
Я, конечно, ожидал, что предыдущий пост понравится людям, но я даже представить не мог, насколько. Данный пост, на мой взгляд, одновременно и более и менее интересный, чем предыдущий. В то время, как в прошлый раз это было увлекательная казуальная игра — совершенно бессмысленная и отнимающая кучу времени, но доставляющая удовольствие своим необычным геймплеем и, самое главное, интерактивная и доступная каждому желающему, то сейчас речь скорее о детективном рассказе — позволяющем сопереживать и пытаться угадать дальнейшее развитие сюжета, но не оставляющем места интерактивности. С другой стороны, «детектив» «основан на реальных событиях», что добавляет происходящему особого шарма.
А началось все с вопроса в Q&A.
Для тех, кому лень ходить по ссылкам, позволю себе процитировать сам вопрос:
Собственно, иногда при открытии «Мой компьютер» со списком дисков или при вставке флешки/DVD компьютер просто намертво замирает (мышка не двигается, клавиатура не реагирует на NumLock), т.е. полное отсутствие реакции на внешние раздражители. Спустя секунд 10-30 комп сам отмирает, как будто ничего и не было. Вопрос собственно в том, как определить причину такого подвисания системы и как с этим бороться.
Ну и дополнительная информация: аппаратный RAID 4x640 (зависть), обновление дров не помогает, SMART молчит, тесты тоже.
Как писал один очень хороший человек: «Местные избегают ездить в пустыню летом по трём причинам. Гремучие змеи, клещи и скорпионы. Идея! – подумал я. У меня же как раз есть палатка.»
Первая идея: кто-то принимает прерывание и решает «передохнуть» в ISR. Также возможно, что этот кто-то просто задирает IRQL до непотребного уровня и все так же решает «передохнуть». Ловить будем при помощи все того же xperf.
xperf -on latency -stackwalk profile -maxfile 128 -filemode circular
Пояснения:
Включаем latency — что ж еще нам включать для отлова задержек. Как говорит нам «xperf -providers K»:
Latency: PROC_THREAD+LOADER+DISK_IO+HARD_FAULTS+DPC+INTERRUPT+CSWITCH+PROFILE
Другими словами, к обязательным PROC_THREAD+LOADER, необходимым для того привязки происходящего к собственно бинарникам, добавляются DISK_IO+HARD_FAULTS, которые в моем личном топе занимают первое место по убиванию производительности любой системы (похоже в Microsoft со мной солидарны), DPC+INTERRUPT — доставляют проблемы нечасто, но уж если доставляют, то «с душой», CSWITCH — context switch — для отслеживания дедлоков и неправильных приоритетов, ну и PROFILE — события profile interrupt (по умолчанию каждую миллисекунду)
Есть все основания полагать, что профайл прерывание все еще будет доставляться даже если все остальное в системе не подает признаков жизни. Вот список предопределенных IRQL в винде:
#define PASSIVE_LEVEL 0 #define LOW_LEVEL 0 #define APC_LEVEL 1 #define DISPATCH_LEVEL 2 #define PROFILE_LEVEL 27 #define CLOCK1_LEVEL 28 #define CLOCK2_LEVEL 28 #define IPI_LEVEL 29 #define POWER_LEVEL 30 #define HIGH_LEVEL 31
Выше profile только часы, межпроцессорные прерывания и прерывания электропитания. Ни одно из этих прерываний не отдается на откуп third-party драйверам, соответственно, если profile interrupt окажется замаскированным — это тоже сильно сузит пространство поиска.
"-stackwalk profile" означает, что для каждого события PROFILE будет сниматься еще и полный стектрейс. Кто хоть раз пользовался sampled profiler-ами сразу оценит эту возможность: ну и что, что 90% времени мы провели в каком нибудь спинлоке — нам важно знать, КТО дернул этот спинлок.
"-maxfile 128 -filemode circular" — знакомая любому программисту идея циклических буферов. Так как зависания происходят раз в день-два, а информации каждую секунду генерируется около мегабайта, то собирать полный лог за это время места может и хватит (4x640, чо), но вот открыть (или тем более переслать) для анализа будет уже труднее.
