Я не искал неприятностей. Не запускал процесс сборки Chrome тысячу раз за выходные, а только занимался самыми обычными задачами 21-го века — просто писал электронное письмо в 10:30 утра. И вдруг Gmail подвис. Я продолжал печатать несколько секунд, но на экране не появлялось никаких символов. Затем внезапно Gmail отвис — и я вернулся к своему очень важному письму. Но впоследствии всё повторилось, только на этот раз Gmail ещё дольше не отвечал запросы. Это странно…
Трудно устоять перед возможностью провести хорошее расследование, но в данном случае вызов особенно силён. Ведь я в Google работаю над улучшением производительности Chrome для Windows. Обнаружить причину зависания — моя работа. И после множества фальстартов и тяжёлых усилий мне всё-таки удалось выяснить, как Chrome, Gmail, Windows и наш IT-отдел вместе помешали мне набрать электронное письмо. По ходу дела нашёлся способ сэкономить значительное количество памяти для некоторых веб-страниц в Chrome.
В расследовании оказалось так много нюансов, что я оставлю некоторые для другой статьи, а сейчас полностью объясню причины подвисаний.
Как обычно, у меня в фоне работает UIforETW и отслеживает циклические буферы, поэтому оставалось только ввести Ctrl+Win+R — и буферы примерно за последние тридцать секунд активности системы сохранились на диск. Я загрузил их в Windows Performance Analyzer (WPA), но не смог окончательно установить зависание.
Когда программа Windows перестаёт передавать сообщения, то выдаются события ETW с указанием, где именно это произошло, поэтому такие типы зависаний тривиально найти. Но, видимо, Chrome продолжал передавать сообщения. Я поискал момент, когда один из ключевых потоков Chrome либо вошёл в активный цикл, либо полностью простаивал, но ничего явного не нашёл. Были некоторые места, где Chrome преимущественно простаивал, но даже тогда все ключевые потоки продолжали трудиться, поэтому нельзя было быть уверенным, где произошло зависание — Chrome мог простаивать просто в отсутствие событий:
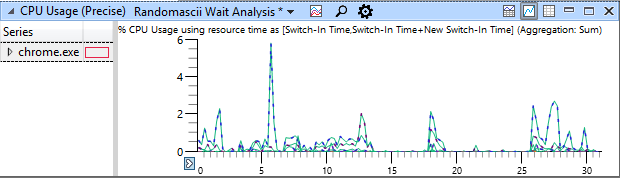
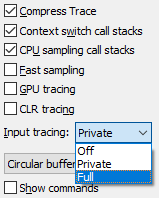 В UIforETW есть встроенный кейлоггер, который часто полезен при идентификации ключевых точек в трассировке. Тем не менее, по очевидным причинам безопасности он по умолчанию анонимизирует нажатия клавиш, расценивая каждое введённое число как “1”, а каждую букву как “A”. Это затрудняет поиск точного момента зависания, поэтому я изменил тип трассировки с «частной» на «полную» и ожидал зависания. Около 10:30 на следующее утро зависание повторилось. Я сохранил буферы трассировки и сохранил такую пометку в поле информации трассировки UIforETW:
В UIforETW есть встроенный кейлоггер, который часто полезен при идентификации ключевых точек в трассировке. Тем не менее, по очевидным причинам безопасности он по умолчанию анонимизирует нажатия клавиш, расценивая каждое введённое число как “1”, а каждую букву как “A”. Это затрудняет поиск точного момента зависания, поэтому я изменил тип трассировки с «частной» на «полную» и ожидал зависания. Около 10:30 на следующее утро зависание повторилось. Я сохранил буферы трассировки и сохранил такую пометку в поле информации трассировки UIforETW:
Это обычное обсуждение способов добраться до офиса, но важно, что теперь появился способ найти зависание в трассировке ETW. Я загружаю трассировку, смотрю на данные кейлогера в поле Generic Events (события выдаются самим UIforETW, а каждое представляет собой фиолетовый ромб на скриншоте внизу) — и сразу вижу, где произошло зависание, с которым явно коррелирует провал в использовании CPU:

Хорошо, но почему Chrome остановился? Вот некоторые намёки: на скриншотах не показано, что каждый раз при этом WmiPrvSE.exe полностью использует гиперпоток CPU. Но это не должно иметь значения. В моей машине 24 ядра/48 потоков, так что потребление одного гиперпотока означает, что система по-прежнему свободна на 98%.
