Облака, облака и ещё раз облака. Движение в облака, будь то ваше частное облако у вас в ЦОД, приватное облако у провайдера или у публичных провайдеров таких как Amazon AWS, Microsoft Azure, IBM Cloud, Google Cloud, неумолимо. Особенно я это заметил, переехав в США. Здесь о них говорят все и всегда — воздух буквально пропитан этой темой. Производители как программного, так и аппаратного обеспечения прекрасно это поняли и не хотят упустить данное окно возможностей в этом изменяющемся мире.

Kuberneties Service
становится важным и мощным инструментом как для создания и управления Data Fabric (о котором дальше), так и для конкуренции на поле HCI систем. Ранее NetApp HCI был достаточно простым решением, работающим только с VMware, как, собственно, начинал и Nutanix. Теперь же когда появился NKS, NetApp HCI составит намного более жесткую конкуренцию Nutanix в плане Next Generation DataCenter & Next generation applications на базе контейнеров, но при этом самое интересное оставляя нишу, в которой гипервизор Nutanix, теоретически может запускаться на NetApp HCI. NetApp Kubernetes Service Demo.
HCI
Одним из первых и заслуженным HCI, который знаком многим, является Nutanix. Несмотря на то, что Nutanix очень интересный продукт, он не лишен недостатков. Самое интересное в Nutanix, на мой взгляд, внутренняя экосистема, а не архитектура хранилища. Если говорить касательно недостатков, стоит отметить, что маркетинг мог замылить некоторым инженерам глаза передавая не верный посыл, что все данные всегда находятся локально и это хорошо. В то время как у конкурентов, намекая на NetApp HCI, к данным нужно обращаться по сети, что «долго» и вообще это «не настоящий HCI», при этом не давая определения, что же является настоящим HCI, хотя его и не может быть в принципе как, например и у «Облака», которому тоже никто не берется дать определение. Потому что оно выдумано людьми для маркетинговых целей, чтобы в будущем можно было дополнять и изменять содержание этого понятия, а не для сугубо технических целей, в которых изначально у объекта всегда есть неизменное определение.
Изначально проще было войти на рынок HCI именно с архитектурой доступной массам, которую легче можно потребить, а именно просто использовать комодити сервера с набитыми дисками.
Но это далеко не значит, что это и есть определяющие свойства HCI и единый наилучший вариант HCI. Постановка задачи на самом деле породила проблему или как я уже сказал нюанс: когда вы используете storage в share-nothing архитектуре, к которой относятся Nutanix HCI на базе комодити оборудования, вам необходимо обеспечить доступность и защиту данных, для этого необходимо все записи как минимум копировать с одного сервера на другой. И когда виртуальная машина генерирует новую запись на локальный диск, всё бы было хорошо, если бы не нужно было эту запись синхронно продублировать и передать еще на второй сервер и дождаться ответа, что она находится в целости и сохранности. Другими словами, в Nutanix, да и в принципе любой share-nothing архитектуре, скорость записей плюс минус в лучшем случае равносильна тому, что эти записи были бы сразу переданы по сети на shared storage.
Главными базовыми конструктивными лозунгами HCI всегда были простота начальной установки и настройки, возможность начать из минимальной, простой и не дорогой конфигурации и расшириться до нужного размера, простота расширения/сжатия, простота управления из единой консоли, автоматизация, всё это так или иначе связано с, простотой, cloud-like experience, гибкостью и гранулярностью потребления ресурсов. А вот является ли система хранения в архитектуре HCI отдельно выделенной коробочкой или частью сервера, на самом деле архитектурно не играет большой роли для достижения этой простоты.
