Оптимизация явно не является коньком MySQL сервера. Цель данной статьи объяснить разработчикам, которые плотно не работают с базами данных и иногда не понимают, по какой причине запрос, который успешно отрабатывает в других СУБД, в MySQL безбожно тормозит, каким образом оптимизируется конструкция between в MySQL.
MySQL использует rule based оптимизатор. Зачатки cost based оптимизации в нем конечно присутствуют, но не в должной мере, в какой их хотелось бы видеть. По этой причине часто мощности получаемых после применения фильтров множеств вычисляются неверно. Это приводит к ошибкам оптимизатора и выбору неверного плана выполнения. При чем полученные between оптимизации невозможно изменить явным указанием: индексов для выполнения запроса и порядка соединения таблиц.
Чтобы понять суть бага сформируем тестовый набор данных в размере 125 миллионов записей.
Таблица attributes по сути является справочником, для big_table а так же содержит две колонки ограничивающие интервал дат одним месяцем.
Для каждого attr_id в большой таблице содержится 250 000 записей. Попробуем узнать сколько записей содержится в big_table с учетом дат заданных таблицей attributes для аттрибута один.
Получаем порядка 500 записей (время выполнения запроса ничтожно мало и составило 00.050 секунды). Логично предположить, что так как данные распределены одинаково для всех значений аттрибутов, то при соединении с таблицей attributes заместо явного указания бинд переменных время запроса должно увеличится незначительно, и составить не более 25 секунд. Что ж проверим:
Время выполнения: более 15 минут (на этой отметке я прервал выполнение запроса). Отчего же так получется? Все дело в том, что MySQL не поддерживает динамическое ранжирование о чем нам и говорит бага #5982 созданная ещё в далеком 2004 году. Посмотрим план выполнения:
План явно показывает, что идет полное сканирование таблицы в 125 миллионов записей. Странное решение. Исправить ситуацию не поможет и straight_join для смены порядка джойна ни force index для явного указания использовать индекс. Все дело в том что в лучшем случае мы получим план вида:
Который говорит нам о том, что таблица big_table будет сканироваться по нужному индексу, но индекс будет задействован неполностью, то есть из него будет использоваться только первая колонка. В некоторых, вырожденных случаях, мы сможем добиться нужного нам плана и полного использования индекса, однако, ввиду непостоянства оптимизатора и невозможности применения данного решения (не буду приводить здесь его код, оно не работает в 90% случаев) во всех 100% случаев, нужен иной подход.
Данный поход предлагает нам сам MySQL. Будем явно указывать bind переменные. Конечно для ряда задач это не всегда эффективно, так как бывает, что полное сканирование проходит быстрее чем индексное, но явно не в нашем случае когда надо выбрать 500 записей из 250000. Для решения задачи нам потребуется создание следующей процедуры.
Т.е. мы в начале открываем курсор по пятистам записям таблицы аттрибутов, и для каждой строки данной таблицы делаем запрос из big_table. Посмотрим на результат:
Время выполнения: 0:00:05.017 имхо результат гораздо лучше. Не идеально, но зато работает.
Теперь можно рассмотреть обратный пример, когда поиск производится не в таблице «транзакций», а наоборот в таблице фактов.
Данная бага проявляется если вы:
— работаете с базой GeoIP
— пытаетесь проанализировать расписание
— фиксируете рейты валют на Forex
— вычисляете город по номерной емкости оператора
и т.д.
Для начала создадим тестовый набор данных из 25 миллионов строк.
Получим таблицу вида
И с ходу попробуем выполнить запрос, который успешно оптимизируется всеми СУБД за исключением MySQL:
Время выполнения: 0:00:22.412. Вообще не вариант с учетом того, что мы то знаем, что такой запрос должен вернуть одну уникальную строку. И чем выше значение выбранной вами переменной — тем больше записей будет просканировано, время работы запроса растет экпоненциально.
