Nodeload, первому проекту команды GitHub, выполненному с использованием node.js, недавно исполнился 1 год. Nodeload, — это тот сервис, который упаковывает содержимое Git-репозитория в ZIP-архивы и тарболы. С тех пор нагрузка на сервис росла в течение года, и мы столкнулись с различными проблемами. Почитайте о происхождении Nodeload, если вы не помните, почему это работает так, как работает сейчас.
По существу, у нас стало слишком много запросов, проходящих через один сервер nodeload. Эти запросы запускали процессы
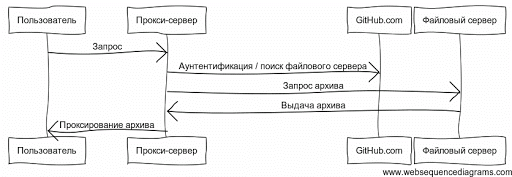
Теперь сервер Nodeload работает только как простое прокси-приложение. Это прокси-приложение ищет соответствующие файловые сервера запрошенного репозитория, и проксирует данные напрямую из файлового сервера. На файловых серверах теперь работает приложение-архиватор, которое в основном является HTTP-интерфейсом для
Node.js прекрасно подходит для этого приложения из-за великолепного потокового API. При реализации прокси любого рода вам приходится иметь дело с клиентами, которые не могут читать данные так же быстро, как вы можете отправить их. Когда поток ответа HTTP-сервера не может посылать больше данных с вашей стороны,
После запуска мы наткнулись на какие-то странные проблемы в выходные дни:
Для отслеживания утечки памяти я пробовал поставить v8-profiler (включая патч Феликса Гнасса для показа heap retainers (объектов, которые удерживают GC от освобождения других объектов)), и использовал node-inspector для наблюдения вживую за процессами Node в производственной среде (production). Webkit Web Inspector для профилирования приложения работает замечательно, но так и не показал на какую-либо очевидную утечку памяти.
К тому моменту @tmm1, @rtomayko и @rodjek пришли на помощь для мозгового штурма в поиске других возможных проблем. В конечном итоге они выследили утечку в виде накопления файловых дескрипторов FD на процессах.
Исправление этой проблемы — обработка события
Nodeload сейчас более стабилен, чем это было раньше. Переписанный код стал проще и лучше протестирован, чем прежде. Node.js работает просто великолепно. Но тот факт, что мы используем HTTP везде, означает, что мы можем легко заменить любой из компонентов. Наша основная задача сейчас заключается в установке лучших пробников для наблюдения за Nodeload и повышения надежности обслуживания.
По существу, у нас стало слишком много запросов, проходящих через один сервер nodeload. Эти запросы запускали процессы
git archive, которые запускали SSH-процессы для общения с файловыми серверами. Эти запросы постоянно записывали гигабайты данных, а также передавали их через nginx. Одной простой идеей было заказать больше серверов, но это создало бы дубликат кэша заархивированных репозиториев. Я хотел избежать этого, если возможно. Итак, я решил начать все сначала и переписать Nodeload с нуля.Теперь сервер Nodeload работает только как простое прокси-приложение. Это прокси-приложение ищет соответствующие файловые сервера запрошенного репозитория, и проксирует данные напрямую из файлового сервера. На файловых серверах теперь работает приложение-архиватор, которое в основном является HTTP-интерфейсом для
git archive. Кэшируемые репозитории теперь записываются в разделе TMPFS, чтобы снизить нагрузку на подсистему ввода-вывода данных (IO). Прокси-сервер Nodeload также старается использовать файловые сервера резервного копирования вместо активных файловых серверов, смещая большую часть нагрузки на незагруженные сервера резервных копий.Node.js прекрасно подходит для этого приложения из-за великолепного потокового API. При реализации прокси любого рода вам приходится иметь дело с клиентами, которые не могут читать данные так же быстро, как вы можете отправить их. Когда поток ответа HTTP-сервера не может посылать больше данных с вашей стороны,
write() возвращает false. Получив такое значение, вы можете приостановить проксированный поток HTTP-запроса, пока объект ответа не сгенерирует событие drain. Событие drain означает, что объект ответа готов послать больше данных, и что теперь вы можете возобновить проксированный поток HTTP-запроса. Эта логика полностью инкапсулирована в метод ReadableStream.pipe().// proxy the file stream to the outgoing HTTP response
var reader = fs.createReadStream('some/file');
reader.pipe(res);
Тяжелый запуск
После запуска мы наткнулись на какие-то странные проблемы в выходные дни:
- Сервера Nodeload всё ещё имели большую нагрузку на систему ввода/вывода (IO);
- Файловые сервера резервного копирования исчерпывали всю доступную оперативную память;
- Сервера Nodeload исчерпывали всю доступную оперативную память;
topиpsне показали, что процессы nodeload меняют занятый ими размер. Процессы Nodeload работали хорошо, но мы наблюдали, что доступная память сервера медленно уменьшалась в размерах.
proxy_buffering. Как только мы её отключили, IO резко упал. Это означает, что потоки идут со скоростью клиента. Если клиенты не могут скачать архив достаточно быстро, прокси ставит на паузу поток HTTP-запроса. Это передаётся далее приложению-архиватору, которое приостанавливает файловый поток.Для отслеживания утечки памяти я пробовал поставить v8-profiler (включая патч Феликса Гнасса для показа heap retainers (объектов, которые удерживают GC от освобождения других объектов)), и использовал node-inspector для наблюдения вживую за процессами Node в производственной среде (production). Webkit Web Inspector для профилирования приложения работает замечательно, но так и не показал на какую-либо очевидную утечку памяти.
К тому моменту @tmm1, @rtomayko и @rodjek пришли на помощь для мозгового штурма в поиске других возможных проблем. В конечном итоге они выследили утечку в виде накопления файловых дескрипторов FD на процессах.
tmm1@arch1:~$ sudo lsof -nPp 17655 | grep ":7005 ("
node 17655 git 16u IPv4 8057958 TCP 172.17.1.40:49232->172.17.0.148:7005 (ESTABLISHED)
node 17655 git 21u IPv4 8027784 TCP 172.17.1.40:38054->172.17.0.133:7005 (ESTABLISHED)
node 17655 git 22u IPv4 8058226 TCP 172.17.1.40:42498->172.17.0.134:7005 (ESTABLISHED)
Исправление этой проблемы — обработка события
close объекта HTTP-запрос на сервере. pipe() на самом деле не обрабатывает этот случай, потому он написан для общего API читаемого потока. Событие «close» отличается от более общего события «end», потому что первое событие означает, что поток HTTP-запроса был оборван перед тем, как был вызван response.end().// check to see if the request is closed already
if (req.connection.destroyed) {
return;
}
var reader = fs.createReadStream('/some/file');
req.on('close', function() {
reader.destroy();
});
reader.pipe(res);
Заключение
Nodeload сейчас более стабилен, чем это было раньше. Переписанный код стал проще и лучше протестирован, чем прежде. Node.js работает просто великолепно. Но тот факт, что мы используем HTTP везде, означает, что мы можем легко заменить любой из компонентов. Наша основная задача сейчас заключается в установке лучших пробников для наблюдения за Nodeload и повышения надежности обслуживания.

