Проверить один сервер — не проблема. Берешь чек-лист и по порядку проверяешь: процессор, память, диски. Но с сотней серверов такой способ вряд ли хорошо сработает. Чтобы исключить человеческий фактор, сделать проверки более надежными и быстрыми, надо автоматизировать процесс. Кому знать, как это лучше сделать, как не хостинг-провайдеру. Артём Артемьев на HighLoad++ Siberia рассказал, какие методы можно использовать, что лучше запускать руками, а что отлично получается автоматизировать. Далее текстовая версия доклада с советами, которые сможет повторить каждый, кто работает с железом и нуждается в регулярной проверке его работоспособности.
О спикере: Артём Артемьев (artemirk) технический директор в большом хостинг-провайдере FirstVDS, сам работает с железом.
У FirstVDS есть два дата-центра. Первый — собственный, сами построили свое здание, привезли и поставили свои стойки, сами обслуживают, переживают за ток и охлаждение дата-центра. Второй дата-центр — это большая комната в большом ЦОДе снятая в аренду, с ней все проще, но она тоже есть. Суммарно это 60 стоек и порядка 3000 железных серверов. Было на чем потренироваться и проверить разные подходы, значит нас ждут практически подтвержденные рекомендации. Приступим к просмотру или чтению доклада.
Примерно 6-7 лет назад мы поняли, что просто поставить операционную систему на сервер недостаточно. ОС стоит, сервер бодр и готов к бою. Запускаем его на продакшен — начинаются непонятные перезагрузки и зависания. Что делать, непонятно — процесс идет, перевести целиком рабочий проект на новую железяку — это тяжело, дорого, больно. Куда бежать?
Современные методы деплоя позволяют этого избежать и перевозить сервер за 5 секунд, но наши клиенты (тем более 6 лет назад) точно не летали в облаках, ходили по земле и использовали обычные железяки.

В этой статье я расскажу, какие методы мы пробовали, какие у нас прижились, какие не прижились, какие хорошо запускать руками, и как все это автоматизировать. Дам вам советы, и вы сможете это повторить у себя в компании, если вы работаете с железом и у вас есть такая потребность.
В чем проблема?
По идее, проверить сервер — не проблема. Изначально у нас был процесс, как на картинке ниже. Садится человек, берет чек-лист, проверяет: процессор, память, диски, морщит лоб, принимает решение.
Тогда в месяц устанавливалось 3 сервера. Но, когда серверов становится все больше и больше, этот человек начинает плакать и жаловаться, что он гибнет на работе. Человек все чаще ошибается, потому что проверка превратилась в рутину.
Мы приняли решение: автоматизируем! А человек будет заниматься более полезными вещами.
Небольшая экскурсия
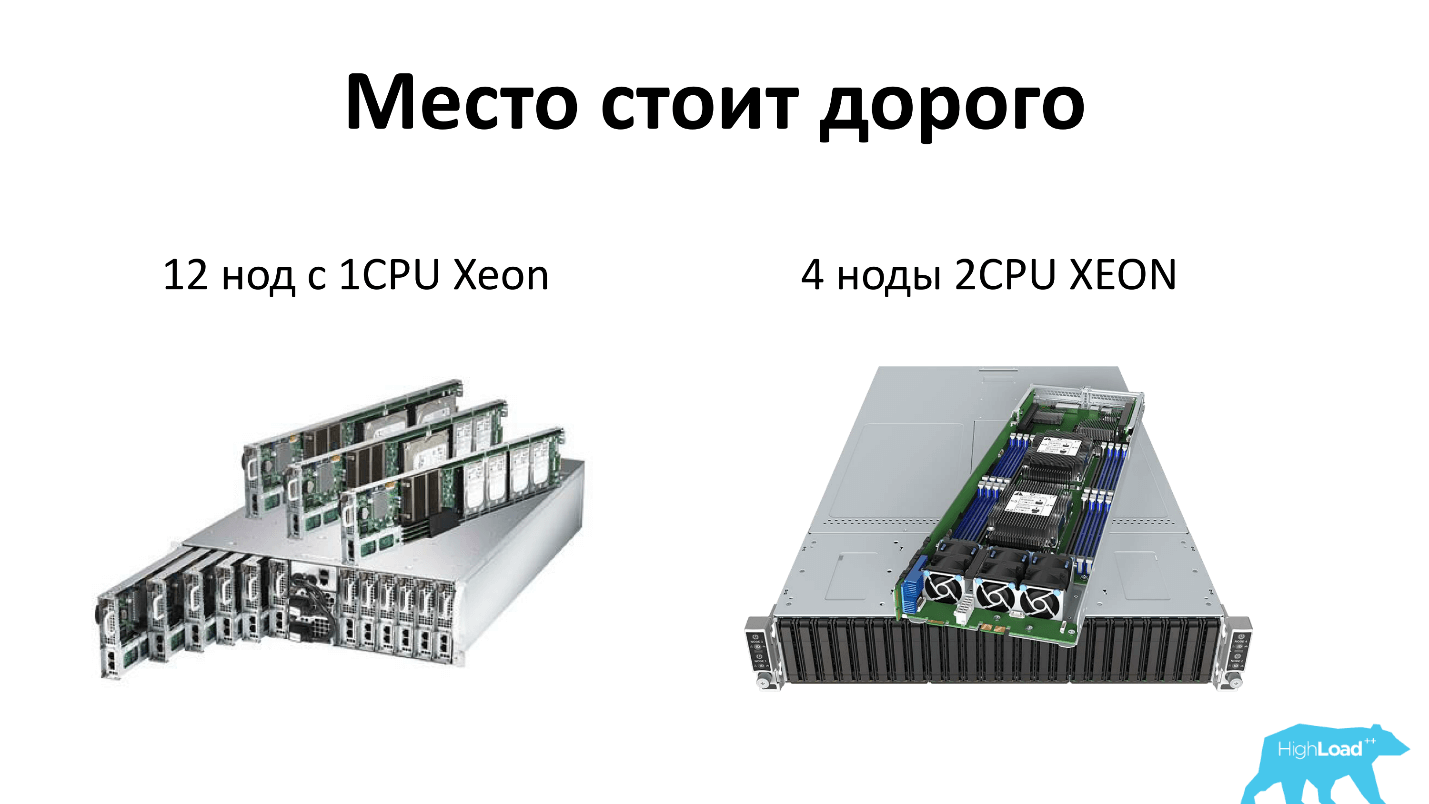
Уточню, что я имею в виду, когда я говорю о сервере сегодня. Мы, как и все, экономим место в стойках и используем серверы высокой плотности. На сегодня это 2 юнита, в которые может поместиться либо 12 узлов однопроцессорных серверов, либо 4 узла двухпроцессорных серверов. То есть каждому серверу достается по 4 диска — всё по-честному. Плюс в стойке два блока питания, то есть всё резервировано и всем нравится.
Откуда железо?
Железо к нам в дата-центр привозят наши поставщики — как правило, это Supermicro и Intel. В дата-центре наши ребята-операторы, устанавливают серверы в свободное место в стойке и подключают два проводка, сеть и питание. Также в обязанности операторов входит настроить BIOS в сервере. То есть подключить клавиатуру, монитор и настроить два параметра:
После этого оператор открывает панель учета железных серверов, в которой нужно зафиксировать факт установки сервера, для чего указывается:
После этого порт сети, куда оператор поставил новый сервер, с целью безопасности переходит в специальный карантинный VLAN, на котором к тому же висит DHCP, Pxe, TFtp. Далее на сервере загружается наш любимый Linux, в котором есть все необходимые утилиты, и запускается процесс диагностики.
Так как у сервера все еще остается первый загрузочный девайс по сети, то у серверов, которые уходят в продакшен, порт переключается на другой VLAN. В другом VLAN нет DHCP, и мы не боимся, что мы свой продакшен-сервер нечаянно переустановим. Для этого у нас предусмотрен отдельный VLAN.
Бывает так, что сервер поставили, все хорошо, но он в систему диагностики так и не загрузился. Случается это, как правило, из-за того, что при задержке переключения VLAN не все сетевые свичи быстро переключают VLAN и т.д.