Сам MySQL для решения данной проблемы предлагает следующий workaround:
Время выполнения: 0:00:00.350. Неплохо. Но данное решение имеет ряд недостатков, в частности, вы не сможете производить join с другими таблицами. Т.е. данный запрос может существовать исключительно атомарно. Для возможности джойнов воспользуемся стандартным решением RTree индексами (если конечно ваш справочник не нуждается в транзакциях или же вы обеспечите его целостность триггерами, так как данный тип индексов по прежнему работает только для MyISAM). Для тех кто не в курсе, что такое геометрические объекты в MySQL приведу иллюстрацию того, что обычно делают в таких случаях:
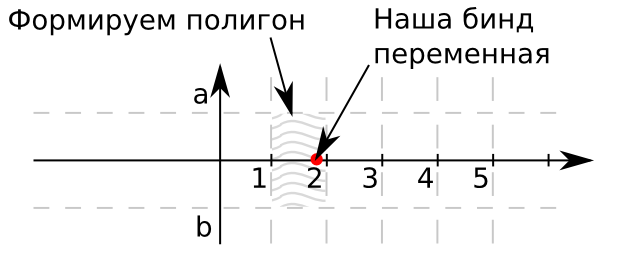
Представим плоскость. На оси абсцисс будут находится наши значения для поиска. Ордината ашей точки равна нулю, так как в данном конкретном случае, для упрощения, будем искать between только для одного критерия. Если критериев больше необходимо использовать многомерные объекты. В качестве границ прямоугольника a и b обычно используют 1 и -1 соответственно. Таким образом значения из нашего справочника будут покрывать луч выходящий из 0. Так же они будут ограничены множеством заштрихованных прямоугольников. Если точка принадлежит данному прямоугольнику, то значит идентификатор этого прямоугольника дает нам искомый идентификатор записи в таблице. Запускаем преобразование:
Для тех, кто рискнул проделать эту операцию вместе со мной — мониторим время окончания update.
Если вы дошли до этого шага — советую его не делать, так как при неверных настройках БД создание данного индекса может затянуться на неделю.
Что ж теперь можно сравнить скорость работы. Для начала посмотрим на скорость выполнения начального варианта запроса и «геометрического» постепенно увеличивая значение limit от 10 до 100.
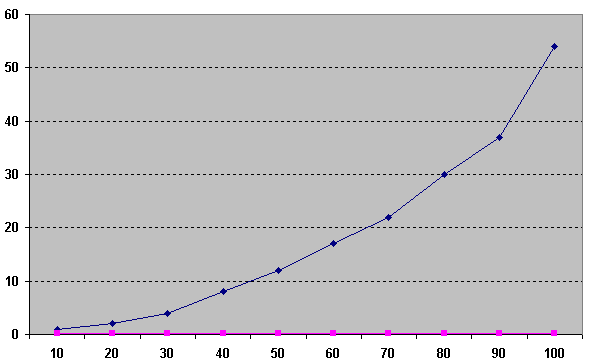
Слева — время, снизу — значение limit. Как видно из рисунка время between (синий) растет экспоненциально в зависимости от того в начале мы или же ближе к концу, так как для каждого следующего значения бинд переменной нам необходимо сканировать все больше и больше строк. «Геометрическое» же решение (розовый) на таких маленьких значениях просто константа.
Попробуем сравнить order by limit 1 и geometry для бОльших значений. Для этого воспользуемся процедурами, для создания равных условий и проведем рандомную выборку.
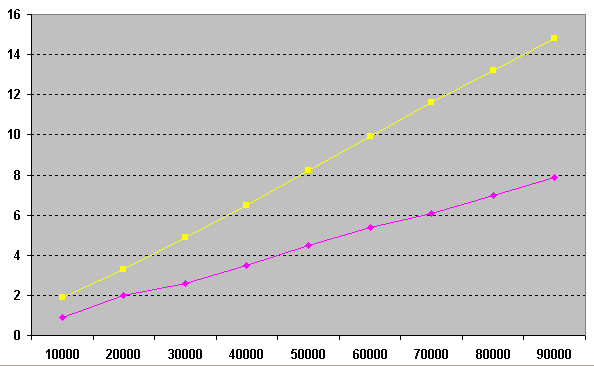
На графике мы видим результат последовательного увеличения количества запусков процедур от 10000 до 90000 и кол-во секунд затраченно на соотвествующие операции. Как видно «геометрическое» решение (розовое) в 2 раза быстрее нежели решения с использованием order by limit 1 (желтое) а помимо этого данное решение можно применять в стандартном SQL.
