
Разбираем настройку HA-кластера с Keepalived и Orchestrator для тех, кто предпочитает контроль облачным black box-решениям.

Хабр, привет!
Почему проблема отказа мастера в кластере MySQL до сих пор актуальна? Потому что сегодня 10 минут простоя у крупных заказчиков – это ЧП, а человеческий фактор в кризисной ситуации – главный источник риска. Многие проекты, мигрируя на MySQL 8.0, заново проходят путь настройки отказоустойчивости. И далеко не все готовы доверить свою основную базу данных облачным managed-сервисам, иногда нужен полный контроль на своей инфраструктуре.
Мы доказали, что падение мастера MySQL больше не означает аврал по скриптам, внедрив для заказчика полностью автоматический фейловер. Система теперь переключается сама, а инженеры получают уже готовый отчет о произошедшем.
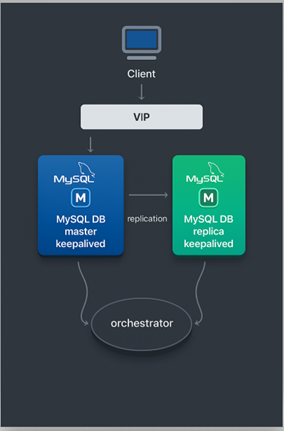
В этом мануале на живом примере развернем такую же отказоустойчивую связку. За основу возьмем кластер MySQL 8.0.24 с GTID-репликацией и добавим два ключевых компонента:
Keepalived — будет управлять виртуальным IP (VIP), бесшовно направляя подключения на текущий мастер-узел.
Orchestrator — выступит «мозгом» системы: мониторит кластер и в случае сбоя сам продвигает реплику в мастера, перестраивая топологию.
Наша цель — обеспечить непрерывную работу БД, минимизируя потери данных. . В идеале, даже при выходе из строя узла или целого ЦОД, кластер должен обслуживать запросы без значительного простоя, а риск расхождения данных или “split-brain” должен быть сведён к минимуму.
Почему мы выбрали Orchestrator и Keepalived?
Мы используем только Open Source компоненты (MySQL Community, Orchestrator, Keepalived). Из доступных решений для двух узлов эта связка оказалась оптимальной. Рассмотренные альтернативы (например, Pacemaker+Corosync или galera) не подошли или были сложны.
Настройка MySQL на узлах: GTID, репликация, конфигурация
Начнем с базовой настройки MySQL. На каждом узле node01 и node02 необходимо задать уникальный server-id и включить бинарный лог. Убедитесь, что в конфигурации (/etc/my.cnf) на обоих серверах установлены параметры для GTID-репликации:
log_bin = mysql-bin(включает бинарный журнал для репликации).server_id = 1(наnode01) иserver_id = 2(наnode02) – уникальные идентификаторы сервера.gtid_mode = ONиenforce_gtid_consistency = ON– включение глобальных идентификаторов транзакций GTID и требование консистентности (обязателен для корректной работы GTID).master_info_repository = TABLEиrelay_log_info_repository = TABLE– хранение ��лужебной информации репликации в системных таблицах, а не в файлах. Это необходимо, чтобы Orchestrator читал координаты репликации из таблицыmysql.slave_master_info.Режим бинарного лога
binlog_format = ROW. Рекомендуем режим row-based для репликации с GTID.log_slave_updates = ONна реплике (node02), чтобы при переключении ролей новый мастер имел полный журнал.skip_name_resolve = ON. Необязательно, но полезно, чтобы MySQL не задерживался на DNS при подключениях.
Пример конфига для мастера:
Скрытый текст
[mysqld] # --- Основное --- server-id = 1 # Уникальный ID мастера port = 3306 datadir = /var/lib/mysql socket = /var/lib/mysql/mysql.sock pid-file = /var/run/mysqld/mysqld.pid bind-address = 0.0.0.0 # --- GTID-репликация --- gtid-mode = ON enforce-gtid-consistency = ON log-bin = mysql-bin binlog-format = ROW log-slave-updates = ON # Нужно, если этот мастер когда-то был репликой master-info-repository = TABLE relay-log-info-repository = TABLE relay-log-recovery = ON # Защита при сбоях, особенно если был репликой skip-slave-start = 0 slave-net-timeout = 10 # --- Безопасность --- read-only = OFF super-read-only = OFF # --- Надёжность --- innodb_flush_log_at_trx_commit = 1 sync_binlog = 1 # --- Память --- innodb_buffer_pool_size = 5G # Подстрой под объём RAM # --- Monitoring --- performance_schema = ON # --- Сеть --- skip-name-resolve
Пример конфига для реплики:
Скрытый текст
[mysqld] # --- Основное --- server-id = 2 # Уникальный ID реплики port = 3306 datadir = /var/lib/mysql socket = /var/lib/mysql/mysql.sock pid-file = /var/run/mysqld/mysqld.pid bind-address = 0.0.0.0 # --- GTID-репликация --- gtid-mode = ON enforce-gtid-consistency = ON log-bin = mysql-bin binlog-format = ROW log-slave-updates = ON # Чтобы реплику можно было продвигать в мастера relay-log = /var/lib/mysql/mysql-relay-bin relay-log-index = /var/lib/mysql/mysql-relay-bin.index master-info-repository = TABLE relay-log-info-repository = TABLE relay-log-recovery = ON skip-slave-start = 0 slave-net-timeout = 30 # --- Безопасность --- read-only = ON # --- Надёжность --- innodb_flush_log_at_trx_commit = 1 sync_binlog = 1 # --- Память --- innodb_buffer_pool_size = 5G # --- Monitoring --- performance_schema = ON # --- Сеть --- skip-name-resolve
После указания этих настроек перезапускаем MySQL-серверы. На node01 (предполагаемый первоначальный мастер) убедитесь, что read_only = OFF (по умолчанию) — это позволит выполнять записи. На node02 (реплика) установите read_only = ON в конфигурации, чтобы предотвратить нежелательные записи напрямую на реплику. В дальнейшем Orchestrator будет переключать эту настройку при фейловере, делая новый мастер разрешимым на запись, а бывший мастер — только для чтения. Изначально на ��боих узлах можно выставить read_only=1, для мастера временно отключить через консоль при старте либо управлять этим через Orchestrator.
