
На AI Conference о применении обучения с подкреплением расскажет Владимир Иванов vivanov879, Sr. Deep learning engineer в Nvidia. Эксперт занимается машинным обучением в отделе тестирования: «Я анализирую данные, которые мы собираем во время тестирования видеоигр и железа. Для это пользуюсь машинным обучением и компьютерным зрением. Основную часть работы составляет анализ изображений, чистка данных перед обучением, разметка данных и визуализация полученных решений».
В сегодняшней статье Владимир объясняет, почему в автономных автомобилях используется обучение с подкреплением и рассказывает, как обучают агента для действий в изменяющейся среде – на примерах из видеоигр.
В последние несколько лет человечество накопило огромное количество данных. Некоторые датасеты выкладывают в общий доступ и размечают вручную. К примеру, датасет CIFAR, где у каждой картинки подписано, к какому классу она относится.

Появляются датасеты, где необходимо присвоить класс не просто картинке в целом, а каждому пикселю на изображении. Как, например, в CityScapes.

Что объединяет эти задачи, так это то, что обучающейся нейронной сети необходимо лишь запомнить закономерности в данных. Поэтому при достаточно больших объемах данных, а в случае CIFAR это 80 млн картинок, нейронная сеть учится обобщать. В результате она неплохо справляется с классификацией картинок, которые никогда раньше не видела.
Но действуя в рамках техники обучения с учителем, которая работает для разметки картинок, невозможно решить задачи, где мы хотим не предсказывать метку, а принимать решения. Как, например, в случае автономного вождения, где задача состоит в том, чтобы безопасно и надежно добраться до конечной точки маршрута.
В задачах классификации мы пользовались техникой обучения с учителем – когда каждой картинке присвоен определенный класс. А что если у нас нет такой разметки, зато есть агент и среда, в которой он может совершать определенные действия? Например, пусть это будет видеоигра, а мы можем нажимать на стрелки управления.

Такого рода задачи стоит решать с помощью обучения с подкреплением. В общей постановке задачи мы хотим научиться выполнять правильную последовательность действий. Принципиально важно, что у агента есть возможность выполнять действия вновь и вновь, таким образом исследуя среду, в которой он находится. И вместо правильного ответа, как надо поступить в той или иной ситуации, он получает награду за правильно выполненную задачу. Например, в случае автономного такси водитель будет получать премию за каждую выполненную поездку.
Вернемся к простому примеру – к видеоигре. Возьмем что-нибудь незатейливое, например, игру Atari в настольный теннис.

Мы будем управлять дощечкой слева. Играть будем против запрограммированного на правилах компьютерного игрока справа. Поскольку мы работаем с изображением, а успешней всех с извлечением информации из изображений справляются нейронные сети, давайте подавать картинку на вход трехслойной нейронной сети с размером ядра 3х3. На выходе она должна будет выбрать одно из двух действий: двигать дощечку вверх или вниз.

