В интернете без труда можно найти множество критики в адрес программистов, которые пишут плохой код. Есть множество статей о плохих и хороших программистах, и даже специальные сайты. Но меня удивляет почти полное безразличие к тому говнокоду, что пишут верстальщики. В этой статье я постараюсь донести вам свои мысли о том, почему подавляющее большинство сайтов в интернете просто не должны работать.
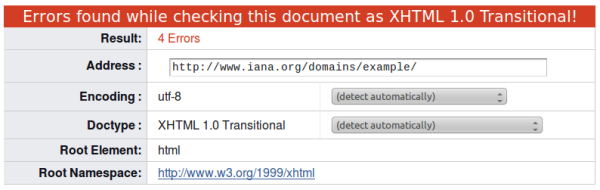
Фрагмент результата валидации example.com
Как известно, самизнаетекто придерживается следующего мнения о валидации:
Это — яркий пример дилетантства и некомпетентности. Это — путь, по которому, к сожалению, работает множество студий, и имя этому пути «Работает, ну и ладно». Безошибочная с точки зрения валидации вёрстка должна быть также важна для сайта, как, собственно, и программный код.
По какой-то совершенно загадочной причине подавляющее большинство сайтов до сих пор верстается в XHTML. Но разработчики не могут ответить на простой вопрос «Почему вы используете XHTML?». Я не слышал ни одного внятного объяснения. И причина в обычном не понимании предмета.
Как известно, браузеры всегда прощают ошибки в HTML, отображая страницу «как есть», даже если вы забудете закрыть тэг. XHTML же основан XML, а XML — строгий язык разметки. Это значит, что парсер просто не сможет обработать невалидный XML-код, выдав сообщение о синтаксической ошибке.
Проверить это очень просто. Достаточно взять любую сверстанную «в соответствии» со стандартами XHTML-страничку и, сохранив локально, переименовать её в *.xhtml. Если после этого страница откроется в браузере без проблем — у меня для вас хорошие новости. Ежели нет — вероятно вы будете удивлены тем, что увидите.
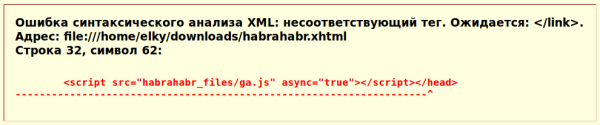
Скриншот ошибки синтаксического анализа главной страницы habrahabr.ru. Браузер Firefox
«Так если страница с невалидным кодом открывается с ошибкой локально, то почему же мы не видим таких ошибок на сайтах?» — справедливо спросит читатель.
DOCTYPE, который мы указываем в самом начале документа, на самом деле, не играет никакой роли в выборе парсера браузером.
Итак, браузер парсит страницу в соответствии с HTTP-ответом. Но в нём в большинстве случаев можно увидеть:
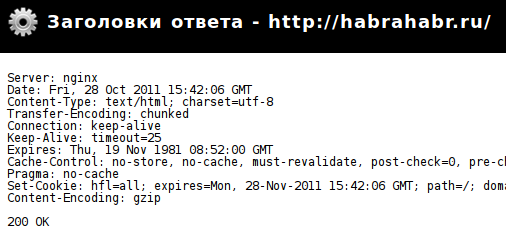
Скриншот страницы HTTP-ответа, полученной с помощью плагина Web Developer Toolbar для Firefox
Что это значит? Получая такой ответ браузер думает, что получил HTML, а не XHTML, и парсит код соответствующе.
Вот почему мы не видим ошибок на сайтах. Вот почему вы думаете, что ошибки в валидации никак не влияют на отображение страниц. Ваш сайт просто обманывает браузер, а вы и сами того не подозреваете. Ваш сайт скорее всего не должен открываться вовсе.
Если вы хотите получить действительно то, что написали в своем документе, то правильный тип Content-Type должен быть таким:
Объявив в самом начале своей страницы XHTML-ный doctype, и действительно использовав синтаксис XHTML при написании документа, будьте добры проверить код на валидность и объявить правильный контент-тайп. А затем готовьтесь к сюрпризам. Придется быть уверенным в том, что визуальный редактор в вашей CMS отдаст валидный код (даже если клиент в нём вручную исправит код в html-view), придется беспокоиться о специальных символах, придется беспокоиться о CDATA например в скриптах и т. д. Иначе страница просто не отобразится.