Силки расставлены — ждем. Первая жертва попалась через 4 дня:
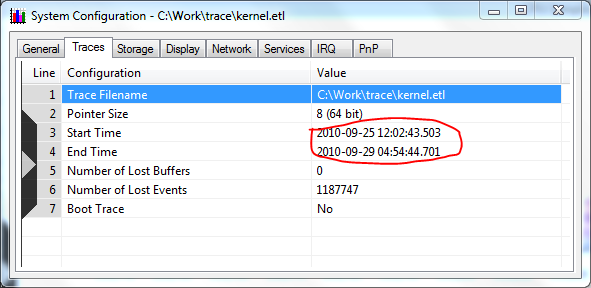
И выглядело это так:
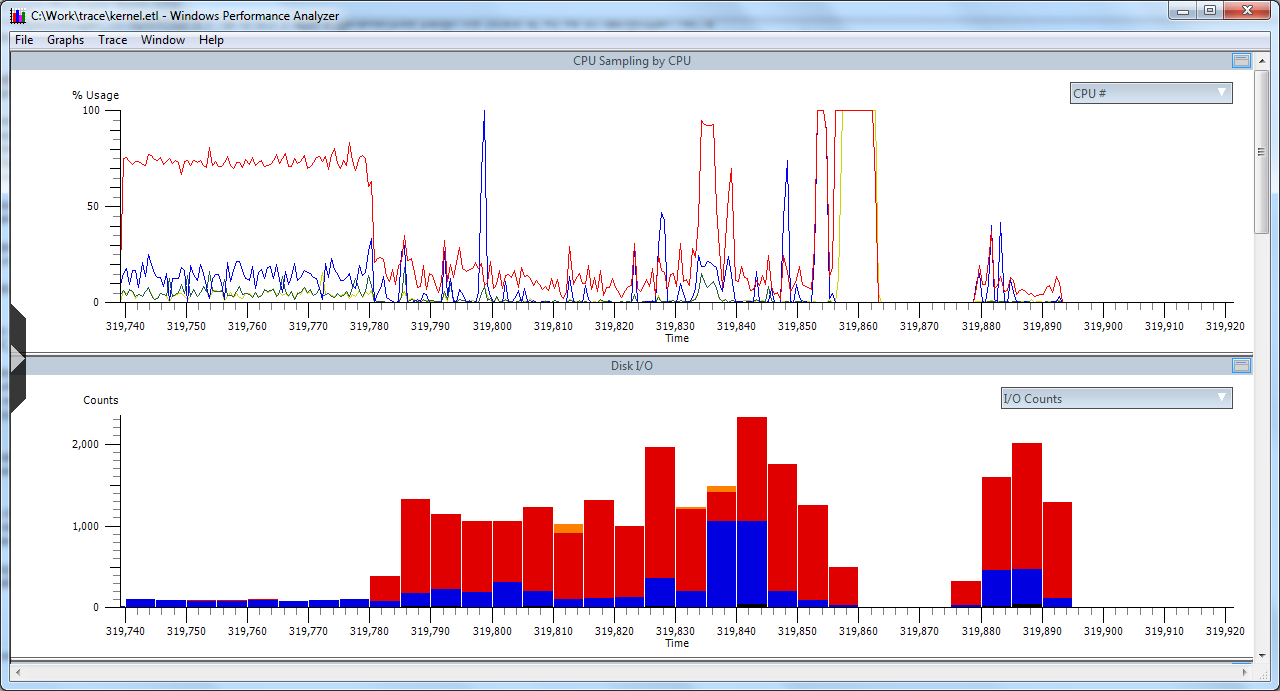
Более того, по странному совпадению
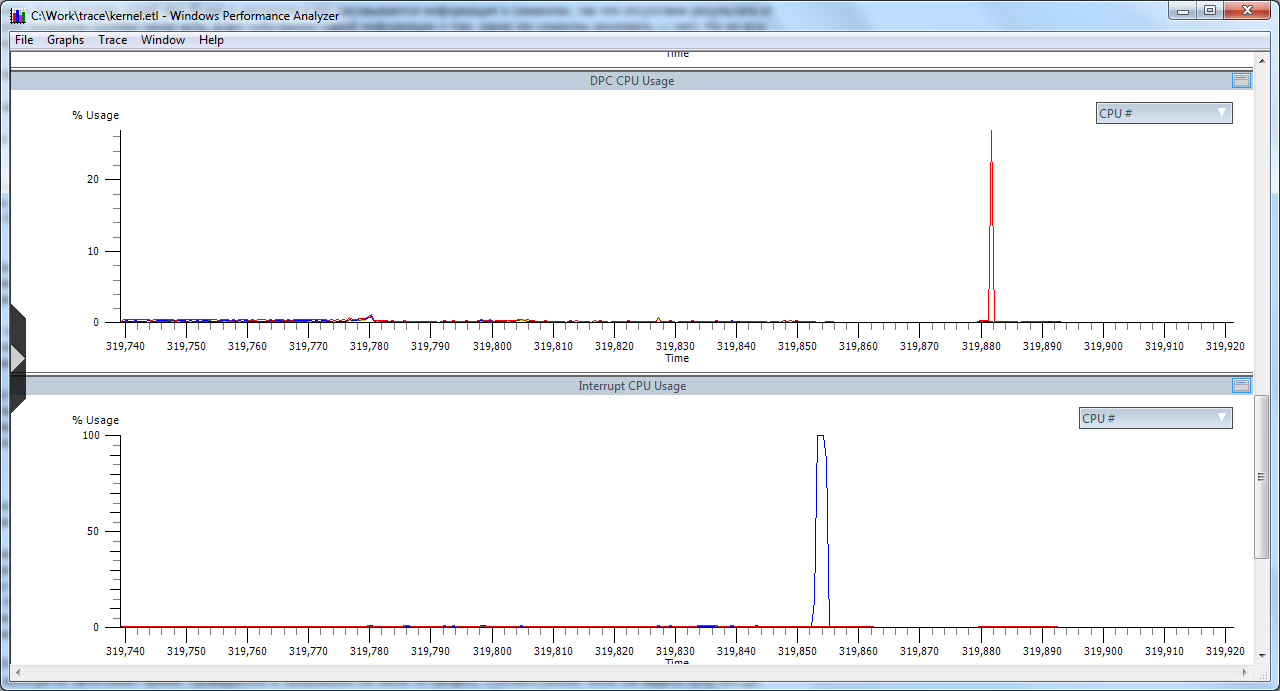
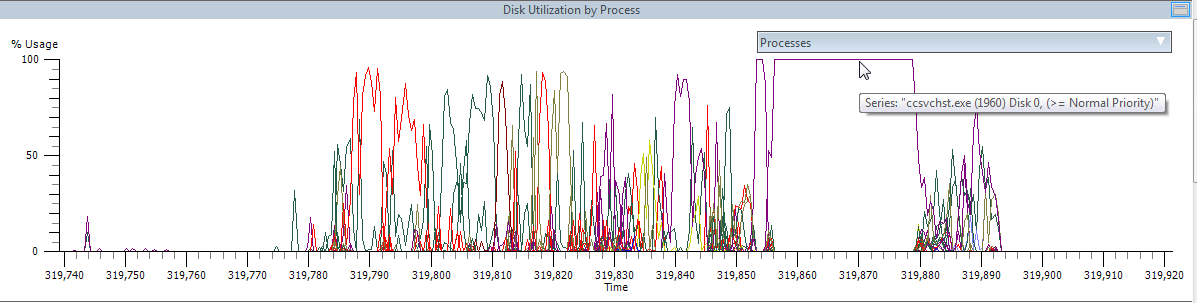
Добегался, подумал я и полез в поиск

Воображение живо нарисовало картину, в которой прерывание для каких то там целей сериализуется и доставляется на обработку в пользовательский процесс (такое в принципе можно реализовать на многопроцессорных системах, что же до идиотизма подобного решения — ну люди они такие — любят писать всякое непотребство). К чести пользователя Mear, он не стал сразу же сносить NIS и тут я заметил одну деталь с самого первого скриншота: 1.2 миллиона потерянных событий. Разрыв в графиках — это не отсутствие активности, а переполнение буферов и затирание их новыми данными при отсутствии возможности сбросить буферы на диск (может кто то задержался в прерывании от диска или каким то образом заблокировал I/O manager).
