После прочтения статьи "Нейронный машинный перевод Google" вспомнился курсирующий последнее время в интернет очередной epic-fail машинного перевода от Google. Кому сильно не терпится сразу мотаем в низ статьи.
GNMT есть система нейронного машинного перевода (NMT) компании Google, которая использует нейросеть (ANN) для повышения точности и скорости перевода, и в частности для создания лучших, более естественных вариантов перевода текста в Google Translate.
В случае GNMT речь идет о так называемом методе перевода на основе примеров (EBMT), т.е. ANN, лежащая в основе метода, обучается на миллионах примеров перевода, причем в отличии от других систем этот метод позволяет выполнять так называемый zero-shot перевод, т. е. переводить с одного языка на другой, не имея явные примеры для этой пары конкретных языков в процессе обучения (в обучающей выборке).
Рис. 1. Zero-Shot Translation
Причем GNMT разработан в первую очередь для улучшения перевода фраз и предложений, т.к. как раз при контекстном переводе нельзя использовать дословный вариант перевода и нередко предложение переводится совершенно по другому.
Кроме того, возвращаясь к zero-shot translation, Google стараются при этом выделить некоторую общую составляющую, действительную сразу для нескольких языков (как при поиске зависимостей, так и при построении связей для предложений и фраз).
Например на рисунке 2, показана такая interlingua «общность» среди всех возможных пар для японского, корейского и английского языков.

Рис. 2. Interlingua. 3-мерное представление данных сети для японского, корейского и английского языков.
Часть (а) показывает общую «геометрию» таких переводов, где точки окрашены по смыслу (и одинаковым цветом для одного и того же смысла у нескольких пар языков).
Часть (b) показывает увеличение одной из групп, часть © в цветах исходного языка.
GNMT использует большую ANN глубокого обучения (DNN), которая, выученная на миллионах примеров, должна улучшать качество перевода, применяя контекстное абстрактное приближение для наиболее подходящего варианта перевода. Грубо говоря выбирает лучший, в смысле наиболее соответствующего грамматике человеческого языка, результат, при этом учитывая общности построения связей, фраз и предложений для нескольких языков (т.е. отдельно выделяя и обучая interlingua модель или слои).
Однако DNN как в процессе обучения так и в процессе работы как правило полагается на статистический (вероятностный) вывод и редко обвязывается дополнительными не вероятностными алгоритмами. Т.е. для оценки лучшего из возможных результатов, вышедших из вариатора, будет выбран статистически наиболее лучший (вероятный) вариант.
Всё это, естественным образом, дополнительно зависит от качества обучающей выборки (и/или качества алгоритмов в случае самообучающейся модели).
Учитывая сквозной (zero-shot) метод перевода и помня о некой общей (interlingua) составляющей, при наличии некоторой позитивной логической глубокой связи для одного языка, и отсутствии негативных составляющих для других языков, некоторая абстрактная ошибка, вылезшая в процессе обучения и соответственно в результате перевода некоторой фразы для одного языка, с большой долей вероятности повторится и для других языков или даже языковых пар.
Все картинки кликабельны (в качестве пруфа на соответствующую страницу Google Translate).
Немецкий:
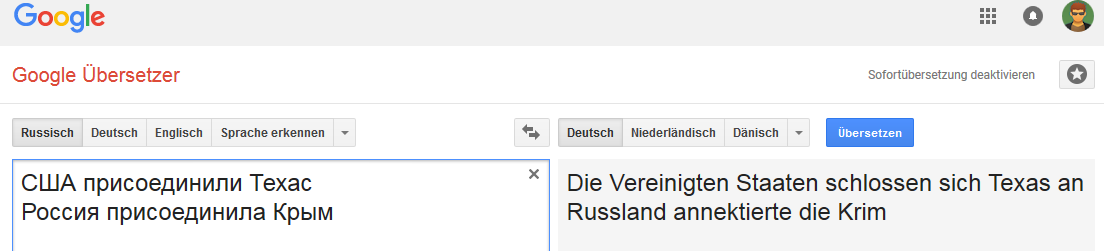
Английский:
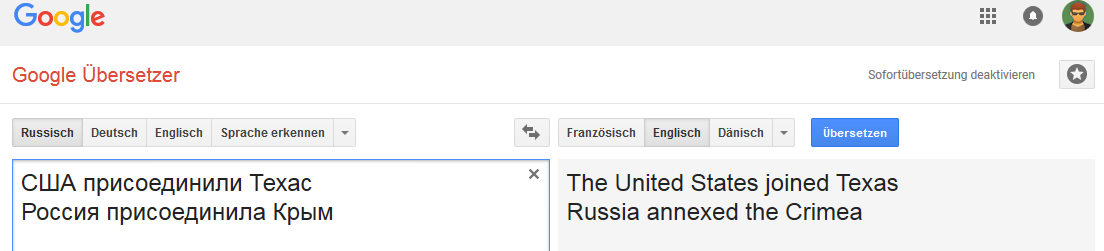
Нидерландский:

Датский:

Французский:

И т.д.
