Споры о том, что лучше: ручное управление или автоматическое ведутся во многих областях науки и техники. Положиться на человека или отдаться на откуп бесстрастным механизмам и алгоритмам? Похоже, что в мире создания Enterprise решений чаша весов склонилась все-таки в сторону автоматического управления памятью, большей частью из-за того, что возиться с указателями, ручным управлением памятью и закрашивать седину после каждого бага, появившегося из-за «неправильного» компилятора С/C++ не хочется сейчас уже никому. Но до сих пор возникают на форумах топики, где не сдающиеся суровые приверженцы ручного управления памятью яростно и непримиримо отстаивают свои ретроградные взгляды в борьбе с прогрессивной частью человечества. Пусть их, оставим их в покое.
Одной из наиболее часто использующихся платформ с механизмами автоматического управления памятью стала Java. Но, автоматическое управление памятью принесло не только комфорт в нелегкий труд программистов, но и свои недостатки, с которыми приходиться сталкиваться всё чаще и чаще. Современные многопользовательские приложения, способные обработать огромный поток транзакций, требуют значительных аппаратных ресурсов, размеры которых раньше было трудно даже вообразить. Однако, дело не в размерах этих ресурсов, дело в том, что сборщик мусора, существующий в большинстве современных JVM, не может работать эффективно с большими объемами памяти.
Сборщик мусора автоматизирует процесс очищения памяти и избавляет программиста от многих головных болей, привнося вместо этого, одну большую проблему – какой механизм GC использовать и какой размер heap-a будет самым оптимальным? Сделаешь heap больше необходимого и столкнешься с постоянными “stop-the-world” паузами, сделаешь меньше нужного, то появятся ошибки “Out of memory”. Всё это осложняется тем, что при росте размера heap-a сборщику мусора требуется больше времени на очистку памяти, дефрагментацию. Это приводит к тому, что при использовании heap-a больше чем в 2 — 4GB паузы становятся критичными для бизнеса и составляют несколько секунд, а то и минут, во время которых все потоки вынуждены ждать, пока завершиться процесс очистки памяти. Время отклика возрастает и становиться нестабильным, падает пропускная способность — для крупных веб порталов, компаний, работающих в сфере электронной коммерции или критических важных для бизнеса приложений это недопустимо.
Есть несколько способов борьбы с большим размером heap-a, одними из которых являются разворачивание нескольких десятков или сотен экземпляров или вынесение хранение данных за область heap-a. Я не хочу затрагивать их в этой статье, оставляя на будущее обсуждение. Хотелось бы заметить, что эти способы довольно дорогостоящи, так как подразумевают под собой достаточно много работы разработчиков и администраторов, необходимой для того, чтобы воплотить их в жизнь. Будем оставаться в рамках JVM, не придумывая «костылей» и обходных решений, на поддержку которых потом тратятся время, нервы и деньги.
Ни для кого не секрет, что GC в распространенных JVM имеет несколько режимов работы и некоторые из них предназначены именно для того, чтобы сократить так называемые “stop-the-world” паузы, во время которых все потоки останавливаются. Тем не менее, исключить эти паузы по технологическим причинам невозможно, за одним исключением, о котором я расскажу ниже. Это означает, что даже в лучшем случае, потокам все равно придётся ждать, пока GC не закончит очистку памяти. Все чаще и чаще это становиться неприемлемым – бизнес не может ждать.
В этой статье я постараюсь провести краткий обзор наиболее распространенных JVMs, а также расскажу о методах предлагаемых этими JVMs для эффективной работы GC с heap-ами большого размера. Я думаю, посетители ресурса знакомы с понятием heap в JVM и знают, что он из себя представляет. Также нет смысла объяснять про поколения объектов, стоит только заметить, что предполагается что объекты, относящиеся к молодому поколению, чаще становятся недостижимыми и удаляются из памяти. Приведу рисунок heap-a:

Основные алгоритмы, которые используют GC в своей работе:
Mark-Sweep-Compact
«Mark»: помечаются неиспользуемые объекты.
«Sweep»: эти объекты удаляются из памяти.
«Compact»: объекты «уплотняются», занимая свободные слоты, что освобождает пространство на тот случай, если потребуется создать «большой» объект.
На протяжении всех трех шагов действует «stop-the-world» пауза.