Освещение данной темы, я провел исключительно по причине того, что на малых объемах данных данные косяки не видны, однако когда БД вырастает, и на ней начинает жить более 10 пользователей, деградация производительности становится просто чудовищной, а указанные типы запросов можно встретить практически в каждой промышленной БД.
Удачных вам оптимизаций. Если данная статья будет интересна в следующий раз расскажу про баги, которые не только не мешают жить, но даже наоборот — увеличивают производительность запросов при правильном их использовании.
З.Ы.
MySQL version 5.5.11
все запросы проводились после перезагрузки MySQL для исключения попадания в КЭШ результатов.
настройки MySQL далеко не стандартные, но размер буферов innodb не превышает 300 Mb, размеры буфферов MyISAM (за исключнием момента создания индекса) не превышают 100Mb.
размеры используемых файлов:
big_range_table.ibd 1740M
big_table.ibd 5520M — без индексов
big_table.ibd 8268M — с индексами
т.е. попадание объектов в кэш БД до начала запроса полностью исключено.
MySQL использует rule based оптимизатор. Зачатки cost based оптимизации в нем конечно присутствуют, но не в должной мере, в какой их хотелось бы видеть. По этой причине часто мощности получаемых после применения фильтров множеств вычисляются неверно. Это приводит к ошибкам оптимизатора и выбору неверного плана выполнения. При чем полученные between оптимизации невозможно изменить явным указанием: индексов для выполнения запроса и порядка соединения таблиц.
Для начала рассмотрим баг: bugs.mysql.com/bug.php?id=5982 и возможные пути его разрешения
Чтобы понять суть бага сформируем тестовый набор данных в размере 125 миллионов записей.
drop table if exists pivot; drop table if exists big_table; drop table if exists attributes; create table pivot ( row_number int(4) unsigned auto_increment, primary key pk_pivot (row_number) ) engine = innodb; insert into pivot(row_number) select null from information_schema.global_status g1, information_schema.global_status g2 limit 500; create table attributes(attr_id int(10) unsigned auto_increment, attribute_name varchar(32) not null, start_date datetime, end_date datetime, constraint pk_attributes primary key(attr_id) ) engine = innodb; create table big_table(btbl_id int(10) unsigned auto_increment, attr_attr_id int(10) unsigned, record_date datetime, record_value varchar(128) not null, constraint pk_big_table primary key(btbl_id) ) engine = innodb; insert into attributes(attribute_name, start_date, end_date) select row_number, str_to_date("20000101", "%Y%m%d"), str_to_date("20000201", "%Y%m%d") from pivot; insert into big_table(attr_attr_id, record_date, record_value) select p1.row_number, date_add(str_to_date("20000101", "%Y%m%d"), interval p2.row_number + p3.row_number day), p2.row_number * 1000 + p3.row_number from pivot p1, pivot p2, pivot p3; create index idx_big_table_attr_date on big_table(attr_attr_id, record_date);
Таблица attributes по сути является справочником, для big_table а так же содержит две колонки ограничивающие интервал дат одним месяцем.
| attr_id | attribute_name | start_date | end_date |
| 1 | 1 | 1/1/2000 12:00:00 AM | 2/1/2000 12:00:00 AM |
| 2 | 2 | 1/1/2000 12:00:00 AM | 2/1/2000 12:00:00 AM |
| 3 | 3 | 1/1/2000 12:00:00 AM | 2/1/2000 12:00:00 AM |
Для каждого attr_id в большой таблице содержится 250 000 записей. Попробуем узнать сколько записей содержится в big_table с учетом дат заданных таблицей attributes для аттрибута один.
