В последнее время предпринимаются многочисленные попытки разработать эффективный алгоритм для выявления сообществ в социальных сетях из миллионов узлов, которые невозможно визуализировать или анализировать на уровне отдельных узлов.
Бельгийские разработчики представили новый алгоритм, который превосходит все существующие аналоги по вычислительной скорости. Вследствие этого его можно применять на базах беспрецедентного размера: анализ типичной сети из 2 млн нодов занимает 2 минуты. Он получил название Лувенский метод (Louvain Method), поскольку создан в то время, когда все разработчики трудились в Лувене (Бельгия).
Лувенский метод доказал свою точность при тестировании на сетях с известной структурой сообществ, где можно было проверить результат. Благодаря своей иерархической структуре он подходит для анализа сообществ в различных масштабах. В частности, его проверяли также для сообществ в сети бельгийского оператора мобильной связи (2,6 млн абонентов) и на базе веб-страниц, собранной краулером Stanford WebBase (118 млн узлов и более 1 млрд ссылок).
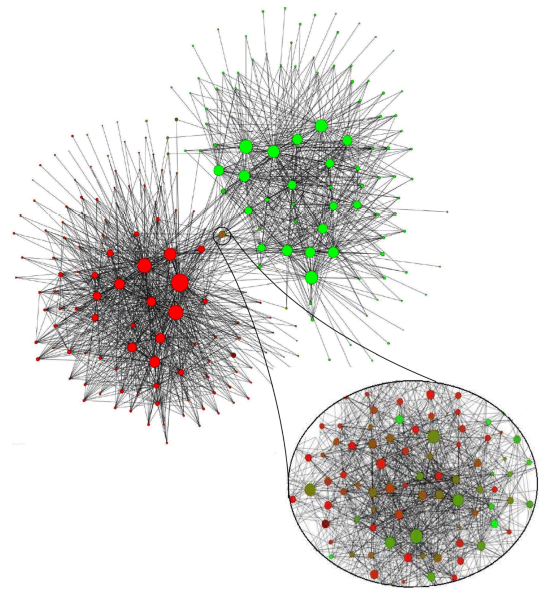
Результат анализа базы абонентов в сети бельгийского оператора сотовой связи. Красным цветом отмечены сообщества, разговаривающие на французском языке, зелёным — на голландском. Зуммирован участок «промежуточных» сообществ, которые общаются на обоих языках. В этом масштабе отображены группы людей более 100 человек.
Метод состоит из двух стадий. На первой происходит поиск «малых» сообществ путём оптимизации модульности на локальном уровне. На второй стадии узлы одного сообщества агрегируются и строится новая сеть большего масштаба, после чего эти стадии повторяются до тех пор, пока не будет достигнут максимальный уровень модульности.
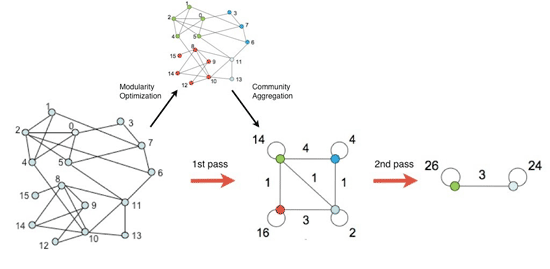
Таким образом, после каждого этапа программа отображает сообщества всё большего масштаба.
Более подробная информация приведена в статье Fast unfolding of communities in large networks. Например, там содержится таблица качества и скорости работы алгоритма по сравнению с алгоритмами Clauset/Newman/Moore, Pons/Latapy и Wakita/Tsurumi. Для каждой задачи указан уровень модульности и время выполнения на машине Opteron 2,2 ГГц с 24 ГБ RAM (прочерк, если время превышает 24 часа). Судя по результатам, Лувенский метод буквально не имеет себе равных.

Программа на C++ и matlab распространяется бесплатно.
Бельгийские разработчики представили новый алгоритм, который превосходит все существующие аналоги по вычислительной скорости. Вследствие этого его можно применять на базах беспрецедентного размера: анализ типичной сети из 2 млн нодов занимает 2 минуты. Он получил название Лувенский метод (Louvain Method), поскольку создан в то время, когда все разработчики трудились в Лувене (Бельгия).
Лувенский метод доказал свою точность при тестировании на сетях с известной структурой сообществ, где можно было проверить результат. Благодаря своей иерархической структуре он подходит для анализа сообществ в различных масштабах. В частности, его проверяли также для сообществ в сети бельгийского оператора мобильной связи (2,6 млн абонентов) и на базе веб-страниц, собранной краулером Stanford WebBase (118 млн узлов и более 1 млрд ссылок).
Результат анализа базы абонентов в сети бельгийского оператора сотовой связи. Красным цветом отмечены сообщества, разговаривающие на французском языке, зелёным — на голландском. Зуммирован участок «промежуточных» сообществ, которые общаются на обоих языках. В этом масштабе отображены группы людей более 100 человек.
Метод состоит из двух стадий. На первой происходит поиск «малых» сообществ путём оптимизации модульности на локальном уровне. На второй стадии узлы одного сообщества агрегируются и строится новая сеть большего масштаба, после чего эти стадии повторяются до тех пор, пока не будет достигнут максимальный уровень модульности.

Таким образом, после каждого этапа программа отображает сообщества всё большего масштаба.
Более подробная информация приведена в статье Fast unfolding of communities in large networks. Например, там содержится таблица качества и скорости работы алгоритма по сравнению с алгоритмами Clauset/Newman/Moore, Pons/Latapy и Wakita/Tsurumi. Для каждой задачи указан уровень модульности и время выполнения на машине Opteron 2,2 ГГц с 24 ГБ RAM (прочерк, если время превышает 24 часа). Судя по результатам, Лувенский метод буквально не имеет себе равных.
Программа на C++ и matlab распространяется бесплатно.