Тогда оператор получает задачу на перезагрузку сервера руками. Раньше не было IPMI, мы ставили удаленные розетки и фиксировали, в каком порту розетки сервер, дергали розетку по сети, и сервер перезагружался.
Но управляемые розетки тоже работают не всегда хорошо, поэтому сейчас мы управляем питанием серверов по IPMI. Но когда сервер новый, IPMI не настроен, его можно перезагрузить, только подойдя и нажав кнопочку. Поэтому сидит человек, ждет — лампочка загорелась — бежит и жмет кнопку. Такая у него работа.
Если после этого сервер не загрузился, то он заносится в специальный список на починку. В этот список попадают серверы, на которых не запустилась диагностика, или ее результаты оказались не удовлетворительными. Отдельный человек — который любит железо — каждый день сидит и разбирает—собирает, смотрит, почему не работает.
Процессор
Все хорошо, сервер запустился, начинаем тестировать. Первым тестируем процессор, как один из самых важных элементов.

Первым порывом было использовать приложение от вендора. У нас почти все процессоры Intel — зашли на сайт, скачали Intel Processor Diagnostic Tool — все хорошо, показывает много интересной информации, в том числе наработку сервера в часах и график потребления питания.
Но проблема в том, что Intel PTD работает под Windows, что нам уже не понравилось. Чтобы запустить в нем проверку, нужно просто подвести мышку, нажать кнопку «СТАРТ», и начнется проверка. Результат выводится на экран, но нет возможности его куда-либо экспортировать. Это нам не подходит, потому что процесс не автоматизируется.

Пошли читать форумы и нашли два самых простых способа.
Отдаем серверы в продакшен, возвращаются пользователи и говорят, что процессор нестабилен. Проверили — процессор нестабилен. Стали расследовать, взяли сервер, который проверки проходит, но в бою падает, включили в Linux ядре debug, собрали Core dump. Сервер перед перезагрузкой сбрасывает в файлик все, что было в памяти перед падением.

В процессоры встраивают различные оптимизации для частых операций. Мы можем посмотреть флаги отражающие, какие оптимизации процессор поддерживает, например, оптимизации работы с числами с плавающей запятой, оптимизации мультимедиа и т.д. Но наша /bin/stress, и вечный цикл просто прожигают процессор одной операцией и не используют дополнительные возможности. Расследование показало, что CPU падает при попытке использовать функциональность одного из встроенных флагов.
Первым порывом было оставить /bin/stress — пусть греет процессор. Потом в цикле пробежим по всем флагам, дернем их. Пока думали, как это реализовать, какие команды вызвать, чтобы вызвать функции каждого флага, читали форумы.
На форуме оверклокеров наткнулись на интересный проект по поиску простых чисел Great Internet Mersenne Prime Search. Ученые сделали распределенную сеть, к которой каждый может подключиться и помочь найти простое число. Ученые никому не верят, поэтому программка работает очень хитро: сначала ты ее запускаешь, она просчитывает простые числа, которые она уже знает, и сравнивает результат с тем, что ей известно. Если результат не совпадает, то значит процессор работает неправильно. Это свойство нам очень понравилось: при любой ерунде она склонна к падению.
К тому же цель проекта найти как можно больше простых чисел, поэтому программу постоянно оптимизируют под свойства новых процессоров, как следствие она дергает очень много флагов.
Mprime не имеет ограничения по времени, если не остановить — работает вечно. Мы запускаем ее на 30 минут.
После завершения работы проверяем, чтобы в result.txt не было ошибок, и смотрим логи ядра, в частности в файле /proc/kmsg ищем ошибки.
Еще экскурсия

