В прошлой статье я обещал подробнее раскрыть некоторые детали, которые опустил во время расследования [подвисаний Gmail в Chrome под Windows — прим. пер.], включая таблицы страниц, блокировки, WMI и ошибку vmmap. Сейчас восполняю эти пробелы вместе с обновлёнными примерами кода. Но сначала вкратце изложим суть.
Речь шла о том, что процесс с поддержкой Control Flow Guard (CFG) выделяет исполняемую память, одновременно выделяя память CFG, которую Windows никогда не освобождает. Поэтому если вы продолжаете выделять и освобождать исполняемую память по разным адресам, то процесс накапливает произвольный объём памяти CFG. Браузер Chrome делает это, что приводит к практически неограниченной утечке памяти и подвисаниям на некоторых машинах.
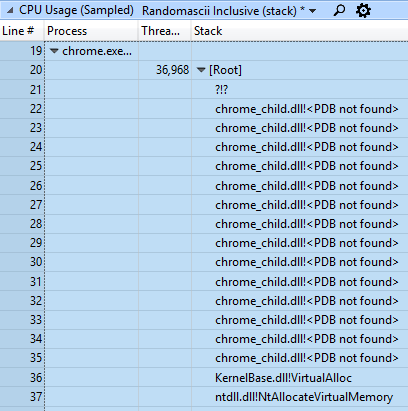
Нужно заметить, что подвисаний трудно избежать, если VirtualAlloc начинает работать более чем в миллион раз медленнее, чем обычно.
Кроме CFG есть и другая потраченная впустую память, хотя её не так много, как утверждает vmmap.
И память программы, и память CFG в конечном счёте выделяются 4-килобайтными страницами (подробнее об этом позже). Поскольку 4 КБ памяти CFG могут описывать 256 КБ памяти программы (подробнее об этом позже), это означает, что если выделить блок памяти 256 КБ, выровненный по 256 КБ, то вы получите одну страницу CFG на 4 КБ. И если выделить блок исполняемой памяти 4 КБ, то вы всё равно получите страницу CFG на 4 КБ, но её бóльшая часть не будет использоваться.
 Всё сложнее, если освобождается исполняемая память. Если применить функцию VirtualFree на блоке исполняемой памяти, не кратном 256 КБ или не выровненном по 256 КБ, то ОС должна провести некоторый анализ и проверить, что какая-нибудь другая исполняемая память не использует CFG-страницу. Авторы CFG решили не заморачиваться — и просто навсегда оставляют выделенную память CFG. Весьма прискорбно. Это означает, что когда моя тестовая программа выделяет, а затем освобождает 1 гигабайт выровненной исполняемой памяти, то она оставляет 16 МБ памяти CFG.
Всё сложнее, если освобождается исполняемая память. Если применить функцию VirtualFree на блоке исполняемой памяти, не кратном 256 КБ или не выровненном по 256 КБ, то ОС должна провести некоторый анализ и проверить, что какая-нибудь другая исполняемая память не использует CFG-страницу. Авторы CFG решили не заморачиваться — и просто навсегда оставляют выделенную память CFG. Весьма прискорбно. Это означает, что когда моя тестовая программа выделяет, а затем освобождает 1 гигабайт выровненной исполняемой памяти, то она оставляет 16 МБ памяти CFG.
На практике выходит, что когда JavaScript-движок Chrome выделяет, а затем освобождает 128 МБ выровненной исполняемой памяти (не вся она была использована, но весь диапазон выделен и сразу освобождён), то до 2 МБ памяти CFG останется выделенной, хотя тривиально освободить её целиком. Поскольку Chrome неоднократно выделяет и освобождает память по случайным адресам, то это приводит к вышеописанной проблеме.
В любой современной ОС каждый процесс получает собственное адресное пространство виртуальной памяти, чтобы ОС изолировала процессы и защитила память. Это делается с помощью блока управления памятью (MMU) и таблиц страниц. Память разбита на страницы по 4 КБ. Это минимальный объём памяти, который даёт вам ОС. На каждую страницу указывает восьмибайтовая запись в таблице страниц, а сами записи сохраняются в страницах по 4 КБ. Каждая из них указывает максимум на 512 различных страниц памяти, поэтому нам нужна иерархия таблиц страниц. Для 48-разрядного адресного пространства в 64-битной операционной системе система такая:
MMU индексирует таблицу 1-го уровня в первых 9 (из 48) битах адреса, таблицы 2-го уровня — в следующих 9 битах, и остальным уровням выдаётся по 9 бит, то есть всего 36 бит. Оставшиеся 12 бит используются для индексации 4-килобайтных страниц из таблицы 4-го уровня. Ну и ну.