Затем я приблизился к явно важному периоду, когда Chrome простаивал — и посмотрел, в частности, на процесс CrRendererMain в chrome.exe (27368), соответствующий вкладке Gmail.
Проблема прояснилась. В течение 2,81 секунды зависания этот поток запускался по расписанию 440 раз. Обычно запуска каждые 6 мс достаточно, чтобы сделать программу отзывчивой, но по какой-то причине этого не произошло. Я заметил, что каждый раз, когда он просыпался, то был на одном стеке. Если упростить:
Chrome вызывает VirtualAlloc, который пытается обновить некоторые “CfgBits” и должен получить блокировку. Сначала я предположил, что Chrome вызывал VirtualAlloc 440 раз, что кажется странным. Но реальность оказалась ещё более странной. Chrome вызвал VirtualAlloc однажды — и должен был получить блокировку. Chrome сигнализировал о доступности блокировки, но — 439 раз подряд — когда Chrome просыпался и пытался получить блокировку, она оказывалась недоступна. Блокировка получалась повторно через процесс, упомянутый выше.
Это потому что блокировки Windows по своей природе несправедливы — и если поток освобождает блокировку, а затем немедленно её запрашивает снова, то может получать её вечно. Голод. Подробнее об этом в следующий раз.
В каждом случае процессом, который сигнализирует Chrome захватить блокировку, был WmiPrvSE.ехе, отпускающий блокировку на этот стек:
Некоторое время занял разбор в WMI (подробнее об этом в следующий раз), но в итоге я написал программу для воссоздания поведения WMI. У меня были данные выборки CPU, которые показали, на что тратит время WmiPrvSE.exe (в упрощённом виде с некоторыми правками):
Воспроизвести медленное сканирование по данным выборки было довольно легко. Интересной частью стека вызовов выше оказался NtQueryVirtualMemory, который используется для сканирования памяти процесса и вызывается соответствующим образом именованным GetProcessVaData, где Va, вероятно, обозначает виртуальный адрес. Моя программа VirtualScan просто вызывала NtQueryVirtualMemory в очевидном цикле для сканирования адресного пространства указанного процесса, код работал очень долго для сканирования процесса Gmail (10-15 секунд) — и приводил к зависанию. Но почему?
Преимущество собственноручно написанного цикла сканирования в том, что можно генерировать статистику. NtQueryVirtualMemory возвращает данные для каждого смежного диапазона адресного пространства с соответствующими атрибутами. Такими могут быть «всё зарезервировано», «всё зафиксировано с определенными настройками защиты» и т.д. В процессе Gmail около 26 000 этих блоков, но я нашёл другой процесс (как оказалось, это WPA) с 16 000 блоками памяти, который сканировался очень быстро.
В какой-то момент я посмотрел на процесс Gmail с помощью vmmap и заметил, что процесс Gmail занимает немало памяти (361 836 КБ) и много отдельных блоков (49 719), поступающих из единого источника зарезервированной общей памяти — источника размером 2 147 483 648 КБ, то есть 2 ТБ. Что?

Я знал, что резервирование 2 ТБ используется для Control Flow Guard (CFG), и вспомнил, что “CFG” действительно появлялся в стеках вызовов, где ожидал процесс Gmail в Chrome — на стеке присутствовал MiCommitVadCfgBits. Может, большое количество блоков в регионе CFG и было проблемой!