Резюмируя это можно сказать, что маркетинг удивительным образом ввёл в заблуждение многих инженеров, о том, что локальные диски — это всегда лучше, что не является действительностью, потому что с технической точки зрения, в отличии от маркетинга, не всё так просто. Сделав неверный вывод о том, что есть HCI архитектуры, в которых используются только локальные диски, можно сделать следующий не верный вывод, что системы хранения, подключённые по сети, будут всегда работать медленнее. Но принципы защиты информации, логика и физика в этом мире устроены таким образом что этого достичь невозможно, и от коммуникации по сети между дисковыми подсистемами в HCI инфраструктуре никуда не деться, по этому принципиальной разницы в том, будут ли диски локально вместе с компьютинг нодами или в отдельной storage ноде подключённой по сети нет. Скорее наоборот, выделенные storage ноды позволяют добиться меньших зависимостей компонент HCI друг от друга, к примеру если вы уменьшаете количество нод в HCI кластере на базе того же Nutanix или vSAN, вы автоматически уменьшает пространство в кластере. И наоборот: добавляя компьютинг ноды вы обязаны добавить и диски в этот сервер. В то время как в архитектуре NetApp HCI эти компоненты не связаны друг с другом. Плата за такую инфраструктуру отнюдь не в скорости работы дисковой подсистемы, а в том, что для старта необходимо иметь минимум 2 storage ноды и минимум 2 компьютинг ноды, итого 4 ноды. 4 ноды NetApp HCI могут быть упакованы в 2U используя половинчатые лезвия.

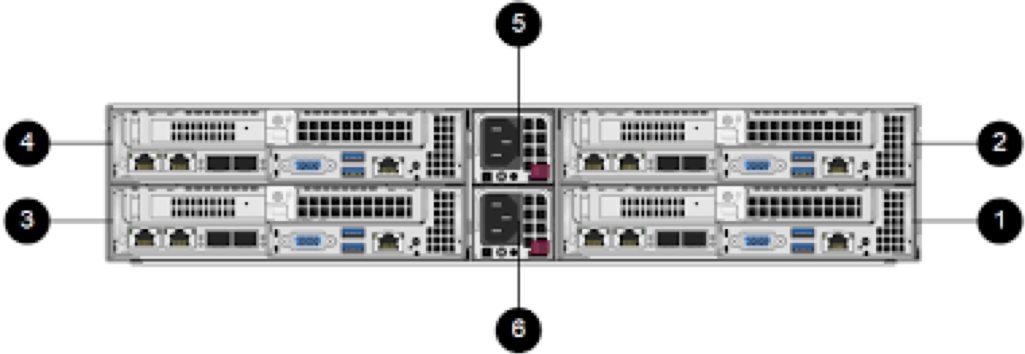
NetApp HCI
С покупкой SolidFire в линейке продуктов NetApp появилась HCI (у данного продукта нет собственного названия, по этому его называют просто HCI) система. Основным её отличием от “классических” HCI систем являются отдельный storage ноды, подключённые по сети. Сама же система SolidFire, которая является “стораджовой” прослойкой для HCI радикально отличается от All-Flash систем AFF, которые развилась из линейки FAS, которая в свою очередь уже около 26 лет находится на рынке. Познакомившись с ним поближе (что можете сделать и вы), становится понятно, что это продукт совсем другой идеологии, нацеленный на другой сегмент потребителей (облачных провайдеров) и идеально вписывающийся именно под их задачи, как с точки зрения производительности, отказоустойчивости, так и с точки зрения интеграции в единую экосистему биллинга.
Отжигаем на все 200 Тестирование NetApp SolidFire Артур Аликулов, Евгений Елизаров. NetApp Directions 2018.
Компания NetApp движется в облака
и давно уже перестала быть просто производителем систем хранения данных. Теперь это скорее уже облачная, дата менеджмент компания, по крайней мере они упорно движутся в этом направлении. Огромное количество тех или иных внедрений продуктов компании NetApp говорит именно об этом — SaaS backup for O365, SaaS backup for Salesforce (и планы для Google Apps, Slack & ServiceNow). ONTAP Select стал очень важным решением, самостоятельным, а не как раньше маленькой примочкой для репликации на «полноценный» FAS. NDAS всё глубже объединяет раньше, казалось бы, необъединимое – системы хранения данных и облако предоставляя резервное копирование, google-like поиск по каталогу файлов и графический интерфейс управления как услугу. FabricPool пошел ещё глубже и объединил SSD и облако, что казалось раньше не вероятным или даже сумасшедшим.
Тот только факт, что NetApp за довольно-таки короткий срок оказался в четырёх этих самых больших в мире облачных провайдерах говорит о серьёзности их намерений. Мало того NFS сервис в Azure построен исключительно на NetApp AFF системах.
Azure NetApp Files Demo.
В Azure, AWS и Google доступны системы хранения NetApp AFF как сервис, их поддержкой, обновлением и обслуживанием занимается NetApp, а пользователи облака могут потреблять пространство AFF систем и функционал снепшотирования, клонирования, QoS, как услугу. NetApp Cloud Volumes Service for AWS Demo.
