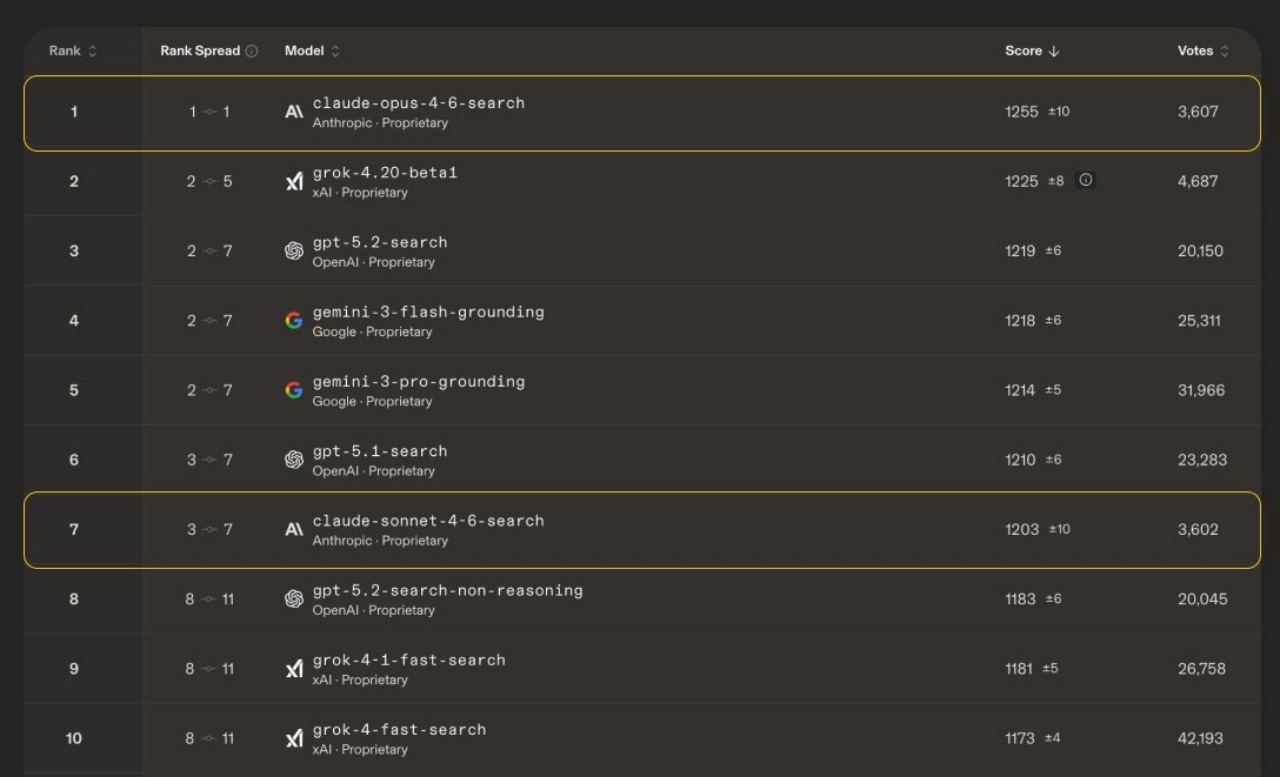
Claude Opus 4.6 от Anthropic занял первое место в категории Search на платформе Arena.ai — бенчмарке, где пользователи вслепую сравнивают ответы ИИ-моделей и голосуют за лучший. Модель набрала 1255 баллов Elo, обойдя Grok-4.20-beta1 от xAI (1225), GPT-5.2-search от OpenAI (1219) и Gemini-3-flash-grounding от Google (1218). Теперь Claude Opus 4.6 лидирует одновременно в трех главных категориях Arena: тексте, коде и поиске.
Младшая модель Anthropic — Claude Sonnet 4.6 — заняла седьмую строчку (1203 балла), расположившись на уровне GPT-5.1-search от OpenAI.
Веб-поиск быстро превращается в ключевое поле конкуренции между ИИ-моделями. ChatGPT обрабатывает более миллиарда поисковых запросов в день, Perplexity за год нарастила аудиторию на 800%, а Google встроил ИИ-генерируемые ответы почти в половину поисковой выдачи. По оценкам аналитиков, на ИИ-поиск уже приходится 12-15% мирового рынка, а трафик из ИИ-платформ конвертируется в покупки в пять раз лучше, чем из классического поиска Google.
В двух других ключевых категориях Arena модель закрепилась еще раньше. В Text Arena, где оценивается качество текстовых ответов, Claude Opus 4.6 Thinking набрал 1496 баллов Elo, обойдя Gemini 3 Pro от Google. В Code Arena, сравнивающей модели на задачах программирования, результат оказался еще убедительнее: разрыв с предшественником Opus 4.5 составил 106 очков. Anthropic при этом удерживает четыре из пяти верхних строчек в рейтинге кода.
P.S. Поддержать меня можно подпиской на канал "сбежавшая нейросеть", где я рассказываю про ИИ с творческой стороны.