Переходим к настройке репликации с GTID.
Сначала обращаемся к репликации мастер–слейв между node01 (мастер) и node02 (реплика). Предположим, что на node02 БД пустая, и мы можем сделать начальный дамп с node01. Наши шаги:
На
node01создаем пользователя репликации, например:
CREATE USER 'repl'@'node02_host_or_IP' IDENTIFIED WITH mysql_native_password BY 'репликационный_пароль'; GRANT REPLICATION SLAVE ON *.* TO 'repl'@'node02_host_or_IP'; FLUSH PRIVILEGES; (Укажите хост или подсеть, откуда будет подключаться реплика – это IP node02)
Создаем начальную копию данных для
node02. Это можно сделать либо mysqldump-ом (с флагами--master-data=2 --set-gtid-purged=ON), либо с помощью xtrabackup, чтобы не прерывать работу мастера. Важно: реплика стартовала с позицией GTID, актуальной на мастере.Загружаем эту копию на
node02. Затем наnode02настраиваем источник репликации (MASTER) через CHANGE MASTER:
CHANGE MASTER TO MASTER_HOST='node01_host', MASTER_USER='repl', MASTER_PASSWORD='репликационный_пароль', MASTER_PORT=3306, MASTER_AUTO_POSITION=1; Параметр MASTER_AUTO_POSITION=1 включает репликацию по GTID (не указывая файловые координаты).
Запускаем SQL-поток репликации на
node02:START SLAVE;
Убедитесь командой SHOW SLAVE STATUS\G, что реплика подключилась (Both IO and SQL threads running, Slave_IO_Running: Yes, Slave_SQL_Running: Yes).
Теперь займёмся полномочиями для Orchestrator. Он будет подключаться к обоим MySQL-узлам, чтобы мониторить их и при необходимости изменять настройки реплик��ции. Создаём на обоих MySQL-серверах специального пользователя, например, Orchestrator, с необходимыми правами:
CREATE USER 'orchestrator'@'%' IDENTIFIED BY 'StrongPassword'; GRANT SUPER, PROCESS, REPLICATION SLAVE, RELOAD ON *.* TO 'orchestrator'@'%'; GRANT SELECT ON mysql.slave_master_info TO 'orchestrator'@'%'; FLUSH PRIVILEGES;
Эти привилегии соответствуют рекомендациям в документации Orchestrator и позволяют ему читать статус репликации, а также выполнять переключение мастера.
Обратите внимание, что Orchestrator читает информацию о соединении реплики из таблицы mysql.slave_master_info, поэтому мы ранее включили master_info_repository = TABLE – без этого Orchestrator не сможет автоматически выполнять CHANGE MASTER при переключениях.
Примечание инженера: наличие привилегии SUPER у пользователя Orchestrator необходимо для переключения read_only, сброса соединений реплики и подобного, но стоит ограничить доступ этого пользователя только с хоста node03 или конкретной подсети, а пароль задать сложный.
Чтобы минимизировать потерю данных, рекомендуется задействовать Semi-Synchronous Replication (полусинхронную репликацию) между мастером и репликой. В этом режиме мастер будет ждать, пока хотя бы одна реплика подтвердит приём транзакции, перед тем как сообщить приложению об успешном коммите. Это снизит риск потери транзакций, если мастер внезапно выйдет из строя. В MySQL 8.0 полусинхронность реализуется плагином. Шаги на обоих узлах:
· Включите плагин: в my.cnf добавить plugin_load_add = rpl_semi_sync_master=semisync_master.so и plugin_load_add = rpl_semi_sync_slave=semisync_slave.so (или выполнить INSTALL PLUGIN через SQL).
· На мастере (node01) установить:
rpl_semi_sync_master_enabled = ON
rpl_semi_sync_master_timeout = 5000 (например, 5 секунд ожидания подтверждения от реплики)
На реплике (node02) установить:
rpl_semi_sync_slave_enabled = ON.
· Перезапустить MySQL и после этого на текущем мастере выполнить:SET GLOBAL rpl_semi_sync_master_wait_for_slave_count = 1;
Это гарантирует, что мастер будет ждать хотя бы 1 реплику. В нашем случае реплика одна, поэтому 1 и требуется.