В IBM Cloud используется ONTAP Select, который имеет точно такой же функционал, как и AFF системы, но используется в виде ПО который может быть установлен на комодити сервера. Active IQ это веб-портал который отображает информацию по программному обеспечению и оборудованию NetApp и даёт рекомендации по упреждению проблем и обновлению при помощи AI алгоритмов запущенных на собранной телеметрии с устройств и сервисов NetApp. NetApp Active IQ Demo.
Data Fabric
В целом, стратегия Data Fabric, которой сейчас придерживается компания NetApp как раз призвана совместить эти, совершенно разные среды: публичные и частные облака, и все продукты NetApp. Ведь мало просто запустить какой-то продукт в облаке, нужно что бы он логично и гармонично вписывался в сервисы облачных провайдеров. И на сегодняшний день NetApp это удаётся более чем успешно. Data Fabric из маркетинговой идеи плавно приобретает вполне осязаемые черты в виде отдельно взятых технологий и продуктов: FabricPool тиринг между SSD & S3, SnapMirror между ONTAP & SolidFier/HCI, SnapCenter для ONTAP & SolidFier (который еще не реализован), NDAS сервис резервного копирования данных их СХД в облако, MAX Data ПО для software defined memory, это всё продукты или фичи NetApp которые воплощают это видение Data Fabric. ONTAP Select теперь может работать на Nutanix, доставляя богатый файловый функционал в их экосистему.
Data Fabric это от части видение процесса слияния либо интеграции всех продуктов NetApp и даже облаков, и я даже вижу не просто маркетинговое, а вполне даже физическое слияние отдельно взятых продуктов.
Мало того, я хочу сделать предсказание. Я уже несколько лет играю в эту игру на счёт предсказаний с некоторыми своими коллегами и пока что я всегда был очень близок либо угадывал ход мыслей в этой компании, посмотрим, как мне повезёт в этот раз. Хочу подчеркнуть, что это лично моё мнение, основанное на кусочках информации, полученные за все 7 лет моего опыта с NetApp и интуиции, никто из NetApp мне этого не говорил, поэтому это может быть исключительно плодом моей фантазии:
NetApp заканчивает быть вендором СХД
может это слишком громкое название заголовка, но NetApp переходит в фазу, где компания становится data management, software defined, cloud-native оператором и по старинке по-прежнему продолжает выпускать СХД. СХД никуда не делись и не видно края тому, что это может произойти в ближайшее время, но смещается упор на облачность и на сами данные.
Данный текст написан в тесной коллаборации с Дмитрием bbk, если вы хотите знать больше о технологиях NetApp — не поленитесь поставить ему +, и новые статьи не заставят себя ждать.
Если вас интересуют новости из мира NetApp, добро пожаловать в telegram-канал StorageTalks, но а если вы ищете активное русскоязычное storage-комьюнити, приходите в telegram-чат StorageDiscussions.
Kuberneties Service
становится важным и мощным инструментом как для создания и управления Data Fabric (о котором дальше), так и для конкуренции на поле HCI систем. Ранее NetApp HCI был достаточно простым решением, работающим только с VMware, как, собственно, начинал и Nutanix. Теперь же когда появился NKS, NetApp HCI составит намного более жесткую конкуренцию Nutanix в плане Next Generation DataCenter & Next generation applications на базе контейнеров, но при этом самое интересное оставляя нишу, в которой гипервизор Nutanix, теоретически может запускаться на NetApp HCI. NetApp Kubernetes Service Demo.
HCI
Одним из первых и заслуженным HCI, который знаком многим, является Nutanix. Несмотря на то, что Nutanix очень интересный продукт, он не лишен недостатков. Самое интересное в Nutanix, на мой взгляд, внутренняя экосистема, а не архитектура хранилища. Если говорить касательно недостатков, стоит отметить, что маркетинг мог замылить некоторым инженерам глаза передавая не верный посыл, что все данные всегда находятся локально и это хорошо. В то время как у конкурентов, намекая на NetApp HCI, к данным нужно обращаться по сети, что «долго» и вообще это «не настоящий HCI», при этом не давая определения, что же является настоящим HCI, хотя его и не может быть в принципе как, например и у «Облака», которому тоже никто не берется дать определение. Потому что оно выдумано людьми для маркетинговых целей, чтобы в будущем можно было дополнять и изменять содержание этого понятия, а не для сугубо технических целей, в которых изначально у объекта всегда есть неизменное определение.
