Небольшая заметка, скорее для себя, о мелких трюках по восстановлению данных в Elasticsearch. Как починить красный индекс если нет бэкапа, что делать если удалил документы, а копии не осталось — к сожалению в официальной документации об этих возможностях умалчивают.
Первое, что необходимо сделать, это настроить бэкапы важных данных. Как это делается описано в официальной документации.
В целом, ничего сложного. В простейшем варианте создаем шару на другом сервере, монтируем ее ко всем узлам эластика любым удобным способом (nfs, smbfs, whatever). Далее используем cron, ваше приложение или что угодно для отправки запросов на периодическое создание снэпшотов.
Первый снэпшот будет долгим, последующие будут содержать только дельту между состояниями индекса. Учтите, что если вы периодически делаете forcemerge, дельта будет огромной и соответственно время создания снэпшота будет примерно как в первый раз.
Что следует учесть:
В общем смотрите в документацию, там эта тема более-менее раскрыта.

Небольшая утилита на nodejs, позволяющая копировать данные из одного индекса в другой индекс, кластер, файл, stdout.
Вывод в файл или stdout кстати можно использовать как альтернативный метод бэкапа — на выходе получается обычный валидный json (что-то вроде sql dump), который можно переиспользовать как хотите. Например, можно засунуть вывод в pipe, где ваш скрипт будет как-то преобразовывать данные и отправлять в другое хранилище, например clickhouse. Простейшие js преобразования можно делать прямо самим elasticdump, есть соответствующий ключ --transform. В общем, полёт фантазии.
Из подводных камней:
Для сливания большого количества индексов одновременно в комплекте есть multielasticdump с упрощенным набором опций, но зато все индексы сливаются параллельно.
Замечание! Автор утилиты сообщил, что у него больше нет времени на поддержку, поэтому программа ищет нового мэйнтейнера.
Из личного опыта: утилита полезная, выручала не раз. Скорость и стабильность так себе, хотелось бы адекватную замену, но пока ничего на горизонте.
Итак, мы начинаем подбираться к тёмной стороне. Ситуация: индекс перешёл в состояние красный. В логах — что-то пошло не так, не совпадает чек сумма, наверное у вас навернулась память или диск:
Конечно у мамкиных админов никогда такое не происходит, потому что у них топовое железо с тройной репликацией, память суперECC с коррекцией абсолютно всех уровней ошибок на лету и вообще снэпшоты каждую секунду настроены.
Но реальность к сожалению иногда подкидывает и такие варианты, когда бэкап был относительно давно (если у вас индексируются гигабайты в час, слишком ли стар бэкап сделанный 2 часа назад?), данные восстановить неоткуда, репликация не успела и все в таком духе.
Конечно, если есть снэпшот, бэкап или т.п. — отлично, раскатывайте и не парьтесь. А если нет? К счастью, хотя бы часть данных все-таки можно спасти.
Первым делом, закройте индекс и/или выключите эластик, сделайте резервную копию провалившегося шарда.
У Lucene (а именно она работает бэкендом в elasticsearch) есть замечательный метод CheckIndex. Нам нужно всего лишь вызвать его над поломанным шардом. Lucene проверит все его сегменты и удалит поврежденные. Да, данные потеряются, но хотя бы не абсолютно все. Хотя тут как повезет.
Тут есть как минимум 2 способа.
Нам поможет вот такой простенький скрипт
Вызвав его без параметров получим что-то такое:
Собственно, можем либо просто прогнать тест индекса, либо заставить CheckIndex его «починить», вырезав все поврежденное.
Люценовский индекс живет примерно по такому пути: /var/lib/elasticsearch/nodes/0/indices/str4ngEHashVa1uE/0/index/, где 0 и 0 — номер узла на сервере и номер шарда на узле. Страшное значение между ними — внутреннее название индекса — можно получить из вывода curl localhost:9200/_cat/indices.