3 января 2018 года нашли 50-е простое число Мерсенна (2p-1). В этом числе всего 23 миллиона цифр. Его можно скачать, чтобы посмотреть, — это zip-архив 12 Мб.
Для чего нам нужны простые числа? Во-первых, любое RSA-шифрование использует простые числа. Чем больше простых чисел мы знаем, тем надежнее ваш SSH ключ. Во-вторых, ученые проверяют свои гипотезы и математические теоремы, а мы не против помогать ученым — нам это ничего не стоит. Получается win-win история.

Итак, процессор работает, все хорошо. Осталось выяснить, что это за процессор. Используем dmidecode -t processor и видим все слоты, которые есть в материнской плате, и какие процессоры стоят в этих слотах. Эта информация поступает в нашу систему учета, интерпретировать ее будем позже.
Улов
Таким образом, на удивление можно найти сломанные ноги. /bin/stress и вечный цикл отработали, а Mprime упал. Долго гоняли, искали, открыли — результат на картинке ниже — тут все понятно.

Такой процессор просто не запустился. Оператор был очень сильный, взял не тот процессор — но поставить смог.

Еще один прекрасный случай. Черный ряд на фотографии ниже — это вентиляторы, стрелка показывает, как дует воздух. Видим: радиатор стоит поперек потока. Конечно, все перегрелось и отключилось.

Память
С памятью все довольно просто. Это ячейки, в которые мы записываем информацию, а через некоторое время снова ее читаем. Если там осталось то же, что мы записали, то данная ячейка исправна.

Всем известна хорошая, прямо классическая, программа Memtest86+, которая запускается с любого носителя, по сети или даже с флоппи-диска. Она сделана для того, чтобы проверить как можно больше ячеек памяти. Любые занятые ячейки проверить уже нельзя. Поэтому memtest86+ имеет минимальный размер чтобы не занимать память. К сожалению, memtest86+ отображает свою статистику только на экран. Мы пытались ее как-то расширить, но все уперлось в то, что внутри программы даже нет сетевого стека. Чтобы ее расширить, нужно было бы с собой притащить Linux-ядро и все остальное.
Есть платная версия этой программы, которая уже умеет скидывать информацию на диск. Но на наших серверах не всегда есть диск, и не всегда есть файловая система на этих дисках. А сетевой диск, как мы уже выяснили, подключить нельзя.
Мы стали копать дальше и нашли похожую программу Memtester. Эта программа работает с уровня ОС из Linux. Самый большой ее минус в том, что сама ОС и Memtester занимают какие-то ячейки памяти, и эти ячейки не будут проверяться.
Memtester запускается командой: memtester `cat /proc/meminfo |grep MemFree | awk ’{print $2-1024}’`k 5
Здесь мы передаем количество свободной памяти минус 1 Мб. Это сделано так, потому что иначе Memtester занимает всю память, и его убивает down killer. Гоняем этот тест 5 циклов, на выходе имеем табличку либо с ОК, либо fail.
Итоговый результат сохраняем и дальше анализируем на предмет провалов.

Для понимания масштабов проблемы — у нас самый маленький сервер имеет 32 Гб памяти, наш образ Linux c Memtester занимает 60 Мб, 2% памяти мы не проверяем. Но по статистике за последние 6 лет такого, что в продакшен попала откровенно битая память, не было. Это тот компромисс, на который мы согласны, и который нам дорого исправить — так и живем с ним.
По пути собираем также dmidecode -t memory, который отдает все банки памяти, которые у нас есть на материнской плате (обычно их до 24 штук), и какие плашки стоят в каждом банке. Эта информация пригодится, если захотим проапгрейдить сервер — будем знать, куда что можно добавить, сколько планок взять и к какому серверу пойти.
Устройства хранения
6 лет назад все диски были с блинами, которые крутились. Отдельная история была собрать просто список всех дисков. Было несколько разных подходов, поскольку не верилось, что можно просто ls /dev/sd посмотреть. Но в итоге остановились, что смотрим ls /dev/sd* и ls /dev/cciss/c0d*. В первом случае это SATA девайс, во втором — SCSI и SAS.

Буквально в этом году начали продавать nvme-диски и добавили сюда nvme list.
После того, как собран список дисков, мы пытаемся с него прочитать 0 байт, чтобы понять, что это блочное устройство и все хорошо. Если не смогли прочитать, то считаем, что это какое-то приведение, и такого диска у нас нет и никогда не было.
Первым подходом к проверке дисков было очевидное: «Давайте на диск запишем случайные данные и посмотрим скорость» —
Но снова стали возвращаться пользователи и говорить, что диски плохие. Выяснилось, что коварная физика с нами опять пошутила.