Если сразу заполнить все уровни таблиц, то потребуется более 512 ГБ оперативной памяти, поэтому они заполняются по мере необходимости. Это означает, что при выделении страницы памяти ОС выделяет некоторые таблицы страниц — от нуля до трёх, в зависимости от того, находятся выделенные адреса в ранее неиспользуемой области 2 МБ, ранее неиспользуемой области 1 ГБ или ранее неиспользуемой области 512 ГБ (таблица страниц уровня 1 выделяется всегда).
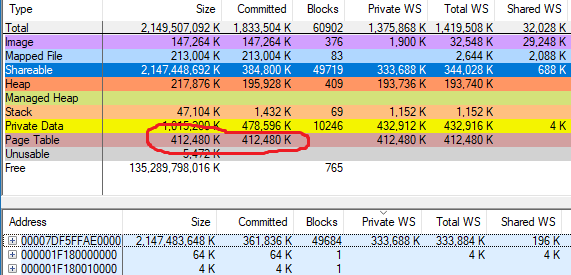
Короче говоря, выделения по случайным адресам обходятся значительно дороже, чем выделения близлежащих адресов, так как в первом случае нельзя совместно использовать таблицы страниц. Утечки CFG случаются довольно редко, так что когда vmmap показал 412 480 КБ использованных таблиц страниц в Chrome, я предположил правильность цифр. Вот скриншот vmmap с раскладкой памяти chrome.exe из прошлой статьи, но со строкой Page Table:
Но что-то показалось неправильным. Я решил добавить симулятор таблиц страниц в свой инструмент VirtualScan. Он подсчитывает, сколько страниц таблиц страниц необходимо для всей выделенной памяти в процессе сканирования. Нужно просто просканировать выделенную память, прибавляя к счётчику по единице на каждом числе, кратном 2 МБ, 1 ГБ или 512 ГБ.
Быстро обнаружилось, что результаты симулятора соответствуют vmmap на нормальных процессах, но не на процессах с большим количеством памяти CFG. Разница примерно соответствует выделенной памяти CFG. Для вышеупомянутого процесса, где vmmap говорит о 402,8 МБ (412 480 КБ) таблиц страниц мой инструмент показывает 67,7 МБ.
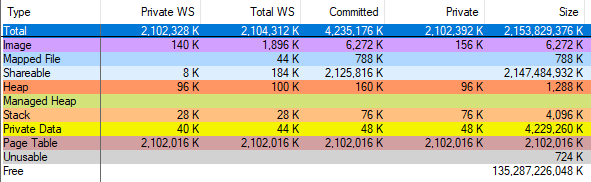
Я убедился в ошибке vmmap, запустив VAllocStress, который в настройках по умолчанию заставляет Windows выделять 2 гигабайта CFG-памяти. vmmap утверждал, что выделил 2 гигабайта таблиц страниц:
И когда я завершил процесс через Диспетчер задач, vmmap показал, что объём выделенной памяти снизился всего на 2 гигабайта. Итак, vmmap ошибается, мои вычисления с таблицами страниц верны, и после плодотворного обсуждения в твиттере я отправил отчёт об ошибке vmmap, которую должны исправить. Память CFG по-прежнему расходует много записей таблиц страниц (59,2 МБ в вышеприведённом примере), но не так много, как говорит vmmap, а после исправления вообще не будет расходовать практически ничего.
Хочу немного отступить назад и более подробно рассказать, что такое CFG.
CFG — сокращение от Control Flow Guard. Это метод защиты от эксплойтов с помощью перезаписи указателей на функции. При включенном CFG компилятор и ОС вместе проверяют валидность целевого объекта ветви. Сначала соответствующий управляющий байт CFG загружается из зарезервированной области CFG в 2 ТБ. 64-разрядный процесс в Windows распоряжается адресным пространством 128 ТБ, поэтому деление адреса на 64 позволяет найти соответствующий байт CFG для этого объекта.
