Все началось с того, что мы столкнулись с потребностью быстро и правильно формировать структуры EDWEX, JSON, DDL и затем раскатывать их на разных контурах реляционных БД. Под контурами я подразумеваю знакомые всем аббревиатуры — DEV, TST, UAT, PRD.

На тот момент мы делали практически все вручную: и генерировали DDL, и собирали edwex-ы и json-ы на основе метаданных из Oracle БД. Входных параметров множество. Упустишь один — и некорректно сформируешь сущность. А так как весь процесс формирования был последовательным и непрерывным, то ошибка обнаружится только в самом конце. О том, как мы все автоматизировали и побороли ошибки, читайте под катом.
Перед тем, как залить данные в таблицы реляционных БД, нам необходимо принять их из источника — в любом формате, например в Excel. Данные из источника с помощью in-house механизма транспортируются в Hadoop (Data Lake). На Hadoop установлена надстройка Hive — с ее помощью мы можем просматривать содержимое файлов с помощью SQL-подобного синтаксиса.
Чтобы переложить данные в Data Lake в виде таблиц, нам необходимы json’ы, которые формируются на основе метаданных. Чтобы распарсить данные в формате Excel, нам необходимо сформировать EDWEX файлы. EDWEX (EDW_EXTRACTOR) файлы представляют собой некий набор артефактов, в которых содержатся наборы таблиц с наименованием, а также наборы полей для каждой из этих таблиц, формирующихся на основе метаданных. В зависимости от версии моделей и ID источника набор полей различается. Формирование DDL необходимо для создания самих таблиц в БД Hive на уровне оперативных данных и в БД Greenplum на уровне детальных и агрегированных данных. То есть первично данные попадают в Hive, при необходимости фильтруются и перекладываются в Greenplum для последующих манипуляций с данными и создания витрин на их основе.
Для решения задачи мы использовали:
Начнем с того, что изначально мы работаем с большим количеством источников, поэтому с помощью Shell script в качестве параметра запуска передаем ID источников SQL-функциям для их идентификации. Полученные SQL-функции впоследствии будут автоматически выполнены в базе метаданных. На основе имеющихся метаданных эти функции формируют файл со списком новых SQL-функций для каждой из таблиц источника, чтобы мы их могли впоследствии вызвать в исполняемой программе. Результат выполнения сформированных функций — это передача в output-параметр значений DDL, JSON или EDWEX.
Здесь подключается Python, на котором написана вся исполняемая функциональность и unit-тесты. Перед запуском какого-либо из модулей раскатки артефактов с помощью unit-тестов проверяется корректная передача параметров для запуска python-скриптов. Тесты не только проверяют корректность параметров на входе, но и их наличие в модуле метаданных, размеры созданных файлов и даты их создания. Тесты также мониторят количество созданных новых артефактов и количество уже существующих артефактов. Так мы оптимизируем использование серверных ресурсов, поскольку берем для раскатки только новые файлы и не инсталлируем уже существующие модели заново.
И только после успешного прохождения всех проверок выполняется python-программа, которая создает необходимые артефакты и раскладывает полученный результат по необходимым папкам проектов на сервере. Python не только разбивает по каталогам сгенерированные json-файлы, но и формирует по ним структуры в Data Lake, чтобы данные загружались корректно. При формировании DDL-артефактов, они не только сохраняются для последующего анализа и переиспользования, но и сразу же могут быть инсталлированы в БД по новым моделям и структурам, указанным в модуле метаданных. Это позволяет создавать сотни таблиц за короткое время без привлечения ручного труда.
Jenkins вступает, когда необходимо управлять всеми этими процессами наглядно при помощи интерфейса.
Данный инструмент был выбран, потому как он:
Для решения поставленных задач мы создали несколько multijob проектов. Такой тип проектов был использован, так как он может работать параллельно с другими джобами при единовременном запуске. Каждый из джобов отвечает за реализацию своего блока функциональности. Так мы заменили последовательный процесс получения артефактов на автономные параллельные. Все запускается раздельно: формирование EDWEX, JSON, DDL, формирование структуры в HIVE, инсталляция структур таблиц в БД. Мы анализируем полученный результат на разных этапах формирования артефактов и приступаем к запуску последующих действий в случае успеха.