Тренируем нейронную сеть на выполнение действий, которые приводят к победе. Техника обучения следующая. Мы даем нейронной сети поиграть несколько раундов в настольный теннис. Потом начинаем разбирать сыгранные партии. В тех партиях, где она победила, мы размечаем картинки с меткой “Вверх” там, где она поднимала ракетку, и “Вниз” там, где она ее опускала. В проигранных партиях мы поступаем наоборот. Размечаем те картинки, где она опускала дощечку, меткой “Вверх”, а где поднимала — “Вниз”. Таким образом, мы сводим задачу к уже известному нам подходу — обучению с учителем. У нас есть набор картинок с метками.
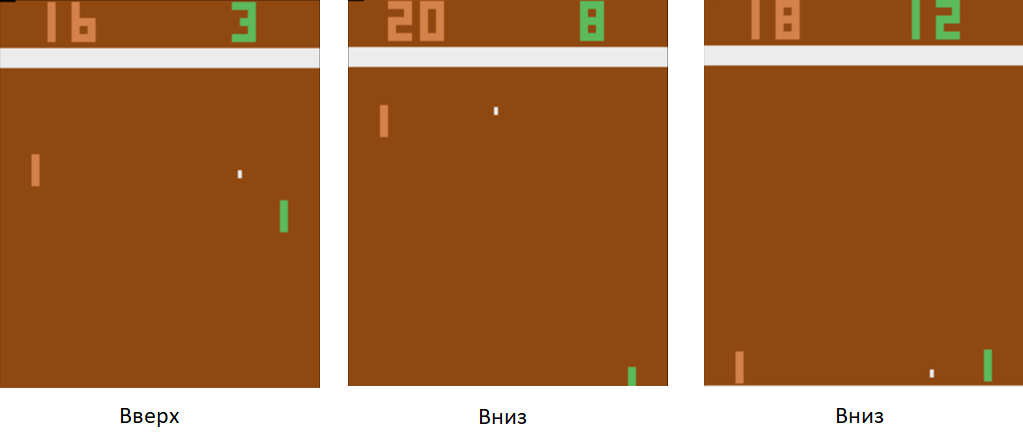
Пользуясь этой техникой обучения, через пару часов наш агент научится обыгрывать запрограммированного на правилах компьютерного игрока.
Как быть в случае автономного вождения? Дело в том, что в настольный теннис — очень простая игра. И она может выдавать тысячи кадров в секунду. В нашей сети сейчас всего-навсего 3 слоя. Поэтому процесс обучения молниеносный. Игра генерирует огромное количество данных, а мы мгновенно их обрабатываем. В случае автономного вождения данные собирать намного дольше и дороже. Автомобили дорогие, и с одного автомобиля мы будем получать только 60 кадров в секунду. Кроме того, возрастает цена ошибки. В видеоигре мы могли позволить себе проигрывать партию за партией в самом начале обучения. Но мы не можем позволить себе испортить автомобиль.
В таком случае, давайте поможем нейронной сети в самом начале обучения. Закрепим камеру на автомобиле, посадим в него опытного водителя и будем записывать фотографии с камеры. К каждому снимку подпишем угол поворота руля автомобиля. Будем обучать нейронную сеть копировать поведение опытного водителя. Таким образом, мы вновь свели задачу к уже известному обучению с учителем.
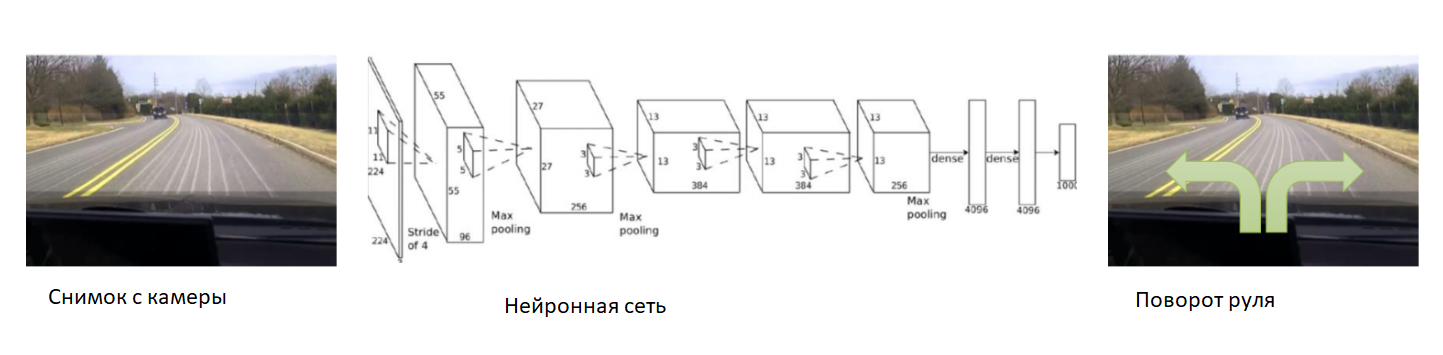
При достаточно большом и разнообразном датасете, который будет включать в себя разные ландшафты, времена года и погодные условия, нейронная сеть научится точно управлять автомобилем.
Тем не менее, осталась проблема с данными. Их очень долго и дорого собирать. Давайте воспользуемся симулятором, в котором будет реализована вся физика движения автомобиля – например, DeepDrive. Мы сможем обучаться в нем, не боясь потерять автомобиль.