Теперь у нас есть один байт, который должен описывать, какие адреса в 64-байтовом диапазоне являются допустимыми целями ветвей. Для этого CFG обрабатывает байт как четыре двухбитных значения, каждое из которых соответствует 16-байтовому диапазону. Это двухбитное число (значение которого от нуля до трёх) интерпретируется следующим образом:
Если цель косвенной ветви оказывается недопустимой, процесс завершается, и эксплойт предотвращается. Ура!
Из этого можно сделать вывод, что для максимальной безопасности косвенные цели ветви следует выравнивать по 16 байтам, и можно понять, почему объём памяти CFG для процесса примерно равен 1/64 от объёма памяти программы.
Подвисания Gmail происходят по двум причинам. Во-первых, сканирование CFG-памяти на Windows 10 16299 или более ранних версий мучительно медленно. Я видел, как сканирование адресного пространства процесса занимает 40 или более секунд, и буквально 99,99% этого времени сканируется зарезервированная память CFG, хотя она составляет всего около 75% зафиксированных блоков памяти. Не знаю, почему сканирование происходило так медленно, но в Windows 10 17134 это исправили, так что нет смысла изучать проблему более подробно.
Из-за медленного сканирования возникало подвисание, потому что Gmail хотел получить резервирование CFG, а WMI держал блокировку на время сканирования. Но блокировка резервирования памяти не удерживалась на протяжении всего сканирования. В моём примере в области CFG примерно 49 000 блоков, а функция NtQueryVirtualMemory, которая получает и освобождает блокировку, вызывалась по разу для каждого из них. Поэтому блокировка получалась и освобождалась ~49 000 раз и каждый раз удерживалась менее 1 миллисекунды.
Но хотя блокировка освобождалась 49 000 раз, процесс Chrome по какой-то причине так и не смог её получить. Это несправедливо!
Именно в этом суть проблемы. Как я писал в прошлый раз:
Справедливая блокировка означает, что два конкурирующих потока будут получать её по очереди. Но это означает много дорогих переключений контекста, так что на протяжении длительного времени блокировка не будет использоваться.

Несправедливые блокировки дешевле, и они не заставляют потоки ждать в очереди. Они просто захватывают блокировку, как упоминается в статье Джо Даффи. Он также пишет:
Как же соотнести заявление Джо от 2006 года о редкости голода с моим опытом на 100% повторяемой и длительной проблеме? Думаю, главная причина в том, что произошло в 2006 году. Intel выпустила Core Duo, и многоядерные компьютеры стали повсеместными.
Ведь оказывается, что эта проблема голода происходит только на многоядерной системе! В такой системе поток WMI снимет блокировку, подаст сигнал потоку Chrome о пробуждении и продолжит работу. Поскольку поток WMI уже запущен, у него «фора» перед потоком Chrome, так что он с лёгкостью повторно вызывает NtQueryVirtualMemory и повторно получает блокировку, прежде чем Chrome имеет шансы сделать это.
Очевидно, что в одноядерной системе одновременно может работать только один поток. Как правило, Windows повышает приоритет нового потока, а повышение приоритета означает, что при освобождении блокировки новый поток Chrome будет готов и немедленно опередит поток WMI. Это даёт потоку Chrome много времени, чтобы проснуться и получить блокировку, а голод никогда не наступает.
Понимаете? В многоядерной системе повышение приоритета в большинстве случаев не влияет на поток WMI, так как он будет выполняться на другом ядре!
Это означает, что система с дополнительными ядрами может медленнее реагировать, чем система с той же рабочей нагрузкой и меньшим количеством ядер. Любопытен и другой вывод: если бы у моего компьютера была большая нагрузка — потоки соответствующего приоритета, работающие на всех ядрах процессора, — то подвисаний можно было бы избежать (не пытайтесь повторить это дома).
Таким образом, несправедливые блокировки повышают производительность, но могут привести к голоду. Подозреваю, что решением может быть то, что я называю «иногда справедливыми» блокировками. Скажем, 99% времени они будут несправедливыми, но в 1% отдавать блокировку другому процессу. Это с большего сохранит преимущества производительности, избежав проблемы голода. Раньше блокировки в Windows распределялись справедливо и, вероятно, можно частично вернуться к этому, найдя идеального баланс. Отказ от ответственности: я не эксперт по блокировкам или инженер ОС, но мне интересно услышать мысли об этом, и по крайней мере я не первый, кто предлагает нечто подобное.
