..it is true that asking regexes to parse arbitrary HTML is like asking Paris Hilton to write an operating system..
Последние версии языка Nemerle включают в состав библиотеку для разбора языков, грамматика которых принадлежит классу PEG.
Что такое PEG?
В отличии от других инструментов для создания парсеров, PEG описывает не грамматику, а стратегию её разбора, но фактически описание стратегии разора является описанием грамматики. Для парсера описанного с помощью PEG существует алгоритм (packrat), разбирающий любой текст, удовлетворяющий грамматике из этого класса, за линейное время от длинны текста.
Класс языков, которые можно разобрать с помощью парсеров описанных подобным образом, достаточно широк, чтобы покрыть популярные языки программирования (например, C#) и языки разметки. Очевидно, что он покрывает всю функциональность регулярных выражений.
Зачем что-то нужно, когда есть RegExp?
Библиотеки для работы с регулярными выражениями включены в набор стандартных библиотек практически любого языка программирования. Из-за такой шаговой доступности их используют там, где это уместно (разбор регулярных грамматик), и там, где нет (разбор html и других рекурсивных структур).
Цитата с stackoverflow:
..it is true that asking regexes to parse arbitrary HTML is like asking Paris Hilton to write an operating system..
Другой крайностью являются генераторы парсеров, например, yacc и antlr. Они справляются с задачей генерацией парсеров по предоставленной грамматике, но на практике случается, что программисту «проще» написать парсер самому, чем использовать их. Причина этого, скорее всего, в сложности работы с этими инструментами, а так же в том, что, в отличии от регулярных выражений, которые являются eDSL, работа с ними требует кодогенерации, а кодогенерация неудобна.
За генерацию парсера по PEG грамматике в Nemerle отвечает макрос. Таким образом исчезает кодогенерация и работа с нерегулярными грамматиками превращается в работу с eDSL: к мощи генерации парсеров прибавляется шаговая доступность регулярных выражений. Рассмотрим пример работы с PEG в Nemerle
Разбор математической разметки языка TeX
Рассмотрим PEG грамматику на примере грамматики математической разметки TeX. Будем разбирать исходник этой картинки
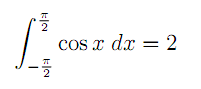
Вот он
\int_{-\frac{\pi}{2}}^{\frac{\pi}{2}} \cos x \; dx = 2Видно, что он состоит из команд (\int, \pi, \cos), escape последовательности (\;), вложенной скобочной структуры ({..{..}..}) и всего остального.
Прежде всего определим структуру, в которую будет разбираться данный текст:
public variant WordTexAst
{
| Command { name : string } // команды
| Escape { symbol : string } // escape последовательности
| Group { data : WordTexAst.Sequence } // вложенная скобочная структура
| Data { data : string } // все остальное
| Sequence { words : list[WordTexAst]}
}Я использовал варианты, в других языках программирования они так же известны как алгебраические типы данных или размеченные объединения.
Для того, чтобы создать парсер языка, нужно объявить класс, описать стратегию разбора языка в атрибуте этого класса и каждому правилу разбора сопоставить функцию, строящую дерево по разобранной информации. Начнем с атрибута
[PegGrammar(ast,
grammar
{
commandName = ['a'..'z','A'..'Z']+;
escapeLetter = ';' / ',';
letter = ['a'..'z','A'..'Z','0'..'9'] / '^' / '_' / '=' / ' ' / '-' / '+' / '/' / '(' / ')' / '[' / ']';
command : WordTexAst = '\\' commandName;
escape : WordTexAst = '\\' escapeLetter;
group : WordTexAst = '{' ast '}';
data : WordTexAst = letter+;
word : WordTexAst = command / escape / group / data;
ast : WordTexAst.Sequence = word+;
})]Первый параметр макроса — правило, с какого следует начать разбор. Затем — описание грамматики (стратегии), которое очень напоминает форму Бэкуса — Наура. В левой колонке — определяемое правило, за ним — тип структуры, разбираемый этим правилом. В первых трех случаях он опущен, так как эти правила выполняют роль констант для остальных правил. После знака равенства описывается структура разбираемого текста, она может быть задана через константы и другие правила, разделенные пробелом. Для описания структуры можно использовать спец символы, например, '+' — применить правило один или более число раз, 'a / b' означает применить правило разбора 'a', если оно не подойдет, то правило разбора 'b'. Важно, что этот оператор 'или' не коммутативен, если первое правило разбора применяется успешно, то альтернатива не рассматривается.
Помимо атрибута, нужно добавить в класс парсера несколько методов — по одному на каждое правило разбора. Количество аргументов и их тип должны соответствовать правилам, которые используются данным правилом в правой части (после знака равно).
Полный пример кода парсера:
[PegGrammar(ast,
grammar
{
commandName = ['a'..'z','A'..'Z']+;
escapeLetter = ';' / ',';
letter = ['a'..'z','A'..'Z','0'..'9'] / '^' / '_' / '=' / ' ' / '-' / '+' / '/' / '(' / ')' / '[' / ']';
command : WordTexAst = '\\' commandName;
escape : WordTexAst = '\\' escapeLetter;
group : WordTexAst = '{' ast '}';
data : WordTexAst = letter+;
word : WordTexAst = command / escape / group / data;
ast : WordTexAst.Sequence = word+;
})]
public class TexParser
{
private escape(_ : NToken, symbol : NToken) : WordTexAst
{
WordTexAst.Escape(GetText(symbol))
}
private command(_ : NToken, commandName : NToken) : WordTexAst
{
WordTexAst.Command(GetText(commandName))
}
private group(_ : NToken, ast : WordTexAst.Sequence, _ : NToken) : WordTexAst
{
WordTexAst.Group(ast)
}
private data(arg : NToken) : WordTexAst
{
WordTexAst.Data(GetText(arg))
}
private word(arg : WordTexAst) : WordTexAst { arg }
private ast(data : List[WordTexAst]) : WordTexAst.Sequence
{
WordTexAst.Sequence(data.ToList())
}
}Не был описан еще тип NToken. Это класс, который соответствует подстроке в разбираемом тексте, удовлетворяющей «константному» правилу. Перевести объект этого класса в строку можно с помощью метода GetText.
Осталось продемонстрировать использование парсера:
def parser = TexParser();
def text = @"\int_{-\frac{\pi}{2}}^{\frac{\pi}{2}} \cos x \; dx = 2";
def (pos,ast) = parser.TryParse(text);
when (pos == text.Length) Console.WriteLine("success");Метод TryParse производит разбор текста, pos содержит число разобранных символов, если строка разобрана полностью, то pos равен длине строки, если разобран только префикс, то pos содержит длину префикса.
Заключение
В статье рассмотрен eDSL для построения парсеров PEG грамматик. Помимо построения парсеров рекурсивных языков, его можно использовать для разбора регулярных грамматик, в том случае когда регулярное выражение получается слишком сложным для работы с ним.
Данный eDSL реализован в виде макроса, который на этапе компиляции раскрывается в эффективный алгоритм разбора. Полученная dll может быть использована в любом .net языке. Таким образом использование данной библиотеки не ограничено одним языком.
Ссылки
Текущая версия Nemerle
Форум на rsdn.ru (русский)
Google группа (английский)