Jenkins-часть реализована без особых ухищрений. На вход джобам подаются String или Run параметры для запуска python-кода. String параметр представляет из себя окно для ввода значения с типом str перед запуском. Run параметр может передаваться на лету другому джобу для исполнения, для этого достаточно всего лишь указать из какого проекта необходимо забрать полученную переменную. Также отдельным параметром передается нода для выполнения. Здесь как раз реализовано разбиение по средам выполнения на DEV, TST, UAT, PRD. Отдельным джобом выполнена передача полученных EDWEX файлов в SVN с номером ревизии для возможности отслеживания версий измененных структур.
Пример интерфейса в Jenkins:

Результат выполнения джобов — это создание и инсталляция необходимых артефактов, передача их в SVN и формирование HTML-отчета, который отображает успешность прохождения unit-тестов и результаты выполнения сборки и инсталляции артефактов. Джобы можно запускать как руками по отдельности, так и в автоматическом режиме, предварительно выстроив цепочку исполнения.
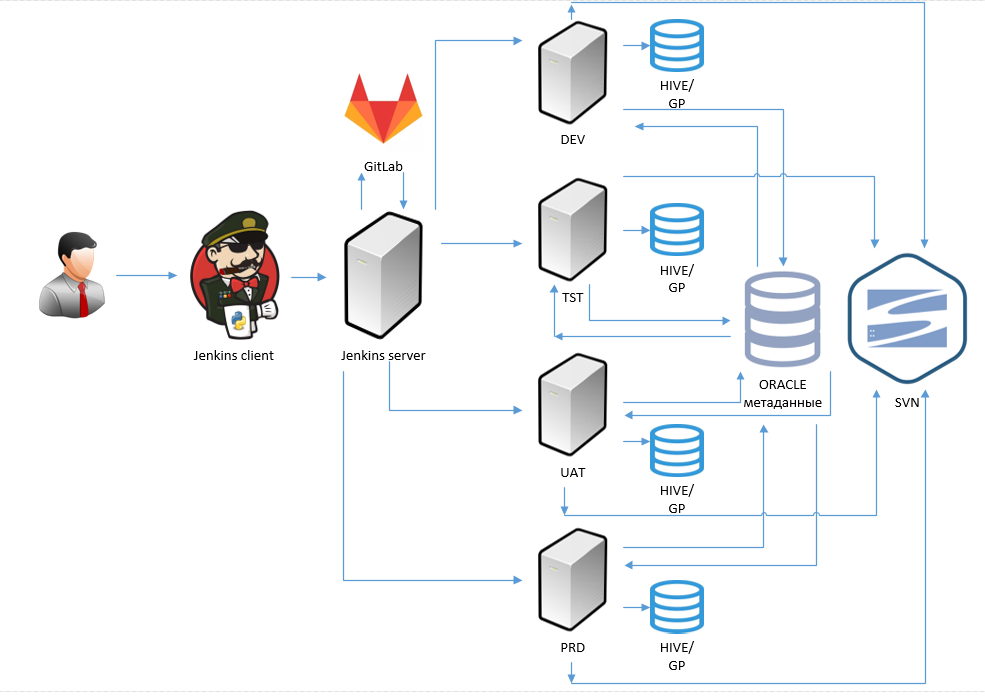
Архитектура механизма сборки и инсталляции
Была проделана большая работа по автоматизации формирования артефактов. Раньше нужно было вручную залезть на сервер, запустить shell скрипты, а затем долго изучать и править данные руками. Теперь достаточно нажать всего на кнопку запуска, указать ID системы источника, номер модели и контур исполнения. С помощью Jenkins удалось структурировать и разбить на независимые этапы весь механизм сборки и инсталляции артефактов. Были добавлены необходимые проверки перед запуском формирования артефактов и их интеграции. Полученные артефакты автоматически перекладываются в SVN, что упрощает работу с ними смежным командам системных аналитиков и дата-моделлерам. Реализованы проверки, чтобы избежать холостых запусков формирования артефактов и подтвердить их корректность.
В итоге мы сократили трудоемкий процесс сборки и инсталляции артефактов модели от нескольких часов до пары минут. А самое главное, устранили возникновение ошибок из-за человеческого фактора, которые неизбежно возникали в сложном рутинном процессе.