Линус Торвальдс недавно оценил важность справедливых блокировок: здесь и здесь. Может быть, пришло время для изменений и в Windows.
Подводя итог: Блокировка на несколько секунд — это нехорошо, она ограничивает параллелизм. Но на многоядерных системах с несправедливыми блокировками снятие, а затем немедленное повторное получение блокировки ведёт себя именно так — у других потоков нет возможности для работы.
 Для всех этих исследований я полагался на трассировку ETW, так что слегка испугался, когда в начале расследования оказалось, что Windows Performance Analyzer (WPA) не мог загрузить символы Chrome. Уверен, буквально на прошлой неделе всё работало. Что же случилось…
Для всех этих исследований я полагался на трассировку ETW, так что слегка испугался, когда в начале расследования оказалось, что Windows Performance Analyzer (WPA) не мог загрузить символы Chrome. Уверен, буквально на прошлой неделе всё работало. Что же случилось…
Случилось то, что вышел Chrome M68, а он скомпонован с помощью lld-link вместо компоновщика VC++. Если запустить dumpbin и посмотреть на отладочную информацию, вы увидите:
Ладно, наверное, WPA не нравятся эти слэши. Но всё равно это не имеет смысла, потому что я изменил компоновщик на lld-link, и помню, что тестировал WPA до этого, так что же случилось…
Оказалось, что причина в новой WPA версии 17134. Я протестировал компоновку lld-Link — и она нормально работала в WPA 16299. Как совпало! Новый компоновщик и новая WPA оказались несовместимы.
Я поставил старую версию WPA, чтобы продолжить расследование (xcopy с машины со старой версией) и сообщил о баге lld-link, который разработчики быстро исправили. Теперь можно вернуться к WPA 17134, когда M69 скомпонуют исправленным линкером.
Триггер зависания WMI является оснасткой управления Windows (Windows Management Instrumentation), а в этом я плохо разбираюсь. Я обнаружил, что в 2014 году или ранее кто-то столкнулся с проблемой значительного использования CPU в WmiPrvSE.exe внутри perfproc!GetProcessVaData, но они не предоставили достаточно информации, чтобы понять причины бага. В какой-то момент я сделал ошибку и пытался выяснить, какой сумасшедший запрос WMI может повесить Gmail на несколько секунд. Я подключил к расследованию некоторых экспертов и потратил кучу времени, пытаясь найти этот волшебный запрос. Я записал активность Microsoft-Windows-WMI-Activity в трассировках ETW, экспериментировал с PowerShell, чтобы найти все запросы Win32_Perf, и заплутал ещё по нескольким окольным путям, которые слишком скучны для обсуждения. В конце концов я обнаружил, что зависание Gmail вызывает такой счётчик Win32_PerfRawData_PerfProc_ProcessAddressSpace_Costly, запускаемый однострочником PowerShell:
Я тогда заплутал ещё больше из-за названия счётчика («дорогой»? в самом деле?) и потому что этот счётчик появляется и исчезает на основе факторов, которые я не понимаю.
Но детали WMI не имеют значения. WMI не делал ничего плохого — не совсем — он просто сканировал память. Написание собственного кода сканирования оказалось гораздо полезнее в расследовании проблемы.
Chrome выпустил патч, остальное за Microsoft.
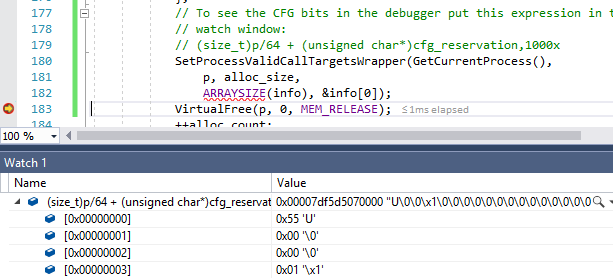
Я обновил примеры кода, особенно VAllocStress. Туда включено 20 строк для демонстрации, как найти резервацию CFG для процесса. Я также добавил тестовый код, который использует SetProcessValidCallTargets для проверки значения битов CFG и демонстрации трюков, необходимых для их успешного вызова (подсказка: вызов через GetProcAddress, вероятно, приведёт к нарушению CFG!)