select attr_attr_id, max(record_date), min(record_date), max(record_value), count(1) from big_table where attr_attr_id = 1 and record_date between str_to_date("20000101", "%Y%m%d") and str_to_date("20000201", "%Y%m%d") group by attr_attr_id;
| attr_attr_id | max(record_date) | min(record_date) | count(1) |
| 1 | 2/1/2000 12:00:00 AM | 1/3/2000 12:00:00 AM | 465 |
Получаем порядка 500 записей (время выполнения запроса ничтожно мало и составило 00.050 секунды). Логично предположить, что так как данные распределены одинаково для всех значений аттрибутов, то при соединении с таблицей attributes заместо явного указания бинд переменных время запроса должно увеличится незначительно, и составить не более 25 секунд. Что ж проверим:
select b.attr_attr_id, max(b.record_date), min(b.record_date), max(b.record_value), count(1) from attributes a join big_table b on b.attr_attr_id = a.attr_id and b.record_date between a.start_date and a.end_date group by b.attr_attr_id;
Время выполнения: более 15 минут (на этой отметке я прервал выполнение запроса). Отчего же так получется? Все дело в том, что MySQL не поддерживает динамическое ранжирование о чем нам и говорит бага #5982 созданная ещё в далеком 2004 году. Посмотрим план выполнения:
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
| 1 | SIMPLE | b | ALL | idx_big_table_attr_date | 125443538 | Using temporary; Using filesort | |||
| 1 | SIMPLE | a | eq_ref | PRIMARY | PRIMARY | 4 | test.b.attr_attr_id | 1 | Using where |
План явно показывает, что идет полное сканирование таблицы в 125 миллионов записей. Странное решение. Исправить ситуацию не поможет и straight_join для смены порядка джойна ни force index для явного указания использовать индекс. Все дело в том что в лучшем случае мы получим план вида:
| PRIMARY | b | ref | idx_big_table_attr_date | idx_big_table_attr_date | 5 | a.attr_id | 6949780 | Using where |
Который говорит нам о том, что таблица big_table будет сканироваться по нужному индексу, но индекс будет задействован неполностью, то есть из него будет использоваться только первая колонка. В некоторых, вырожденных случаях, мы сможем добиться нужного нам плана и полного использования индекса, однако, ввиду непостоянства оптимизатора и невозможности применения данного решения (не буду приводить здесь его код, оно не работает в 90% случаев) во всех 100% случаев, нужен иной подход.
Данный поход предлагает нам сам MySQL. Будем явно указывать bind переменные. Конечно для ряда задач это не всегда эффективно, так как бывает, что полное сканирование проходит быстрее чем индексное, но явно не в нашем случае когда надо выбрать 500 записей из 250000. Для решения задачи нам потребуется создание следующей процедуры.
drop procedure if exists get_big_table_data;
delimiter $$
create procedure get_big_table_data(i_attr_from int(10))
main_sql:
begin
declare v_attr_id int(10);
declare v_start_date datetime;
declare v_end_date datetime;
declare ex_no_records_found int(10) default 0;
declare
attr cursor for
select attr_id, start_date, end_date
from attributes
where attr_id > i_attr_from;
declare continue handler for not found set ex_no_records_found = 1;
declare continue handler for sqlstate '42S01' begin
end;
create temporary table if not exists temp_big_table_results(
attr_attr_id int(10) unsigned,
max_record_date datetime,
min_record_date datetime,
max_record_value varchar(128),
cnt int(10)
)
engine = innodb;
truncate table temp_big_table_results;
open attr;
repeat
fetch attr
into v_attr_id, v_start_date, v_end_date;
if not ex_no_records_found then
insert into temp_big_table_results(attr_attr_id,
max_record_date,
min_record_date,
max_record_value,
cnt
)
select attr_attr_id,
max(record_date) max_record_date,
min(record_date) min_record_date,
max(record_value) max_record_value,
count(1) cnt
from big_table b
where attr_attr_id = v_attr_id and record_date between v_start_date and v_end_date
group by attr_attr_id;
end if;
until ex_no_records_found
end repeat;
close attr;
select attr_attr_id,
max_record_date,
min_record_date,
max_record_value,
cnt
from temp_big_table_results;
end
$$
delimiter ;
* This source code was highlighted with Source Code Highlighter.Т.е. мы в начале открываем курсор по пятистам записям таблицы аттрибутов, и для каждой строки данной таблицы делаем запрос из big_table. Посмотрим на результат:
call get_big_table_data(0);
* This source code was highlighted with Source Code Highlighter.Время выполнения: 0:00:05.017 имхо результат гораздо лучше. Не идеально, но зато работает.