Control Flow Guard (CFG) используется для защиты от эксплойтов. Два терабайта зарезервированы как битовый массив, который указывает на валидные косвенные переходы в 128-терабайтном адресном пространстве пользовательского режима. Поэтому я изменил свой сканер виртуальной памяти для подсчёта, сколько блоков находится в регионе CFG (просто поиск резервации 2 ТБ), а сколько блоков помечены как исполняемые. Поскольку память CFG используется для описания исполняемой памяти, то я ожидал увидеть в процессе один блок памяти CFG для каждого блока исполняемой памяти. Вместо этого я увидел 98 блоков исполняемой памяти и 24 866 блоков фиксированной CFG-памяти. Существенное расхождение:
Задним умом это кажется очевидным, но что если битовый массив CFG никогда не очищается? Что если память выделяется в битовом массиве CFG при выделении исполняемой памяти, но не освобождается при освобождении исполняемой памяти? Тогда такое поведение понятно.
Следующий шаг — написание программы VAllocStress, которая выделяет и освобождает тысячи блоков исполняемой памяти по случайным адресам. Для этого исполняемого файла должен работать 64-битный режим CFG, и возникли некоторые затруднения, потому что я действительно не знал, что я пытаюсь сделать, но всё заработало. После выделения и освобождения этого количества блоков исполняемой памяти программа должна сидеть в цикле, откуда она изредка пытается выделить/освободить больше исполняемой памяти, и следит, когда этот процесс замедляется. Вот базовый алгоритм для VAllocStress:
Вот и всё. Очень просто. И было так приятно, когда это сработало. Я запустил программу, а потом поручил VirtualScan просканировать процесс VAllocStress. Быстро выяснилось, что блок CFG ужасно фрагментирован, и сканирование занимает очень много времени. И моя программа VAllocStress зависала на время сканирования!
На этом этапе я смоделировал фрагментацию CFG, длительное время сканирования и зависание. Ура!
Оказывается, в JavaScript-движке v8 задействованы объекты CodeRange для управления генератором кода, и каждый объект CodeRange ограничен диапазоном адресов 128 МБ. Казалось бы, это достаточно небольшой объём, чтобы избежать безудержного распределения CFG, которые мы наблюдаем.
Но что, если у вас несколько объектов CodeRange, и они распределяются по случайным адресам, а затем освобождаются? Я настроил конструктор CodeRange, оставил работать Gmail — и нашёл виновника. Каждые пару минут создавался (и уничтожался) новый объект CodeRange. В отладчике легко видеть, как WorkerThread::Start выделяет эти объекты. И тут головоломка сложилась:
Медленное сканирование памяти CFG фактически исправлено в Windows 10 RS4 (обновление от апреля 2018 года), что заставило меня ненадолго задуматься, был ли смысл во всём этом расследовании. Оказывается, был.
Резервирование CFG начинается с простой резервации адресов — никакая память фактически не фиксируется. Но по мере выделения исполняемых страниц часть резервации CFG превращается в выделенную память, используя реальные страницы памяти. И эти страницы никогда не освобождаются. Если вы продолжаете выделять и освобождать случайно расположенные блоки исполняемой памяти, то область CFG может стать бесконечно большой! Ну, это не совсем правда. Блок памяти CFG ограничен кэшем определённого размера. Но это мало утешает, если ограничение составляет 2 ТБ на процесс!
Худшее, что я видел до сих пор — это когда моя вкладка Gmail работала в течение восьми дней и накопила 353,3 МБ памяти CFG и 59,2 МБ таблиц страниц для отображения этой памяти, что в общей сложности составляет около 400 МБ. По какой-то причине у большинства людей нет таких проблем или они гораздо мягче, чем у меня.
Команда v8 (движок JavaScript в Chrome) изменила код таким образом, что он повторно использует адреса для объектов CodeRange, что довольно хорошо устраняет эту проблему. Microsoft уже исправила проблемы с производительностью сканирования памяти CFG. Может, когда-нибудь Microsoft будет освобождать регионы CFG по мере освобождения исполняемой памяти, по крайней мере, в простых случаях, когда освобождаются большие диапазоны адресов. И баг vmmap тоже в обработке.
