Walt Disney Animation Studios (WDAS) недавно сделала сообществу исследователей рендеринга неоценимый подарок, выпустив полное описание сцены для острова из мультфильма «Моана». Геометрия и текстуры для одного кадра занимают на диске более 70 ГБ. Это потрясающий пример той степени сложности, с которой сегодня приходится иметь дело системам рендеринга; никогда ранее исследователи и разработчики, занимающиеся рендерингом вне киностудий, не могли поработать с подобными реалистичными сценами.
Вот, как выглядит результат рендеринга сцены с помощью современного pbrt:

Остров из «Моаны», отрендеренный pbrt-v3 в разрешении 2048x858 с 256 сэмплами на пиксель. Общее время рендеринга на 12-ядерном/24-поточном инстансе Google Compute Engine с частотой 2 ГГц с последней версией pbrt-v3 составило 1 ч 44 мин 45 с.
Со стороны компании Disney это был огромный труд, ей пришлось извлечь сцену из собственного внутреннего формата и преобразовать в обычный; особое спасибо ей за время, потраченное на упаковку и подготовку этих данных для широкого использования. Я уверен, что их работа будет хорошо вознаграждена в будущем, потому что исследователи используют эту сцену, чтобы изучить проблемы эффективного рендеринга сцен такого уровня сложности.
Эта сцена уже многому меня научила и позволила улучшить рендерер pbrt, но прежде чем мы перейдём к этому, я для понимания контекста расскажу короткую историю.
Много лет назад, проходя интернатуру в команде рендеринга Pixar, я научился любопытному уроку: «интересные» вещи почти всегда появляются, когда программной системе передаются входные данные, значительно отличающиеся от всего, что было раньше. Даже в хорошо написанных и зрелых программных системах новые типы вводимых данных почти всегда приводят к обнаружению неизвестных дефектов в существующей реализации.
Впервые я уяснил этот урок во время продакшена Toy Story 2. Однажды кто-то заметил, что удивительно много времени тратится на парсинг файлов описаний сцен RIB. Кто-то ещё из команды рендеринга (полагаю, это был Крейг Колб) запустил профайлер и начал разбираться.
Оказалось, что бОльшую часть времени парсинга занимали операции поиска в хэш-таблице, использовавшейся для string interning. Хэш-таблица имела довольно маленький размер, наверно, 256 элементов, а когда в одну ячейку хэшировалось несколько значений, она организовывала цепочку. После первой реализации хэш-таблицы прошло много времени и в сценах теперь были десятки тысяч объектов, поэтому такая маленькая таблица быстро заполнялась и становилась неэффективной.
Целесообразнее всего было просто увеличить размер таблицы — всё это происходило в разгар рабочего процесса, поэтому времени на какое-нибудь изысканное решение, например, расширение размера таблицы при её заполнении, не было. Вносим изменение в одну строку, пересобираем приложение, выполняем быстрый тест перед коммитом и… никаких улучшений скорости не происходит. На поиск по хэш-таблице тратится столько же времени. Потрясающе!
После дальнейшего изучения обнаружили, что используемая функция хэш-таблицы была аналогом следующей:
(Прости меня, Pixar, если я раскрыл ваш сверхсекретный исходный код RenderMan.)
«Хэш»-функция была реализована ещё в 1980-х. В то время программист, вероятно, посчитал, что вычислительные затраты на проверку влияния всех символов строки на значение хэша будут слишком высоки и не стоят того. (Думаю, что если в сцене было всего несколько объектов и 256 элементов в хэш-таблице, то этого было вполне достаточно.)
Свой вклад внесла и ещё одна устаревшая реализация: с момента начала создания студией Pixar своих фильмов, названия объектов в сценах довольно сильно разрослись, например, «BuzzLightyear/LeftArm/Hand/IndexFinger/Knuckle2». Однако какой-то начальный этап конвейера использовал для хранения названий объектов буфер фиксированной длины и сокращал все длинные названия, сохраняя только конец, и, если повезёт, добавлял в начале многоточие, давая понять, что часть названия утеряна: "…year/LeftArm/Hand/IndexFinger/Knuckle2".
В дальнейшем все названия объектов, которые видел рендерер, имели такую форму, хэш-функция хэшировала их всех в один фрагмент памяти как ".", а хэш-таблица на самом деле была большим связанным списком. Добрые старые времена. По крайней мере, разобравшись, мы довольно быстро исправили эту ошибку.