После настройки проверьте статус:SHOW STATUS LIKE 'Rpl_semi_sync%';
У мастера параметры Rpl_semi_sync_master_status должны быть в режиме «ON», если реплика подключена: Rpl_semi_sync_master_clients = 1. Это значит, что мастер успешно ждет подтверждения от реплики при коммитах
Механизм не гарантирует нулевых потерь (неподтвержденные транзакции при аварии мастера могут пропасть), но значительно снижает риски.
Итог этапа: кластер готов. Node01 (мастер) и node02 (реплика) синхронизированы через GTID, реплика работает в режиме read_only. Вся нагрузка на запись должна идти строго через VIP, который изначально указывает на node01. Прямые подключения к узлам в обход VIP лишают смысла всю схему отказоустойчивости.
Также стоит отметить нюансы полусинхронной репликации:
При включённой полусинхронной репликации (rpl_semi_sync_master_enabled = ON):
Мастер ждёт подтверждения от реплики при каждом
COMMIT.Если реплика:
перегружена (CPU/диск),
у неё задержка по сети,
relay-log долго записывается,
или просто тормозит
IO thread
мастер зависает на этапе фиксации транзакции.
То есть клиент послал COMMIT, а MySQL не вернёт OK, пока реплика не скажет «я получил».
Хитрый момент:
Даже если SQL thread на реплике тормозит, но IO thread работает, то semi-sync будет считать «всё ок». Подтверждение отправляется после записи в relay-log, а не после применения транзакции. Таким образом мастер думает: «реплика подтвердила». Тем не менее фактически транзакция ещё не применена. Это значит, что реальный lag больше, чем кажется, и при failover вы можете потерять «время применения» даже если запись «была получена».
Настройка Keepalived на узлах — виртуальный IP для автоматического фейловера
Keepalived обеспечит автоматическое переключение виртуального IP-адреса между node01 и node02 в случае сбоя. Приложения будут обращаться к VIP, не зная, какой узел сейчас мастер. Предварительно советуем создать отдельного пользователя без привилегий для скрипта:
CREATE USER 'check_mysql'@'127.0.0.1' IDENTIFIED BY 'SuperSecretPwd';
Начнем с установки Keepalived. Для этого на CentOS 7 через менеджер пакетов набираем: yum install keepalived
Убедитесь, что модуль ядра для VRRP загружен, обычно keepalived сам его использует. После установки у вас получится вот такой путь к конфигу: /etc/keepalived/keepalived.conf.
Теперь выбираем виртуальный IP в вашей сети, который будет использоваться как плавающий, то есть не совпадающий с реальными IP узлом. Предположим, VIP = 10.0.0.100/24 (замените на ваш). Этот IP должен быть доступен и анонсирован в обоих ЦОД, например, в обоих сегментах сети. Если сегменты L2 разные, вам потребуется использовать unicast-режим VRRP или обеспечить маршрутизацию VIP.
Важное примечание : в нашем примере считаем, что VIP может быть поднят на любом узле и будет доступен приложениям независимо от ЦОДа. Это возможно при расширенной L2-сети между площадками либо при использовании динамической маршрутизации (например, BGP) с анонсом VIP. Данный момент необходимо учитывать при сетевом проектировании.
Обращаемся к конфигурации keepalived.conf. Настраиваем идентичный, за исключением приоритетов и роли, конфиг на обоих узлах. Основные элементы конфига:
global_defs (опционально). Можно указать настройки логирования, email-уведомлений и прочего. Мы опускаем их для простоты или указываем пустыми.
vrrp_script — скрипт мониторинга MySQL на локальном узле. Он будет периодически проверять состояние MySQL и при сбое понижать приоритет узла или помечать его как fail. Мы используем утилиту
mysqladmin pingдля проверки. Например:
vrrp_script chk_mysql { script "/usr/bin/mysqladmin ping -h 127.0.0.1 -P 3306 -u check_user > /dev/null 2>&1" interval 2 timeout 1 fall 3 rise 3 }
Здесь mysqladmin ping обращается к локальному серверу MySQL через localhost:3306 под пользователем check_user. Если три проверки подряд вернут ошибку (параметр fall 3), скрипт будет считаться неуспешным, и keepalived понизит приоритет узла. Имейте в виду, что по умолчанию, если weight не указан, keepalived переведёт экземпляр в состояние FAULT при отказе трекаемого скрипта. Параметры rise 3 означают, что для восстановления работоспособности нужно 3 успешных ответа. Интервал проверки — 2 секунды.