Я обычно делаю копию в другой каталог, а чиню in-place. После чего перезапускаю elasticsearch. Как правило все подхватывается, пусть и с потерей данных. Иногда индекс все равно не хочет зачитываться из-за файлов *corrupted* в папке шарды. Переместите их в безопасное место на время.
(картинка из интернета)
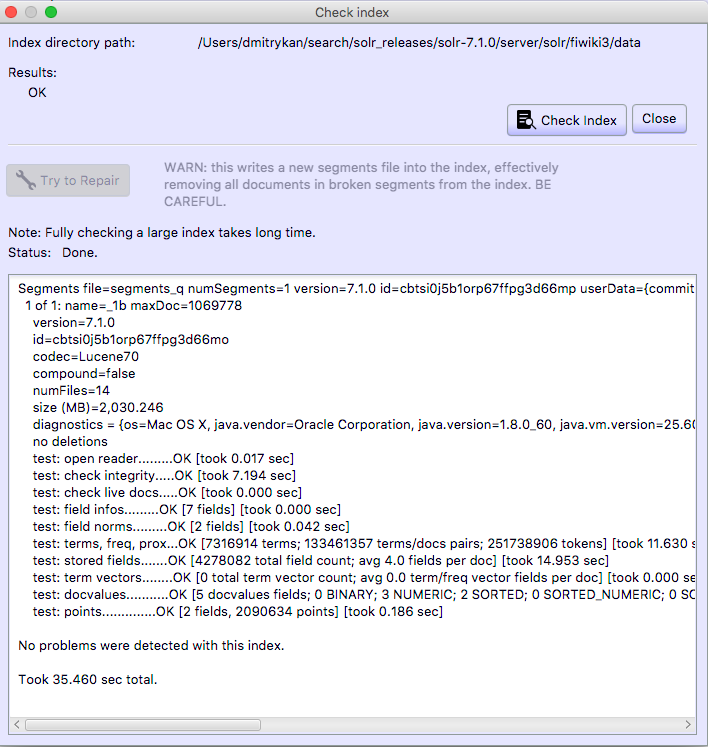
Для работы с Lucene есть замечательная утилита под названием Luke.
Тут все еще проще. Узнаем версию Lucene у вашего elasticsearch:
Берем ту же версию Luke. Открываем в нем индекс (копию конечно) с галкой Do not open IndexReader (when openning corrupted index). Далее жмем Tools / Check Index. Сначала рекомендую прогнать всухую, а уже потом в режиме починки. Дальше действия аналогичные — копируем назад эластику, перезапускаем/открываем индекс.
Ситуация: вы выполнили разрушительный запрос, который поудалял много/все нужные данные. А восстановить неоткуда, либо очень затратно. Ну конечно ССЗБ, что бэкапов нет, но и такое бывает.
К сожалению или счастью, Lucene никогда ничего не удаляет напрямую. Её философия ближе к CoW, поэтому удаленные данные на самом деле не удаляются, а лишь помечаются удаленными. Собственно удаление происходит при оптимизации индекса — живые данные из сегментов копируются во вновь созданные сегменты, старые сегменты просто удаляются. В общем, пока в статусе индекса deleted не 0, шансы вытащить есть.
После forcemerge шансов нет.
Итак, первым делом закрываем индекс, стопаем эластик, копируем индекс (файлики) в безопасное место.
Вытащить индивидуальный удаленный документ невозможно. Можно только восстановить вообще все удаленные документы в указанном сегменте.
Для версий Lucene ниже 4 все очень просто. В Lucene API есть функция под названием undeleteAll. Можно вызвать ее прямо из Luke из предыдущего пункта.
Для более новых версий увы функционал выпилили. Но все-таки способ все еще есть. Информация о «живых» документах хранится в файликах *.liv. Однако простое их удаление сделает индекс нечитаемым. Необходимо поправить файл segments_N, чтобы он вообще забыл о их существовании.