Есть угловая скорость, и, как правило, когда запускаешь -dd, он пишет возле шпинделя. Если по каким-то причинам скорость шпинделя деградировала, то это менее заметно, чем если писать с краю диска.
Пришлось поменять принцип проверки. Теперь мы проверяем в трех местах: возле шпинделя, посерединке и снаружи. Наверное, можно проверять только снаружи, но так уж у нас исторически сложилось. А, что работает, не трогаем.
Можно использовать smartctl, чтобы спросить у диска, как у него дела. Мы считаем, что у хорошего диска:

Распространившиеся SSD — вообще прекрасные диски, работают быстро, не шумят, не греются. Мы считаем, что хороший SSD имеет скорость записи больше 200 Мбайт/с. Наши клиенты любят невысокие цены, и к нам не всегда попадают серверные модели, которые выдают 320-350 Mбайт/с.
Для SSD мы так же смотрим smartctl. Те же Reallocated, Power_On_Hours, Current_Pending_Sector. Все SSD-диски умеют отображать степень износа, ее показывает параметр Media_Wearout_Indicator. Мы истираем диски до 5% жизни, и только потом вынимаем. Такие диски иногда находят вторую жизнь в личных нуждах сотрудников. Например, недавно я узнал, что за 2 года такой диск истерся еще на 1% в ноутбуке сотрудника, хотя у нас он под SSD-кэшем примерно за 10 месяцев истирает 95%.
Но проблема в том, что не все производители дисков договорились о названиях параметра, и этот Media_Wearout_Indicator, например, у Toshiba называется Percent_Lifetime_Used, у других производителей Wear Leveling Count, Percent Lifetime Remaining, либо просто .*wear.*.
У Crucial вообще нет этого параметра. Тогда мы просто считаем объем перезаписи диска — «byte writed» — сколько байт мы на этот диск уже записали. Далее по спецификации пытаемся выяснить на сколько перезаписей этот диск рассчитан производителем. Элементарной математикой определяем, сколько он еще проживет. Если пора менять — меняем.
RAID
Я не знаю, почему в современном мире наши клиенты все еще хотят RAID’ы. Люди покупают RAID, ставят туда 4 SSD, которые сильно быстрее этого RAID’а (6 Гбит). У них есть какая-то инструкция, и они по ней собирают. Я считаю, что это почти ненужная штука.
Раньше было 3 производителя: Adaptec; 3ware; Intel. У нас было 3 утилиты, мы заморачивались, но проводили диагностику для всех. Сейчас LSI купил всех — осталась одна утилита.
Когда наша система диагностики видит RAID, она разбирает логический том на отдельные диски, чтобы можно было померить скорость каждого диска, почитать его Smart. После этого остается у RAID проверить батарейку. Кто не знает — батарейки на RAID хватает, чтобы все диски еще 2 часа покрутить. То есть ты выключаешь сервер, вынимаешь, а он еще 2 часа вращает диск, чтобы завершить все записи.
Сеть
С сетью у нас все довольно просто — внутри дата-центра должно быть на меньше 300 Мбит. Если меньше, то надо чинить. Также смотрим ошибки на интерфейсе. Ошибок на сетевом интерфейсе быть не должно совсем, и если они есть, то все плохо.
По пути стараемся обновить BIOS и IPMI firmware. Оказалось, что мы не все BIOS’ы любим. У нас еще есть BIOS’ы, которые не умеют UEFI и другие фичи, которые мы используем. Стараемся обновить его автоматически, но это не всегда получается, там все не очень просто. Если не получается, то человек идет и руками обновляет.
IPMI Supermicro мы не отдаем в мир, у нас он на серых адресах через OpenVPN. Тем не менее мы опасаемся, что однажды вылезут очередные уязвимости и мы пострадаем. Поэтому стараемся, чтобы просто прошивка IPMI была всегда последняя. Если это не так, то обновляем.
Из странного недавно вылезло что Intel на 10 и 40-гигабитных сетевых картах не включает PXE загрузку. Оказывается, если сервер находится в стойке, в которой есть только 40-гигабитная карта, то невозможно загрузиться по сети, потому что надо грузиться в гигабитную карточку. Мы отдельно прошиваем сетевые карты на 40G, чтобы у них появилось PXE и можно было дальше жить.
После того, как всё проверено, сервер сразу уходит на продажу. Вычисляется его цена, по которой он выставляется на сайт и продается.
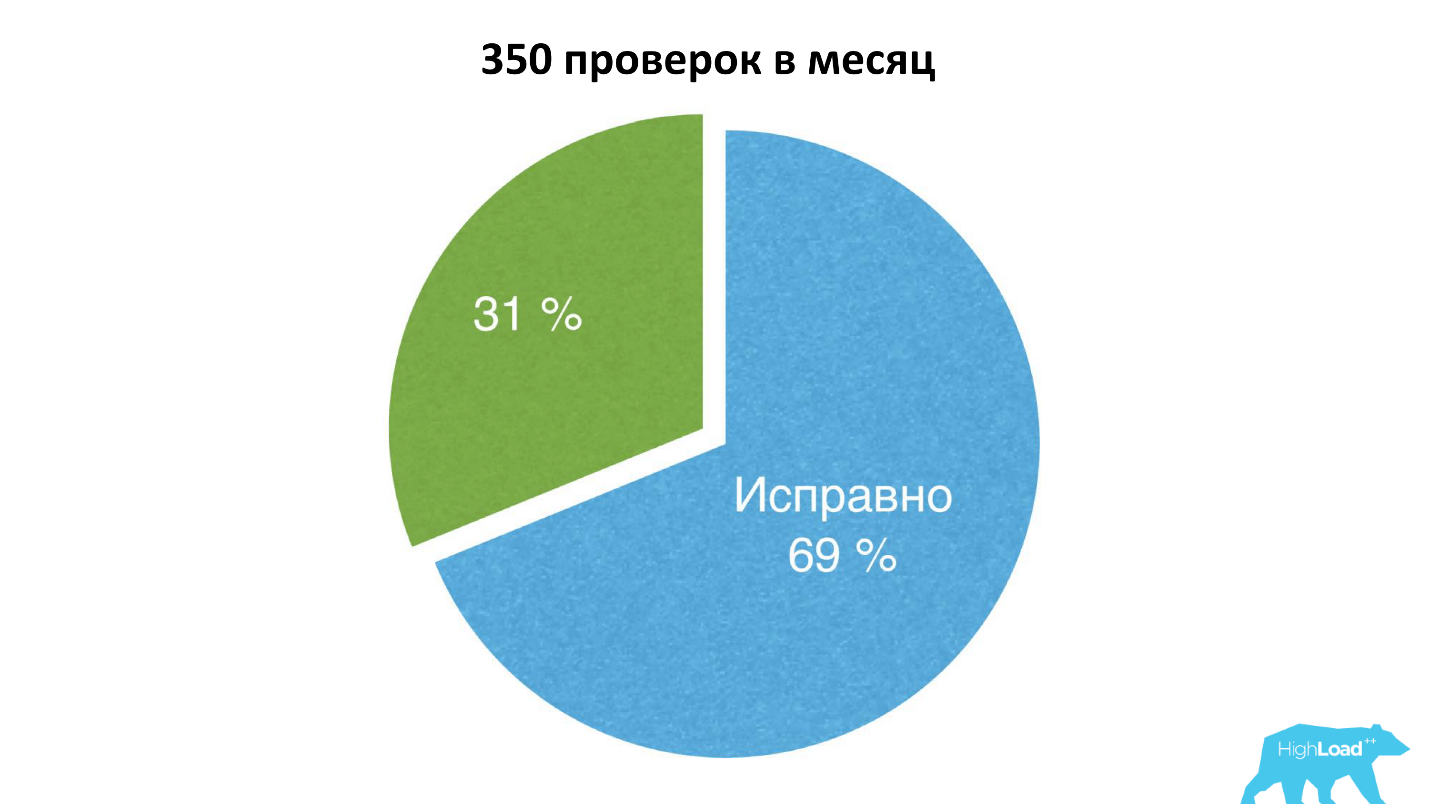
Итого у нас проводится примерно 350 проверок в месяц, 69% серверов исправны, 31% — не исправны. Это связано с тем, что у нас богатая история, некоторые серверы стоят уже по 10 лет. Большинство серверов, которые не прошли проверку, мы просто выкидываем.
Будущее пришло! Если бы я городил эту систему сегодня…