Copying Collector
Выполняет все три действия за один проход, используя области “from” и “to”. Происходит это следующим образом: в начале работы одно из survivor spaces, “To”, является пустым, а другое, “From”, содержит объекты, пережившие предыдущие сборки. Сборщик мусора ищет живые объекты в Eden и копирует их в To space, а затем копирует туда же и живые «молодые» (то есть не пережившие еще заданное число сборок мусора, tenuring threshold) объекты из From space. Старые объекты из From space перемещаются в Old generation. После сборки From space и To space меняются ролями, область Eden становится пустой, а число объектов в Old generation увеличивается. Если в процессе копирования живых объектов To space переполняется, то оставшиеся живые объекты из Eden и From space, которым не хватило места в To space, будут перемещены в Old generation, независимо от того, сколько сборок мусора они пережили.
Поскольку при использовании этого алгоритма сборщик мусора просто копирует все живые объекты из одной области памяти в другую, то такой сборщик мусора называется копирующим. Очевидно, что для работы копирующего сборщика мусора у приложения всегда должна быть свободная область памяти, в которую будут копироваться живые объекты, и такой алгоритм может применяться для областей памяти сравнительно небольших по отношению к общему размеру памяти приложения.
Главный недостаток существующих GC – это необходимость в паузах. Паузы эти являются результатом неизбежных событий из-за фрагментирования памяти. Даже если использовать так называемые «mostly concurrent» (в большинстве случаев одновременные) алгоритмы сборки мусора, то все равно рано или поздно мы столкнемся с тем, что область, относящаяся к старому поколению, будет сильно фрагментирована, и количество памяти для новых объектов будет недостаточном, что приведет к вызову «mark-sweep-compact» алгоритму и остановит приложение( есть еще один трюк, как оттянуть это событие во времени – о нем дальше). Еще одна задача, которая приводит к возникновению “stop-the-world” пауз – это маркировка. «Mostly concurrent» GC проводят маркировку живых объектов в два этапа – первый этап включает в себя маркировку одновременно с работой потоков, и называется concurrent mark. Второй этап — это повторная маркировка(remark) – так как за то время, когда проходил первый этап, приложение могло модифицировать ссылки или создать новые объекты, то необходимо это проверить. На этом этапе GC устанавливает “stop-the-world” паузы и проверяет, что изменилось. Такой подход позволяет сократить общее время “stop-the-world” пауз при малом проценте мутаций, но мало помогает, если у нас постоянно создается и модифицируется большое количество объектов.
Я приведу тут таблицу с наиболее распространенными GC:
«Монолитный» означает то, что всё поколение должно быть очищено за проход.
«В большинстве случаев одновременный» — mostly concurrent, одновременный имеется в виду фоновый, «работающий вместе с потоками приложения».
Остановимся чуть подробнее на нескольких:
Oracle HotSpot ParallelGC
GC для HotSpot по умолчанию. Использует «монолитный», stop-the-world алгоритм(Copying Collector) для молодого поколения и «монолитный», stop-the-world алгоритм (Mark/Sweep/Compact) для старшего поколения.
Oracle HotSpot CMS
GC пытается устранить паузы, возникающие при работе со старшим поколением, насколько возможно с помощью одновременной маркировки и очистки, но без дефрагментации. Однако как только область памяти, относящаяся к OG, будет сильно фрагментирована, то вызывается дефрагментация с stop-the-world.
Цикл сборки мусора CMS состоит из нескольких этапов, основные этапы следующие:
· начальная маркировка (initial mark): работа CMS начинается с очень короткой stop-the-world паузы, в течении которой сборщик мусора находит так называемые корневые (root) ссылки на объекты, созданные приложением
· одновременная маркировка (concurrent mark): во время этого этапа CMS отмечает все объекты, достижимые из корневых объектов, то есть все «живые» объекты, которые не должны удаляться сборщиком мусора. Этот этап выполняется одновременно с работой приложения
· повторная маркировка (remark): так как во время этапа одновременной маркировки потоки приложения продолжали работать, и в это время они могли создавать новые объекты и модифицировать ссылки, то к концу этого этапа нет гарантии, что все живые объекты были отмечены. Чтобы решить эту проблему CMS ещё раз приостанавливает приложение и завершает маркировку, проверяя все объекты, которые были изменены пользовательскими потоками во время выполнения предыдущего этапа. Поскольку повторная маркировка может занимать довольно много времени, то на многопроцессорных машинах этот этап выполняется несколькими параллельными потоками.
· одновременная очистка (concurrent sweep): после завершения этапа повторной маркировки все живые объекты в приложении были отмечены, и во время этапа одновременной очистки CMS удаляет весь найденный мусор (все неотмеченные объекты). Этот этап не требует приостановки приложения.