Изначально проще было войти на рынок HCI именно с архитектурой доступной массам, которую легче можно потребить, а именно просто использовать комодити сервера с набитыми дисками.
Но это далеко не значит, что это и есть определяющие свойства HCI и единый наилучший вариант HCI. Постановка задачи на самом деле породила проблему или как я уже сказал нюанс: когда вы используете storage в share-nothing архитектуре, к которой относятся Nutanix HCI на базе комодити оборудования, вам необходимо обеспечить доступность и защиту данных, для этого необходимо все записи как минимум копировать с одного сервера на другой. И когда виртуальная машина генерирует новую запись на локальный диск, всё бы было хорошо, если бы не нужно было эту запись синхронно продублировать и передать еще на второй сервер и дождаться ответа, что она находится в целости и сохранности. Другими словами, в Nutanix, да и в принципе любой share-nothing архитектуре, скорость записей плюс минус в лучшем случае равносильна тому, что эти записи были бы сразу переданы по сети на shared storage.
Главными базовыми конструктивными лозунгами HCI всегда были простота начальной установки и настройки, возможность начать из минимальной, простой и не дорогой конфигурации и расшириться до нужного размера, простота расширения/сжатия, простота управления из единой консоли, автоматизация, всё это так или иначе связано с, простотой, cloud-like experience, гибкостью и гранулярностью потребления ресурсов. А вот является ли система хранения в архитектуре HCI отдельно выделенной коробочкой или частью сервера, на самом деле архитектурно не играет большой роли для достижения этой простоты.
Резюмируя это можно сказать, что маркетинг удивительным образом ввёл в заблуждение многих инженеров, о том, что локальные диски — это всегда лучше, что не является действительностью, потому что с технической точки зрения, в отличии от маркетинга, не всё так просто. Сделав неверный вывод о том, что есть HCI архитектуры, в которых используются только локальные диски, можно сделать следующий не верный вывод, что системы хранения, подключённые по сети, будут всегда работать медленнее. Но принципы защиты информации, логика и физика в этом мире устроены таким образом что этого достичь невозможно, и от коммуникации по сети между дисковыми подсистемами в HCI инфраструктуре никуда не деться, по этому принципиальной разницы в том, будут ли диски локально вместе с компьютинг нодами или в отдельной storage ноде подключённой по сети нет. Скорее наоборот, выделенные storage ноды позволяют добиться меньших зависимостей компонент HCI друг от друга, к примеру если вы уменьшаете количество нод в HCI кластере на базе того же Nutanix или vSAN, вы автоматически уменьшает пространство в кластере. И наоборот: добавляя компьютинг ноды вы обязаны добавить и диски в этот сервер. В то время как в архитектуре NetApp HCI эти компоненты не связаны друг с другом. Плата за такую инфраструктуру отнюдь не в скорости работы дисковой подсистемы, а в том, что для старта необходимо иметь минимум 2 storage ноды и минимум 2 компьютинг ноды, итого 4 ноды. 4 ноды NetApp HCI могут быть упакованы в 2U используя половинчатые лезвия.
NetApp HCI
С покупкой SolidFire в линейке продуктов NetApp появилась HCI (у данного продукта нет собственного названия, по этому его называют просто HCI) система. Основным её отличием от “классических” HCI систем являются отдельный storage ноды, подключённые по сети. Сама же система SolidFire, которая является “стораджовой” прослойкой для HCI радикально отличается от All-Flash систем AFF, которые развилась из линейки FAS, которая в свою очередь уже около 26 лет находится на рынке. Познакомившись с ним поближе (что можете сделать и вы), становится понятно, что это продукт совсем другой идеологии, нацеленный на другой сегмент потребителей (облачных провайдеров) и идеально вписывающийся именно под их задачи, как с точки зрения производительности, отказоустойчивости, так и с точки зрения интеграции в единую экосистему биллинга.
Отжигаем на все 200 Тестирование NetApp SolidFire Артур Аликулов, Евгений Елизаров. NetApp Directions 2018.