Предварительно необходимо в home-директории пользователя настроить файл авторизации /root/.my.cnf с правами 600:
[client] user=check_user password=secret
vrrp_instance VI_1 — описание VRRP-группы. Нам нужно одинаковое имя (
VI_1) на обоих узлах. Здесь указываются: интерфейс, виртуальный маршрутизатор ID, приоритет, список отслеживаемых скриптов/процессов и, собственно, VIP.Важные моменты — пошагово:
o На обоих узлах зададим
state BACKUPи опциюnopreempt. Это нетипичная конфигурация — обычно на мастере ставят MASTER. Но она нужна, чтобы отключить автопереключение — то есть узел с более высоким приоритетом не будет отнимать VIP назад, если восстановится после сбоя. При запуске обоих узлов с состоянием BACKUP keepalived сам определит мастера по приоритету. Более высокий приоритет станет активным мастером. Опцияnopreemptгарантирует, что если узел с большим приоритетом «вернется», а другой уже держит VIP, то VIP останется у текущего мастера до ручного вмешательства. Это соответствует требованию «в случае возврата node01 VIP всё равно не переезжал обратно». В документации отмечено, чтоnopreemptработает, только если оба узла стартуют в BACKUP — мы это выполняем.o
interface— укажите сетевой интерфейс, на котором будет VIP, например,eth0или имя бондинга, в зависимости от вашей конфигурации сети.o
virtual_router_id— произвольный идентификатор VRRP (число 0–255), но одинаковый на обоих. Пусть будет51.o
priority— число 1–254. Уnode01зададим большее значение — 150, уnode02чуть меньше — 100. Это определяет, кто из BACKUP станет активным.node01(150) >node02(100) — значит, при нормальном стартеnode01возьмет VIP.o
advert_int 1— интервал рассылки VRRP-объявлений (1 секунда по умолчанию). Это скорость обнаружения сбоя мастера. С интервалом 1 сек иfaultпри 3 падениях скрипта суммарно переключение займет ~3 секунды в худшем случае. Можно настроить агрессивнее: advert_int 1 и fall 2, тогда ~2 сек.o
authentication— указываем простой пароль для VRRP (типPASSилиAH). Например:
authentication { auth_type PASS; auth_pass MyVRRPpass; }
Пароль не обеспечивает сильной безопасности. При PASS он в открытом виде в пакетах, зато защищает от случайного присоединения лишних узлов.
o virtual_ipaddress — блок, в котором перечислен VIP с маской и, при необходимости, с интерфейсом. Пример:
virtual_ipaddress { 10.0.0.100/24 dev eth0 }
Можно указать label и прочее, но это необязательно. Если интерфейс dev уже задан выше, VIP привязывается автоматически.
track_script — привязка скрипта мониторинга: track_script { chk_mysql }
Это говорит keepalived использовать результат скрипта chk_mysql, описанного выше для изменения состояния. При сбое MySQL на узле keepalived пометит этот узел как FAILED или уменьшит priority на 0, effectively leaving backup role.
Если VRRP-пакеты не могут доставляться между узлами по multicast(например, узлы находятся в разных L2-сегментах или multicast-трафик запрещён / не гарантирован),используйте unicast-режим VRRP. Для этого добавьте в vrrp_instance на каждом узле:
unicast_src_ip <основной_IP_этого_узла> unicast_peer { <основной_IP_другого_узла> }
Например, на node01:
unicast_src_ip 10.0.0.1 # IP node01 unicast_peer { 10.0.0.2 # IP node02 }
И наоборот на node02. Это настроит keepalived отправлять VRRP-пакеты напрямую на адрес соседа по UDP-порту VRRP вместо multicast. В наших разных ЦОД это может понадобиться, если нет общей L2.
Полный пример keepalived.conf для node01 (с IP 10.0.0.1 и VIP 10.0.0.100):
Скрытый текст
! Настройка Keepalived для node01 (мастер) global_defs { router_id NODE01 } vrrp_script chk_mysql { script "/usr/bin/mysqladmin ping -h 127.0.0.1 -P 3306 -u check_user > /dev/null 2>&1" interval 2 timeout 1 fall 3 rise 3 } vrrp_instance VI_1 { state BACKUP nopreempt interface eth0 virtual_router_id 51 priority 150 advert_int 1 authentication { auth_type PASS auth_pass MyVRRPpass } virtual_ipaddress { 10.0.0.100/24 dev eth0 } track_script { chk_mysql } unicast_src_ip 10.0.0.1 # IP node01 unicast_peer { 10.0.0.2 # IP node02 } }
Для node02 (10.0.0.2) конфиг будет почти идентичным, за исключением router_id, priority и строки unicast_src_ip/unicast_peer:
global_defs { router_id NODE02 } vrrp_script chk_mysql { script "/usr/bin/mysqladmin ping -h 127.0.0.1 -P 3306 -u check_user > /dev/null 2>&1" interval 2 timeout 1 fall 3 rise 3 } vrrp_instance VI_1 { state BACKUP nopreempt interface eth0 virtual_router_id 51 priority 100 advert_int 1 authentication { auth_type PASS auth_pass MyVRRPpass } virtual_ipaddress { 10.0.0.100/24 dev eth0 } track_script { chk_mysql } unicast_src_ip 10.0.0.2 # IP node02 unicast_peer { 10.0.0.1 # IP node01 } }
Теперь разберем логику.
При нормальной работе node01 имеет приоритет 150 против 100 у node02, оба запускаются как BACKUP с nopreempt. Keepalived быстро выяснит, что node01 выше, и назначит его владельцем VIP. Если node01 выйдет из строя (сервер выключится или keepalived перестанет слать объявления), node02 через ~3 секунды не получит VRRP-пакетов и присвоит себе VIP. Также, если MySQL на node01 упадет, а сервер жив, то скрипт chk_mysql на node01 начнет возвращать ошибку — keepalived на node01 опустит свой приоритет до 0 и перейдет в состояние FAULT, освобождая VIP. node02 увидит отсутствие активного мастера и захватит VIP. После переключения VIP не вернется автоматически на node01 благодаря nopreempt: даже если node01 восстановится, он останется в пассивном состоянии (BACKUP) с приоритетом 150, но не будет отбирать VIP у node02. Это предотвращает дергание IP при нестабильности узла и поддерживает принцип «failover без автоматического failback».