Вышла прекрасная утилита Hardware Lister (lshw), которая умеет общаться с ядром, красиво отображать, какое железо есть в ядре, что ядро смогло определить. Не нужны все эти пляски. Если будете повторять — настойчиво советую посмотреть на эту утилиту и использовать ее. Все станет сильно проще.
Итоги:
О спикере: Артём Артемьев (artemirk) технический директор в большом хостинг-провайдере FirstVDS, сам работает с железом.
У FirstVDS есть два дата-центра. Первый — собственный, сами построили свое здание, привезли и поставили свои стойки, сами обслуживают, переживают за ток и охлаждение дата-центра. Второй дата-центр — это большая комната в большом ЦОДе снятая в аренду, с ней все проще, но она тоже есть. Суммарно это 60 стоек и порядка 3000 железных серверов. Было на чем потренироваться и проверить разные подходы, значит нас ждут практически подтвержденные рекомендации. Приступим к просмотру или чтению доклада.
Примерно 6-7 лет назад мы поняли, что просто поставить операционную систему на сервер недостаточно. ОС стоит, сервер бодр и готов к бою. Запускаем его на продакшен — начинаются непонятные перезагрузки и зависания. Что делать, непонятно — процесс идет, перевести целиком рабочий проект на новую железяку — это тяжело, дорого, больно. Куда бежать?
Современные методы деплоя позволяют этого избежать и перевозить сервер за 5 секунд, но наши клиенты (тем более 6 лет назад) точно не летали в облаках, ходили по земле и использовали обычные железяки.
В этой статье я расскажу, какие методы мы пробовали, какие у нас прижились, какие не прижились, какие хорошо запускать руками, и как все это автоматизировать. Дам вам советы, и вы сможете это повторить у себя в компании, если вы работаете с железом и у вас есть такая потребность.
В чем проблема?
По идее, проверить сервер — не проблема. Изначально у нас был процесс, как на картинке ниже. Садится человек, берет чек-лист, проверяет: процессор, память, диски, морщит лоб, принимает решение.
Тогда в месяц устанавливалось 3 сервера. Но, когда серверов становится все больше и больше, этот человек начинает плакать и жаловаться, что он гибнет на работе. Человек все чаще ошибается, потому что проверка превратилась в рутину.
Мы приняли решение: автоматизируем! А человек будет заниматься более полезными вещами.
Небольшая экскурсия
Уточню, что я имею в виду, когда я говорю о сервере сегодня. Мы, как и все, экономим место в стойках и используем серверы высокой плотности. На сегодня это 2 юнита, в которые может поместиться либо 12 узлов однопроцессорных серверов, либо 4 узла двухпроцессорных серверов. То есть каждому серверу достается по 4 диска — всё по-честному. Плюс в стойке два блока питания, то есть всё резервировано и всем нравится.
Откуда железо?
Железо к нам в дата-центр привозят наши поставщики — как правило, это Supermicro и Intel. В дата-центре наши ребята-операторы, устанавливают серверы в свободное место в стойке и подключают два проводка, сеть и питание. Также в обязанности операторов входит настроить BIOS в сервере. То есть подключить клавиатуру, монитор и настроить два параметра:
Restore on AC/Power Loss — [Power On], чтобы сервер включался всегда, как только появляется питание. Он должен работать без остановок. Второе First boot device — [PXE], то есть первый загрузочный девайс мы ставим в сеть, иначе не сможем достучаться до сервера, так как не факт, что в нем есть сразу диски и т.д.После этого оператор открывает панель учета железных серверов, в которой нужно зафиксировать факт установки сервера, для чего указывается:
- стойка;
- наклейка;
- порты сети;
- порты питания;
- номер юнита.
После этого порт сети, куда оператор поставил новый сервер, с целью безопасности переходит в специальный карантинный VLAN, на котором к тому же висит DHCP, Pxe, TFtp. Далее на сервере загружается наш любимый Linux, в котором есть все необходимые утилиты, и запускается процесс диагностики.
Так как у сервера все еще остается первый загрузочный девайс по сети, то у серверов, которые уходят в продакшен, порт переключается на другой VLAN. В другом VLAN нет DHCP, и мы не боимся, что мы свой продакшен-сервер нечаянно переустановим. Для этого у нас предусмотрен отдельный VLAN.
Бывает так, что сервер поставили, все хорошо, но он в систему диагностики так и не загрузился. Случается это, как правило, из-за того, что при задержке переключения VLAN не все сетевые свичи быстро переключают VLAN и т.д.
Тогда оператор получает задачу на перезагрузку сервера руками. Раньше не было IPMI, мы ставили удаленные розетки и фиксировали, в каком порту розетки сервер, дергали розетку по сети, и сервер перезагружался.
Но управляемые розетки тоже работают не всегда хорошо, поэтому сейчас мы управляем питанием серверов по IPMI. Но когда сервер новый, IPMI не настроен, его можно перезагрузить, только подойдя и нажав кнопочку. Поэтому сидит человек, ждет — лампочка загорелась — бежит и жмет кнопку. Такая у него работа.