Таким образом, CMS разделяет всю работу по очистке OldGen на несколько частей, некоторые из которых могут выполняться одновременно с работой приложения, и за счёт этого избегает продолжительных stop-the-world пауз. В то же время из-за особенностей алгоритма общее количество работы, выполняемое CMS, становится больше по сравнению с последовательным сборщиком мусора (например, из-за необходимости повторной маркировки), и в результате этого при использовании CMS общая производительность приложения может несколько уменьшиться.
IBM J9 optthruput делает практически то же самое.
Oracle HotSpot G1GC (Garbage First)
Сборщик мусора с поколениями, но принцип работы другой. Вся heap разбита на регионы фиксированного размера. Набор регионов генерируются динамически и могут быть eden, survivor space или старшим поколением(OG). Если объект не помещается в один регион, то он храниться в наборе смежных регионов и называется “humongous”. Предполагается, что некоторые регионы обладают бОльшой популярность, чем другие. При выполнении процедуры очистки памяти происходит следующее:
1) Выбираются регионы, где будет проходить GC – все молодое поколение и непопулярные регионы из старшего поколения, где нет живых объектов
2) Повторная маркировка для отлавливания новых объектов и модифицированных ссылок, на короткий промежуток времени устанавливается stop-the-world
3) Копирование в регионы, помеченные, как “To”, за счет этого происходит частичное «сжатие»
Также есть Remembered Set – информация о местонахождении ссылок на объекты из региона, которая позволяет использовать несколько независимых регионов в разных частях памяти, и отказаться от т.н. free list. Этот GC работает с большим heap-ом лучше предыдущих, и, в принципе, может предложить приемлемую производительность для heap-a размером в 10-15GB. Тем не менее, огромное количество багов, а также тот факт, что со временем G1 все равно вынужден прибегать к stop-the-world из-за сильной фрагментированности популярных регионов, не добавляет ему привлекательности. Также недостатком этого GC является снижение максимальной пропускной способности по сравнению с остальными GC.
IBM J9 balanced делает то же самое.
Azul C4
Наибольший интерес вызывает именно этот сборщик мусора, так как в своем описании он декларирует следующее:
«По-настоящему полностью фоновый, одновременный сборщик мусора, использующий свой собственный алгоритм C4 (Continuously Concurrent Compacting Collector), эксплуатируемый в Azul JVM. С4 одновременно дефрагментирует оба поколения, молодое и старшее. В отличии от других алгоритмов, он не «в большинстве случаев одновременный», а действительно работает с потоками приложения всегда одновременно, т.е. stop-the-world не вызывается никогда. С4 использует Loaded Value Barrier (LVB) для проверки каждой ссылки, а каждая модифицированная ссылка отлавливается с помощью “self-healing” метода. С4 гарантирует, что все ссылки будут маркированы за один проход GC. Также гарантируется, что объекты будут перемещены, а ссылки на них модифицированы одновременно с работой приложения, не препятствуя его работе и не вызывая «stop-the-world»»
Также в описания этого продукта приводятся следующие графики сравнения с некоторыми текущими реализациями GC:
По пропускной способности:
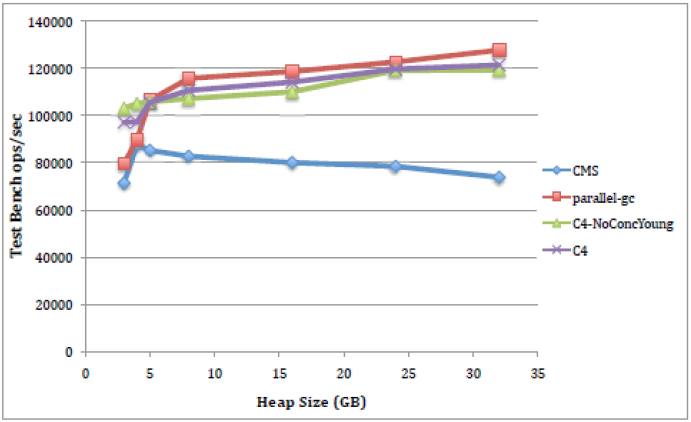
По времени отклика:
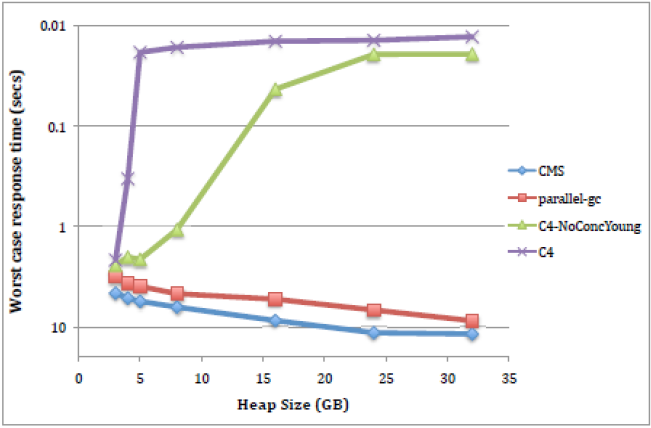
Если по пропускной способности наблюдается некий паритет, а в большинстве случаев видно, что Parallel GC работает лучше, то на графике, показывающем зависимость времени отклика от размера heap-a, можно увидеть, что Azul C4 безусловно лидирует во всех случаях. Однако было бы неправильным поверить этим графикам, просто посмотрев на них, и не вникания в детали, которые могли бы дать нам понимание, откуда берётся столь существенная разница по сравнению с «традиционными» GC? Для того чтобы сделать это надо разобрать алгоритм, по которому действует Azul C4.