В конфигурации выше два узла принимают решения на основе локального мониторинга и сигналов VRRP. В случае полной потери связи между ЦОД1 и ЦОД2 (разрыв сети) возможен сценарий, когда node01 и node02 оба решат, что они мастера. Например, если связь между узлами пропала, node02 перестанет получать пакеты от node01 и активирует VIP у себя, считая, что node01 недоступен. Однако node01 может тоже не видеть node02 и продолжать считать себя мастером с VIP. Это особенно актуально при условиях, если сеть разделилась и каждый VIP в своей части сети. Подобные ситуации вызывают split-brain с раздвоением VIP (в разных сегментах) и двумя активными мастерами. Полностью устранить эту проблему на двух узлах сложно, но можно минимизировать:
Внешний маркер доступности. Для этого добавляем вторую проверку, например, пинг до узла-соседа или до стороннего узла. Если
node01не пингуется сnode02или не достигает шлюза, можно запрограммировать, чтобы он снял VIP. Однако такой подход надо применять осторожно. Еслиnode02упал, аnode01просто его не пингует,node01ошибочно сдаст VIP. Классический вариант — третий арбитр (witness node). К сожалению, у нас нет третьего MySQL для кворума, но можно использовать, к примеру, самnode03с Orchestrator как «маяк». Например, дописатьvrrp_script chk_linkпроверяющий доступностьnode03. Еслиnode01потерял связь сnode03, вероятно, он изолирован. Но если потерян только канал между node01 и node02, а Orchestrator в DC2 доступен с node1, то тут есть и другие варианты. В общем, реализация арбитража выходит за рамки простого keepalived.Fencing — отключение проблемного узла. В случае разделения Orchestrator или другая система попытаются «отключить» тот узел, который считают неверным мастером. Так, Orchestrator не умеет напрямую выключать сервер, но может пометить его как read_only. Однако, если разделение сетевое, Orchestrator не сможет связаться с изолированным узлом. Поэтому уповаем на VIP: даже если оба узла считают себя мастерами, VIP все равно не будет одновременно активен в одной подсети. В нашем случае, если сеть разделилась, VIP появится в обоих ЦОД по отдельности. Это плохо, если у приложений тоже разделение — они могут писать в разные мастера, что приведет к рассинхронизации. Важно: чтобы снизить ущерб, все клиенты базы должны обращаться только через VIP, и желательно располагаться в том же ЦОДе, в котором активен мастер, или иметь доступ в резервный ЦОД. Стоит придерживаться организационного решения. Для критичных сценариев после восстановления связи администратор должен оценить, были ли параллельные изменения в обеих половинах, и, возможно, откатить одну из сторон и ресинхронизировать.
Отметим, что настройка nopreempt и read_only на репликах частично смягчает проблему split-brain — если VIP «убежал» на реплику (node02), то на старом мастере (node01) Orchestrator при восстановлении пометит его как read_only, не дав ему принимать запись. Но при полной изоляции node01 этого не случится автоматически. Таким образом, сценарий разделения сети остаётся опасным местом в 2-узловом кластере. Полного автоматического решения без третьего узла нет, но вероятность одновременных записей можно снизить, строго используя VIP и настроив мониторинг сети.
Теперь приступаем к запуску keepalived. Убедитесь, что демоны MySQL уже запущены и репликация работает. Затем включите keepalived на обоих узлах:
systemctl enable keepalived systemctl start keepalived
Через пару секунд на node01 командой ip addr show eth0 проверьте, что VIP-адрес 10.0.0.100 поднят на интерфейсе. На node02 VIP не должен быть виден*. Можно также посмотреть лог /var/log/messages — keepalived пишет переходы статусов.
Лирическое отступление: а если виден, то мы все умрем нужно разбираться, почему все плохо😊
Проверьте, что при выключении MySQL на node01, например, systemctl stop mysqld, VIP автоматически появляется на node02 спустя ~3 секунды. После обратного включения MySQL на node01 и даже перезагрузки node01 – VIP остаётся на node02 благодаря nopreempt. Это то, что нужно.
На этом этапе мы добились отказоустойчивости на уровне IP: один узел выходит из строя — другой прозрачно «наследует» IP, и клиенты переподключатся к нему. Однако сама роль мастера БД ещё не переключилась. Этим займётся Orchestrator.
Установка и настройка MySQL Orchestrator
MySQL Orchestrator — это утилита для управления топологией репликации MySQL, разработанная на Go. Она умеет:
автоматически обнаруживать статус мастера и реплик;
предоставлять Web-интерфейс визуализации;
выполнять автоматическое восстановление при падении мастера (авто-failover) по заданным правилам.
Последний параметр нам особенно важен.
Разворачиваем Orchestrator на отдельном сервере node03 (Oracle Linux 9, аналог RHEL 9). Мы предполагаем, что node03 находится во втором ЦОД, рядом с node02. Это хорошо, так как в случае потери ЦОД1 Orchestrator останется доступен и сможет переключить кластер на реплику.