Большинство пользователей и моих коллег никогда не замечали этой проблемы. Я заметил её только потому что:
Кажется очень маловероятным, что, как один из самых квалифицированных людей для диагностирования этой ошибки, я первым её заметил. Если убрать любой из вышеперечисленных факторов, то ни зависания, ни связанную с этим потерю памяти, возможно, никогда бы не заметили.
Кстати, зависания происходили именно в 10:30 утра только потому, что именно в этом время наш IT-отдел запускал соответствующее сканирование. Если хотите запустить сканирование вручную, можете зайти в Control Panel → Configuration Manager → Actions, выбрать Hardware Inventory Cycle и нажать Run Now.

Если желаете поиграться, то исходный код VAllocStress и VirtualScan лежит на Github.
В этом расследовании много нюансов. Некоторые из них важные (таблицы страниц), некоторые поучительные (блокировки), а некоторые оказались пустой тратой времени (детали WMI). В следующей статье я расскажу подробнее о них и об ошибке vmmap. Если хотите больше кровавых подробностей — некоторые из которых оказались неправильными или неактуальными — можете следить за расследованием на crbug.com/870054.
UPD. Вторая часть
Трудно устоять перед возможностью провести хорошее расследование, но в данном случае вызов особенно силён. Ведь я в Google работаю над улучшением производительности Chrome для Windows. Обнаружить причину зависания — моя работа. И после множества фальстартов и тяжёлых усилий мне всё-таки удалось выяснить, как Chrome, Gmail, Windows и наш IT-отдел вместе помешали мне набрать электронное письмо. По ходу дела нашёлся способ сэкономить значительное количество памяти для некоторых веб-страниц в Chrome.
В расследовании оказалось так много нюансов, что я оставлю некоторые для другой статьи, а сейчас полностью объясню причины подвисаний.
Как обычно, у меня в фоне работает UIforETW и отслеживает циклические буферы, поэтому оставалось только ввести Ctrl+Win+R — и буферы примерно за последние тридцать секунд активности системы сохранились на диск. Я загрузил их в Windows Performance Analyzer (WPA), но не смог окончательно установить зависание.
Когда программа Windows перестаёт передавать сообщения, то выдаются события ETW с указанием, где именно это произошло, поэтому такие типы зависаний тривиально найти. Но, видимо, Chrome продолжал передавать сообщения. Я поискал момент, когда один из ключевых потоков Chrome либо вошёл в активный цикл, либо полностью простаивал, но ничего явного не нашёл. Были некоторые места, где Chrome преимущественно простаивал, но даже тогда все ключевые потоки продолжали трудиться, поэтому нельзя было быть уверенным, где произошло зависание — Chrome мог простаивать просто в отсутствие событий:
В UIforETW есть встроенный кейлоггер, который часто полезен при идентификации ключевых точек в трассировке. Тем не менее, по очевидным причинам безопасности он по умолчанию анонимизирует нажатия клавиш, расценивая каждое введённое число как “1”, а каждую букву как “A”. Это затрудняет поиск точного момента зависания, поэтому я изменил тип трассировки с «частной» на «полную» и ожидал зависания. Около 10:30 на следующее утро зависание повторилось. Я сохранил буферы трассировки и сохранил такую пометку в поле информации трассировки UIforETW:Набирал «отложить для тех, у кого больше опыт работы с подводным плаванием» — и Gmail подвис в конце слова «тех», а затем возобновил работу в районе слова «опыт». Вкладка Gmail с PID 27368.
Это обычное обсуждение способов добраться до офиса, но важно, что теперь появился способ найти зависание в трассировке ETW. Я загружаю трассировку, смотрю на данные кейлогера в поле Generic Events (события выдаются самим UIforETW, а каждое представляет собой фиолетовый ромб на скриншоте внизу) — и сразу вижу, где произошло зависание, с которым явно коррелирует провал в использовании CPU:
Хорошо, но почему Chrome остановился? Вот некоторые намёки: на скриншотах не показано, что каждый раз при этом WmiPrvSE.exe полностью использует гиперпоток CPU. Но это не должно иметь значения. В моей машине 24 ядра/48 потоков, так что потребление одного гиперпотока означает, что система по-прежнему свободна на 98%.