Теперь можно рассмотреть обратный пример, когда поиск производится не в таблице «транзакций», а наоборот в таблице фактов.
Теперь посмотрим на багу bugs.mysql.com/bug.php?id=8113
Данная бага проявляется если вы:
— работаете с базой GeoIP
— пытаетесь проанализировать расписание
— фиксируете рейты валют на Forex
— вычисляете город по номерной емкости оператора
и т.д.
Для начала создадим тестовый набор данных из 25 миллионов строк.
drop table if exists big_range_table; create table big_range_table(rtbl_id int(10) unsigned auto_increment, value_from int(10) unsigned, value_to int(10) unsigned, range_value varchar(128), constraint pk_big_range_table primary key(rtbl_id) ) engine = innodb; insert into big_range_table(value_from, value_to, range_value) select @row_number := @row_number + 1, @row_number + 1, p1.row_number + p2.row_number + p3.row_number from (select * from pivot where row_number <= 100) p1, pivot p2, pivot p3, (select @row_number := 0) counter; create index idx_big_range_table_from_to on big_range_table(value_from, value_to); create index idx_big_range_table_from on big_range_table(value_from);
Получим таблицу вида
| rtbl_id | value_from | value_to | range_value |
| 1 | 1 | 2 | 3 |
| 2 | 2 | 3 | 4 |
| 3 | 3 | 4 | 5 |
И с ходу попробуем выполнить запрос, который успешно оптимизируется всеми СУБД за исключением MySQL:
select range_value from big_range_table where 10000000.5 >= value_from and 10000000.5 < value_to;
Время выполнения: 0:00:22.412. Вообще не вариант с учетом того, что мы то знаем, что такой запрос должен вернуть одну уникальную строку. И чем выше значение выбранной вами переменной — тем больше записей будет просканировано, время работы запроса растет экпоненциально.
Сам MySQL для решения данной проблемы предлагает следующий workaround:
select range_value from big_range_table where value_from <= 25000000 order by value_from desc limit 1;
Время выполнения: 0:00:00.350. Неплохо. Но данное решение имеет ряд недостатков, в частности, вы не сможете производить join с другими таблицами. Т.е. данный запрос может существовать исключительно атомарно. Для возможности джойнов воспользуемся стандартным решением RTree индексами (если конечно ваш справочник не нуждается в транзакциях или же вы обеспечите его целостность триггерами, так как данный тип индексов по прежнему работает только для MyISAM). Для тех кто не в курсе, что такое геометрические объекты в MySQL приведу иллюстрацию того, что обычно делают в таких случаях:
Представим плоскость. На оси абсцисс будут находится наши значения для поиска. Ордината ашей точки равна нулю, так как в данном конкретном случае, для упрощения, будем искать between только для одного критерия. Если критериев больше необходимо использовать многомерные объекты. В качестве границ прямоугольника a и b обычно используют 1 и -1 соответственно. Таким образом значения из нашего справочника будут покрывать луч выходящий из 0. Так же они будут ограничены множеством заштрихованных прямоугольников. Если точка принадлежит данному прямоугольнику, то значит идентификатор этого прямоугольника дает нам искомый идентификатор записи в таблице. Запускаем преобразование:
alter table big_range_table engine = myisam, add column polygon_value polygon not null; update big_range_table set polygon_value = geomfromwkb(polygon(linestring( /* двигаемся против часовой стрелке, задаем четыре точки и обратно к первой замыкаем полигон */ point(value_from, -1), /* нижняя левая */ point(value_to, -1), /* нижняя правая */ point(value_to, 1), /* верхняя правая */ point(value_from, 1), /* верхняя левая */ point(value_from, -1) /* к первой точке */ )));
Для тех, кто рискнул проделать эту операцию вместе со мной — мониторим время окончания update.
select (select @first_value := variable_value from information_schema.global_status where variable_name = 'HANDLER_UPDATE') updated, sleep(10) lets_sleep, (select @second_value := variable_value from information_schema.global_status where variable_name = 'HANDLER_UPDATE') updated_in_a_ten_second, @second_value - @first_value myisam_updated_records, 25000000 / (@second_value - @first_value) / 6 estimate_for_update_in_minutes, (select 25000000 / (@second_value - @first_value) / 6 - time / 60 from information_schema.processlist where info like 'update big_range_table%') estimate_time_left_in_minutes;
Если вы дошли до этого шага — советую его не делать, так как при неверных настройках БД создание данного индекса может затянуться на неделю.