Выше я упоминал две основные причины, приводящие к возникновению “stop-the-world” пауз. Это фрагментация области памяти со старшим поколением и маркировка живых объектов. Если мы не будем дефрагментировать память, то рано или поздно получим “Out of memory”, если дефрагментировать память одновременно с работой приложения, то получим неправильные данные. В случае же с маркировкой есть опасность удалить «живые» объекты из памяти, что потом приведет к сообщениям об их недоступности.
Для разрешения этих проблем в алгоритме сборщика мусора Azul C4 используется аппаратная эмуляция так называемого «барьера на чтение» (read barrier). В Azul C4 он имеет название LVB (Load Value Barrier), и именно он помогает гарантировать работу сборщика мусора и приложения в параллельном режиме.
Azul C4 также использует два поколения – молодое и старшее, память занимаемая этими поколениями, дефрагментируются одновременно с выполнением приложения. На рисунке ниже представлены основные этапы очистки мусора. Всего их три – Mark, Relocate, Remap. Хотелось бы заметить, что Remap и Mark могут выполняться в одно и то же время. Что же происходить на каждом этапе?
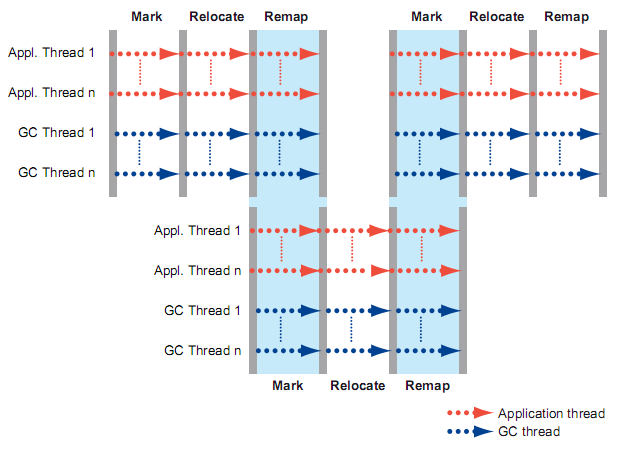
Mark
На этом этапе происходит маркировка всех объектов, достижимых из корневых объектов, в памяти. Такие объекты помечаются, как «живые», все прочие подразумеваются, как «мертвые» и могут быть очищены. Он проходит одновременно с работой приложения и не вызывает «stop-the-world» паузу. В целом, он похож на стадию «concurrent mark» для CMS, но имеет несколько важных отличий. Во-первых, в дополнение к маркировке, Azul C4 также подсчитывает количество «живых» объектов в каждой странице памяти. Эта информация используется в дальнейшем для выбора страниц для переноса и дефрагментации в памяти. Во-вторых, алгоритм Azul C4 отслеживает все ссылки «живых» объектов с помощью архитектурно зарезервированного бита NMT в 64-битных ссылках. Этот бит, NMT (Not Marked Through), предназначен для отметки ссылки, как “marked through” в случае, если GC «прошел» её или, в противном случае, “not marked through”. Таким образом, Azul C4 отмечает все достижимые объекты, как «живые», и также, все ссылки, которые он «прошел», как «marked through». Как только этап Mark начался, потоки приложения, пытающиеся «пройти» по ссылке с битом NMT, выставленным в «not marked through», будут перехвачены «барьером на чтение» LVB. Аппаратная эмуляция этого барьера знает о функции бита NMT и может гарантировать, что потоки приложения никогда не получат доступ к ссылке, отмеченной как «not marked through». Если какой-либо из потоков приложения попробует сделать это, то процессор вызовет прерывание(trap) GC. Прерывание обработает ситуацию, вызвавшую его, следующим образом: поместит ссылку в список GC, поставит бит NMT в положение «marked through» и проверит бит NMT для объекта, откуда была загружена ссылка на правильность (должен иметь состояние “marked through”). После того, как прерывание будет обработано, работа потоков приложения возобновится. Использование этого механизма позволяет отметить все «живые» объекты за один проход, не вызывая повторную маркировку (как это делает CMS) и «stop-the-world» паузу. Также, устранение причины, вызвавшей прерывание, при обработке этого самого прерывания, оказывает эффект «самолечения», т.е. не позволяет этой же причине вызвать прерывание еще раз, что гарантирует конечный и предсказуемый объем работ по маркировке.