Ну что ж, раз система в конце концов «отмирает» — наша задача складывать все в память до тех, пока не появится возможность сбросить все на диск:
xperf -on latency -stackwalk profile -maxfile 256 -filemode circular -buffersize 1024 -minbuffers 256
Добавляем размер буфера и минимальное количество буферов. Ждем. Через день получаем красивый лог без потерь:
К сожалению «мои глаза и руки» на той стороне замешкались с остановкой трейса и начали просматривать не останавливая и чуть не потеряли собственно сам проблемный момент. Но к счастью, информации оказалось достаточно (на графике видно постепенно выходящий за пределы циклического буфера всплеск обработчиков DPC)
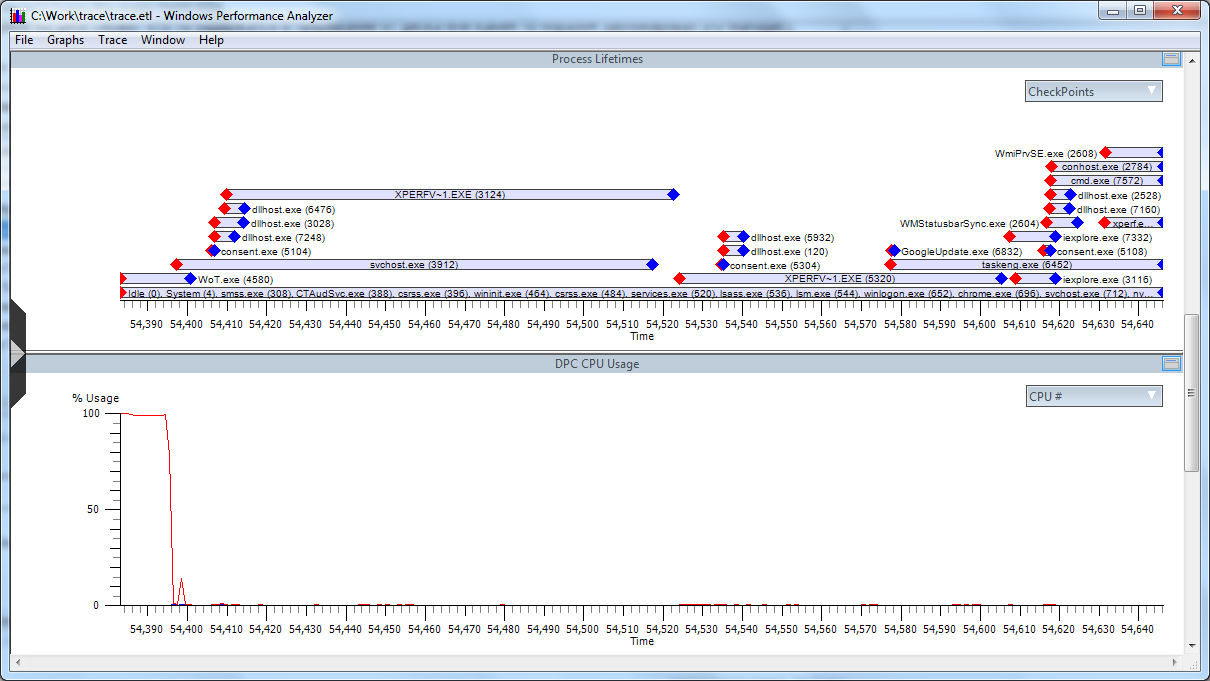
Ну что ж, делаем zoom на проблемную область и начинаем исследование.
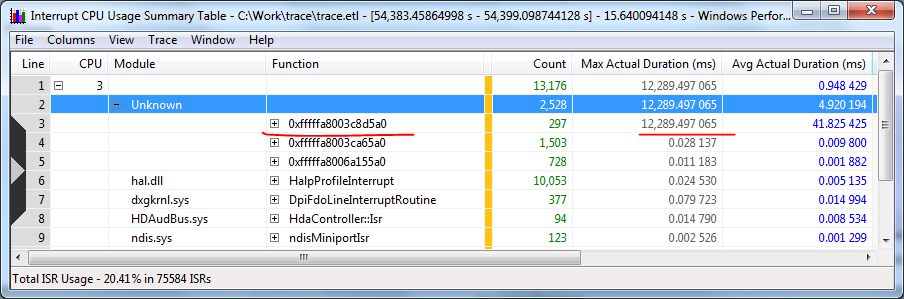
Прежде всего видим ISR, занявшую 12 секунд
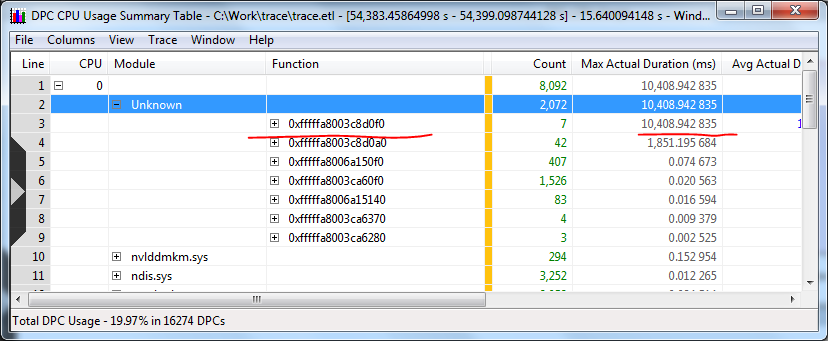
И DPC, занявшую 10
К сожалению, по проблемному адресу не получается найти модуль, но я же не зря в самом начале расписывал прелести stackwalk-а:
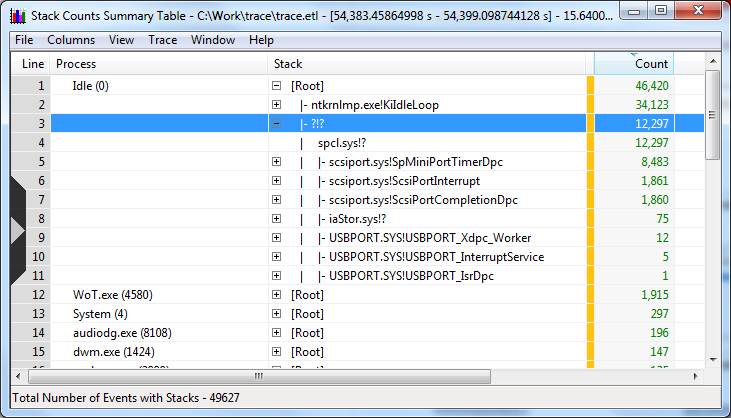
