Стоит отметить что оригинальный pivot от Т.Кайта лучше подходит для случаев если вам просто нужно транспонировать таблицу и вы знаете возможный максимум столбцов.
Ухищрение с запросом для столбцов ('select count(distinct trunc(dt)) from actions') может сыграть злую шутку с производительностью. Алиасы, конечно, полезны, но если в них заселектится строка с двойными кавычками, случится фейл.
Да, его вариант в этих случаях гораздо правильнее(не нужно делать лишний запрос), но такие случаи достаточно редки, и хочется большей гибкости. Вообще, наверное, зря я не упомянул, что хотел в свое время добавить условие максимального ограничения для кол-ва столбцов прямо в функцию, но все руки не дотягивались и каждый раз делал в таких случаях просто select case when count(1)<=max_limit then count(1) else max_limit end as max_cols from…
Сомневаюсь, что он появится в DDL, как спрашивает там ТС, но вообще, думаю было бы правильно его стандартизировать, т.к. в тех случаях, когда вся логика в самой базе это было бы удобно и правильно.
Приведите, пожалуйста, в тексте статьи ссылку на оригинальный метод Кайта, чтобы когда из закладок придётся доставать, самому не пришлось искать. Спасибо.
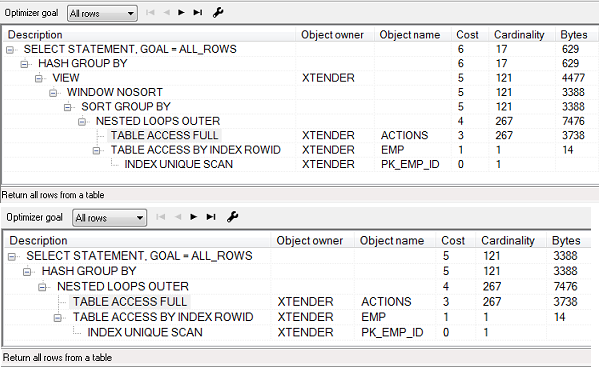
Вы про планы каких запросов? Если из самодельного pkg_pivot, то cost увеличивается всего на 1 из-за dense_rank, а вообще в общем-то неудивительно, что запрос несколько тяжелее(не хуже, чем другие различные функции, вроде row_number,dense_rank и тд).

Функции Oracle 11g Pivot, Unpivot