Замечание инженера. Если упадёт ЦОД2, то упадёт и Orchestrator. В этом случае кластер продолжит работу на node01, но без возможности автоматического фейловера, пока Orchestrator не восстановят. Этот риск мы осознаем в полной мере. В качестве альтернативы мы можем зарезервировать Orchestrator (об этом смотрите ниже про Raft).
Начнем с базы данных backend для Orchestrator. Она хранит информацию о кластере (топология, метрики, история) во внутреннем хранилище. Есть два варианта хранения: встроенная SQLite-база или внешний MySQL instance. Мы можем использовать SQLite, чтобы не поднимать ещё один MySQL. Это упростит настройку — Orchestrator будет сохранять данные в файл (подойдёт для одного инстанса). Альтернатива: запустить на node03 небольшой MySQL- или MariaDB-сервер и создать там базу Orchestrator для бэкенда.
Мы рекомендуем использовать SQLite, так как у нас один Orchestrator. Мы не настраиваем кластеризованный Ochestrator с Raft. SQLite достаточно надёжен для одной ноды и не требует администрирования. Учтите, что Orchestrator — потенциальная единственная точка отказа для автоматического фейловера. Если node03 с Orchestrator будет недоступен, при падении мастера переключение не произойдёт автоматически, придется настраивать вручную. Однако существующие соединения к БД не порвутся, ведь VIP останется на мастере. Поэтому отказ Orchestrator не критичен для работы БД, но его нужно мониторить.
Теперь устанавливаем Orchestrator на node03. Начнем с бинарников. Orchestrator распространяется как rpm-пакет. Для Oracle Linux 9 (RHEL 9) можно использовать пакет из GitHub Releases или репозиториев Percona. Например:
yum install -y https://github.com/github/orchestrator/releases/download/v3.2.6/orchestrator-3.2.6-1.x86_64.rpm
Это установит бинарник /usr/bin/orchestrator и пример конфига. Убедитесь, что также есть и зависимости. Ещё полезно установить jq (JSON parser) для CLI Orchestrator, но это необязательно.
Создаем конфиг. Копируем шаблон: cp /usr/local/orchestrator/orchestrator-sample.conf.json /etc/orchestrator.conf.json
Редактируем /etc/orchestrator.conf.json. Для этого нужно задать параметры:
Соединение к topology вашей кластерной БД:
"MySQLTopologyUser": "orchestrator",
"MySQLTopologyPassword": "StrongPassword",
Здесь указываем логин/пароль, созданные ранее на серверах MySQL (см. шаг 2.3).Orchestratorбудет использовать эти креды для подключения ко всем серверам кластера.Хранилище для
Orchestrator, если используем SQLite:
"BackendDB": "sqlite", "SQLite3DataFile": "/var/lib/orchestrator/orchestrator.db",
Указываем желаемый путь для файла БД. Убедитесь, что Orchestrator имеет права писать туда. Если бы мы использовали MySQL как бэкенд, нужно было бы задать "BackendDB": "mysql" и параметры "MySQLOrchestratorHost": "127.0.0.1", "MySQLOrchestratorDatabase": "orchestrator", "MySQLOrchestratorUser": "...", "MySQLOrchestratorPassword": "..." — это соединение к БД Orchestrator. Но при SQLite эти поля можно оставить как есть.
Фильтр кластеров для автофейловера. По умолчанию Orchestrator не выполняет recovery для всех кластеров — его нужно разрешить. Установим:
"RecoverMasterClusterFilters": [ "*" ],
Этой командой мы задаём автоматическое восстановление мастера для всех кластеров. Так Orchestrator не будет игнорировать наш кластер при сбое.Интервалы мониторинга и таймауты. По умолчанию у нас есть в распоряжении:
"InstancePollSeconds": 5,"RecoveryPollSeconds": 10,— проверка условий failover каждые 10 секунд.
Время можно снизить и до 5 секунд, но в этом особого смысла нет — keepalived уже переключит IP за ~3 сек, Orchestrator через несколько секунд догонит с репликацией.Важно иметь в виду:
Чтобы избежать flapping при неустойчивом канале связи, установим:
"RecoveryPeriodBlockSeconds": 3600.После одного фейловера в течение часа на тот же кластер не запустится повторный автофейловер автоматически — это можно сделать вручную. Подобный механизм защищает от ситуации, когда мастер падает и поднимается попеременно.Действия при failover (hooks). В нашем случае keepalived сам переводит VIP, поэтому Orchestrator не требуется запускать внешний скрипт для VIP. Мы можем не задавать никаких
PostFailoverProcesses— оставим пустым или по умолчанию. Важно лишь, чтобы Orchestrator не пытался сам что-то делать с VIP без явной настройки — по умолчанию Orchestrator только переключает репликацию и статусы БД, DNS/VIP не трогает. При желании можно было бы настроить hooks — например, скрипт, отключающий/включающий keepalived или меняющийread_only. Но, как показала практика, достаточно правильных таймаутов.Опции GTID / Pseudo-GTID. Поскольку у нас GTID включены, Orchestrator будет автоматически использовать метод GTID для репозиционирования реплик. Специально включать
PseudoGTIDне нужно (оставляемAutoPseudoGTID: false или не указываем). Однако, на всякий случай проверим, чтоMasterFailoverUseGTID: true (в новых версиях Orchestrator обычно сам определяет). КонфигурацияPseudoGTIDPatternпо умолчанию пуста: pseudo-GTID отключён, он нам не нужен.Что такое Pseudo GTID?
