающим; на самом деле это небольшой регресс. Xeon теряет около 1% своей пропускной способности, ThunderX2 — около 5%.
Перейдем к рассмотрению метрики Critical-jOPS, где пропускная способность измеряется как 99 процентиль ограничения времени отклика.
Огромное различие! Вместо поражения, система Intel выходит за пределы показателей ThunderX2. Тем не менее следует сказать, что производительность с 4 КБ страницами, по-видимому, является серьезной слабостью в архитектуре Intel.
Apache Spark 2.x Бенчмаркинг
Последний в списке, но не по значению, нашем арсенале есть тест Apache Spark. Apache Spark является детищем Big Data processing. Ускорение приложений Big Data остается приоритетным проектом в университетской лаборатории, в которой я работаю (лаборатория Sizing Servers Lab University University of West-Flanders), поэтому мы подготовили ориентир, который использует многие функции Spark и основан на использовании в реальном мире.
Тест описан на схеме выше. Мы начинаем с 300 ГБ сжатых данных, собранных из CommonCrawl. Эти сжатые файлы представляют собой большое количество веб-архивов. Мы разархивируем данные «на лету», чтобы избежать длительного ожидания, которое в основном связано с устройством хранения. Затем мы извлекаем значимые текстовые данные из архивов, используя библиотеку Java «BoilerPipe». Используя Инструмент обработки естественного языка Stanford CoreNLP, мы извлекаем из текста сущности («слова, которые означают что-то»), а затем подсчитываем, какие URL-адреса имеют наибольшее вхождение этих объектов. Алгоритм Alternating Lessest Square используется, чтобы рекомендовать, какие URL-адреса являются наиболее интересными для определенного субъекта.
Чтобы добиться лучшего масштабирования, мы запускаем 4 исполнителя. Исследователь Эсли Хейваерт переконфигурировал тест Spark, чтобы он мог работать на Apache Spark 2.1.1.
Вот результаты:
(*) EPYC и Xeon E5 V4 являются более старыми, работают на Kernel 4.8 и немного старшей Java 1.8.0_131 вместо 1.8.0_161. Хотя мы ожидаем, что результаты будут очень похожими на ядре 4.13 и Java 1.8.0_161, поскольку мы не увидели большой разницы в Skylake Xeon между этими двумя настройками.
Обработка данных очень параллельна и очень интенсивно нагружает процессор, но для фаз «тасования» требуется много взаимодействий с памятью. Время, затрачиваемое на коммуникацию с устройством хранения, незначительно. Фаза ALS не масштабируется по многим потокам, но составляет менее 4% от общего времени тестирования.
ThunderX2 обеспечивает 87% производительности от вдвое более дорогого EPYC 7601. Так как этот показатель хорошо масштабируется с количеством ядер, мы можем оценить, что Xeon 6148 наберет около 4.8. на Apache Spark Таким образом, в то время как ThunderX2 не может реально угрожать Xeon Platinum 8176, он дает то же, что и Gold 6148 и его брат за куда меньшие деньги.
И что же в итоге
Подытожив все, наши тесты SPECInt показывают, что ядра ThunderX2 все еще имеют некоторые недостатки. Наше первое негативное впечатление заключается в том, что код интенсивного ветвления — особенно в сочетании с обычными промахами L3-кэша (высокая задержка DRAM) — работает довольно медленно. Таким образом, будут частные случаи, когда ThunderX2 не лучший выбор.
Однако, помимо некоторых нишевых рынков, мы вполне уверены, что ThunderX2 станет солидным исполнителем. Например, измерения производительности, выполненные нашими коллегами из Бристольского университета, подтверждают наше предположение, что интенсивные рабочие нагрузки HPC, такие как OpenFoam (CFD) и NAMD.run, действительно хорошо работают на ThunderX2
По итогам раннего тестирования программного обеспечения сервера, которое мы успели сделать, мы можем быть приятно удивлены. Производительность за доллар ThunderX2 как на Java Server (SPECJbb), так и на обработке больших данных — сейчас — безусловно, лучшая на рынке серверов. Мы должны повторно протестировать процессор AMD EPYC и золотую версию нынешнего поколения (Skylake) Xeon, но при этом 80-90% производительности процессора 8176 за одну четверть его стоимости будет очень сложно превзойти.
В качестве дополнительной выгоды для Cavium и ThunderX2, нужно упомянуть, что в 2018 году экосистема Arm Linux уже зрелая; специализированные ядра Linux и другие инструменты больше не нужны. Вы просто устанавливаете сервер Ubuntu, Red Hat или Suse, и вы можете автоматизировать развертывание и установку программного обеспечения из стандартных хранилищ. Это значительное улучшение по сравнению с тем, что мы пережили, когда был запущен ThunderX. Еще в 2016 году простая установка из обычных хранилищ Ubuntu могла вызвать проблемы.
Итак, в целом, ThunderX2 является очень мощным соперником. Это может быть даже более опасно для EPYC AMD, чем для Skylake Xeon от Intel благодаря тому, что и Cavium и AMD конкурируют за одну и ту же группу клиентов, учитывая возможность отказа от Intel. Это связано с тем, что клиенты, которые инвестировали в дорогостоящее корпоративное программное обеспечение (Oracle, SAP), менее чувствительны к стоимости на стороне оборудования, поэтому они значительно реже переходят на новую аппаратную платформу. И эти люди инвестировали последние 5 лет в Intel, поскольку это был единственный вариант.
Это, в свою очередь, означает, что те, кто является более гибким и чувствительным к цене, например, хостинг и облачные провайдеры, теперь смогут выбрать альтернативный сервер Arm с отличным соотношением «производительность за доллар». И с HP, Cray, Pengiun, Gigabyte, Foxconn и Inventec, предлагающими системы, основанные на ThunderX2, нет недостатка в качественных поставщиках.
Короче говоря, ThunderX2 является первым SoC, который способен конкурировать с Intel и AMD на рынке серверов центрального процессора. И это приятный сюрприз: наконец, появилось решение для серверов Arm!
Спасибо, что остаетесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас оформив заказ или порекомендовав знакомым, 30% скидка для пользователей Хабра на уникальный аналог entry-level серверов, который был придуман нами для Вас: Вся правда о VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps от $20 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
Dell R730xd в 2 раза дешевле? Только у нас 2 х Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 ТВ от $249 в Нидерландах и США! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5-2650 v4 стоимостью 9000 евро за копейки?