Открываем файл segments_N (N — целое число) в вашем любимом Hex-редакторе. Ориентироваться в нем нам поможет официальная документация:
Из всего этого нам нужны значения DelGen (Int64) и DeletionCount (Int32). Первое надо сделать равным -1, а второе 0.
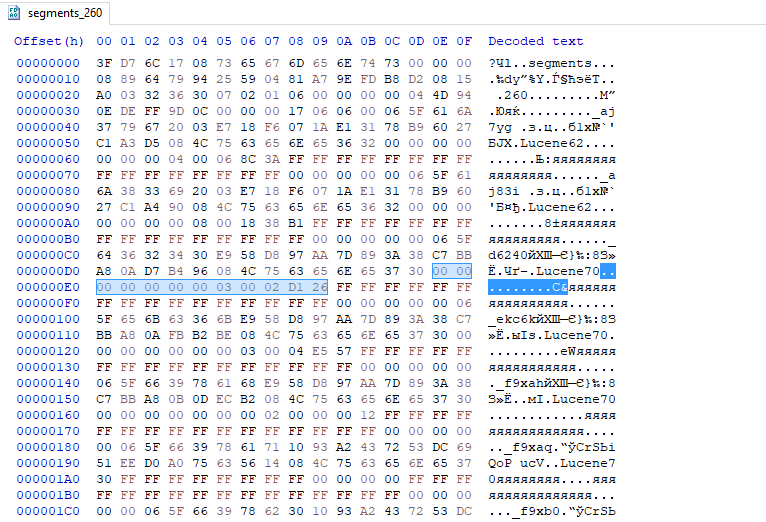
Найти их не сложно, они сразу за SegCodec, который весьма бросающаяся в глаза строка типа Lucene62. На данном скрине видно, что DelGen имеет значение 3, а DeletionCount — 184614. Заменяем первое на 0xFFFFFFFFFFFFFFFF, а второе на 0х00000000. Повторяем для всех необходимых сегментов, сохраняем.
Однако, пофикшенный индекс не захочет грузится, ссылаясь на ошибку контрольной суммы. Тут все еще проще. Берем Luke, загружаем индекс с отключенным IndexReader, Tools / Check Index. Делаем тестовый прогон и сразу же ловим, что segments_N поврежден. Ожидается чексумма такая-то, а получена такая-то.
Ерунда! Берем ожидаемую контрольную сумму и вписываем в последние 4 байта файла.
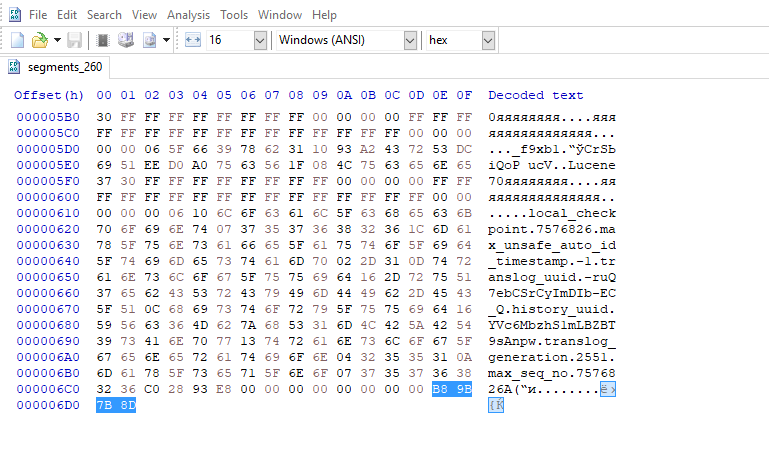
Сохраняем. Прогоняем еще раз CheckIndex, чтобы убедиться что все ок и индекс загружается.
Et voilà!
Бэкапы
Первое, что необходимо сделать, это настроить бэкапы важных данных. Как это делается описано в официальной документации.