Затем я приблизился к явно важному периоду, когда Chrome простаивал — и посмотрел, в частности, на процесс CrRendererMain в chrome.exe (27368), соответствующий вкладке Gmail.
Примечание: хочу сказать спасибо себе из 2015 года за просьбу Microsoft улучшить механизмы именования потоков, и спасибо Microsoft за реализацию всего предложенного — названия потоков в WPA просто великолепны!
Проблема прояснилась. В течение 2,81 секунды зависания этот поток запускался по расписанию 440 раз. Обычно запуска каждые 6 мс достаточно, чтобы сделать программу отзывчивой, но по какой-то причине этого не произошло. Я заметил, что каждый раз, когда он просыпался, то был на одном стеке. Если упростить:
chrome_child.dll (stack base) KernelBase.dll!VirtualAlloc ntoskrnl.exe!MiCommitVadCfgBits ntoskrnl.exe!MiPopulateCfgBitMap ntoskrnl.exe!ExAcquirePushLockExclusiveEx ntoskrnl.exe!KeWaitForSingleObject (stack leaf)
Chrome вызывает VirtualAlloc, который пытается обновить некоторые “CfgBits” и должен получить блокировку. Сначала я предположил, что Chrome вызывал VirtualAlloc 440 раз, что кажется странным. Но реальность оказалась ещё более странной. Chrome вызвал VirtualAlloc однажды — и должен был получить блокировку. Chrome сигнализировал о доступности блокировки, но — 439 раз подряд — когда Chrome просыпался и пытался получить блокировку, она оказывалась недоступна. Блокировка получалась повторно через процесс, упомянутый выше.
Это потому что блокировки Windows по своей природе несправедливы — и если поток освобождает блокировку, а затем немедленно её запрашивает снова, то может получать её вечно. Голод. Подробнее об этом в следующий раз.
В каждом случае процессом, который сигнализирует Chrome захватить блокировку, был WmiPrvSE.ехе, отпускающий блокировку на этот стек:
ntoskrnl.exe!KiSystemServiceCopyEnd (stack base) ntoskrnl.exe!NtQueryVirtualMemory ntoskrnl.exe!MmQueryVirtualMemory ntoskrnl.exe!MiUnlockAndDereferenceVad ntoskrnl.exe!ExfTryToWakePushLock (stack leaf)
Некоторое время занял разбор в WMI (подробнее об этом в следующий раз), но в итоге я написал программу для воссоздания поведения WMI. У меня были данные выборки CPU, которые показали, на что тратит время WmiPrvSE.exe (в упрощённом виде с некоторыми правками):
WmiPerfClass.dll!EnumSelectCounterObjects (stack base) WmiPerfClass.dll!ConvertCounterPath pdh.dll!PdhiTranslateCounter pdh.dll!GetSystemPerfData KernelBase.dll!blah-blah-blah advapi32.dll!blah-blah-blah perfproc.dll!blah-blah-blah perfproc.dll!GetProcessVaData ntdll.dll!NtQueryVirtualMemory ntoskrnl.exe!NtQueryVirtualMemory ntoskrnl.exe!MmQueryVirtualMemory ntoskrnl.exe!MiQueryAddressSpan ntoskrnl.exe!MiQueryAddressState ntoskrnl.exe!MiGetNextPageTable (stack leaf)
Воспроизвести медленное сканирование по данным выборки было довольно легко. Интересной частью стека вызовов выше оказался NtQueryVirtualMemory, который используется для сканирования памяти процесса и вызывается соответствующим образом именованным GetProcessVaData, где Va, вероятно, обозначает виртуальный адрес. Моя программа VirtualScan просто вызывала NtQueryVirtualMemory в очевидном цикле для сканирования адресного пространства указанного процесса, код работал очень долго для сканирования процесса Gmail (10-15 секунд) — и приводил к зависанию. Но почему?