Это механизм, при котором Orchestrator или другой инструмент вставляет особые метки в бинарный лог MySQL, чтобы имитировать глобальные идентификаторы транзакций. Это использовалось в старых версиях MySQL (5.6/5.7), когда GTID могли быть не включены. В нашем случае GTID работает, поэтому мы не используем pseudo-GTID. На будущее: Orchestrator поддерживает Pseudo GTID — он может автоматически вставлять записи UUID в таблицу, и тогда при фейловере сопоставлять позиции реплик по этим записям.
Отключение автоматического реаттача старого мастера: очень важный параметр:
"ApplyMySQLPromotionAfterMasterFailover": true,По умолчанию
Orchestrator, выполнив failover, оставляет старый мастер в топологии. Если старый мастер «очнулся», он может начать репликацию с нового. Хуже, если новый попытается реплицироваться с ним. Устанавливая этот параметр в true, мы отделяем (detaches) старого мастера после фейловера. На практике это означает вот что: после переключения кластер считаетnode02новым мастером, аnode01(старый) Orchestrator не будет автоматически подключать его обратно и пометит как отключённый. Это предотвратит ситуацию, когда при возвратеnode01вдруг нарушит порядок. По умолчанию в логикеOrchestratorмог оставить конфигурацию, при которой новый мастер числится слейвом старого — это не то, что нам надо. Мы лучше позже вручную присоединимnode01как реплику к новому мастеру, либо настроимOrchestratorсоответствующим образом, о чем скажем ниже.Прочие настройки. Можно включить
HTTPAuthUserиHTTPAuthPasswordдля защиты веб-интерфейса Orchestrator. По умолчанию UI доступен без пароля, но лучше его задать. UI слушает порт 3000. Если нужно сменить, то делаем черезListenAddress: ":3000". Помимо этого, если у вас несколько датацентров, лучше прописатьDataCenterPatternрегэксп для меток (необязательно, косметика — но, например, узлы с именем, содержащимdc1/dc2,можно окрасить).
Проверим, чтоDiscoverByShowSlaveHosts: true,DetectClusterAliasQuery: можно задать запрос, который вернёт имя кластера.
Приведём пример секции конфигурации orchestrator.conf.json, где мы учли самое основное к этому этапу:
{ "Debug": false, "EnableSyslog": true, "ListenAddress": ":3000", "MySQLTopologyUser": "orchestrator", "MySQLTopologyPassword": "StrongPassword", "BackendDB": "sqlite", "SQLite3DataFile": "/var/lib/orchestrator/orchestrator.db", "RecoverMasterClusterFilters": [ "*" ], "RecoveryPeriodBlockSeconds": 3600, "AutoPseudoGTID": false, "MasterFailoverDetachReplicaMasterHost": true, "ApplyMySQLPromotionAfterMasterFailover": true, "DetachLostReplicasAfterMasterFailover": true, "DelayMasterPromotionIfSQLThreadNotUpToDate": true, "StatusEndpoint": "/api/status", "HTTPAuthUser": "orc_admin", "HTTPAuthPassword": "SomePassword" }
Конфиг на прод сервера:
Описание
Общие настройки
Параметр | Описание |
| Включает отладочный режим. |
| Включает логгирование в syslog. Полезно для централизованного логирования. |
| Адрес и порт, на котором запускается веб-интерфейс Orchestrator. |
Подключение к MySQL-нодам (topology)
Параметр | Описание |
| Имя пользователя, от которого Orchestrator подключается к MySQL-нодам (репликам и мастеру). |
| Пароль указанного выше пользователя. |
Хранилище конфигурации Orchestrator
Параметр | Описание |
| Бэкенд-хранилище конфигурации. В вашем случае — |
| Путь до файла SQLite-базы для хранения состояния и конфигурации. |
Мониторинг и работа с топологией
Параметр | Описание |
| Таймаут подключения к MySQL-нодам. |
| Порт по умолчанию для MySQL. |
| Использовать ли |
| Интервал опроса MySQL-нод (в секундах). |
| Через сколько часов забывать ноды, если они не видны. |
| Таймаут ожидания при массовых операциях. |
| Сколько секунд лага считается допустимым. |
| Допустимый лаг при техобслуживании. |
Разрешение имён
Параметр | Описание |
| Метод разрешения имён. |
| Как MySQL возвращает своё имя. |
| Пропустить проверку неразрешимых binlog-серверов. |
| Сколько минут кэшировать разрешение DNS. |
Безопасность
Параметр | Описание |
| Перевести интерфейс Orchestrator в read-only (например, на стендбае). |
| Метод авторизации — в вашем случае |
| Логин для доступа к веб-интерфейсу. |
| Пароль. |
| Пользователи с полным доступом ко всем действиям. |
Логгирование
Параметр | Описание |
| Путь до файла с журналом аудита. |
| Логировать действия пользователей в syslog. |
Failover-логика
Параметр | Описание |
| Какие кластеры допускают автоматический failover. |
| Аналогично, но для промежуточных мастеров. |
| В течение какого времени повторные recovery блокируются. |
