Если вы путешествовали по территории индексов MongoDB, вы возможно слышали принцип: Если ваши запросы содержат сортировку, то добавте сортированное поле в конец индекса который используется в этих запросах.
Во многих случаях когда запросы содержат условия равенства как например {“name”: “Charlie”}, принцип который выше очень полезен. Но что о нем можно сказать со следующим примером:
Эта связка является не эффективной, хотя принцип соблюдается. Потому что тут есть ловушка в которую вас может привести этот принцип.
Ниже мы рассмотрим причины возниконвения этой ловушки и к концу статьи вы будете иметь новое правило которое будет вам помогать при индексировании.
Давайте вспомним основы из документации MongoDB:
* «Индексы рано»
Индексы заслуживают рассмотрения в начале проектирования. Исторический, эффективность на уровне доступа к данным была переложена на администраторов баз данных, это создавало слой оптимизации после проектирования.
С документо-ориентированныим базами данных есть возможность этого избежать.
* «Индексы часто»
Индексированные запросы работают лучше на несколько порядков, даже на маленьких данных. В то время как без индекса запрос может занять 10 секунд, тот же запрос может занять 0 милисекунд с соответсвующим индексом.
* «Индексы полностью»
Запросы используют индексы слева направо. Индекс может быть использован только при условии что запрос использует все поля в индексе без пропусков.
* «Сортировка индекса»
Если ваш запрос будет содержать сортировку, то добавте сортированное поле в ваш индекс.
* «Команды»
.explain() покажет какой индекс используется для данного запроса.
.ensureIndex() создает индексы.
.getIndexes() и .getIndexKeys() покажут какие индексы у вас есть.
Теперь вернемся к нашему вопросу. С учетом основ индексации, для следующего запроса:
Мы должны создать такой индекс:
Что если большинство запросов в условии используют выбор диапазона вместо сравнения? Как в этом:
Здесь мы использовали оператор $in, но кроме него есть ещё такие как: $gt, $lt, и др.
Если вы будете использовать подобный запрос, вы увидите что он не эффективен, при этом вы помните основы — нужно запустить .explain() и посмотреть какой индекс используется и как.
В результате выполнения .explain() Вы увидите {scanAndOrder: true}, что значит MongoDB выполняет сортировочные операции, а это дорогая операция т.к. MongoDB сортирует документы в памяти. Поэтому Вы должны избегать большых наборов данных т.к. это медленно и ресурсоемко.
Не нужно забывать, почему scanAndOrder медленный, почему MongoDB сортирует результат хотя у нас уже есть индекс с сортировкой? Ответ простой: у нас нет подходящего индекса.
Почему? Причина проста, дело в структуре индекса который мы создали. Для примера выше, документы имеющие {“country”: “A”} и документы имеющие {“country”: “G”} отсортированы в индиксе по {“carsOwned”: 1},
но они сортируются независимо друг от друга. Они не отсортированы вместе! Рассмотрим диаграмму ниже:
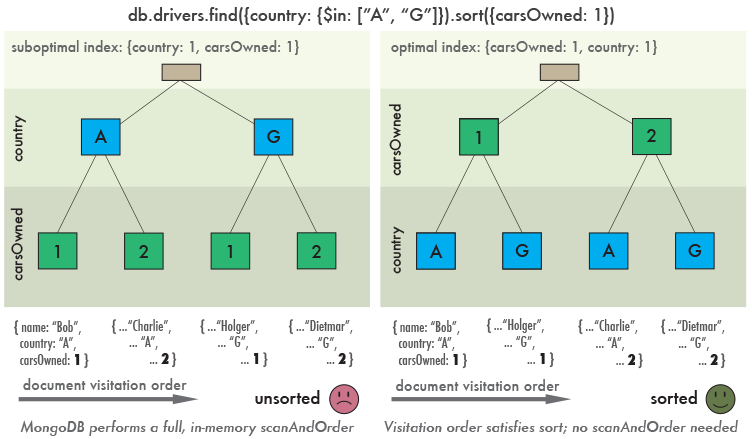
На левой схеме показан порядок обхода документов по индексу который мы создали. После того как все документы будут найдены, их нужно будет отсортировать.
На правой схеме альтернативный индекс { “carsOwned”: 1, “country”: 1}. В этом случае найденые документы будут уже в отсортированном виде.
Этот тонкий момент эффективности привел к следующим правилам при индексации:
Порядок полей должен быть:
1. Сначала поля которые отбираются по точным значениям.
2. Далее поля по которым будет идти сортировка.