На тот момент мы делали практически все вручную: и генерировали DDL, и собирали edwex-ы и json-ы на основе метаданных из Oracle БД. Входных параметров множество. Упустишь один — и некорректно сформируешь сущность. А так как весь процесс формирования был последовательным и непрерывным, то ошибка обнаружится только в самом конце. О том, как мы все автоматизировали и побороли ошибки, читайте под катом.
Немного об инфраструктуре
Перед тем, как залить данные в таблицы реляционных БД, нам необходимо принять их из источника — в любом формате, например в Excel. Данные из источника с помощью in-house механизма транспортируются в Hadoop (Data Lake). На Hadoop установлена надстройка Hive — с ее помощью мы можем просматривать содержимое файлов с помощью SQL-подобного синтаксиса.
Чтобы переложить данные в Data Lake в виде таблиц, нам необходимы json’ы, которые формируются на основе метаданных. Чтобы распарсить данные в формате Excel, нам необходимо сформировать EDWEX файлы. EDWEX (EDW_EXTRACTOR) файлы представляют собой некий набор артефактов, в которых содержатся наборы таблиц с наименованием, а также наборы полей для каждой из этих таблиц, формирующихся на основе метаданных. В зависимости от версии моделей и ID источника набор полей различается. Формирование DDL необходимо для создания самих таблиц в БД Hive на уровне оперативных данных и в БД Greenplum на уровне детальных и агрегированных данных. То есть первично данные попадают в Hive, при необходимости фильтруются и перекладываются в Greenplum для последующих манипуляций с данными и создания витрин на их основе.
Пример edwex артефактов
pack – содержит набор таблиц
data – содержит набор полей
pack.edwex:
data.edwex:
data – содержит набор полей
pack.edwex:
1 Table_1 User Table_1 bid between to_char($fromdt,'yyyymm') and to_char($actualdt,'yyyymm') 2 Table_2 User Table_2 curbid between to_char($fromdt,'yyyymm') and to_char($actualdt,'yyyymm') 3 Table_3 User Table_3 bid between to_char($fromdt,'yyyymm') and to_char($actualdt,'yyyymm')
data.edwex:
1 1 CHARGE_ID NUMBER 38 0 1 2 SVC_ID NUMBER 38 0 1 3 VND_ID NUMBER 38 0 1 4 PRICE NUMBER 38 5 1 5 QUANTITY NUMBER 38 5 1 6 BASE NUMBER 38 5 1 7 TAX NUMBER 38 5 1 8 TOTAL NUMBER 38 5 1 9 TAX_RATE NUMBER 38 5 1 10 TAX_IN VARCHAR 1 1 11 CHARGE_KIND VARCHAR 3 1 12 PRIVILEGE_ID NUMBER 38 0 1 13 CHARGE_REF_ID NUMBER 38 0 1 14 EBID NUMBER 38 0 1 15 INVOICE_ID NUMBER 38 0 1 16 ZERO_STATE_ID NUMBER 38 0 1 17 USER_ID NUMBER 38 0 1 18 BID NUMBER 38 0 1 19 QUANTITY_REAL NUMBER 38 5 2 1 CURBID NUMBER 38 0 2 2 USER_ID NUMBER 38 0 2 3 VND_ID NUMBER 38 0 2 4 APPBID NUMBER 38 0 2 5 SVC_ID NUMBER 38 0 2 6 DEBT NUMBER 38 5 2 7 INSTDEBT NUMBER 38 5 3 1 INVOICE_ID NUMBER 38 0 3 2 INVOICE_DATE DATE 3 3 INVOICE_NUM VARCHAR 64 3 4 INVOICE_NUM_N NUMBER 38 5 3 5 BASE NUMBER 38 5 3 6 TAX NUMBER 38 5 3 7 TOTAL NUMBER 38 5 3 8 PREPAID VARCHAR 1 3 9 EXPLICIT VARCHAR 1 3 10 VND_ID NUMBER 38 0 3 11 ADV_PAYMENT_ID NUMBER 38 0 3 12 MDBID NUMBER 38 0 3 13 BID NUMBER 38 0 3 14 USER_ID NUMBER 38 0 3 15 ZERO_STATE_ID NUMBER 38 0 3 16 ACTIVE_SUM NUMBER 38 5 3 17 SPLIT_VND NUMBER 38 5 3 18 PRECREATED VARCHAR 1