Этот урок вспомнился мне в прошлом году, когда Хитер Притчет и Расмус Тамсторф из WDAS связались со мной и спросили, интересно ли мне будет проверить возможное качество рендеринга сцены из «Моаны» в pbrt1. Естественно, я согласился. Я рад был помочь и мне интересно было, как всё получится.
Наивный оптимист внутри меня надеялся, что огромных сюрпризов не будет — в конце концов, первая версия pbrt была выпущена около 15 лет назад, и многие люди долгие годы использовали и изучали его код. Можно быть уверенным, что не будет никаких помех наподобие старой хэш-функции из RenderMan, правда?
Разумеется, ответ был отрицательным. (И именно поэтому я пишу этот и ещё несколько других постов.) Хотя я был немного разочарован, что pbrt не был идеальным «из коробки», но считаю, что опыт моей работы со сценой из «Моаны» был первым подтверждением ценности опубликования этой сцены; pbrt уже стал более качественной системой благодаря тому, что я разобрался с обработкой этой сцены.
Получив доступ к сцене, я сразу же её скачал (с моим домашним Интернет-подключением на это ушло несколько часов) и распаковал из tar, получив 29 ГБ файлов pbrt и 38 ГБ текстурных карт ptex2. Я беспечно попытался отрендерить сцену на моей домашней системе (с 16 ГБ ОЗУ и 4-ядерным ЦП). Вернувшись через какое-то время к компьютеру, я увидел, что он завис, вся ОЗУ заполнена, а pbrt всё ещё пытается завершить парсинг описания сцены. ОС стремилась справиться с задачей, используя виртуальную память, но это казалось безнадёжным. Прибив процесс, мне пришлось ждать ещё около минуты, прежде чем система начала реагировать на мои действия.
Следующей попыткой был инстанс Google Compute Engine, позволяющий использовать больше ОЗУ (120 ГБ) и больше ЦП (32 потоков на 16 ЦП). Хорошая новость заключалась в том, что pbrt смог успешно отрендерить сцену (благодаря труду Хитер и Расмуса по её переводу в формат pbrt). Было очень волнующе увидеть, что pbrt может генерировать относительно хорошие пиксели для качественного киноконтента, но скорость оказалась совсем не такой восхитительной: 34 мин 58 с только на парсинг описания сцены, причём во время рендеринга система тратила до 70 ГБ ОЗУ.
Да, на диске лежало 29 гигабайт файлов описаний сцен формата pbrt, которые нужно было спарсить, поэтому я не ждал, что первый этап займёт пару секунд. Но тратить полчаса ещё до того, как начнут трассироваться лучи? Это сильно усложняет саму работу со сценой.
С другой стороны, такая скорость говорила нам, что в коде, вероятно, происходит что-то очень дурно пахнущее; не просто «инверсию матрицы можно выполнить на 10% быстрее»; скорее, что-то уровня «ой, мы проходим по связанному списку из 100 тысяч элементов». Я был настроен оптимистично и надеялся, что разобравшись, смогу значительно ускорить процесс.
Первым местом, в котором я начал искать подсказки, была статистика дампа pbrt после рендеринга. Основные этапы выполнения pbrt настроены так, что можно собирать приблизительные данные профилирования благодаря фиксации операций с периодичными прерываниями в процессе рендеринга. К сожалению, статистика нам мало чем помогла: по отчётам, из почти 35 минут до начала рендеринга 4 минуты 22 секунды было потрачено на построение BVH, но про остальное время не было указано никаких подробностей.
Построение BVH — это единственная значимая вычислительная задача, выполняемая во время парсинга сцены; всё остальное по сути является десериализацией описаний геометрии и материалов. Знание о том, сколько времени тратилось на создание BVH, дало понимание того, насколько (не)эффективной была система: оставшееся время, а именно около 30 минут, уходило на парсинг 29 ГБ данных, то есть скорость составляла 16,5 МБ/с. Хорошо оптимизированные парсеры JSON, по сути выполняющие такую же задачу, работают со скоростью 50-200 МБ/с. Ясно, что пространство для усовершенствования ещё есть.