В данном симуляторе у нас есть доступ ко всем показателям автомобиля и окружающего мира. Кроме того, размечены все находящиеся вокруг люди, автомобили, их скорости и расстояния до них.

С точки зрения инженера в таком симуляторе можно смело пробовать новые техники обучения. А как поступить исследователю? Например, изучающему разные варианты градиентного спуска в задачах обучения с подкреплением. Чтобы проверить простую гипотезу, не хочется стрелять из пушки по воробьям и запускать агента в сложном виртуальном мире, а потом ждать днями результаты симуляции. В таком случае давайте более эффективно использовать наши вычислительные мощности. Пусть агенты будут попроще. Возьмем, например, модель паука на четырех лапках. В симуляторе Mujoco он выглядит так:

Поставим ему задачу бежать с как можно большей скоростью в заданном направлении — например, направо. Количество наблюдаемых параметров для паука представляет собой 39-размерный вектор, куда записываются показатели положения и скорости всех его конечностей. В отличие от нейронной сети для настольного тенниса, где на выходе был всего один нейрон, здесь на выходе восемь (поскольку у паука в данной модели 8 суставов).
В таких простых моделях можно проверять различные гипотезы о технике обучения. Например, давайте сравним скорость обучения бегу в зависимости от типа нейросети. Пусть это будут однослойная нейронная сеть, трехслойная нейронная сеть, сверточная сеть и рекуррентная сеть:

Вывод можно сделать такой: поскольку модель паука и задача достаточно простые, результаты тренировки приблизительно одинаковые для разных моделей. А трехслойная сеть слишком сложная, и поэтому обучается хуже.
Несмотря на то что симулятор работает с простой моделью паука, в зависимости от задачи, которая ставится перед пауком, обучение может длиться днями. В таком случае давайте на одной поверхности анимировать одновременно несколько сотен пауков вместо одного и обучаться на данных, которые будем получать со всех. Так мы ускорим обучение в несколько сотен раз. Вот пример движка Flex.

Единственное, что поменялось с точки зрения оптимизации нейронной сети, — это сбор данных. Когда у нас бегал только один паук, мы получали данные последовательно. Один пробег за другим.

Теперь же может случиться, что некоторые пауки только начинают забег, а другие уже давно бегут.
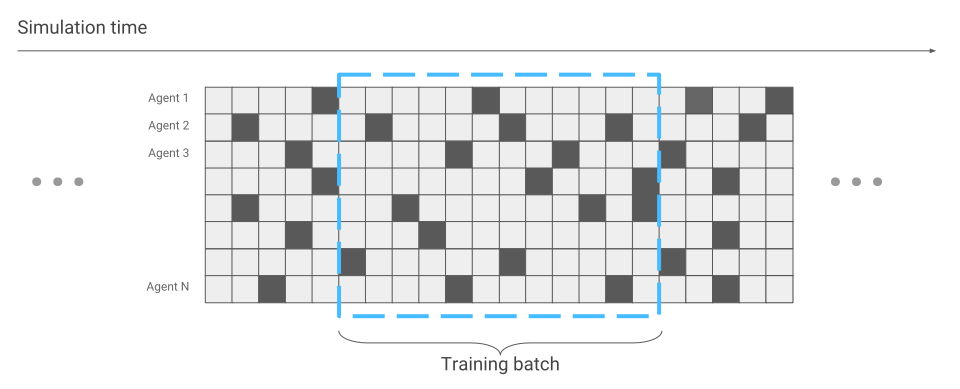
Будем это учитывать во время оптимизации нейронной сети. В остальном все остается так же. В результате мы получаем ускорение в обучении в сотни раз, по количеству пауков, которые одновременно находятся на экране.
Раз у нас появился эффективный симулятор, давайте попробуем решать более сложные задачи. Например, бег по пересеченной местности.