Связь устойчивая для слова Россия (в том смысле что при замене России, например на Российскую империю, вариант «перевода» меняется).
И не очень устойчива при некоторых изменениях фразы, не типичных для перевода на английский язык, но общих например для русского, немецкого и нидерландского языков.
Это к сожалению далеко не единственный случай и интернет пестрит всевозможными ошибками Google Translate.
И думается мне, что немалая часть существующих ошибок проявляется из-за совокупности нескольких факторов, начиная от собственно качества обучающей выборки и заканчивая качеством алгоритмов семантического и морфологического разбора для конкретного языка (и модели обучения в частности).
Как-то раз, один коллега предложил поучаствовать в Text Normalization Challenge (для русского и английского языков) от Google на kaggle…
Перед тем как согласиться, я сделал тогда небольшой анализ качества обучающей тестовой выборки для всех классов токенов для обоих языков… и в результате отказался участвовать вовсе, ибо чем больше я копал, тем сильнее было чувство что конкурс будет похож на лотерею или выиграет тот, кто наиболее максимально точно сможет повторить все ошибки, допущенные при полу-ручном создании Google обучающей выборки.
Даже хотел написать статью на тему «Как запросто выбросить 50К...», да время — будь оно не ладно.
Если кому вдруг интересно — попробую выкроить чуть-чуть.
[UPD] Почему собственно это — фэйл. Не отвлекаясь на лирику, «политический» подтекст и всяческие попытки оправдать «так перевел бы человек» и т. п. тематику.
1. Это неправильный перевод. Точка.
2. На этом показательном случае видно полное отсутствие у GNMT какой-либо классификационной модели (в смысле CADM, в которой как раз Google должен блистать, ибо у них полно данных ото всюду). Просто постольку поскольку подлежащие в обоих случаях являются странами/государствами, а дополнения являются географическими субъектами (территорией).
Даже тупейшее plausibility-правило какой-нибудь fuzzy K-nn classification никогда не допустило бы такую ошибку. Умолчим уже про современные алгоритмы классификации и построения (семантических) связей.
Как говорится ничего личного, простая математика… Ну а если Google таки в лоб без разбора решил кормить свою сеть вырезками из бульварной прессы, то у меня для него плохие новости.
P. S. Однако, как сказал мне однажды один многоуважаемый мною профессор — «Очень трудно порой доказать дятлу, что он дятел, особенно если он уверен что умнее профессора».
Ну а для начала немного теории:
GNMT есть система нейронного машинного перевода (NMT) компании Google, которая использует нейросеть (ANN) для повышения точности и скорости перевода, и в частности для создания лучших, более естественных вариантов перевода текста в Google Translate.
В случае GNMT речь идет о так называемом методе перевода на основе примеров (EBMT), т.е. ANN, лежащая в основе метода, обучается на миллионах примеров перевода, причем в отличии от других систем этот метод позволяет выполнять так называемый zero-shot перевод, т. е. переводить с одного языка на другой, не имея явные примеры для этой пары конкретных языков в процессе обучения (в обучающей выборке).
Рис. 1. Zero-Shot Translation
Причем GNMT разработан в первую очередь для улучшения перевода фраз и предложений, т.к. как раз при контекстном переводе нельзя использовать дословный вариант перевода и нередко предложение переводится совершенно по другому.
Кроме того, возвращаясь к zero-shot translation, Google стараются при этом выделить некоторую общую составляющую, действительную сразу для нескольких языков (как при поиске зависимостей, так и при построении связей для предложений и фраз).
Например на рисунке 2, показана такая interlingua «общность» среди всех возможных пар для японского, корейского и английского языков.