Преимущество собственноручно написанного цикла сканирования в том, что можно генерировать статистику. NtQueryVirtualMemory возвращает данные для каждого смежного диапазона адресного пространства с соответствующими атрибутами. Такими могут быть «всё зарезервировано», «всё зафиксировано с определенными настройками защиты» и т.д. В процессе Gmail около 26 000 этих блоков, но я нашёл другой процесс (как оказалось, это WPA) с 16 000 блоками памяти, который сканировался очень быстро.
В какой-то момент я посмотрел на процесс Gmail с помощью vmmap и заметил, что процесс Gmail занимает немало памяти (361 836 КБ) и много отдельных блоков (49 719), поступающих из единого источника зарезервированной общей памяти — источника размером 2 147 483 648 КБ, то есть 2 ТБ. Что?
Я знал, что резервирование 2 ТБ используется для Control Flow Guard (CFG), и вспомнил, что “CFG” действительно появлялся в стеках вызовов, где ожидал процесс Gmail в Chrome — на стеке присутствовал MiCommitVadCfgBits. Может, большое количество блоков в регионе CFG и было проблемой!
Control Flow Guard (CFG) используется для защиты от эксплойтов. Два терабайта зарезервированы как битовый массив, который указывает на валидные косвенные переходы в 128-терабайтном адресном пространстве пользовательского режима. Поэтому я изменил свой сканер виртуальной памяти для подсчёта, сколько блоков находится в регионе CFG (просто поиск резервации 2 ТБ), а сколько блоков помечены как исполняемые. Поскольку память CFG используется для описания исполняемой памяти, то я ожидал увидеть в процессе один блок памяти CFG для каждого блока исполняемой памяти. Вместо этого я увидел 98 блоков исполняемой памяти и 24 866 блоков фиксированной CFG-памяти. Существенное расхождение:
Scan time, Committed, page tables, committed blocks Total: 41.763s, 1457.7 MiB, 67.7 MiB, 32112, 98 code blocks CFG: 41.759s, 353.3 MiB, 59.2 MiB, 24866
vmmap показывает резервирование и выделенную память как блоки, а мой инструмент сканирования считает только выделенные блоки — вот почему vmmap показывает 49 684 блоков, а мой инструмент 24 866
Задним умом это кажется очевидным, но что если битовый массив CFG никогда не очищается? Что если память выделяется в битовом массиве CFG при выделении исполняемой памяти, но не освобождается при освобождении исполняемой памяти? Тогда такое поведение понятно.
Воспроизведение от начала до конца
Следующий шаг — написание программы VAllocStress, которая выделяет и освобождает тысячи блоков исполняемой памяти по случайным адресам. Для этого исполняемого файла должен работать 64-битный режим CFG, и возникли некоторые затруднения, потому что я действительно не знал, что я пытаюсь сделать, но всё заработало. После выделения и освобождения этого количества блоков исполняемой памяти программа должна сидеть в цикле, откуда она изредка пытается выделить/освободить больше исполняемой памяти, и следит, когда этот процесс замедляется. Вот базовый алгоритм для VAllocStress:
- Многократный цикл:
- Выделить исполняемую память с помощью VirtualAlloc по случайному адресу.
- Освободить память.
- Затем бесконечный цикл:
- Спящий режим на 500 мс (не хочу свински захватывать процессор).
- Выделить немного исполняемой памяти с VirtualAlloc по заданному адресу.
- Вывод сообщения, если вызов VirtualAlloc занимает более ~500 мс
- Освободить память.
Вот и всё. Очень просто. И было так приятно, когда это сработало. Я запустил программу, а потом поручил VirtualScan просканировать процесс VAllocStress. Быстро выяснилось, что блок CFG ужасно фрагментирован, и сканирование занимает очень много времени. И моя программа VAllocStress зависала на время сканирования!
На этом этапе я смоделировал фрагментацию CFG, длительное время сканирования и зависание. Ура!
Первопричина
Оказывается, в JavaScript-движке v8 задействованы объекты CodeRange для управления генератором кода, и каждый объект CodeRange ограничен диапазоном адресов 128 МБ. Казалось бы, это достаточно небольшой объём, чтобы избежать безудержного распределения CFG, которые мы наблюдаем.