Пример json артефактов
Table.json: { "metadata": [ { "colOrder":"1", "name":"charge_id", "dataType":"DECIMAL", "precision":"0", "requied":"true", "keyFile":"" }, { "colOrder":"2", "name":"svc_id", "dataType":"DECIMAL", "precision":"0", "requied":"false", "keyFile":"" }, { "colOrder":"3", "name":"vnd_id", "dataType":"DECIMAL", "precision":"0", "requied":"false", "keyFile":"" }, { "colOrder":"4", "name":"price", "dataType":"DECIMAL", "precision":"0", "requied":"false", "keyFile":"" }, { "colOrder":"5", "name":"quantity", "dataType":"DECIMAL", "precision":"0", "requied":"false", "keyFile":"" }, { "colOrder":"6", "name":"base", "dataType":"DECIMAL", "precision":"0", "requied":"false", "keyFile":"" }, { "colOrder":"7", "name":"tax", "dataType":"DECIMAL", "precision":"0", "requied":"false", "keyFile":"" }, { "colOrder":"8", "name":"total", "dataType":"DECIMAL", "precision":"0", "requied":"false", "keyFile":"" }, { "colOrder":"9", "name":"tax_rate", "dataType":"DECIMAL", "precision":"0", "requied":"false", "keyFile":"" }, { "colOrder":"10", "name":"tax_in", "dataType":"STRING", "precision":"0", "requied":"false", "keyFile":"" }, { "colOrder":"11", "name":"charge_kind", "dataType":"STRING", "precision":"0", "requied":"false", "keyFile":"" }, { "colOrder":"12", "name":"privilege_id", "dataType":"DECIMAL", "precision":"0", "requied":"false", "keyFile":"" }, { "colOrder":"13", "name":"charge_ref_id", "dataType":"DECIMAL", "precision":"0", "requied":"false", "keyFile":"" }, { "colOrder":"14", "name":"ebid", "dataType":"DECIMAL", "precision":"0", "requied":"false", "keyFile":"" }, { "colOrder":"15", "name":"invoice_id", "dataType":"DECIMAL", "precision":"0", "requied":"false", "keyFile":"" }, { "colOrder":"16", "name":"zero_state_id", "dataType":"DECIMAL", "precision":"0", "requied":"false", "keyFile":"" }, { "colOrder":"17", "name":"user_id", "dataType":"DECIMAL", "precision":"0", "requied":"false", "keyFile":"" }, { "colOrder":"18", "name":"bid", "dataType":"DECIMAL", "precision":"0", "requied":"false", "keyFile":"" }, { "colOrder":"19", "name":"quantity_real", "dataType":"DECIMAL", "precision":"0", "requied":"false", "keyFile":"" } ], "ctlPath":"путь до ctl", "errPath":"путь до файла логирования ошибок", "inPath":"путь для формирования в hdfs", "outSchema":"схема БД", "outTable":"наименование таблицы", "isPartitioned":"параметр партиционирования", "sourceId":"id системы источника" }
Пример DDL-артефактов
alter table scheme.GP_000001_TABLE rename to Z_GP_000001_TABLE_20180807;
create table scheme.GP_000001_TABLE
(
`charge_id` DECIMAL(38,0),
`svc_id` DECIMAL(38,0),
`vnd_id` DECIMAL(38,0),
`price` DECIMAL(38,5),
`quantity` DECIMAL(38,5),
`base` DECIMAL(38,5),
`tax` DECIMAL(38,5),
`total` DECIMAL(38,5),
`tax_rate` DECIMAL(38,5),
`tax_in` STRING,
`charge_kind` STRING,
`privilege_id` DECIMAL(38,0),
`charge_ref_id` DECIMAL(38,0),
`ebid` DECIMAL(38,0),
`invoice_id` DECIMAL(38,0),
`zero_state_id` DECIMAL(38,0),
`user_id` DECIMAL(38,0),
`bid` DECIMAL(38,0),
`quantity_real` DECIMAL(38,5),
`load_dttm` TIMESTAMP,