Поскольку среда в данном случае стала более агрессивной, давайте во время обучения менять и усложнять задачи. Тяжело в учении, зато легко в бою. Например, каждые несколько минут менять рельеф местности. Вдобавок давайте на агента направим еще и внешние воздействия. Например, станем бросать в него шарики и включать и выключать ветер. Тогда агент учится бегать даже по поверхностям, которые он ни разу не встречал. Например, подниматься по лестнице.

Раз мы так эффективно научились бегать в симуляторах, давайте проверять техники обучения с подкреплением в соревновательных дисциплинах. Например, в стрелялках. Платформа VizDoom предлагает мир, в котором можно стрелять, собирать оружие и пополнять здоровье. В этой игре мы так же будем использовать нейронную сеть. Только теперь у нее будет пять выходов: четыре на движение и один на стрельбу.
Чтобы обучение шло эффективно, давайте к этому подходить постепенно. От простого к сложному. На вход нейросеть получает изображение, и перед тем как начать делать что-то осознанное, она должна научиться понимать, из чего состоит окружающий мир. Обучаясь на простых сценариях, она научится понимать, какие объекты населяют мир и как с ними можно взаимодействовать. Начнем с тира:

Освоив этот сценарий, агент разберется, что бывают враги, и в них стоит стрелять, потому что за них получаешь очки. Потом обучим его в сценарии, где здоровье постоянно уменьшается, и нужно его пополнять.

Здесь он выучит, что у него есть здоровье, и его необходимо пополнять, ведь в случае гибели агент получает отрицательную награду. Кроме того, он выучит, что если двигаться в сторону предмета, его можно собрать. В первом сценарии агент не мог перемещаться.
И в заключительном, третьем сценарии, давайте оставим его стреляться с запрограммированными на правилах ботами из игры, чтобы он мог отточить свое мастерство.

Во время обучения в этом сценарии очень важную роль играет правильный подбор наград, которые получает агент. Например, если давать награду только за поверженных соперников, сигнал получится очень редким: если вокруг мало игроков, то очки мы будем получать раз в несколько минут. Поэтому давайте воспользуемся комбинацией наград, которые были раньше. Агент будет получать поощрение за каждое полезное действие, будь то повышение здоровья, подбор патронов или попадание в соперника.
В результате агент, обученный с помощью хорошо подобранных наград, оказывается сильнее своих более вычислительно требовательных оппонентов. В 2016 году такая система выиграла соревнование по VizDoom с отрывом в более чем половину набранных очков от второго места. Команда, занявшая второе место, тоже использовала нейросеть, только с большим количеством слоев и дополнительной информацией от движка игры во время обучения. Например, информацией о том, есть ли враги в поле зрения агента.
Мы с вами рассмотрели подходы к решению задач, где важно принимать решения. Но многие задачи при таком подходе останутся нерешенными. Например, игра-квест Montezuma Revenge.

Здесь необходимо искать ключи, чтобы открывать двери в соседние комнаты. Ключи мы получаем редко, а комнаты открываем еще реже. Еще важно не отвлекаться на посторонние предметы. Если обучать систему так, как мы это делали в предыдущих задачах, и давать награды за побитых врагов, она просто станет выбивать катающийся череп вновь и вновь и не будет исследовать карту. О решении такого рода задач, если интересно, я могу рассказать в отдельной статье.
Послушать выступление Владимира Иванова можно будет на AI Conference 22 ноября. Подробная программа и билеты — на официальном сайте мероприятия.
Интервью с Владимиром читайте здесь.