В целом, механизм прерываний позволяет проводить маркировку «живых» объектов за один проход, и при этом не вызывать «stop-the-world» паузу.
Relocate
На этом этапе GC освобождает память, занимаемую «мертвыми» объектами. При этом «живые» объекты он переносит в другую область памяти, тем самым дефрагментируя и уплотняя её. Для большей эффективности Azul C4 использует количество подсчитанных объектов на прошлом этапе (Mark) для того, чтобы первыми очистить страницы, в которых количество «мертвых» объектов сравнительно велико. Так как «живых» объектов в этих страницах мало, то их перенос занимает небольшой промежуток времени, в то же время, позволяя освобождать бОльшие объемы памяти в первую очередь, делая их доступными для приложения. Этап заканчивается, когда память, занимаемая «мертвые» объектами, будет полностью очищена. При этом «живые» объекты переносятся только из сильно фрагментированных страниц.
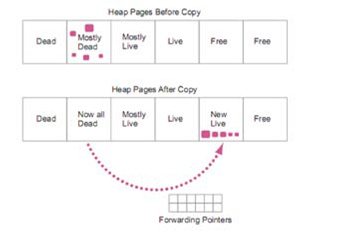
В начале этапа, используя механизм защиты памяти для того, чтобы ограничить доступ к определенным страницам памяти, сборщик мусора начинает перенос «живых» объектов в другие страницы памяти. Информация о начальном и новом адресе хранится в специальном массиве с «переадресацией указателей» (Forwarding Pointers), вынесенном отдельно от “From” пространства. Как только все «живые» объекты будут перенесены, физическая память становится доступной для потоков приложения. LVB используется для определения попыток доступа потоков к страницам памяти, в которых происходит процесс переноса «живых» объектов или переопределения адресов для этого объекта. Он перехватывает обращения потоков и сравнивает значение ссылки с имеющимися у него ссылками в буфере Translation Look-aside Buffer (TLS). Если значение совпадает со ссылкой, для которой сейчас происходит процесс перемещения, то вызывается прерывание. Это прерывание выполняет следующие действия: при помощи информации, находящейся в массиве Forwarding Pointers, определяется, перемещен ли уже объект или нет. Если объект уже перемещен в новую страницу памяти, то потоку возвращается новая ссылка на объект, а также переопределяется адрес для ссылки на объект, из которого он был загружен, для того, чтобы в дальнейшем он использовал новую ссылку. В случае, если объект еще не перемещен, то прерывание перемещает этот объект, не ожидая пока сборщик мусора обработает страницу памяти, где этот объект находится. После этого работа потока возобновляется. Использование того же эффекта «самолечения», что и на предыдущем этапе, дает возможность закончить этап перемещения в детерминированные сроки. Также, этап перемещения может быть завершен принудительно, если сборщик мусора решит, что сейчас выполнить этап маркирования будет эффективнее, чем продолжать этап перемещения объектов в памяти.
При рассмотрении этого этапа можно сказать, что такое поведение алгоритма и механизм прерываний гарантирует, что потоки не будут ожидать момента, пока сборщик мусора закончит работу с перемещением и переопределением адресов, тем самым позволяя сборщику мусора работать действительно одновременно с потоками и не вызывать «stop-the-world» паузу.
Remap
Этот этап завершает переопределение адресов для всех перемещенных объектных ссылок и гарантирует отсутствие ссылок на старое расположение в heap-е для перемещенных объектов. Эти ссылки могут существовать в начале этапа переопределения, так как heap может содержать ссылки на объекты, которые не посещались потоками после их перемещения. Когда этап переопределения адресов завершается, механизм защиты памяти отключается, а массив Forwarding Pointers становиться больше не нужен. Переопределение адресов выполняется следующим образом: сканируются все «живые» объекты в heap-e и переопределяются для них ссылки, если они указывают на объекты, перемещенные в новые страницы памяти. Этот этап совпадает с этапом маркировки, они выполняются одновременно, т.е. процесс маркировки находит живые объекты и помечает их, а также выставляет бит NMT, как «marked through». В то же время, процесс переназначения адресов находит ссылки на перемещенные объекты и переопределяет их соответственно новым адресам. На протяжении всего времени выполнения процессов маркировки и переопределения адресов механизм «барьера на чтение» продолжает «отлавливать» потоки приложения, обращающиеся к перенесенным объектам, вызывая прерывание, возвращающее потоку новый адрес расположения объекта.