3. И в конце поля для диапазонного фильтра.
Концовка
Есть ли компроммис? Да. Запрос будет посещать несколько узлов индекса, что технический необходимо, т.к. обход сортированной части будет происходить до отфильтровывания.
Таким образом новое правило как чистая прибль для многих запросов, но не забывайте что сложность ваших данных может приводить к различным результатам.
Я надеюсь, что это руководство поможет Вам. Удачи.
Во многих случаях когда запросы содержат условия равенства как например {“name”: “Charlie”}, принцип который выше очень полезен. Но что о нем можно сказать со следующим примером:
Запрос: db.drivers.find({"country": {"$in": ["A", "G"]}).sort({"carsOwned": 1}) Индекс: {"country": 1, "carsOwned": 1}
Эта связка является не эффективной, хотя принцип соблюдается. Потому что тут есть ловушка в которую вас может привести этот принцип.
Ниже мы рассмотрим причины возниконвения этой ловушки и к концу статьи вы будете иметь новое правило которое будет вам помогать при индексировании.
Давайте вспомним основы из документации MongoDB:
* «Индексы рано»
Индексы заслуживают рассмотрения в начале проектирования. Исторический, эффективность на уровне доступа к данным была переложена на администраторов баз данных, это создавало слой оптимизации после проектирования.
С документо-ориентированныим базами данных есть возможность этого избежать.
* «Индексы часто»
Индексированные запросы работают лучше на несколько порядков, даже на маленьких данных. В то время как без индекса запрос может занять 10 секунд, тот же запрос может занять 0 милисекунд с соответсвующим индексом.
* «Индексы полностью»
Запросы используют индексы слева направо. Индекс может быть использован только при условии что запрос использует все поля в индексе без пропусков.
* «Сортировка индекса»
Если ваш запрос будет содержать сортировку, то добавте сортированное поле в ваш индекс.
* «Команды»
.explain() покажет какой индекс используется для данного запроса.
.ensureIndex() создает индексы.
.getIndexes() и .getIndexKeys() покажут какие индексы у вас есть.
Теперь вернемся к нашему вопросу. С учетом основ индексации, для следующего запроса:
db.collection.find({"country": "A"}).sort({"carsOwned": 1})
Мы должны создать такой индекс:
db.collection.ensureIndex({"country": 1, "carsOwned": 1})
Что если большинство запросов в условии используют выбор диапазона вместо сравнения? Как в этом:
db.collection.find({"country": {"$in": ["A", "G"]}}).sort({"carsOwned": 1})
Здесь мы использовали оператор $in, но кроме него есть ещё такие как: $gt, $lt, и др.
Если вы будете использовать подобный запрос, вы увидите что он не эффективен, при этом вы помните основы — нужно запустить .explain() и посмотреть какой индекс используется и как.
В результате выполнения .explain() Вы увидите {scanAndOrder: true}, что значит MongoDB выполняет сортировочные операции, а это дорогая операция т.к. MongoDB сортирует документы в памяти. Поэтому Вы должны избегать большых наборов данных т.к. это медленно и ресурсоемко.
Не нужно забывать, почему scanAndOrder медленный, почему MongoDB сортирует результат хотя у нас уже есть индекс с сортировкой? Ответ простой: у нас нет подходящего индекса.
Почему? Причина проста, дело в структуре индекса который мы создали. Для примера выше, документы имеющие {“country”: “A”} и документы имеющие {“country”: “G”} отсортированы в индиксе по {“carsOwned”: 1},
но они сортируются независимо друг от друга. Они не отсортированы вместе! Рассмотрим диаграмму ниже:
На левой схеме показан порядок обхода документов по индексу который мы создали. После того как все документы будут найдены, их нужно будет отсортировать.
На правой схеме альтернативный индекс { “carsOwned”: 1, “country”: 1}. В этом случае найденые документы будут уже в отсортированном виде.
Этот тонкий момент эффективности привел к следующим правилам при индексации:
Порядок полей должен быть:
1. Сначала поля которые отбираются по точным значениям.
2. Далее поля по которым будет идти сортировка.
3. И в конце поля для диапазонного фильтра.
Концовка
Есть ли компроммис? Да. Запрос будет посещать несколько узлов индекса, что технический необходимо, т.к. обход сортированной части будет происходить до отфильтровывания.
Таким образом новое правило как чистая прибль для многих запросов, но не забывайте что сложность ваших данных может приводить к различным результатам.
Я надеюсь, что это руководство поможет Вам. Удачи.

