
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
<?php echo $myObject->getUserHtml(ESC_RAW); ?>
а готовый хтмл передаётся в виде dom-дерева
как в случае безопасных данных программист передаёт ему дерево
$xsl->load( 'tpl.xsl' );
$proc= new XSLTProcessor( );
$proc->importStyleSheet( $xsl );{foreach from=$childs item=child}в каждой итерации происходит включение файла tpl.smarty из ФС сервера. Просмотрев исходный код для XSLT я подобных вещей не обнаружил, как вы этот момент прокомментируете? Оверхэд I/O операций мог дать то самое замедление относительно XSLT.
{include file='tpl.smarty' color=$child.color shape=$child.shape childs=$child.childs}
{/foreach}
смарти настолько «умный» что загружает шаблон каждый раз заново?Судя по коду, нет, но должен быть выставлен параметр ['smarty_once'], если есть — то файл грузится как include_once, если нет, то как include.
ковыряться с настройкой частичного кэширования и инвалидациейВы так говорите, как будто это что-то плохое. Профит на выходе может оказаться намного выше, в прямопропорционально нагрузке на ваш проект.
{function name="tree"}
{foreach $pages as $page}
<li>
<span>{$page.name}</span>
{if $page.childs}<ul>{tree pages=$page.childs}</ul>{/if}
</li>
{/foreach}
{/function}
<ul id="pages-tree" class="filetree">
{tree pages=$tree}
</ul>
включите кеширование
<code>
<xsl:template match="a[not(starts-with(@href, 'http://our-domain') and starts-with(@href, 'http://')]">
<a href="http://our-domain/our-regirect-script?p={@href}">
<xsl:apply-templates/>
</a>
</xsl:template>
</code>function akeurwbkurlycqvaelkuyrc( $data )
Strict Standards: date() [function.date]: It is not safe to rely on the system's timezone settings. Please use the date.timezone setting, the TZ environment variable or the date_default_timezone_set() function. In case you used any of those methods and you are still getting this warning, you most likely misspelled the timezone identifier. We selected 'Europe/Moscow' for 'MSD/4.0/DST' instead in /home/grey/domains/softcoder.ru/public_html/system/libraries/loger.php on line 15
Strict Standards: is_a(): Deprecated. Please use the instanceof operator in /home/grey/domains/softcoder.ru/public_html/system/libraries/page.php on line 24
{function name="tree"}
<div style="color:{$color|escape}">{$color|escape} {$shape|escape}</div>
<blockquote>
{foreach $childs as $child}
{tree color=$child.color shape=$child.shape childs=$child.childs}
{/foreach}
</blockquote>
{/function}
{tree color=$color shape=$shape childs=$childs}preprocessing: 1.98510742188
templating: 183.681152344
total: 185.666259766
preprocessing: 1.97705078125
templating: 36.2878417969
total: 38.2648925781
smarty 3 rc2
Our preliminary performance tests are already showing us very promising speed improvements over Smarty 2 (2-5x on average), and we're not done!
$xsl = new DOMDocument();
$xsl->loadXML(file_get_contents('layout.xsl'));
$xsl->xinclude();
$xslt = new XSLTProcessor;
$xslt->importStyleSheet($xsl);
echo $xslt->transformToXML($data);для всех shapes кроме rectangle. Для последнего нужно использовать div
'blue', 'yellow', 'magenta', 'cyan' должны быть жирными, остальные нормальным текстом

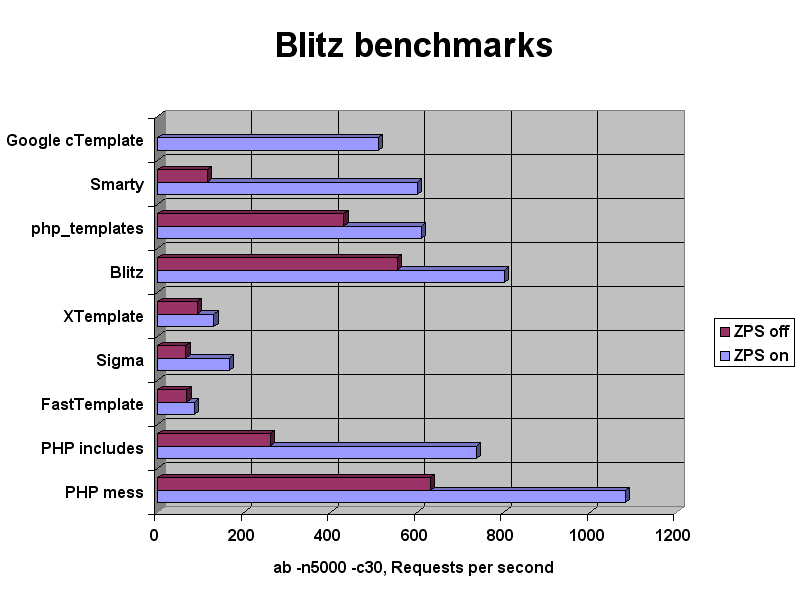{kind=link}
Smarty против XSLT