В целом, ничего сложного. В простейшем варианте создаем шару на другом сервере, монтируем ее ко всем узлам эластика любым удобным способом (nfs, smbfs, whatever). Далее используем cron, ваше приложение или что угодно для отправки запросов на периодическое создание снэпшотов.
Первый снэпшот будет долгим, последующие будут содержать только дельту между состояниями индекса. Учтите, что если вы периодически делаете forcemerge, дельта будет огромной и соответственно время создания снэпшота будет примерно как в первый раз.
Что следует учесть:
- Проверяйте статус бэкапов, например с помощью _cat:
curl localhost:9200/_cat/snapshots/yourbackuprepo/. Снэпшоты в статусе Partial или Failed — не ваши бро. - Начиная с ES 6.x эластик очень требователен к заголовкам запросов. Если вы делаете их вручную (не через API), проверьте что у вас выставлен
Content-Type: application/json, иначе все ваши запросы просто обламываются и бэкапа не происходит - Снэпшот невозможно восстановить в открытый индекс. Его надо обязательно закрыть или удалить сначала. Однако вы можете восстановить снэпшот рядом, используя rename_pattern, rename_replacement (см. пример в доке). Кроме того, при восстановлении снэпшота также восстанавливаются его настройки, в том числе алиасы, количество реплик и т.п. Если вам этого не надо, добавьте в запрос на восстановление index_settings (см. доку для примера) с нужными изменениями.
- Репоз (шару) со снэпшотами можно подключить к более чем одному кластеру и восстанавливать снэпшоты из любого кластера в любой другой. Главное чтобы версии эластиков были совместимы.
В общем смотрите в документацию, там эта тема более-менее раскрыта.
Elasticdump
Небольшая утилита на nodejs, позволяющая копировать данные из одного индекса в другой индекс, кластер, файл, stdout.
Вывод в файл или stdout кстати можно использовать как альтернативный метод бэкапа — на выходе получается обычный валидный json (что-то вроде sql dump), который можно переиспользовать как хотите. Например, можно засунуть вывод в pipe, где ваш скрипт будет как-то преобразовывать данные и отправлять в другое хранилище, например clickhouse. Простейшие js преобразования можно делать прямо самим elasticdump, есть соответствующий ключ --transform. В общем, полёт фантазии.
Из подводных камней:
- Как метод бэкапа — значительно медленнее чем снэпшоты. Плюс бэкап растянут по времени, поэтому результат на часто изменяющемся индексе может быть неконсистентным. Имейте ввиду.
- Не используйте nodejs из репозитория debian, там слишком старая версия, отрицательно влияющая на стабильность тулзы.
- Стабильность работы может варьироваться, особенно если одна из сторон перегружена. Не пытайтесь бэкапить с одного сервера на другой запуская тулзу на офисной машине — весь трафик польется через нее.
- Фигово копирует маппинги. Если у вас там что-то сложное, то создайте индекс вручную, а уже потом заливайте в него данные.
- Иногда имеет смысл поменять размер чанка (параметр --limit). Этот параметр напрямую влияет на скорость копирования.
Для сливания большого количества индексов одновременно в комплекте есть multielasticdump с упрощенным набором опций, но зато все индексы сливаются параллельно.
Замечание! Автор утилиты сообщил, что у него больше нет времени на поддержку, поэтому программа ищет нового мэйнтейнера.
Из личного опыта: утилита полезная, выручала не раз. Скорость и стабильность так себе, хотелось бы адекватную замену, но пока ничего на горизонте.
CheckIndex
Итак, мы начинаем подбираться к тёмной стороне. Ситуация: индекс перешёл в состояние красный. В логах — что-то пошло не так, не совпадает чек сумма, наверное у вас навернулась память или диск:
org.apache.lucene.index.CorruptIndexException: checksum failed (hardware problem?)Конечно у мамкиных админов никогда такое не происходит, потому что у них топовое железо с тройной репликацией, память суперECC с коррекцией абсолютно всех уровней ошибок на лету и вообще снэпшоты каждую секунду настроены.