Чтобы лучше понять, на что тратится время, я запустил pbrt с инструментом Linux perf, которым раньше никогда не пользовался. Но, похоже, он справился с задачей. Я проинструктировал его искать символы DWARF для получения названий функций (
Вот, что он смог мне сказать после запуска с pbrt:
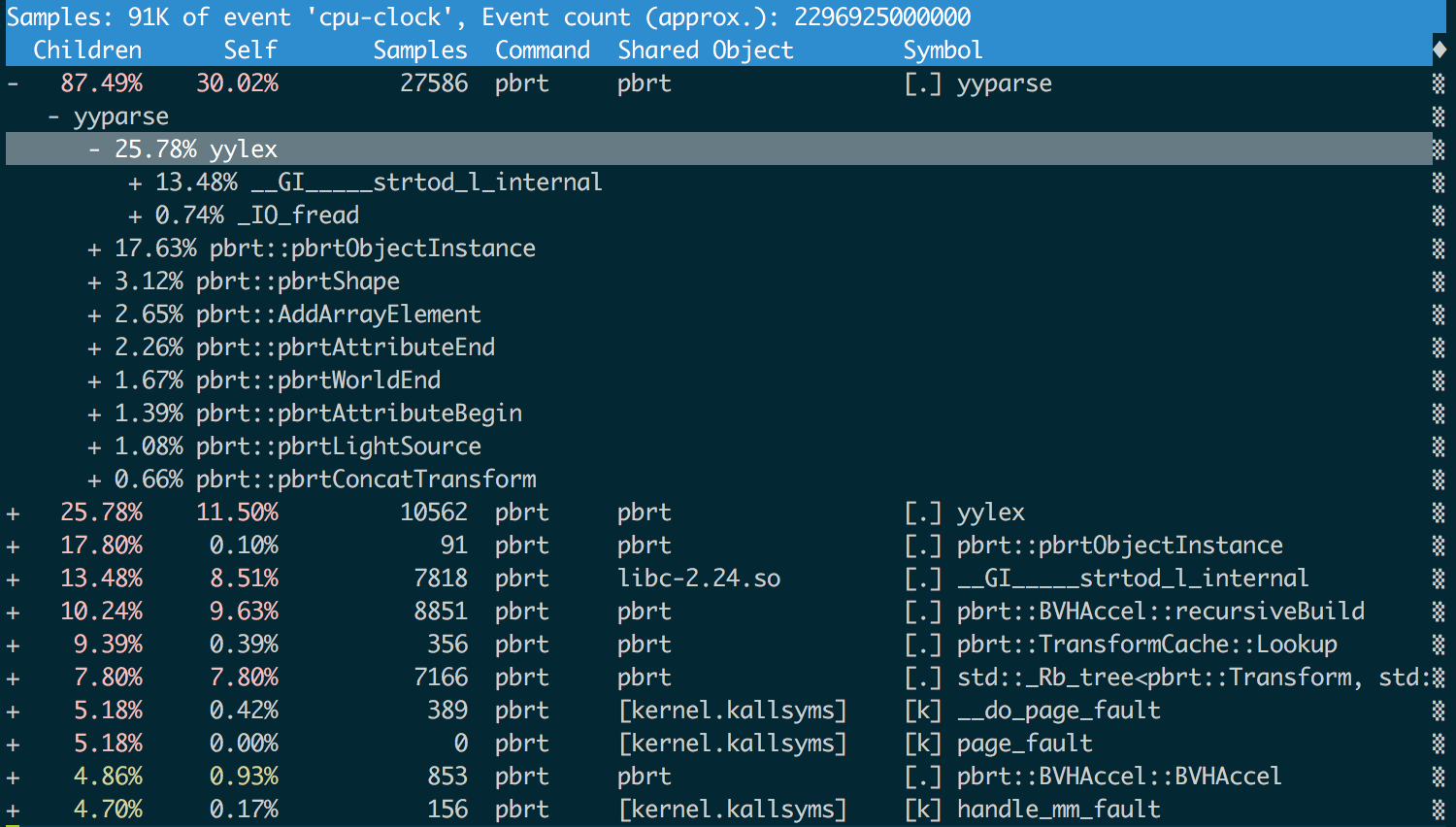
Я не шутил, когда говорил об «интерфейсе с nice curses».