Речь шла о том, что процесс с поддержкой Control Flow Guard (CFG) выделяет исполняемую память, одновременно выделяя память CFG, которую Windows никогда не освобождает. Поэтому если вы продолжаете выделять и освобождать исполняемую память по разным адресам, то процесс накапливает произвольный объём памяти CFG. Браузер Chrome делает это, что приводит к практически неограниченной утечке памяти и подвисаниям на некоторых машинах.
Нужно заметить, что подвисаний трудно избежать, если VirtualAlloc начинает работать более чем в миллион раз медленнее, чем обычно.
Кроме CFG есть и другая потраченная впустую память, хотя её не так много, как утверждает vmmap.
CFG и страницы
И память программы, и память CFG в конечном счёте выделяются 4-килобайтными страницами (подробнее об этом позже). Поскольку 4 КБ памяти CFG могут описывать 256 КБ памяти программы (подробнее об этом позже), это означает, что если выделить блок памяти 256 КБ, выровненный по 256 КБ, то вы получите одну страницу CFG на 4 КБ. И если выделить блок исполняемой памяти 4 КБ, то вы всё равно получите страницу CFG на 4 КБ, но её бóльшая часть не будет использоваться.
Всё сложнее, если освобождается исполняемая память. Если применить функцию VirtualFree на блоке исполняемой памяти, не кратном 256 КБ или не выровненном по 256 КБ, то ОС должна провести некоторый анализ и проверить, что какая-нибудь другая исполняемая память не использует CFG-страницу. Авторы CFG решили не заморачиваться — и просто навсегда оставляют выделенную память CFG. Весьма прискорбно. Это означает, что когда моя тестовая программа выделяет, а затем освобождает 1 гигабайт выровненной исполняемой памяти, то она оставляет 16 МБ памяти CFG.На практике выходит, что когда JavaScript-движок Chrome выделяет, а затем освобождает 128 МБ выровненной исполняемой памяти (не вся она была использована, но весь диапазон выделен и сразу освобождён), то до 2 МБ памяти CFG останется выделенной, хотя тривиально освободить её целиком. Поскольку Chrome неоднократно выделяет и освобождает память по случайным адресам, то это приводит к вышеописанной проблеме.
Дополнительная потерянная память
В любой современной ОС каждый процесс получает собственное адресное пространство виртуальной памяти, чтобы ОС изолировала процессы и защитила память. Это делается с помощью блока управления памятью (MMU) и таблиц страниц. Память разбита на страницы по 4 КБ. Это минимальный объём памяти, который даёт вам ОС. На каждую страницу указывает восьмибайтовая запись в таблице страниц, а сами записи сохраняются в страницах по 4 КБ. Каждая из них указывает максимум на 512 различных страниц памяти, поэтому нам нужна иерархия таблиц страниц. Для 48-разрядного адресного пространства в 64-битной операционной системе система такая:
- Таблица 1-го уровня охватывает 256 ТБ (48 бит), указывая на 512 различных таблиц страниц 2-го уровня
- Каждая таблица уровня 2 покрывает 512 ГБ, указывая на 512 таблиц уровня 3
- Каждая таблица уровня 3 покрывает 1 ГБ, указывая на 512 таблиц уровня 4
- Каждая таблица уровня 4 охватывает 2 МБ, указывая на 512 физических страниц
MMU индексирует таблицу 1-го уровня в первых 9 (из 48) битах адреса, таблицы 2-го уровня — в следующих 9 битах, и остальным уровням выдаётся по 9 бит, то есть всего 36 бит. Оставшиеся 12 бит используются для индексации 4-килобайтных страниц из таблицы 4-го уровня. Ну и ну.
Если сразу заполнить все уровни таблиц, то потребуется более 512 ГБ оперативной памяти, поэтому они заполняются по мере необходимости. Это означает, что при выделении страницы памяти ОС выделяет некоторые таблицы страниц — от нуля до трёх, в зависимости от того, находятся выделенные адреса в ранее неиспользуемой области 2 МБ, ранее неиспользуемой области 1 ГБ или ранее неиспользуемой области 512 ГБ (таблица страниц уровня 1 выделяется всегда).