create spatial index idx_big_range_table_polygon_value on big_range_table(polygon_value);
Что ж теперь можно сравнить скорость работы. Для начала посмотрим на скорость выполнения начального варианта запроса и «геометрического» постепенно увеличивая значение limit от 10 до 100.
select * from (select row_number * 5000 row_number from pivot order by row_number limit 10) p, big_range_table where mbrcontains(polygon_value, pointfromwkb(point(row_number, 0))) and row_number < value_to; select * from (select row_number * 5000 row_number from pivot order by row_number limit 10) p, big_range_table where value_from <= row_number and row_number < value_to;
Слева — время, снизу — значение limit. Как видно из рисунка время between (синий) растет экспоненциально в зависимости от того в начале мы или же ближе к концу, так как для каждого следующего значения бинд переменной нам необходимо сканировать все больше и больше строк. «Геометрическое» же решение (розовый) на таких маленьких значениях просто константа.
Попробуем сравнить order by limit 1 и geometry для бОльших значений. Для этого воспользуемся процедурами, для создания равных условий и проведем рандомную выборку.
drop procedure if exists pbenchmark_mbrcontains;
delimiter $$
create procedure pbenchmark_mbrcontains(i_repeat_count int(10))
main_sql:
begin
declare v_random int(10);
declare v_range_value int(10);
declare v_loop_counter int(10) unsigned default 0;
begin_loop:
loop
set v_loop_counter = v_loop_counter + 1;
if v_loop_counter < i_repeat_count then
set v_random = round(2500000 * rand());
select range_value
into v_range_value
from big_range_table
where mbrcontains(polygon_value, pointfromwkb(point(v_random, 0))) and v_random < value_to;
iterate begin_loop;
end if;
leave begin_loop;
end loop begin_loop;
select v_loop_counter;
end
$$
delimiter ;
drop procedure if exists pbenchmark_limit;
delimiter $$
create procedure pbenchmark_limit(i_repeat_count int(10))
main_sql:
begin
declare v_random int(10);
declare v_range_value int(10);
declare v_loop_counter int(10) unsigned default 0;
begin_loop:
loop
set v_loop_counter = v_loop_counter + 1;
if v_loop_counter < i_repeat_count then
set v_random = round(2500000 * rand());
select range_value
into v_range_value
from big_range_table
where value_from <= v_random order by value_from desc limit 1;
iterate begin_loop;
end if;
leave begin_loop;
end loop begin_loop;
select v_loop_counter;
end
$$
delimiter ;
* This source code was highlighted with Source Code Highlighter.На графике мы видим результат последовательного увеличения количества запусков процедур от 10000 до 90000 и кол-во секунд затраченно на соотвествующие операции. Как видно «геометрическое» решение (розовое) в 2 раза быстрее нежели решения с использованием order by limit 1 (желтое) а помимо этого данное решение можно применять в стандартном SQL.
Освещение данной темы, я провел исключительно по причине того, что на малых объемах данных данные косяки не видны, однако когда БД вырастает, и на ней начинает жить более 10 пользователей, деградация производительности становится просто чудовищной, а указанные типы запросов можно встретить практически в каждой промышленной БД.
Удачных вам оптимизаций. Если данная статья будет интересна в следующий раз расскажу про баги, которые не только не мешают жить, но даже наоборот — увеличивают производительность запросов при правильном их использовании.
З.Ы.
MySQL version 5.5.11
все запросы проводились после перезагрузки MySQL для исключения попадания в КЭШ результатов.
настройки MySQL далеко не стандартные, но размер буферов innodb не превышает 300 Mb, размеры буфферов MyISAM (за исключнием момента создания индекса) не превышают 100Mb.
размеры используемых файлов:
big_range_table.ibd 1740M
big_table.ibd 5520M — без индексов
big_table.ibd 8268M — с индексами
т.е. попадание объектов в кэш БД до начала запроса полностью исключено.