Мы видим, что больше половины времени тратится на механику парсинга:
Один из способов тратить меньше времени на парсинг данных в текстовом виде — преобразовать данные в формат, который парсится более эффективно. Довольно большая часть из 29 ГБ этих файлов описаний сцен являются мешами из треугольников, а в pbrt уже есть нативная поддержка формата PLY, который является эффективным двоичным представлением полигональных мешей. Также в pbrt есть флаг командной строки
Загвоздка заключается в том, что в сцене Disney активно используются ptex-текстуры, которые, в свою очередь, требуют, чтобы с каждым треугольником было связано значение
Я написал небольшой сценарий командной строки для преобразования всех файлов
После преобразования всех больших мешей в PLY размер описания сцены на диске снизился с 29 до 22 ГБ: 16,9 ГБ файлов сцены pbrt и 5,1 ГБ двоичных файлов PLY. После преобразования общее время первого этапа системы снизилось до 27 минут 35 секунд, а экономия составила 7 минут 23 секунды, то есть мы ускорились в 1,3 раза3. Обработка файла PLY намного эффективнее, чем обработка текстового файла pbrt: всего 40 секунд времени запуска тратилось на парсинг файлов PLY, и мы видим, что файлы PLY обрабатывались со скоростью примерно 130 МБ/с, или примерно в 8 раз быстрее, чем текстовый формат pbrt.
Это была хорошая лёгкая победа, но нам ещё предстояло сделать многое.
В следующий раз мы разберёмся, где на самом деле используется вся память, исправим здесь несколько ошибок и добьёмся в процессе ещё большего повышения скорости.
Вот, как выглядит результат рендеринга сцены с помощью современного pbrt:
Остров из «Моаны», отрендеренный pbrt-v3 в разрешении 2048x858 с 256 сэмплами на пиксель. Общее время рендеринга на 12-ядерном/24-поточном инстансе Google Compute Engine с частотой 2 ГГц с последней версией pbrt-v3 составило 1 ч 44 мин 45 с.
Со стороны компании Disney это был огромный труд, ей пришлось извлечь сцену из собственного внутреннего формата и преобразовать в обычный; особое спасибо ей за время, потраченное на упаковку и подготовку этих данных для широкого использования. Я уверен, что их работа будет хорошо вознаграждена в будущем, потому что исследователи используют эту сцену, чтобы изучить проблемы эффективного рендеринга сцен такого уровня сложности.
Эта сцена уже многому меня научила и позволила улучшить рендерер pbrt, но прежде чем мы перейдём к этому, я для понимания контекста расскажу короткую историю.
Хэш, которого не было
Много лет назад, проходя интернатуру в команде рендеринга Pixar, я научился любопытному уроку: «интересные» вещи почти всегда появляются, когда программной системе передаются входные данные, значительно отличающиеся от всего, что было раньше. Даже в хорошо написанных и зрелых программных системах новые типы вводимых данных почти всегда приводят к обнаружению неизвестных дефектов в существующей реализации.
Впервые я уяснил этот урок во время продакшена Toy Story 2. Однажды кто-то заметил, что удивительно много времени тратится на парсинг файлов описаний сцен RIB. Кто-то ещё из команды рендеринга (полагаю, это был Крейг Колб) запустил профайлер и начал разбираться.
Оказалось, что бОльшую часть времени парсинга занимали операции поиска в хэш-таблице, использовавшейся для string interning. Хэш-таблица имела довольно маленький размер, наверно, 256 элементов, а когда в одну ячейку хэшировалось несколько значений, она организовывала цепочку. После первой реализации хэш-таблицы прошло много времени и в сценах теперь были десятки тысяч объектов, поэтому такая маленькая таблица быстро заполнялась и становилась неэффективной.
Целесообразнее всего было просто увеличить размер таблицы — всё это происходило в разгар рабочего процесса, поэтому времени на какое-нибудь изысканное решение, например, расширение размера таблицы при её заполнении, не было. Вносим изменение в одну строку, пересобираем приложение, выполняем быстрый тест перед коммитом и… никаких улучшений скорости не происходит. На поиск по хэш-таблице тратится столько же времени. Потрясающе!
После дальнейшего изучения обнаружили, что используемая функция хэш-таблицы была аналогом следующей:
int hash(const char *str) { return str[0]; }
(Прости меня, Pixar, если я раскрыл ваш сверхсекретный исходный код RenderMan.)
«Хэш»-функция была реализована ещё в 1980-х. В то время программист, вероятно, посчитал, что вычислительные затраты на проверку влияния всех символов строки на значение хэша будут слишком высоки и не стоят того. (Думаю, что если в сцене было всего несколько объектов и 256 элементов в хэш-таблице, то этого было вполне достаточно.)
Свой вклад внесла и ещё одна устаревшая реализация: с момента начала создания студией Pixar своих фильмов, названия объектов в сценах довольно сильно разрослись, например, «BuzzLightyear/LeftArm/Hand/IndexFinger/Knuckle2». Однако какой-то начальный этап конвейера использовал для хранения названий объектов буфер фиксированной длины и сокращал все длинные названия, сохраняя только конец, и, если повезёт, добавлял в начале многоточие, давая понять, что часть названия утеряна: "…year/LeftArm/Hand/IndexFinger/Knuckle2".