Короче говоря, выделения по случайным адресам обходятся значительно дороже, чем выделения близлежащих адресов, так как в первом случае нельзя совместно использовать таблицы страниц. Утечки CFG случаются довольно редко, так что когда vmmap показал 412 480 КБ использованных таблиц страниц в Chrome, я предположил правильность цифр. Вот скриншот vmmap с раскладкой памяти chrome.exe из прошлой статьи, но со строкой Page Table:
Но что-то показалось неправильным. Я решил добавить симулятор таблиц страниц в свой инструмент VirtualScan. Он подсчитывает, сколько страниц таблиц страниц необходимо для всей выделенной памяти в процессе сканирования. Нужно просто просканировать выделенную память, прибавляя к счётчику по единице на каждом числе, кратном 2 МБ, 1 ГБ или 512 ГБ.
Быстро обнаружилось, что результаты симулятора соответствуют vmmap на нормальных процессах, но не на процессах с большим количеством памяти CFG. Разница примерно соответствует выделенной памяти CFG. Для вышеупомянутого процесса, где vmmap говорит о 402,8 МБ (412 480 КБ) таблиц страниц мой инструмент показывает 67,7 МБ.
Scan time, Committed, page tables, committed blocks Total: 41.763s, 1457.7 MiB, 67.7 MiB, 32112, 98 code blocks CFG: 41.759s, 353.3 MiB, 59.2 MiB, 24866
Я убедился в ошибке vmmap, запустив VAllocStress, который в настройках по умолчанию заставляет Windows выделять 2 гигабайта CFG-памяти. vmmap утверждал, что выделил 2 гигабайта таблиц страниц:
И когда я завершил процесс через Диспетчер задач, vmmap показал, что объём выделенной памяти снизился всего на 2 гигабайта. Итак, vmmap ошибается, мои вычисления с таблицами страниц верны, и после плодотворного обсуждения в твиттере я отправил отчёт об ошибке vmmap, которую должны исправить. Память CFG по-прежнему расходует много записей таблиц страниц (59,2 МБ в вышеприведённом примере), но не так много, как говорит vmmap, а после исправления вообще не будет расходовать практически ничего.
Что такое CFG и CFG-память?
Хочу немного отступить назад и более подробно рассказать, что такое CFG.
CFG — сокращение от Control Flow Guard. Это метод защиты от эксплойтов с помощью перезаписи указателей на функции. При включенном CFG компилятор и ОС вместе проверяют валидность целевого объекта ветви. Сначала соответствующий управляющий байт CFG загружается из зарезервированной области CFG в 2 ТБ. 64-разрядный процесс в Windows распоряжается адресным пространством 128 ТБ, поэтому деление адреса на 64 позволяет найти соответствующий байт CFG для этого объекта.
uint8_t cfg_byte = cfg_base[size_t(target_addr) / 64];Теперь у нас есть один байт, который должен описывать, какие адреса в 64-байтовом диапазоне являются допустимыми целями ветвей. Для этого CFG обрабатывает байт как четыре двухбитных значения, каждое из которых соответствует 16-байтовому диапазону. Это двухбитное число (значение которого от нуля до трёх) интерпретируется следующим образом:
- 0 — все цели в этом 16-байтовом блоке являются невалидными целями косвенных веток
- 1 — начальный адрес в этом 16-байтовом блоке является валидной целью косвенной ветви
- 2 — связано с «подавленными» вызовами CFG; адрес потенциально недопустим
- 3 — невыровненные адреса в этом 16-байтовом блоке являются допустимыми целями косвенной ветви, однако 16-байтовый выровненный адрес потенциально недопустим
Если цель косвенной ветви оказывается недопустимой, процесс завершается, и эксплойт предотвращается. Ура!
Из этого можно сделать вывод, что для максимальной безопасности косвенные цели ветви следует выравнивать по 16 байтам, и можно понять, почему объём памяти CFG для процесса примерно равен 1/64 от объёма памяти программы.
Реально CFG загружает по 32 бита за раз, но это детали реализации. Многие источники описывают память CFG как однобитную на 8 байт, а не двухбитную на 16 байт. Моё объяснение лучше.