Если после этого сервер не загрузился, то он заносится в специальный список на починку. В этот список попадают серверы, на которых не запустилась диагностика, или ее результаты оказались не удовлетворительными. Отдельный человек — который любит железо — каждый день сидит и разбирает—собирает, смотрит, почему не работает.
Процессор
Все хорошо, сервер запустился, начинаем тестировать. Первым тестируем процессор, как один из самых важных элементов.
Первым порывом было использовать приложение от вендора. У нас почти все процессоры Intel — зашли на сайт, скачали Intel Processor Diagnostic Tool — все хорошо, показывает много интересной информации, в том числе наработку сервера в часах и график потребления питания.
Но проблема в том, что Intel PTD работает под Windows, что нам уже не понравилось. Чтобы запустить в нем проверку, нужно просто подвести мышку, нажать кнопку «СТАРТ», и начнется проверка. Результат выводится на экран, но нет возможности его куда-либо экспортировать. Это нам не подходит, потому что процесс не автоматизируется.
Пошли читать форумы и нашли два самых простых способа.
- Вечный цикл cat/dev/zero > /dev/null. Можно проверить в top — 100% одно ядро потребляется. Считаем количество ядер, запускаем нужное количество cat/dev/zero, умножаемое на нужное количество ядер. Все отлично работает!
- Утилита /bin/stress. Она строит матрицы в памяти и начинает их постоянно переворачивать. Тоже все хорошо — процессор греется, нагрузка есть.
Отдаем серверы в продакшен, возвращаются пользователи и говорят, что процессор нестабилен. Проверили — процессор нестабилен. Стали расследовать, взяли сервер, который проверки проходит, но в бою падает, включили в Linux ядре debug, собрали Core dump. Сервер перед перезагрузкой сбрасывает в файлик все, что было в памяти перед падением.
В процессоры встраивают различные оптимизации для частых операций. Мы можем посмотреть флаги отражающие, какие оптимизации процессор поддерживает, например, оптимизации работы с числами с плавающей запятой, оптимизации мультимедиа и т.д. Но наша /bin/stress, и вечный цикл просто прожигают процессор одной операцией и не используют дополнительные возможности. Расследование показало, что CPU падает при попытке использовать функциональность одного из встроенных флагов.
Первым порывом было оставить /bin/stress — пусть греет процессор. Потом в цикле пробежим по всем флагам, дернем их. Пока думали, как это реализовать, какие команды вызвать, чтобы вызвать функции каждого флага, читали форумы.
На форуме оверклокеров наткнулись на интересный проект по поиску простых чисел Great Internet Mersenne Prime Search. Ученые сделали распределенную сеть, к которой каждый может подключиться и помочь найти простое число. Ученые никому не верят, поэтому программка работает очень хитро: сначала ты ее запускаешь, она просчитывает простые числа, которые она уже знает, и сравнивает результат с тем, что ей известно. Если результат не совпадает, то значит процессор работает неправильно. Это свойство нам очень понравилось: при любой ерунде она склонна к падению.
К тому же цель проекта найти как можно больше простых чисел, поэтому программу постоянно оптимизируют под свойства новых процессоров, как следствие она дергает очень много флагов.
Mprime не имеет ограничения по времени, если не остановить — работает вечно. Мы запускаем ее на 30 минут.
/usr/bin/timeout 30m /opt/mprime -t /bin/grep -i error /root/result.txt
После завершения работы проверяем, чтобы в result.txt не было ошибок, и смотрим логи ядра, в частности в файле /proc/kmsg ищем ошибки.
Еще экскурсия
3 января 2018 года нашли 50-е простое число Мерсенна (2p-1). В этом числе всего 23 миллиона цифр. Его можно скачать, чтобы посмотреть, — это zip-архив 12 Мб.
Для чего нам нужны простые числа? Во-первых, любое RSA-шифрование использует простые числа. Чем больше простых чисел мы знаем, тем надежнее ваш SSH ключ. Во-вторых, ученые проверяют свои гипотезы и математические теоремы, а мы не против помогать ученым — нам это ничего не стоит. Получается win-win история.
Итак, процессор работает, все хорошо. Осталось выяснить, что это за процессор. Используем dmidecode -t processor и видим все слоты, которые есть в материнской плате, и какие процессоры стоят в этих слотах. Эта информация поступает в нашу систему учета, интерпретировать ее будем позже.
Улов
Таким образом, на удивление можно найти сломанные ноги. /bin/stress и вечный цикл отработали, а Mprime упал. Долго гоняли, искали, открыли — результат на картинке ниже — тут все понятно.
Такой процессор просто не запустился. Оператор был очень сильный, взял не тот процессор — но поставить смог.
Еще один прекрасный случай. Черный ряд на фотографии ниже — это вентиляторы, стрелка показывает, как дует воздух. Видим: радиатор стоит поперек потока. Конечно, все перегрелось и отключилось.
Память