Компания NetApp движется в облака
и давно уже перестала быть просто производителем систем хранения данных. Теперь это скорее уже облачная, дата менеджмент компания, по крайней мере они упорно движутся в этом направлении. Огромное количество тех или иных внедрений продуктов компании NetApp говорит именно об этом — SaaS backup for O365, SaaS backup for Salesforce (и планы для Google Apps, Slack & ServiceNow). ONTAP Select стал очень важным решением, самостоятельным, а не как раньше маленькой примочкой для репликации на «полноценный» FAS. NDAS всё глубже объединяет раньше, казалось бы, необъединимое – системы хранения данных и облако предоставляя резервное копирование, google-like поиск по каталогу файлов и графический интерфейс управления как услугу. FabricPool пошел ещё глубже и объединил SSD и облако, что казалось раньше не вероятным или даже сумасшедшим.
Тот только факт, что NetApp за довольно-таки короткий срок оказался в четырёх этих самых больших в мире облачных провайдерах говорит о серьёзности их намерений. Мало того NFS сервис в Azure построен исключительно на NetApp AFF системах.
Azure NetApp Files Demo.
В Azure, AWS и Google доступны системы хранения NetApp AFF как сервис, их поддержкой, обновлением и обслуживанием занимается NetApp, а пользователи облака могут потреблять пространство AFF систем и функционал снепшотирования, клонирования, QoS, как услугу. NetApp Cloud Volumes Service for AWS Demo.
В IBM Cloud используется ONTAP Select, который имеет точно такой же функционал, как и AFF системы, но используется в виде ПО который может быть установлен на комодити сервера. Active IQ это веб-портал который отображает информацию по программному обеспечению и оборудованию NetApp и даёт рекомендации по упреждению проблем и обновлению при помощи AI алгоритмов запущенных на собранной телеметрии с устройств и сервисов NetApp. NetApp Active IQ Demo.
Data Fabric
В целом, стратегия Data Fabric, которой сейчас придерживается компания NetApp как раз призвана совместить эти, совершенно разные среды: публичные и частные облака, и все продукты NetApp. Ведь мало просто запустить какой-то продукт в облаке, нужно что бы он логично и гармонично вписывался в сервисы облачных провайдеров. И на сегодняшний день NetApp это удаётся более чем успешно. Data Fabric из маркетинговой идеи плавно приобретает вполне осязаемые черты в виде отдельно взятых технологий и продуктов: FabricPool тиринг между SSD & S3, SnapMirror между ONTAP & SolidFier/HCI, SnapCenter для ONTAP & SolidFier (который еще не реализован), NDAS сервис резервного копирования данных их СХД в облако, MAX Data ПО для software defined memory, это всё продукты или фичи NetApp которые воплощают это видение Data Fabric. ONTAP Select теперь может работать на Nutanix, доставляя богатый файловый функционал в их экосистему.
Data Fabric это от части видение процесса слияния либо интеграции всех продуктов NetApp и даже облаков, и я даже вижу не просто маркетинговое, а вполне даже физическое слияние отдельно взятых продуктов.
Мало того, я хочу сделать предсказание. Я уже несколько лет играю в эту игру на счёт предсказаний с некоторыми своими коллегами и пока что я всегда был очень близок либо угадывал ход мыслей в этой компании, посмотрим, как мне повезёт в этот раз. Хочу подчеркнуть, что это лично моё мнение, основанное на кусочках информации, полученные за все 7 лет моего опыта с NetApp и интуиции, никто из NetApp мне этого не говорил, поэтому это может быть исключительно плодом моей фантазии:
- AFF станет частью HCI
- Станет возможно мигрировать LUN в онлайне между AFF/HCI
NetApp заканчивает быть вендором СХД
может это слишком громкое название заголовка, но NetApp переходит в фазу, где компания становится data management, software defined, cloud-native оператором и по старинке по-прежнему продолжает выпускать СХД. СХД никуда не делись и не видно края тому, что это может произойти в ближайшее время, но смещается упор на облачность и на сами данные.
Данный текст написан в тесной коллаборации с Дмитрием bbk, если вы хотите знать больше о технологиях NetApp — не поленитесь поставить ему +, и новые статьи не заставят себя ждать.
Если вас интересуют новости из мира NetApp, добро пожаловать в telegram-канал StorageTalks, но а если вы ищете активное русскоязычное storage-комьюнити, приходите в telegram-чат StorageDiscussions.