Но реальность к сожалению иногда подкидывает и такие варианты, когда бэкап был относительно давно (если у вас индексируются гигабайты в час, слишком ли стар бэкап сделанный 2 часа назад?), данные восстановить неоткуда, репликация не успела и все в таком духе.
Конечно, если есть снэпшот, бэкап или т.п. — отлично, раскатывайте и не парьтесь. А если нет? К счастью, хотя бы часть данных все-таки можно спасти.
Первым делом, закройте индекс и/или выключите эластик, сделайте резервную копию провалившегося шарда.
У Lucene (а именно она работает бэкендом в elasticsearch) есть замечательный метод CheckIndex. Нам нужно всего лишь вызвать его над поломанным шардом. Lucene проверит все его сегменты и удалит поврежденные. Да, данные потеряются, но хотя бы не абсолютно все. Хотя тут как повезет.
Тут есть как минимум 2 способа.
Способ 1: Прямо на узле
Нам поможет вот такой простенький скрипт
#!/bin/bash pushd /usr/share/elasticsearch/lib java -cp lucene-core*.jar -ea:org.apache.lucene... org.apache.lucene.index.CheckIndex "$@" popd
Вызвав его без параметров получим что-то такое:
ERROR: index path not specified Usage: java org.apache.lucene.index.CheckIndex pathToIndex [-exorcise] [-crossCheckTermVectors] [-segment X] [-segment Y] [-dir-impl X] -exorcise: actually write a new segments_N file, removing any problematic segments -fast: just verify file checksums, omitting logical integrity checks -crossCheckTermVectors: verifies that term vectors match postings; THIS IS VERY SLOW! -codec X: when exorcising, codec to write the new segments_N file with -verbose: print additional details -segment X: only check the specified segments. This can be specified multiple times, to check more than one segment, eg '-segment _2 -segment _a'. You can't use this with the -exorcise option -dir-impl X: use a specific FSDirectory implementation. If no package is specified the org.apache.lucene.store package will be used. **WARNING**: -exorcise *LOSES DATA*. This should only be used on an emergency basis as it will cause documents (perhaps many) to be permanently removed from the index. Always make a backup copy of your index before running this! Do not run this tool on an index that is actively being written to. You have been warned! Run without -exorcise, this tool will open the index, report version information and report any exceptions it hits and what action it would take if -exorcise were specified. With -exorcise, this tool will remove any segments that have issues and write a new segments_N file. This means all documents contained in the affected segments will be removed. This tool exits with exit code 1 if the index cannot be opened or has any corruption, else 0.
Собственно, можем либо просто прогнать тест индекса, либо заставить CheckIndex его «починить», вырезав все поврежденное.
Люценовский индекс живет примерно по такому пути: /var/lib/elasticsearch/nodes/0/indices/str4ngEHashVa1uE/0/index/, где 0 и 0 — номер узла на сервере и номер шарда на узле. Страшное значение между ними — внутреннее название индекса — можно получить из вывода curl localhost:9200/_cat/indices.
Я обычно делаю копию в другой каталог, а чиню in-place. После чего перезапускаю elasticsearch. Как правило все подхватывается, пусть и с потерей данных. Иногда индекс все равно не хочет зачитываться из-за файлов *corrupted* в папке шарды. Переместите их в безопасное место на время.
Способ 2: Luke
(картинка из интернета)
Для работы с Lucene есть замечательная утилита под названием Luke.