`src_id` SMALLINT,
`package_id` BIGINT,
`wf_run_id` BIGINT,
`md5` STRING
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 'путь для формирования в hdfs'
TBLPROPERTIES ( 'auto.purge'='true', 'transient_lastDdlTime'='1489060201');
insert into scheme.GP_000001_TABLE( `charge_id`,
`svc_id`,
`vnd_id`,
`price`,
`quantity`,
`base`,
`tax`,
`total`,
`tax_rate`,
`tax_in`,
`charge_kind`,
`privilege_id`,
`charge_ref_id`,
`ebid`,
`invoice_id`,
`zero_state_id`,
`user_id`,
`bid`,
`quantity_real`,
`load_dttm`,
`src_id`,
`package_id`,
`wf_run_id`,
`md5`)
select `charge_id`,
`svc_id`,
`vnd_id`,
`price`,
`quantity`,
`base`,
`tax`,
`total`,
`tax_rate`,
`tax_in`,
`charge_kind`,
`privilege_id`,
`charge_ref_id`,
`ebid`,
`invoice_id`,
`zero_state_id`,
`user_id`,
`bid`,
`quantity_real`,
load_dttm,
src_id,
package_id,
wf_run_id,
md5 from scheme.Z_GP_000001_TABLE_20180807;
alter table scheme.GP_000001_TABLE rename to Z_GP_000001_TABLE_20180807;
create table scheme.GP_000001_TABLE
(
`charge_id` DECIMAL(38,0),
`svc_id` DECIMAL(38,0),
`vnd_id` DECIMAL(38,0),
`price` DECIMAL(38,5),
`quantity` DECIMAL(38,5),
`base` DECIMAL(38,5),
`tax` DECIMAL(38,5),
`total` DECIMAL(38,5),
`tax_rate` DECIMAL(38,5),
`tax_in` STRING,
`charge_kind` STRING,
`privilege_id` DECIMAL(38,0),
`charge_ref_id` DECIMAL(38,0),
`ebid` DECIMAL(38,0),
`invoice_id` DECIMAL(38,0),
`zero_state_id` DECIMAL(38,0),
`user_id` DECIMAL(38,0),
`bid` DECIMAL(38,0),
`quantity_real` DECIMAL(38,5),
`load_dttm` TIMESTAMP,
`src_id` SMALLINT,
`package_id` BIGINT,
`wf_run_id` BIGINT,
`md5` STRING
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 'путь для формирования в hdfs'
TBLPROPERTIES ( 'auto.purge'='true', 'transient_lastDdlTime'='1489060201');
insert into scheme.GP_000001_CPA_CHARGE( `charge_id`,
`svc_id`,
`vnd_id`,
`price`,
`quantity`,
`base`,
`tax`,
`total`,
`tax_rate`,
`tax_in`,
`charge_kind`,
`privilege_id`,
`charge_ref_id`,
`ebid`,
`invoice_id`,
`zero_state_id`,
`user_id`,
`bid`,
`quantity_real`,
`load_dttm`,
`src_id`,
`package_id`,
`wf_run_id`,
`md5`)
select `charge_id`,
`svc_id`,
`vnd_id`,
`price`,
`quantity`,
`base`,
`tax`,
`total`,
`tax_rate`,
`tax_in`,
`charge_kind`,
`privilege_id`,
`charge_ref_id`,
`ebid`,
`invoice_id`,
`zero_state_id`,
`user_id`,
`bid`,
`quantity_real`,
load_dttm,
src_id,
package_id,
wf_run_id,
md5 from scheme.Z_GP_000001_TABLE_20180807;
create table scheme.GP_000001_TABLE
(
`charge_id` DECIMAL(38,0),
`svc_id` DECIMAL(38,0),
`vnd_id` DECIMAL(38,0),
`price` DECIMAL(38,5),
`quantity` DECIMAL(38,5),
`base` DECIMAL(38,5),
`tax` DECIMAL(38,5),
`total` DECIMAL(38,5),
`tax_rate` DECIMAL(38,5),
`tax_in` STRING,
`charge_kind` STRING,
`privilege_id` DECIMAL(38,0),
`charge_ref_id` DECIMAL(38,0),
`ebid` DECIMAL(38,0),
`invoice_id` DECIMAL(38,0),
`zero_state_id` DECIMAL(38,0),
`user_id` DECIMAL(38,0),
`bid` DECIMAL(38,0),
`quantity_real` DECIMAL(38,5),
`load_dttm` TIMESTAMP,
`src_id` SMALLINT,
`package_id` BIGINT,
`wf_run_id` BIGINT,
`md5` STRING
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 'путь для формирования в hdfs'
TBLPROPERTIES ( 'auto.purge'='true', 'transient_lastDdlTime'='1489060201');