Здесь на самом дне стека видим «unknown» адрес-заглушку, которая вызывает spcl.sys, который в свою очередь вызывает уже непосредственно scsiport. Разворачиваем стек дальше:
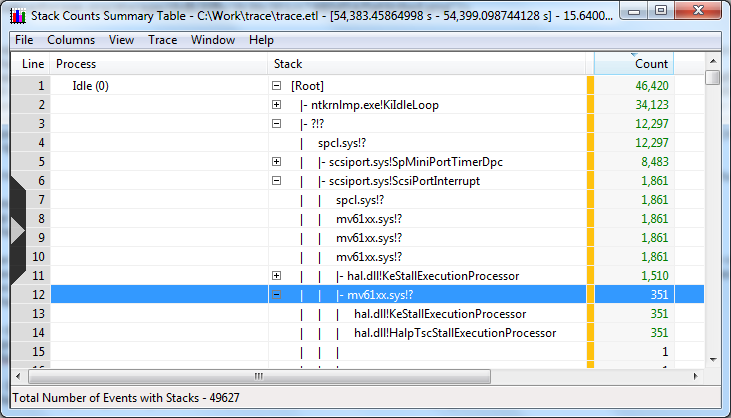
Еще раз заходим в spcl.sys, оттуда попадаем в mv61xx.sys, который зовет KeStallExecutionProcessor (SRSLY? В ОБРАБОТЧИКЕ ПРЕРЫВАНИЯ?). По другому пути мы проводим на один вызов больше в mv61xx и все так же начинаем отдыхать.
Аналогичная картина выходит и при обработке DPC (хотя это уже не так критично для многопроцессорной системы):
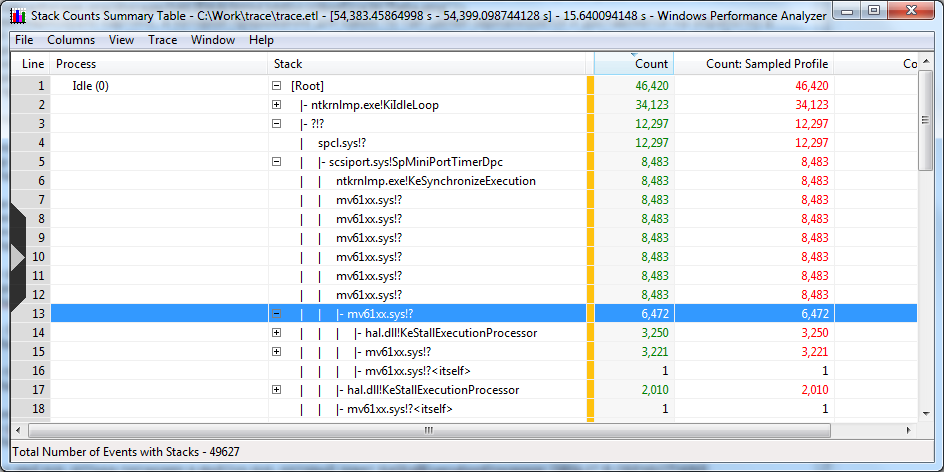
Пара минут поиска выводит нас на авторов spcl и mv61xx — это SPTD (использующийся в Daemon Tools и Alcohol xxx%) и драйвер Marvell-овской железки. Вот эти:

Для начала апдейт драйвера железки и выключение sptd — проблемы прекратились. Осторожно включаем sptd обратно: две недели — полет нормальный.
PS: Данный пост был бы невозможен без Mear. Он предоставил проблемную систему для бесчеловечных экспериментов и всячески помогал мне в нахождении этой проблемы.