В дальнейшем все названия объектов, которые видел рендерер, имели такую форму, хэш-функция хэшировала их всех в один фрагмент памяти как ".", а хэш-таблица на самом деле была большим связанным списком. Добрые старые времена. По крайней мере, разобравшись, мы довольно быстро исправили эту ошибку.
Интригующая инновация
Этот урок вспомнился мне в прошлом году, когда Хитер Притчет и Расмус Тамсторф из WDAS связались со мной и спросили, интересно ли мне будет проверить возможное качество рендеринга сцены из «Моаны» в pbrt1. Естественно, я согласился. Я рад был помочь и мне интересно было, как всё получится.
Наивный оптимист внутри меня надеялся, что огромных сюрпризов не будет — в конце концов, первая версия pbrt была выпущена около 15 лет назад, и многие люди долгие годы использовали и изучали его код. Можно быть уверенным, что не будет никаких помех наподобие старой хэш-функции из RenderMan, правда?
Разумеется, ответ был отрицательным. (И именно поэтому я пишу этот и ещё несколько других постов.) Хотя я был немного разочарован, что pbrt не был идеальным «из коробки», но считаю, что опыт моей работы со сценой из «Моаны» был первым подтверждением ценности опубликования этой сцены; pbrt уже стал более качественной системой благодаря тому, что я разобрался с обработкой этой сцены.
Первые рендеры
Получив доступ к сцене, я сразу же её скачал (с моим домашним Интернет-подключением на это ушло несколько часов) и распаковал из tar, получив 29 ГБ файлов pbrt и 38 ГБ текстурных карт ptex2. Я беспечно попытался отрендерить сцену на моей домашней системе (с 16 ГБ ОЗУ и 4-ядерным ЦП). Вернувшись через какое-то время к компьютеру, я увидел, что он завис, вся ОЗУ заполнена, а pbrt всё ещё пытается завершить парсинг описания сцены. ОС стремилась справиться с задачей, используя виртуальную память, но это казалось безнадёжным. Прибив процесс, мне пришлось ждать ещё около минуты, прежде чем система начала реагировать на мои действия.
Следующей попыткой был инстанс Google Compute Engine, позволяющий использовать больше ОЗУ (120 ГБ) и больше ЦП (32 потоков на 16 ЦП). Хорошая новость заключалась в том, что pbrt смог успешно отрендерить сцену (благодаря труду Хитер и Расмуса по её переводу в формат pbrt). Было очень волнующе увидеть, что pbrt может генерировать относительно хорошие пиксели для качественного киноконтента, но скорость оказалась совсем не такой восхитительной: 34 мин 58 с только на парсинг описания сцены, причём во время рендеринга система тратила до 70 ГБ ОЗУ.
Да, на диске лежало 29 гигабайт файлов описаний сцен формата pbrt, которые нужно было спарсить, поэтому я не ждал, что первый этап займёт пару секунд. Но тратить полчаса ещё до того, как начнут трассироваться лучи? Это сильно усложняет саму работу со сценой.
С другой стороны, такая скорость говорила нам, что в коде, вероятно, происходит что-то очень дурно пахнущее; не просто «инверсию матрицы можно выполнить на 10% быстрее»; скорее, что-то уровня «ой, мы проходим по связанному списку из 100 тысяч элементов». Я был настроен оптимистично и надеялся, что разобравшись, смогу значительно ускорить процесс.
Статистика не помогает
Первым местом, в котором я начал искать подсказки, была статистика дампа pbrt после рендеринга. Основные этапы выполнения pbrt настроены так, что можно собирать приблизительные данные профилирования благодаря фиксации операций с периодичными прерываниями в процессе рендеринга. К сожалению, статистика нам мало чем помогла: по отчётам, из почти 35 минут до начала рендеринга 4 минуты 22 секунды было потрачено на построение BVH, но про остальное время не было указано никаких подробностей.
Построение BVH — это единственная значимая вычислительная задача, выполняемая во время парсинга сцены; всё остальное по сути является десериализацией описаний геометрии и материалов. Знание о том, сколько времени тратилось на создание BVH, дало понимание того, насколько (не)эффективной была система: оставшееся время, а именно около 30 минут, уходило на парсинг 29 ГБ данных, то есть скорость составляла 16,5 МБ/с. Хорошо оптимизированные парсеры JSON, по сути выполняющие такую же задачу, работают со скоростью 50-200 МБ/с. Ясно, что пространство для усовершенствования ещё есть.