insert into scheme.GP_000001_TABLE( `charge_id`,
`svc_id`,
`vnd_id`,
`price`,
`quantity`,
`base`,
`tax`,
`total`,
`tax_rate`,
`tax_in`,
`charge_kind`,
`privilege_id`,
`charge_ref_id`,
`ebid`,
`invoice_id`,
`zero_state_id`,
`user_id`,
`bid`,
`quantity_real`,
`load_dttm`,
`src_id`,
`package_id`,
`wf_run_id`,
`md5`)
select `charge_id`,
`svc_id`,
`vnd_id`,
`price`,
`quantity`,
`base`,
`tax`,
`total`,
`tax_rate`,
`tax_in`,
`charge_kind`,
`privilege_id`,
`charge_ref_id`,
`ebid`,
`invoice_id`,
`zero_state_id`,
`user_id`,
`bid`,
`quantity_real`,
load_dttm,
src_id,
package_id,
wf_run_id,
md5 from scheme.Z_GP_000001_TABLE_20180807;
alter table scheme.GP_000001_TABLE rename to Z_GP_000001_TABLE_20180807;
create table scheme.GP_000001_TABLE
(
`charge_id` DECIMAL(38,0),
`svc_id` DECIMAL(38,0),
`vnd_id` DECIMAL(38,0),
`price` DECIMAL(38,5),
`quantity` DECIMAL(38,5),
`base` DECIMAL(38,5),
`tax` DECIMAL(38,5),
`total` DECIMAL(38,5),
`tax_rate` DECIMAL(38,5),
`tax_in` STRING,
`charge_kind` STRING,
`privilege_id` DECIMAL(38,0),
`charge_ref_id` DECIMAL(38,0),
`ebid` DECIMAL(38,0),
`invoice_id` DECIMAL(38,0),
`zero_state_id` DECIMAL(38,0),
`user_id` DECIMAL(38,0),
`bid` DECIMAL(38,0),
`quantity_real` DECIMAL(38,5),
`load_dttm` TIMESTAMP,
`src_id` SMALLINT,
`package_id` BIGINT,
`wf_run_id` BIGINT,
`md5` STRING
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 'путь для формирования в hdfs'
TBLPROPERTIES ( 'auto.purge'='true', 'transient_lastDdlTime'='1489060201');
insert into scheme.GP_000001_CPA_CHARGE( `charge_id`,
`svc_id`,
`vnd_id`,
`price`,
`quantity`,
`base`,
`tax`,
`total`,
`tax_rate`,
`tax_in`,
`charge_kind`,
`privilege_id`,
`charge_ref_id`,
`ebid`,
`invoice_id`,
`zero_state_id`,
`user_id`,
`bid`,
`quantity_real`,
`load_dttm`,
`src_id`,
`package_id`,
`wf_run_id`,
`md5`)
select `charge_id`,
`svc_id`,
`vnd_id`,
`price`,
`quantity`,
`base`,
`tax`,
`total`,
`tax_rate`,
`tax_in`,
`charge_kind`,
`privilege_id`,
`charge_ref_id`,
`ebid`,
`invoice_id`,
`zero_state_id`,
`user_id`,
`bid`,
`quantity_real`,
load_dttm,
src_id,
package_id,
wf_run_id,
md5 from scheme.Z_GP_000001_TABLE_20180807;
Как автоматизировали
Для решения задачи мы использовали:
- Jenkins — в качестве оркестратора и инструмента для реализации CI-процесса.
- Python — на нем реализована функциональность и unit-тесты.
- SQL — для обращения к базе метаданных.
- Shell script — для копирования артефактов между каталогами и формирования сценариев в multijob проектах, выполняемых на сервере Jenkins.
Начнем с того, что изначально мы работаем с большим количеством источников, поэтому с помощью Shell script в качестве параметра запуска передаем ID источников SQL-функциям для их идентификации. Полученные SQL-функции впоследствии будут автоматически выполнены в базе метаданных. На основе имеющихся метаданных эти функции формируют файл со списком новых SQL-функций для каждой из таблиц источника, чтобы мы их могли впоследствии вызвать в исполняемой программе. Результат выполнения сформированных функций — это передача в output-параметр значений DDL, JSON или EDWEX.