Но что, если у вас несколько объектов CodeRange, и они распределяются по случайным адресам, а затем освобождаются? Я настроил конструктор CodeRange, оставил работать Gmail — и нашёл виновника. Каждые пару минут создавался (и уничтожался) новый объект CodeRange. В отладчике легко видеть, как WorkerThread::Start выделяет эти объекты. И тут головоломка сложилась:
- Gmail использует сервис-воркеров, вероятно, для реализации автономного режима.
- Они появляются и исчезают каждые несколько минут, потому что так ведут себя сервис-воркеры.
- Каждый поток воркера получает временный объект CodeRange, который выделяет некоторые исполняемые страницы для JITted-кода JavaScript из случайного расположения в 47-битном адресном пространстве процесса.
- При выделении новых кодовых страниц производятся записи в резервации памяти CFG на 2 ТБ.
- Распределения CFG никогда не освобождаются.
- NtQueryVirtualMemory мучительно медленно сканирует память CFG (около 1 мс на блок) по причинам, которые я не понимаю.
Медленное сканирование памяти CFG фактически исправлено в Windows 10 RS4 (обновление от апреля 2018 года), что заставило меня ненадолго задуматься, был ли смысл во всём этом расследовании. Оказывается, был.
Память
Резервирование CFG начинается с простой резервации адресов — никакая память фактически не фиксируется. Но по мере выделения исполняемых страниц часть резервации CFG превращается в выделенную память, используя реальные страницы памяти. И эти страницы никогда не освобождаются. Если вы продолжаете выделять и освобождать случайно расположенные блоки исполняемой памяти, то область CFG может стать бесконечно большой! Ну, это не совсем правда. Блок памяти CFG ограничен кэшем определённого размера. Но это мало утешает, если ограничение составляет 2 ТБ на процесс!
Худшее, что я видел до сих пор — это когда моя вкладка Gmail работала в течение восьми дней и накопила 353,3 МБ памяти CFG и 59,2 МБ таблиц страниц для отображения этой памяти, что в общей сложности составляет около 400 МБ. По какой-то причине у большинства людей нет таких проблем или они гораздо мягче, чем у меня.
Решение
Команда v8 (движок JavaScript в Chrome) изменила код таким образом, что он повторно использует адреса для объектов CodeRange, что довольно хорошо устраняет эту проблему. Microsoft уже исправила проблемы с производительностью сканирования памяти CFG. Может, когда-нибудь Microsoft будет освобождать регионы CFG по мере освобождения исполняемой памяти, по крайней мере, в простых случаях, когда освобождаются большие диапазоны адресов. И баг vmmap тоже в обработке.
Большинство пользователей и моих коллег никогда не замечали этой проблемы. Я заметил её только потому что:
- У меня был включен автономный режим Gmail.
- Я работал на старой версии Windows 10.
- Наш IT-отдел регулярно проводит WMI-сканирование наших компьютеров.
- Я был внимателен.
- Мне повезло.
Кажется очень маловероятным, что, как один из самых квалифицированных людей для диагностирования этой ошибки, я первым её заметил. Если убрать любой из вышеперечисленных факторов, то ни зависания, ни связанную с этим потерю памяти, возможно, никогда бы не заметили.
Кстати, зависания происходили именно в 10:30 утра только потому, что именно в этом время наш IT-отдел запускал соответствующее сканирование. Если хотите запустить сканирование вручную, можете зайти в Control Panel → Configuration Manager → Actions, выбрать Hardware Inventory Cycle и нажать Run Now.
Исходный код
Если желаете поиграться, то исходный код VAllocStress и VirtualScan лежит на Github.
Нюансы
В этом расследовании много нюансов. Некоторые из них важные (таблицы страниц), некоторые поучительные (блокировки), а некоторые оказались пустой тратой времени (детали WMI). В следующей статье я расскажу подробнее о них и об ошибке vmmap. Если хотите больше кровавых подробностей — некоторые из которых оказались неправильными или неактуальными — можете следить за расследованием на crbug.com/870054.
UPD. Вторая часть