С памятью все довольно просто. Это ячейки, в которые мы записываем информацию, а через некоторое время снова ее читаем. Если там осталось то же, что мы записали, то данная ячейка исправна.
Всем известна хорошая, прямо классическая, программа Memtest86+, которая запускается с любого носителя, по сети или даже с флоппи-диска. Она сделана для того, чтобы проверить как можно больше ячеек памяти. Любые занятые ячейки проверить уже нельзя. Поэтому memtest86+ имеет минимальный размер чтобы не занимать память. К сожалению, memtest86+ отображает свою статистику только на экран. Мы пытались ее как-то расширить, но все уперлось в то, что внутри программы даже нет сетевого стека. Чтобы ее расширить, нужно было бы с собой притащить Linux-ядро и все остальное.
Есть платная версия этой программы, которая уже умеет скидывать информацию на диск. Но на наших серверах не всегда есть диск, и не всегда есть файловая система на этих дисках. А сетевой диск, как мы уже выяснили, подключить нельзя.
Мы стали копать дальше и нашли похожую программу Memtester. Эта программа работает с уровня ОС из Linux. Самый большой ее минус в том, что сама ОС и Memtester занимают какие-то ячейки памяти, и эти ячейки не будут проверяться.
Memtester запускается командой: memtester `cat /proc/meminfo |grep MemFree | awk ’{print $2-1024}’`k 5
Здесь мы передаем количество свободной памяти минус 1 Мб. Это сделано так, потому что иначе Memtester занимает всю память, и его убивает down killer. Гоняем этот тест 5 циклов, на выходе имеем табличку либо с ОК, либо fail.
| Stuck Address | ok |
| Random Value | ok |
| Compare XOR | ok |
| Compare SUB | ok |
| Compare MUL | ok |
| Compare DIV | ok |
| Compare OR | ok |
| Compare AND | ok |
Итоговый результат сохраняем и дальше анализируем на предмет провалов.
Для понимания масштабов проблемы — у нас самый маленький сервер имеет 32 Гб памяти, наш образ Linux c Memtester занимает 60 Мб, 2% памяти мы не проверяем. Но по статистике за последние 6 лет такого, что в продакшен попала откровенно битая память, не было. Это тот компромисс, на который мы согласны, и который нам дорого исправить — так и живем с ним.
По пути собираем также dmidecode -t memory, который отдает все банки памяти, которые у нас есть на материнской плате (обычно их до 24 штук), и какие плашки стоят в каждом банке. Эта информация пригодится, если захотим проапгрейдить сервер — будем знать, куда что можно добавить, сколько планок взять и к какому серверу пойти.
Устройства хранения
6 лет назад все диски были с блинами, которые крутились. Отдельная история была собрать просто список всех дисков. Было несколько разных подходов, поскольку не верилось, что можно просто ls /dev/sd посмотреть. Но в итоге остановились, что смотрим ls /dev/sd* и ls /dev/cciss/c0d*. В первом случае это SATA девайс, во втором — SCSI и SAS.
Буквально в этом году начали продавать nvme-диски и добавили сюда nvme list.
После того, как собран список дисков, мы пытаемся с него прочитать 0 байт, чтобы понять, что это блочное устройство и все хорошо. Если не смогли прочитать, то считаем, что это какое-то приведение, и такого диска у нас нет и никогда не было.
Первым подходом к проверке дисков было очевидное: «Давайте на диск запишем случайные данные и посмотрим скорость» —
dd -o nocache -o direct if=/dev/urandom of=${disk}. Как правило, блиновые диски выдают 130-150 Мбайт/с. Мы, прищурив глаз, для себя решили, что 90 Мбайт/с — это та цифра, после которой идут исправные диски, все, что меньше — неисправные.Но снова стали возвращаться пользователи и говорить, что диски плохие. Выяснилось, что коварная физика с нами опять пошутила.
Есть угловая скорость, и, как правило, когда запускаешь -dd, он пишет возле шпинделя. Если по каким-то причинам скорость шпинделя деградировала, то это менее заметно, чем если писать с краю диска.
Пришлось поменять принцип проверки. Теперь мы проверяем в трех местах: возле шпинделя, посерединке и снаружи. Наверное, можно проверять только снаружи, но так уж у нас исторически сложилось. А, что работает, не трогаем.
Можно использовать smartctl, чтобы спросить у диска, как у него дела. Мы считаем, что у хорошего диска:
- Нет Reallocated секторов (Reallocated Sectors Count = 0), то есть все секторы, что вышли с завода, работают.
- Мы не используем диски старше 4 лет, хотя они вполне рабочие. До того, как мы ввели эту практику, у нас были диски и по 7 лет. Сейчас мы считаем, что после 4 лет диск окупился, и мы не готовы принимать риск износа.
- Нет секторов, которые собираются быть Reallocated ( Current_Pending_Sector = 0).
- UltraDMA CRC Error Count = 0 — это ошибки на SATA-шлейфе. Если ошибка есть, надо просто поменять провод, менять диск не нужно.
Распространившиеся SSD — вообще прекрасные диски, работают быстро, не шумят, не греются. Мы считаем, что хороший SSD имеет скорость записи больше 200 Мбайт/с. Наши клиенты любят невысокие цены, и к нам не всегда попадают серверные модели, которые выдают 320-350 Mбайт/с.