Здесь подключается Python, на котором написана вся исполняемая функциональность и unit-тесты. Перед запуском какого-либо из модулей раскатки артефактов с помощью unit-тестов проверяется корректная передача параметров для запуска python-скриптов. Тесты не только проверяют корректность параметров на входе, но и их наличие в модуле метаданных, размеры созданных файлов и даты их создания. Тесты также мониторят количество созданных новых артефактов и количество уже существующих артефактов. Так мы оптимизируем использование серверных ресурсов, поскольку берем для раскатки только новые файлы и не инсталлируем уже существующие модели заново.
И только после успешного прохождения всех проверок выполняется python-программа, которая создает необходимые артефакты и раскладывает полученный результат по необходимым папкам проектов на сервере. Python не только разбивает по каталогам сгенерированные json-файлы, но и формирует по ним структуры в Data Lake, чтобы данные загружались корректно. При формировании DDL-артефактов, они не только сохраняются для последующего анализа и переиспользования, но и сразу же могут быть инсталлированы в БД по новым моделям и структурам, указанным в модуле метаданных. Это позволяет создавать сотни таблиц за короткое время без привлечения ручного труда.
И где же тут Jenkins?
Jenkins вступает, когда необходимо управлять всеми этими процессами наглядно при помощи интерфейса.
Данный инструмент был выбран, потому как он:
- полностью покрывает потребности в автоматизации сборки и инсталляции
- позволяет конструировать механизм сборки артефактов с внедрением процесса автотестирования
- позволяет легко управлять запусками джобов и мониторингом выполнения человеку, далекому от программирования
- позволяет настроить механизм логирования таким образом, что результат выполнения будет понятен любому человеку в команде. Явно будет указана проблема в сборке или же процесс будет выполнен успешно.
Для решения поставленных задач мы создали несколько multijob проектов. Такой тип проектов был использован, так как он может работать параллельно с другими джобами при единовременном запуске. Каждый из джобов отвечает за реализацию своего блока функциональности. Так мы заменили последовательный процесс получения артефактов на автономные параллельные. Все запускается раздельно: формирование EDWEX, JSON, DDL, формирование структуры в HIVE, инсталляция структур таблиц в БД. Мы анализируем полученный результат на разных этапах формирования артефактов и приступаем к запуску последующих действий в случае успеха.
Jenkins-часть реализована без особых ухищрений. На вход джобам подаются String или Run параметры для запуска python-кода. String параметр представляет из себя окно для ввода значения с типом str перед запуском. Run параметр может передаваться на лету другому джобу для исполнения, для этого достаточно всего лишь указать из какого проекта необходимо забрать полученную переменную. Также отдельным параметром передается нода для выполнения. Здесь как раз реализовано разбиение по средам выполнения на DEV, TST, UAT, PRD. Отдельным джобом выполнена передача полученных EDWEX файлов в SVN с номером ревизии для возможности отслеживания версий измененных структур.
Пример интерфейса в Jenkins:
Результат выполнения джобов — это создание и инсталляция необходимых артефактов, передача их в SVN и формирование HTML-отчета, который отображает успешность прохождения unit-тестов и результаты выполнения сборки и инсталляции артефактов. Джобы можно запускать как руками по отдельности, так и в автоматическом режиме, предварительно выстроив цепочку исполнения.
Архитектура механизма сборки и инсталляции
Подведем итог
Была проделана большая работа по автоматизации формирования артефактов. Раньше нужно было вручную залезть на сервер, запустить shell скрипты, а затем долго изучать и править данные руками. Теперь достаточно нажать всего на кнопку запуска, указать ID системы источника, номер модели и контур исполнения. С помощью Jenkins удалось структурировать и разбить на независимые этапы весь механизм сборки и инсталляции артефактов. Были добавлены необходимые проверки перед запуском формирования артефактов и их интеграции. Полученные артефакты автоматически перекладываются в SVN, что упрощает работу с ними смежным командам системных аналитиков и дата-моделлерам. Реализованы проверки, чтобы избежать холостых запусков формирования артефактов и подтвердить их корректность.
В итоге мы сократили трудоемкий процесс сборки и инсталляции артефактов модели от нескольких часов до пары минут. А самое главное, устранили возникновение ошибок из-за человеческого фактора, которые неизбежно возникали в сложном рутинном процессе.