Таким образом, Azul C4 может проводить одновременную маркировку, а также переопределение адресов, не вызывая «stop-the-world» паузу.
Подводя итог теоретическому описанию алгоритма Azul C4 можно сказать, что он действительно позволяет работать приложению одновременно со сборщиком мусора. Механизм LVB несколько понижает общую пропускную способность JVM, но стабилизирует время отклика на минимальном уровне, исключая паузы «stop-the-world» полностью. Для компаний, специализирующихся на предоставлении услуг через Интернет и приложений, где время отклика критично для бизнеса, Azul C4 выглядит наиболее привлекательной JVM.
Несмотря на всё это, теория должна подтверждаться практикой. В жизни Azul JVM поставляется как в виде «железки», так и в виде виртуальной машины. Аппаратная платформа Azul Vega 3 уже хорошо себя зарекомендована в финансовых компаниях. Виртуальная реализация Azul JVM приобретает всё большую популярность в мире, отчасти из-за того, что её можно развернуть на любом x86 железе, отчасти из-за того, что задачи, ставящиеся перед Java-приложениями, становятся серьезнее. Кстати, Azul C4 является не единственным преимуществом в Azul JVM, есть еще несколько отличий, выгодно отличающих Azul от конкурентов. Подробное описание этих достоинств займет столько же места, сколько занимает эта статья – поэтому лучше их оставить для отдельной статьи, где можно рассмотреть Azul JVM в общем виде. Если по названиям – то это DirectPathVMTM, Optimistic Thread Concurrency, мониторинг и профилирование выполнения приложений.
На сайте Azul Systems можно увидеть несколько десятков случаев из жизни, где преимущества Azul-a нашли свое применение.
Компании, использующие Azul JVM
Из личной практики могу представить пример реализации Azul JVM в жизни у крупного клиента – трейдинговой компании:
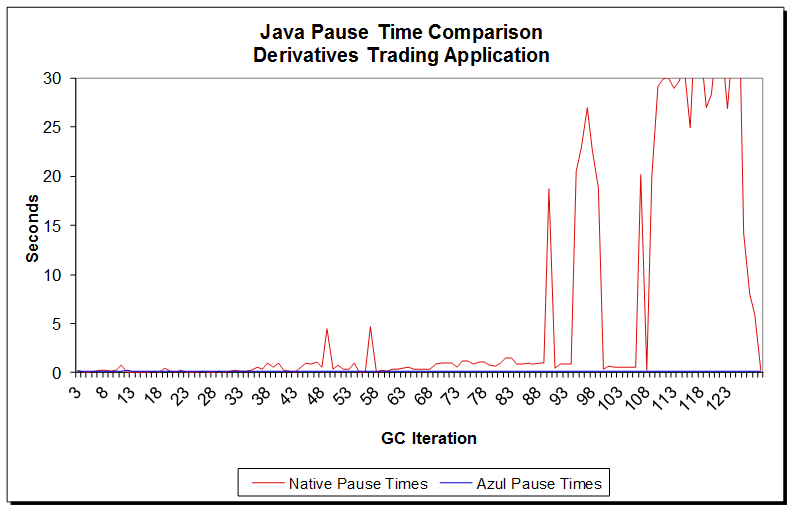
Конфигурация JVM:
Если подвести итог всему вышеизложенному, то можно сказать, что концепция, реализованная в Azul C4, действительно работает в реальной жизни, позволяет иметь heap размером до 1 Терабайта и избавить от головной боли, связанной с настройкой размера heap-a и тюнингом GC, при этом добиться стабильного и минимального времени отклика приложения.
Техническое описание алгоритма Azul C4
Одной из наиболее часто использующихся платформ с механизмами автоматического управления памятью стала Java. Но, автоматическое управление памятью принесло не только комфорт в нелегкий труд программистов, но и свои недостатки, с которыми приходиться сталкиваться всё чаще и чаще. Современные многопользовательские приложения, способные обработать огромный поток транзакций, требуют значительных аппаратных ресурсов, размеры которых раньше было трудно даже вообразить. Однако, дело не в размерах этих ресурсов, дело в том, что сборщик мусора, существующий в большинстве современных JVM, не может работать эффективно с большими объемами памяти.