XHTML — плохая идея. И хорошо, что это успели понять в W3C, отказавшись от разработки XHTML 2.0 и перебросив все силы на HTML5.
Выбирайте правильные технологии, читайте документации и пишите правильный код.
Фрагмент результата валидации example.com
Валидация
Как известно, самизнаетекто придерживается следующего мнения о валидации:
<N.B.>Лучший валидатор - это браузер</N.B.>Это — яркий пример дилетантства и некомпетентности. Это — путь, по которому, к сожалению, работает множество студий, и имя этому пути «Работает, ну и ладно». Безошибочная с точки зрения валидации вёрстка должна быть также важна для сайта, как, собственно, и программный код.
XHTML
По какой-то совершенно загадочной причине подавляющее большинство сайтов до сих пор верстается в XHTML. Но разработчики не могут ответить на простой вопрос «Почему вы используете XHTML?». Я не слышал ни одного внятного объяснения. И причина в обычном не понимании предмета.
Как известно, браузеры всегда прощают ошибки в HTML, отображая страницу «как есть», даже если вы забудете закрыть тэг. XHTML же основан XML, а XML — строгий язык разметки. Это значит, что парсер просто не сможет обработать невалидный XML-код, выдав сообщение о синтаксической ошибке.
Проверить это очень просто. Достаточно взять любую сверстанную «в соответствии» со стандартами XHTML-страничку и, сохранив локально, переименовать её в *.xhtml. Если после этого страница откроется в браузере без проблем — у меня для вас хорошие новости. Ежели нет — вероятно вы будете удивлены тем, что увидите.
Скриншот ошибки синтаксического анализа главной страницы habrahabr.ru. Браузер Firefox
«Так если страница с невалидным кодом открывается с ошибкой локально, то почему же мы не видим таких ошибок на сайтах?» — справедливо спросит читатель.
Content-type
DOCTYPE, который мы указываем в самом начале документа, на самом деле, не играет никакой роли в выборе парсера браузером.
Каждый раз, когда браузер запрашивает страницу, веб-сервер отправляет заголовки-ответа перед тем, как отобразить сам документ. Эти заголовки обычно не видны, но вы можете посмотреть их с помощью специальных инструментов для разработки, если вам интересно. Эти заголовки очень важны, потому что они говорят браузеру как интерпретировать ваш документ. Наиболее важным заголовком является Content-Type.Вольный перевод из Dive into HTML5
Итак, браузер парсит страницу в соответствии с HTTP-ответом. Но в нём в большинстве случаев можно увидеть:
Content-Type: text/html;Скриншот страницы HTTP-ответа, полученной с помощью плагина Web Developer Toolbar для Firefox
Что это значит? Получая такой ответ браузер думает, что получил HTML, а не XHTML, и парсит код соответствующе.
Вот почему мы не видим ошибок на сайтах. Вот почему вы думаете, что ошибки в валидации никак не влияют на отображение страниц. Ваш сайт просто обманывает браузер, а вы и сами того не подозреваете. Ваш сайт скорее всего не должен открываться вовсе.
Если вы хотите получить действительно то, что написали в своем документе, то правильный тип Content-Type должен быть таким:
application/xhtml+xmlНу и что?
Объявив в самом начале своей страницы XHTML-ный doctype, и действительно использовав синтаксис XHTML при написании документа, будьте добры проверить код на валидность и объявить правильный контент-тайп. А затем готовьтесь к сюрпризам. Придется быть уверенным в том, что визуальный редактор в вашей CMS отдаст валидный код (даже если клиент в нём вручную исправит код в html-view), придется беспокоиться о специальных символах, придется беспокоиться о CDATA например в скриптах и т. д. Иначе страница просто не отобразится.
XHTML — плохая идея. И хорошо, что это успели понять в W3C, отказавшись от разработки XHTML 2.0 и перебросив все силы на HTML5.
Выбирайте правильные технологии, читайте документации и пишите правильный код.