| Убирает |
| Отключает потерянные реплики от топологии. |
| Не повышать реплику в мастер, пока SQL-поток не догнал. |
| Удаляет переменные |
| Время простоя для потерянных реплик, после которого они помечаются как недоступные. |
| Задержка восстановления реплики при большом лаге. |
| В случае ко-мастеров продвигается не тот же самый. |
Скрипты действий
Параметр | Описание |
| Скрипты, выполняемые после любого failover. |
| Только после смены основного мастера. |
| Только для промежуточных мастеров. |
Проверка состояния
Параметр | Описание |
| URL для healthcheck-запросов. |
| Упрощённый вывод для мониторингов. |
prod config получился вот такой:
Скрытый текст
{ "Debug": false, "EnableSyslog": true, "ListenAddress": ":3000", "MySQLTopologyUser": "orchestrator", "MySQLTopologyPassword": "StrongPassword", "BackendDB": "sqlite", "SQLite3DataFile": "/var/lib/orchestrator/orchestrator.db", "MySQLConnectTimeoutSeconds": 2, "DefaultInstancePort": 3306, "DiscoverByShowSlaveHosts": false, "InstancePollSeconds": 5, "UnseenInstanceForgetHours": 720, "InstanceBulkOperationsWaitTimeoutSeconds": 10, "ReasonableReplicationLagSeconds": 10, "ReasonableMaintenanceReplicationLagSeconds": 20, "HostnameResolveMethod": "default", "MySQLHostnameResolveMethod": "@@hostname", "SkipBinlogServerUnresolveCheck": true, "ExpiryHostnameResolvesMinutes": 60, "ReadOnly": false, "AuthenticationMethod": "basic", "HTTPAuthUser": "admin", "HTTPAuthPassword": "admin", "PowerAuthUsers": ["admin"], "AuditLogFile": "/var/log/orchestrator-audit.log", "AuditToSyslog": false, "RecoverMasterClusterFilters": ["*"], "RecoverIntermediateMasterClusterFilters": ["*"], "RecoveryPeriodBlockSeconds": 3600, "ApplyMySQLPromotionAfterMasterFailover": true, "DetachLostReplicasAfterMasterFailover": true, "DelayMasterPromotionIfSQLThreadNotUpToDate": true, "MasterFailoverDetachReplicaMasterHost": true, "MasterFailoverLostInstancesDowntimeMinutes": 5, "PostponeReplicaRecoveryOnLagMinutes": 1, "ClusterNameToAlias": { "mysql_node01:3306": "main-cluster" }, "PostFailoverProcesses": [], "PostMasterFailoverProcesses": [], "PostIntermediateMasterFailoverProcesses": [], "StatusEndpoint": "/api/status", "StatusSimpleHealth": true, "AutoPseudoGTID": false }
Теперь запускаем Orchestrator с помощью появившегося сервиса orchestrator.service. Его можно запустить:
systemctl enable orchestrator systemctl start orchestrator
Смотрим лог /var/log/orchestrator.log или journalctl -u orchestrator – здесь должны появиться сообщения об опросе наших серверов. Если всё сделано правильно, Orchestrator автоматически обнаружит топологию: определит, что node01 —мастер, node02 — его реплика. Он получит GTID-сеты, состояния потоков. Чтобы убедиться наверняка, заходим в веб-интерфейс: http://node03:3000 — тут должна отобразиться диаграмма репликации.
Если все-таки Orchestrator не видит сервера, убедитесь, что порт 3306 доступен с node03 до node01/node02 (файрволлы) и что логин-пароль верны. Как вариант — вручную добавляем ноду:
orchestrator -c discover -i node01:3306
После этого Orchestrator подтянет и реплику.
Теперь проверяем функционал с помощью Orchestrator. По команде orchestrator -c topology -i node01:3306 он выведет текущую топологию и статус, или смотрите UI.
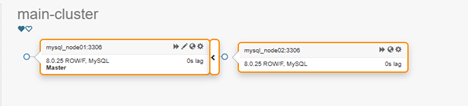
На текущий момент node01 — мастер (read_only=OFF), node02 — реплика (read_only=ON).
Важно: Orchestrator не меняет read_only сам по себе в обычной ситуации. Убедитесь, что node02 действительно read_only (мы ставили в конфиге). Помните, если нет — включаем вручную. Orchestrator отобразит, что у реплики режим read_only (>>), а у мастера << в выводе.
Заключение
Мы развернули двухузловой кластер MySQL с асинхронной репликацией по GTID, улучшенной полу-синхронностью, и добавили два уровня отказоустойчивости:
На уровне сервиса IP –
Keepalivedобеспечивает мгновенное переключение точки входа (VIP) на резервный узел при сбое мастера.На уровне роли БД –
Orchestratorавтоматически продвигает актуальную реплику в мастера и перенастраивает репликацию, тем самым восстановив работу кластера без вмешательства администратора.
Этот подход не требует специальных сборок MySQL – всё на Community Edition. Мы рассмотрели детально настройку Keepalived (особенно режим без preempt для “sticky” фейловера) и Orchestrator (включая интеграцию с GTID и отключение авто-фейлбека старого мастера).
Сценарии, как происходит отказоустойчивое переключение, мы рассмотрим в другом тексте. Пишите в комментариях, получилось или нет. До встречи!