Сборщик мусора автоматизирует процесс очищения памяти и избавляет программиста от многих головных болей, привнося вместо этого, одну большую проблему – какой механизм GC использовать и какой размер heap-a будет самым оптимальным? Сделаешь heap больше необходимого и столкнешься с постоянными “stop-the-world” паузами, сделаешь меньше нужного, то появятся ошибки “Out of memory”. Всё это осложняется тем, что при росте размера heap-a сборщику мусора требуется больше времени на очистку памяти, дефрагментацию. Это приводит к тому, что при использовании heap-a больше чем в 2 — 4GB паузы становятся критичными для бизнеса и составляют несколько секунд, а то и минут, во время которых все потоки вынуждены ждать, пока завершиться процесс очистки памяти. Время отклика возрастает и становиться нестабильным, падает пропускная способность — для крупных веб порталов, компаний, работающих в сфере электронной коммерции или критических важных для бизнеса приложений это недопустимо.
Есть несколько способов борьбы с большим размером heap-a, одними из которых являются разворачивание нескольких десятков или сотен экземпляров или вынесение хранение данных за область heap-a. Я не хочу затрагивать их в этой статье, оставляя на будущее обсуждение. Хотелось бы заметить, что эти способы довольно дорогостоящи, так как подразумевают под собой достаточно много работы разработчиков и администраторов, необходимой для того, чтобы воплотить их в жизнь. Будем оставаться в рамках JVM, не придумывая «костылей» и обходных решений, на поддержку которых потом тратятся время, нервы и деньги.
Ни для кого не секрет, что GC в распространенных JVM имеет несколько режимов работы и некоторые из них предназначены именно для того, чтобы сократить так называемые “stop-the-world” паузы, во время которых все потоки останавливаются. Тем не менее, исключить эти паузы по технологическим причинам невозможно, за одним исключением, о котором я расскажу ниже. Это означает, что даже в лучшем случае, потокам все равно придётся ждать, пока GC не закончит очистку памяти. Все чаще и чаще это становиться неприемлемым – бизнес не может ждать.
В этой статье я постараюсь провести краткий обзор наиболее распространенных JVMs, а также расскажу о методах предлагаемых этими JVMs для эффективной работы GC с heap-ами большого размера. Я думаю, посетители ресурса знакомы с понятием heap в JVM и знают, что он из себя представляет. Также нет смысла объяснять про поколения объектов, стоит только заметить, что предполагается что объекты, относящиеся к молодому поколению, чаще становятся недостижимыми и удаляются из памяти. Приведу рисунок heap-a:
Основные алгоритмы, которые используют GC в своей работе:
Mark-Sweep-Compact
«Mark»: помечаются неиспользуемые объекты.
«Sweep»: эти объекты удаляются из памяти.
«Compact»: объекты «уплотняются», занимая свободные слоты, что освобождает пространство на тот случай, если потребуется создать «большой» объект.
На протяжении всех трех шагов действует «stop-the-world» пауза.
Copying Collector
Выполняет все три действия за один проход, используя области “from” и “to”. Происходит это следующим образом: в начале работы одно из survivor spaces, “To”, является пустым, а другое, “From”, содержит объекты, пережившие предыдущие сборки. Сборщик мусора ищет живые объекты в Eden и копирует их в To space, а затем копирует туда же и живые «молодые» (то есть не пережившие еще заданное число сборок мусора, tenuring threshold) объекты из From space. Старые объекты из From space перемещаются в Old generation. После сборки From space и To space меняются ролями, область Eden становится пустой, а число объектов в Old generation увеличивается. Если в процессе копирования живых объектов To space переполняется, то оставшиеся живые объекты из Eden и From space, которым не хватило места в To space, будут перемещены в Old generation, независимо от того, сколько сборок мусора они пережили.
Поскольку при использовании этого алгоритма сборщик мусора просто копирует все живые объекты из одной области памяти в другую, то такой сборщик мусора называется копирующим. Очевидно, что для работы копирующего сборщика мусора у приложения всегда должна быть свободная область памяти, в которую будут копироваться живые объекты, и такой алгоритм может применяться для областей памяти сравнительно небольших по отношению к общему размеру памяти приложения.