Рис. 2. Interlingua. 3-мерное представление данных сети для японского, корейского и английского языков.
Часть (а) показывает общую «геометрию» таких переводов, где точки окрашены по смыслу (и одинаковым цветом для одного и того же смысла у нескольких пар языков).
Часть (b) показывает увеличение одной из групп, часть © в цветах исходного языка.
GNMT использует большую ANN глубокого обучения (DNN), которая, выученная на миллионах примеров, должна улучшать качество перевода, применяя контекстное абстрактное приближение для наиболее подходящего варианта перевода. Грубо говоря выбирает лучший, в смысле наиболее соответствующего грамматике человеческого языка, результат, при этом учитывая общности построения связей, фраз и предложений для нескольких языков (т.е. отдельно выделяя и обучая interlingua модель или слои).
Однако DNN как в процессе обучения так и в процессе работы как правило полагается на статистический (вероятностный) вывод и редко обвязывается дополнительными не вероятностными алгоритмами. Т.е. для оценки лучшего из возможных результатов, вышедших из вариатора, будет выбран статистически наиболее лучший (вероятный) вариант.
Всё это, естественным образом, дополнительно зависит от качества обучающей выборки (и/или качества алгоритмов в случае самообучающейся модели).
Учитывая сквозной (zero-shot) метод перевода и помня о некой общей (interlingua) составляющей, при наличии некоторой позитивной логической глубокой связи для одного языка, и отсутствии негативных составляющих для других языков, некоторая абстрактная ошибка, вылезшая в процессе обучения и соответственно в результате перевода некоторой фразы для одного языка, с большой долей вероятности повторится и для других языков или даже языковых пар.
Собственно свежий epic fail
Все картинки кликабельны (в качестве пруфа на соответствующую страницу Google Translate).
Немецкий:
Английский:
Нидерландский:
Датский:
Французский:
И т.д.
Вместо заключения
Связь устойчивая для слова Россия (в том смысле что при замене России, например на Российскую империю, вариант «перевода» меняется).
И не очень устойчива при некоторых изменениях фразы, не типичных для перевода на английский язык, но общих например для русского, немецкого и нидерландского языков.
Это к сожалению далеко не единственный случай и интернет пестрит всевозможными ошибками Google Translate.
И думается мне, что немалая часть существующих ошибок проявляется из-за совокупности нескольких факторов, начиная от собственно качества обучающей выборки и заканчивая качеством алгоритмов семантического и морфологического разбора для конкретного языка (и модели обучения в частности).
Как-то раз, один коллега предложил поучаствовать в Text Normalization Challenge (для русского и английского языков) от Google на kaggle…
Перед тем как согласиться, я сделал тогда небольшой анализ качества обучающей тестовой выборки для всех классов токенов для обоих языков… и в результате отказался участвовать вовсе, ибо чем больше я копал, тем сильнее было чувство что конкурс будет похож на лотерею или выиграет тот, кто наиболее максимально точно сможет повторить все ошибки, допущенные при полу-ручном создании Google обучающей выборки.
Даже хотел написать статью на тему «Как запросто выбросить 50К...», да время — будь оно не ладно.
Если кому вдруг интересно — попробую выкроить чуть-чуть.
[UPD] Почему собственно это — фэйл. Не отвлекаясь на лирику, «политический» подтекст и всяческие попытки оправдать «так перевел бы человек» и т. п. тематику.
1. Это неправильный перевод. Точка.
2. На этом показательном случае видно полное отсутствие у GNMT какой-либо классификационной модели (в смысле CADM, в которой как раз Google должен блистать, ибо у них полно данных ото всюду). Просто постольку поскольку подлежащие в обоих случаях являются странами/государствами, а дополнения являются географическими субъектами (территорией).
Даже тупейшее plausibility-правило какой-нибудь fuzzy K-nn classification никогда не допустило бы такую ошибку. Умолчим уже про современные алгоритмы классификации и построения (семантических) связей.
Как говорится ничего личного, простая математика… Ну а если Google таки в лоб без разбора решил кормить свою сеть вырезками из бульварной прессы, то у меня для него плохие новости.
P. S. Однако, как сказал мне однажды один многоуважаемый мною профессор — «Очень трудно порой доказать дятлу, что он дятел, особенно если он уверен что умнее профессора».