Тут все еще проще. Узнаем версию Lucene у вашего elasticsearch:
$ curl localhost:9200 { "name" : "node00", "cluster_name" : "main", "cluster_uuid" : "UCbEivvLTcyWSQElOipgTQ", "version" : { "number" : "6.2.4", "build_hash" : "ccec39f", "build_date" : "2018-04-12T20:37:28.497551Z", "build_snapshot" : false, "lucene_version" : "7.2.1", "minimum_wire_compatibility_version" : "5.6.0", "minimum_index_compatibility_version" : "5.0.0" }, "tagline" : "You Know, for Search" }
Берем ту же версию Luke. Открываем в нем индекс (копию конечно) с галкой Do not open IndexReader (when openning corrupted index). Далее жмем Tools / Check Index. Сначала рекомендую прогнать всухую, а уже потом в режиме починки. Дальше действия аналогичные — копируем назад эластику, перезапускаем/открываем индекс.
Восстановление удаленных документов
Ситуация: вы выполнили разрушительный запрос, который поудалял много/все нужные данные. А восстановить неоткуда, либо очень затратно. Ну конечно ССЗБ, что бэкапов нет, но и такое бывает.
К сожалению или счастью, Lucene никогда ничего не удаляет напрямую. Её философия ближе к CoW, поэтому удаленные данные на самом деле не удаляются, а лишь помечаются удаленными. Собственно удаление происходит при оптимизации индекса — живые данные из сегментов копируются во вновь созданные сегменты, старые сегменты просто удаляются. В общем, пока в статусе индекса deleted не 0, шансы вытащить есть.
$ curl localhost:9200/_cat/indices?v health status index uuid pri rep docs.count docs.deleted store.size pri.store.size green open data.0 R0fgvfPnTUaoI2KKyQsgdg 5 1 7238685 1291566 45.1gb 22.6gb
После forcemerge шансов нет.
Итак, первым делом закрываем индекс, стопаем эластик, копируем индекс (файлики) в безопасное место.
Вытащить индивидуальный удаленный документ невозможно. Можно только восстановить вообще все удаленные документы в указанном сегменте.
Для версий Lucene ниже 4 все очень просто. В Lucene API есть функция под названием undeleteAll. Можно вызвать ее прямо из Luke из предыдущего пункта.
Для более новых версий увы функционал выпилили. Но все-таки способ все еще есть. Информация о «живых» документах хранится в файликах *.liv. Однако простое их удаление сделает индекс нечитаемым. Необходимо поправить файл segments_N, чтобы он вообще забыл о их существовании.
Открываем файл segments_N (N — целое число) в вашем любимом Hex-редакторе. Ориентироваться в нем нам поможет официальная документация:
segments_N: Header, LuceneVersion, Version, NameCounter, SegCount, MinSegmentLuceneVersion, <SegName, SegID, SegCodec, DelGen, DeletionCount, FieldInfosGen, DocValuesGen, UpdatesFiles>SegCount, CommitUserData, Footer
Из всего этого нам нужны значения DelGen (Int64) и DeletionCount (Int32). Первое надо сделать равным -1, а второе 0.
Найти их не сложно, они сразу за SegCodec, который весьма бросающаяся в глаза строка типа Lucene62. На данном скрине видно, что DelGen имеет значение 3, а DeletionCount — 184614. Заменяем первое на 0xFFFFFFFFFFFFFFFF, а второе на 0х00000000. Повторяем для всех необходимых сегментов, сохраняем.
Однако, пофикшенный индекс не захочет грузится, ссылаясь на ошибку контрольной суммы. Тут все еще проще. Берем Luke, загружаем индекс с отключенным IndexReader, Tools / Check Index. Делаем тестовый прогон и сразу же ловим, что segments_N поврежден. Ожидается чексумма такая-то, а получена такая-то.
Caused by: org.apache.lucene.index.CorruptIndexException: checksum failed (hardware problem?) : expected=51fbdb5c actual=6e964d17
Ерунда! Берем ожидаемую контрольную сумму и вписываем в последние 4 байта файла.
Сохраняем. Прогоняем еще раз CheckIndex, чтобы убедиться что все ок и индекс загружается.
Et voilà!