Для SSD мы так же смотрим smartctl. Те же Reallocated, Power_On_Hours, Current_Pending_Sector. Все SSD-диски умеют отображать степень износа, ее показывает параметр Media_Wearout_Indicator. Мы истираем диски до 5% жизни, и только потом вынимаем. Такие диски иногда находят вторую жизнь в личных нуждах сотрудников. Например, недавно я узнал, что за 2 года такой диск истерся еще на 1% в ноутбуке сотрудника, хотя у нас он под SSD-кэшем примерно за 10 месяцев истирает 95%.
Но проблема в том, что не все производители дисков договорились о названиях параметра, и этот Media_Wearout_Indicator, например, у Toshiba называется Percent_Lifetime_Used, у других производителей Wear Leveling Count, Percent Lifetime Remaining, либо просто .*wear.*.
У Crucial вообще нет этого параметра. Тогда мы просто считаем объем перезаписи диска — «byte writed» — сколько байт мы на этот диск уже записали. Далее по спецификации пытаемся выяснить на сколько перезаписей этот диск рассчитан производителем. Элементарной математикой определяем, сколько он еще проживет. Если пора менять — меняем.
RAID
Я не знаю, почему в современном мире наши клиенты все еще хотят RAID’ы. Люди покупают RAID, ставят туда 4 SSD, которые сильно быстрее этого RAID’а (6 Гбит). У них есть какая-то инструкция, и они по ней собирают. Я считаю, что это почти ненужная штука.
Раньше было 3 производителя: Adaptec; 3ware; Intel. У нас было 3 утилиты, мы заморачивались, но проводили диагностику для всех. Сейчас LSI купил всех — осталась одна утилита.
Когда наша система диагностики видит RAID, она разбирает логический том на отдельные диски, чтобы можно было померить скорость каждого диска, почитать его Smart. После этого остается у RAID проверить батарейку. Кто не знает — батарейки на RAID хватает, чтобы все диски еще 2 часа покрутить. То есть ты выключаешь сервер, вынимаешь, а он еще 2 часа вращает диск, чтобы завершить все записи.
Сеть
С сетью у нас все довольно просто — внутри дата-центра должно быть на меньше 300 Мбит. Если меньше, то надо чинить. Также смотрим ошибки на интерфейсе. Ошибок на сетевом интерфейсе быть не должно совсем, и если они есть, то все плохо.
По пути стараемся обновить BIOS и IPMI firmware. Оказалось, что мы не все BIOS’ы любим. У нас еще есть BIOS’ы, которые не умеют UEFI и другие фичи, которые мы используем. Стараемся обновить его автоматически, но это не всегда получается, там все не очень просто. Если не получается, то человек идет и руками обновляет.
IPMI Supermicro мы не отдаем в мир, у нас он на серых адресах через OpenVPN. Тем не менее мы опасаемся, что однажды вылезут очередные уязвимости и мы пострадаем. Поэтому стараемся, чтобы просто прошивка IPMI была всегда последняя. Если это не так, то обновляем.
Из странного недавно вылезло что Intel на 10 и 40-гигабитных сетевых картах не включает PXE загрузку. Оказывается, если сервер находится в стойке, в которой есть только 40-гигабитная карта, то невозможно загрузиться по сети, потому что надо грузиться в гигабитную карточку. Мы отдельно прошиваем сетевые карты на 40G, чтобы у них появилось PXE и можно было дальше жить.
После того, как всё проверено, сервер сразу уходит на продажу. Вычисляется его цена, по которой он выставляется на сайт и продается.
Итого у нас проводится примерно 350 проверок в месяц, 69% серверов исправны, 31% — не исправны. Это связано с тем, что у нас богатая история, некоторые серверы стоят уже по 10 лет. Большинство серверов, которые не прошли проверку, мы просто выкидываем.
Для любознательных: у нас есть 3 клиента, которые все еще живут на Pentium IV, и не хотят никуда уезжать. Им хватает 512 Мб оперативной памяти.
Будущее пришло! Если бы я городил эту систему сегодня…
Вышла прекрасная утилита Hardware Lister (lshw), которая умеет общаться с ядром, красиво отображать, какое железо есть в ядре, что ядро смогло определить. Не нужны все эти пляски. Если будете повторять — настойчиво советую посмотреть на эту утилиту и использовать ее. Все станет сильно проще.
Итоги:
- Компромиссы — это не плохо, это всего лишь вопрос цены. Если решение очень дорогое, надо искать уровень, когда и надежность, и цена приемлемая.
- Непрофильные программы порой классно подходят для тестирования. Остается их только найти.
- Тестируйте все, до чего дотянетесь!
Следующий большой HighLoad++ уже 8 и 9 ноября в Москве. В программе известные специалисты и новые имена, традиционные и новые задачи. В секции DevOps, например, уже приняты:
- David O’Brien (Xirus), который будет обсуждать вечное — «Metrics! Metrics! Metrics!»
- Владимир Колобаев (Avito) с докладом-призывом «Мониторинг — разработчикам! Технологии — сообществу! Профит — всем!»
- Елена Граховац (N26) представит «Лучшие практики нативных облачных сервисов».
Изучайте список докладов и спешите присоединиться. Или подпишитесь на нашу рассылку, и будете регулярно получать обзоры докладов, сообщения о новых статьях и видео.