Чтобы лучше понять, на что тратится время, я запустил pbrt с инструментом Linux perf, которым раньше никогда не пользовался. Но, похоже, он справился с задачей. Я проинструктировал его искать символы DWARF для получения названий функций (
--call-graph dwarf), и чтобы не получить стогигабайтные файлы трассировки, вынужден был снизить частоту сэмплирования с 4000 до 100 сэмплов в секунду (-F 100). Но с этими параметрами всё прошло замечательно, и я был приятно удивлён, что инструмент perf report имеет интерфейс с nice curses.Вот, что он смог мне сказать после запуска с pbrt:
Я не шутил, когда говорил об «интерфейсе с nice curses».
Мы видим, что больше половины времени тратится на механику парсинга:
yyparse() — это парсер, сгенерированный bison, а yylex() — это лексический анализатор (лексер), сгенерированный flex. Больше половины времени в yylex() тратится на strtod(), преобразующую строки в значения double. Мы отложим атаку на yyparse() и yylex() до третьей статьи этой серии, но теперь уже можем понять, что хорошей идеей может быть снижение количества вбрасываемых в рендерер данных.Из текста в PLY
Один из способов тратить меньше времени на парсинг данных в текстовом виде — преобразовать данные в формат, который парсится более эффективно. Довольно большая часть из 29 ГБ этих файлов описаний сцен являются мешами из треугольников, а в pbrt уже есть нативная поддержка формата PLY, который является эффективным двоичным представлением полигональных мешей. Также в pbrt есть флаг командной строки
--toply, который парсит файл описания сцены pbrt, преобразует все найденные меши треугольников в файлы PLY и создаёт новый файл pbrt, который ссылается на эти файлы PLY.Загвоздка заключается в том, что в сцене Disney активно используются ptex-текстуры, которые, в свою очередь, требуют, чтобы с каждым треугольником было связано значение
faceIndex, определяющее, из какой грани исходного подразделённого меша он взят. Для переноса этих значений было достаточно просто добавить поддержку новых полей в файле PLY. При дальнейших исследованиях выяснилось, что в случае преобразования каждого меша — даже если в нём всего десяток треугольников — в файл PLY приводит к тому, что в папке создаются десятки тысяч мелких файлов PLY, и это создаёт свои проблемы с производительностью; от этой проблемы удалось избавиться, добавив в реализацию возможность оставлять мелкие меши неизменными.Я написал небольшой сценарий командной строки для преобразования всех файлов
*_geometry.pbrt в папке, чтобы использовать PLY для крупных мешей. Заметьте, что в нём есть жёстко заданные допущения о путях, которые необходимо изменить, чтобы скрипт работал в другом месте.Первое повышение скорости
После преобразования всех больших мешей в PLY размер описания сцены на диске снизился с 29 до 22 ГБ: 16,9 ГБ файлов сцены pbrt и 5,1 ГБ двоичных файлов PLY. После преобразования общее время первого этапа системы снизилось до 27 минут 35 секунд, а экономия составила 7 минут 23 секунды, то есть мы ускорились в 1,3 раза3. Обработка файла PLY намного эффективнее, чем обработка текстового файла pbrt: всего 40 секунд времени запуска тратилось на парсинг файлов PLY, и мы видим, что файлы PLY обрабатывались со скоростью примерно 130 МБ/с, или примерно в 8 раз быстрее, чем текстовый формат pbrt.
Это была хорошая лёгкая победа, но нам ещё предстояло сделать многое.
В следующий раз мы разберёмся, где на самом деле используется вся память, исправим здесь несколько ошибок и добьёмся в процессе ещё большего повышения скорости.
Примечания
- Теперь вам должна быть более понятна мотивация добавления поддержки ptex с моей стороны и преобразования Disney BSDF в pbrt в прошлом году.
- Всё время здесь и в последующих постах указывается для WIP-версии (Work In Progress), с которой я работал до официального релиза. Похоже, что финальная версия немного больше. Мы будем придерживаться результатов, которые я записал при работе с первоначальной сценой, несмотря на то, что они не совсем соответствуют результатам финальной версии. Подозреваю, уроки из них можно извлечь одинаковые.
- Заметьте, что повышение скорости по сути соответствует тому, чего можно было ожидать при приблизительно 50-процентном снижении объёма парсящихся данных. Количество времени, которое мы тратим по показаниям профайлера, подтверждает нашу идею.