Вот почему всё плохо
Подвисания Gmail происходят по двум причинам. Во-первых, сканирование CFG-памяти на Windows 10 16299 или более ранних версий мучительно медленно. Я видел, как сканирование адресного пространства процесса занимает 40 или более секунд, и буквально 99,99% этого времени сканируется зарезервированная память CFG, хотя она составляет всего около 75% зафиксированных блоков памяти. Не знаю, почему сканирование происходило так медленно, но в Windows 10 17134 это исправили, так что нет смысла изучать проблему более подробно.
Из-за медленного сканирования возникало подвисание, потому что Gmail хотел получить резервирование CFG, а WMI держал блокировку на время сканирования. Но блокировка резервирования памяти не удерживалась на протяжении всего сканирования. В моём примере в области CFG примерно 49 000 блоков, а функция NtQueryVirtualMemory, которая получает и освобождает блокировку, вызывалась по разу для каждого из них. Поэтому блокировка получалась и освобождалась ~49 000 раз и каждый раз удерживалась менее 1 миллисекунды.
Но хотя блокировка освобождалась 49 000 раз, процесс Chrome по какой-то причине так и не смог её получить. Это несправедливо!
Именно в этом суть проблемы. Как я писал в прошлый раз:
Это потому что блокировки Windows по своей природе несправедливы — и если поток освобождает блокировку, а затем немедленно её запрашивает снова, то может получать её вечно.
Справедливая блокировка означает, что два конкурирующих потока будут получать её по очереди. Но это означает много дорогих переключений контекста, так что на протяжении длительного времени блокировка не будет использоваться.
Несправедливые блокировки дешевле, и они не заставляют потоки ждать в очереди. Они просто захватывают блокировку, как упоминается в статье Джо Даффи. Он также пишет:
Введение несправедливых блокировок, несомненно, может привести к голоду. Но статистически время в параллельных системах имеет тенденцию быть настолько изменчивым, что каждый поток в конечном итоге получит свою очередь для выполнения, с вероятностной точки зрения.
Как же соотнести заявление Джо от 2006 года о редкости голода с моим опытом на 100% повторяемой и длительной проблеме? Думаю, главная причина в том, что произошло в 2006 году. Intel выпустила Core Duo, и многоядерные компьютеры стали повсеместными.
Ведь оказывается, что эта проблема голода происходит только на многоядерной системе! В такой системе поток WMI снимет блокировку, подаст сигнал потоку Chrome о пробуждении и продолжит работу. Поскольку поток WMI уже запущен, у него «фора» перед потоком Chrome, так что он с лёгкостью повторно вызывает NtQueryVirtualMemory и повторно получает блокировку, прежде чем Chrome имеет шансы сделать это.
Очевидно, что в одноядерной системе одновременно может работать только один поток. Как правило, Windows повышает приоритет нового потока, а повышение приоритета означает, что при освобождении блокировки новый поток Chrome будет готов и немедленно опередит поток WMI. Это даёт потоку Chrome много времени, чтобы проснуться и получить блокировку, а голод никогда не наступает.
Понимаете? В многоядерной системе повышение приоритета в большинстве случаев не влияет на поток WMI, так как он будет выполняться на другом ядре!
Это означает, что система с дополнительными ядрами может медленнее реагировать, чем система с той же рабочей нагрузкой и меньшим количеством ядер. Любопытен и другой вывод: если бы у моего компьютера была большая нагрузка — потоки соответствующего приоритета, работающие на всех ядрах процессора, — то подвисаний можно было бы избежать (не пытайтесь повторить это дома).
Таким образом, несправедливые блокировки повышают производительность, но могут привести к голоду. Подозреваю, что решением может быть то, что я называю «иногда справедливыми» блокировками. Скажем, 99% времени они будут несправедливыми, но в 1% отдавать блокировку другому процессу. Это с большего сохранит преимущества производительности, избежав проблемы голода. Раньше блокировки в Windows распределялись справедливо и, вероятно, можно частично вернуться к этому, найдя идеального баланс. Отказ от ответственности: я не эксперт по блокировкам или инженер ОС, но мне интересно услышать мысли об этом, и по крайней мере я не первый, кто предлагает нечто подобное.
Линус Торвальдс недавно оценил важность справедливых блокировок: здесь и здесь. Может быть, пришло время для изменений и в Windows.
Подводя итог: Блокировка на несколько секунд — это нехорошо, она ограничивает параллелизм. Но на многоядерных системах с несправедливыми блокировками снятие, а затем немедленное повторное получение блокировки ведёт себя именно так — у других потоков нет возможности для работы.
Почти провал с ETW
Для всех этих исследований я полагался на трассировку ETW, так что слегка испугался, когда в начале расследования оказалось, что Windows Performance Analyzer (WPA) не мог загрузить символы Chrome. Уверен, буквально на прошлой неделе всё работало. Что же случилось…Случилось то, что вышел Chrome M68, а он скомпонован с помощью lld-link вместо компоновщика VC++. Если запустить dumpbin и посмотреть на отладочную информацию, вы увидите:
C:\b\c\b\win64_clang\src\out\Release_x64\./initialexe/chrome.exe.pdbЛадно, наверное, WPA не нравятся эти слэши. Но всё равно это не имеет смысла, потому что я изменил компоновщик на lld-link, и помню, что тестировал WPA до этого, так что же случилось…
Оказалось, что причина в новой WPA версии 17134. Я протестировал компоновку lld-Link — и она нормально работала в WPA 16299. Как совпало! Новый компоновщик и новая WPA оказались несовместимы.
Я поставил старую версию WPA, чтобы продолжить расследование (xcopy с машины со старой версией) и сообщил о баге lld-link, который разработчики быстро исправили. Теперь можно вернуться к WPA 17134, когда M69 скомпонуют исправленным линкером.
WMI
Триггер зависания WMI является оснасткой управления Windows (Windows Management Instrumentation), а в этом я плохо разбираюсь. Я обнаружил, что в 2014 году или ранее кто-то столкнулся с проблемой значительного использования CPU в WmiPrvSE.exe внутри perfproc!GetProcessVaData, но они не предоставили достаточно информации, чтобы понять причины бага. В какой-то момент я сделал ошибку и пытался выяснить, какой сумасшедший запрос WMI может повесить Gmail на несколько секунд. Я подключил к расследованию некоторых экспертов и потратил кучу времени, пытаясь найти этот волшебный запрос. Я записал активность Microsoft-Windows-WMI-Activity в трассировках ETW, экспериментировал с PowerShell, чтобы найти все запросы Win32_Perf, и заплутал ещё по нескольким окольным путям, которые слишком скучны для обсуждения. В конце концов я обнаружил, что зависание Gmail вызывает такой счётчик Win32_PerfRawData_PerfProc_ProcessAddressSpace_Costly, запускаемый однострочником PowerShell:
measure-command {Get-WmiObject -Query “SELECT * FROM Win32_PerfFormattedData_PerfProc_ProcessAddressSpace_Costly”}
Я тогда заплутал ещё больше из-за названия счётчика («дорогой»? в самом деле?) и потому что этот счётчик появляется и исчезает на основе факторов, которые я не понимаю.
Но детали WMI не имеют значения. WMI не делал ничего плохого — не совсем — он просто сканировал память. Написание собственного кода сканирования оказалось гораздо полезнее в расследовании проблемы.
Хлопоты для Microsoft
Chrome выпустил патч, остальное за Microsoft.
Ускорить сканирование регионов CFG— хорошо, это сделано- Освобождать память CFG, когда освобождается исполняемая память — по крайней мере, в случае выравнивания по 256 КБ, это легко
- Рассмотреть флаг, позволяющий выделять исполняемую память без памяти CFG, или использовать для этой цели PAGE_TARGETS_INVALID. Обратите внимание, что руководство Windows Internals Part 1 7th Edition говорит, что «следует выделять [CFG] страницы только с по крайней мере одним битовым набором {1,X}» — если Windows 10 реализует это, то флаг PAGE_TARGETS_INVALID (который сейчас используется движком v8) позволит избежать выделения памяти
- Исправить расчёт таблиц страниц в vmmap для процессов с большим количеством выделений CFG
Обновления кода
Я обновил примеры кода, особенно VAllocStress. Туда включено 20 строк для демонстрации, как найти резервацию CFG для процесса. Я также добавил тестовый код, который использует SetProcessValidCallTargets для проверки значения битов CFG и демонстрации трюков, необходимых для их успешного вызова (подсказка: вызов через GetProcAddress, вероятно, приведёт к нарушению CFG!)