Главный недостаток существующих GC – это необходимость в паузах. Паузы эти являются результатом неизбежных событий из-за фрагментирования памяти. Даже если использовать так называемые «mostly concurrent» (в большинстве случаев одновременные) алгоритмы сборки мусора, то все равно рано или поздно мы столкнемся с тем, что область, относящаяся к старому поколению, будет сильно фрагментирована, и количество памяти для новых объектов будет недостаточном, что приведет к вызову «mark-sweep-compact» алгоритму и остановит приложение( есть еще один трюк, как оттянуть это событие во времени – о нем дальше). Еще одна задача, которая приводит к возникновению “stop-the-world” пауз – это маркировка. «Mostly concurrent» GC проводят маркировку живых объектов в два этапа – первый этап включает в себя маркировку одновременно с работой потоков, и называется concurrent mark. Второй этап — это повторная маркировка(remark) – так как за то время, когда проходил первый этап, приложение могло модифицировать ссылки или создать новые объекты, то необходимо это проверить. На этом этапе GC устанавливает “stop-the-world” паузы и проверяет, что изменилось. Такой подход позволяет сократить общее время “stop-the-world” пауз при малом проценте мутаций, но мало помогает, если у нас постоянно создается и модифицируется большое количество объектов.
Я приведу тут таблицу с наиболее распространенными GC:
«Монолитный» означает то, что всё поколение должно быть очищено за проход.
«В большинстве случаев одновременный» — mostly concurrent, одновременный имеется в виду фоновый, «работающий вместе с потоками приложения».
| Java Virtual Machine | Collector Name | Young Generation | Old Generation |
| Oracle HotSpot | ParallelGC | Монолитный, stop the world, copying | Монолитный, stop-the-world, Mark/Sweep/Compact |
| Oracle HotSpot | CMS | Монолитный, stop the world, copying | В большинстве случаев одновременный, без «сжатия», при дефрагментации вызывающий stop-the-world |
| Oracle HotSpot | G1 (Garbage First) | Монолитный, stop the world, copying | В большинстве случаев одновременный, с «сжатием» регионов по признаку популярности, при дефрагментации вызывающий stop-the-world |
| Oracle JRockit | Dynamic Garbage Collector | Монолитный, stop-the-world, copying | Одновременный или параллельный Mark/Sweep, с «сжатием» регионов по признаку популярности, при дефрагментации вызывающий stop-the-world |
| IBM J9 | Balanced | Монолитный, stop-the-world, copying | В большинстве случаев одновременный, с «сжатием» регионов по признаку популярности, при дефрагментации вызывающий stop-the-world |
| IBM J9 | optthruput | Монолитный, stop-the-world, copying | Параллельный Mark/Sweep, при дефрагментации вызывающий stop-the-world |
| Azul | C4 (Continuously Concurrent Compacting Collector) | Одновременный, с дефрагментацией | Одновременный, с дефрагментацией |
Остановимся чуть подробнее на нескольких:
Oracle HotSpot ParallelGC
GC для HotSpot по умолчанию. Использует «монолитный», stop-the-world алгоритм(Copying Collector) для молодого поколения и «монолитный», stop-the-world алгоритм (Mark/Sweep/Compact) для старшего поколения.
Oracle HotSpot CMS
GC пытается устранить паузы, возникающие при работе со старшим поколением, насколько возможно с помощью одновременной маркировки и очистки, но без дефрагментации. Однако как только область памяти, относящаяся к OG, будет сильно фрагментирована, то вызывается дефрагментация с stop-the-world.
Цикл сборки мусора CMS состоит из нескольких этапов, основные этапы следующие:
· начальная маркировка (initial mark): работа CMS начинается с очень короткой stop-the-world паузы, в течении которой сборщик мусора находит так называемые корневые (root) ссылки на объекты, созданные приложением
· одновременная маркировка (concurrent mark): во время этого этапа CMS отмечает все объекты, достижимые из корневых объектов, то есть все «живые» объекты, которые не должны удаляться сборщиком мусора. Этот этап выполняется одновременно с работой приложения
· повторная маркировка (remark): так как во время этапа одновременной маркировки потоки приложения продолжали работать, и в это время они могли создавать новые объекты и модифицировать ссылки, то к концу этого этапа нет гарантии, что все живые объекты были отмечены. Чтобы решить эту проблему CMS ещё раз приостанавливает приложение и завершает маркировку, проверяя все объекты, которые были изменены пользовательскими потоками во время выполнения предыдущего этапа. Поскольку повторная маркировка может занимать довольно много времени, то на многопроцессорных машинах этот этап выполняется несколькими параллельными потоками.
· одновременная очистка (concurrent sweep): после завершения этапа повторной маркировки все живые объекты в приложении были отмечены, и во время этапа одновременной очистки CMS удаляет весь найденный мусор (все неотмеченные объекты). Этот этап не требует приостановки приложения.
Таким образом, CMS разделяет всю работу по очистке OldGen на несколько частей, некоторые из которых могут выполняться одновременно с работой приложения, и за счёт этого избегает продолжительных stop-the-world пауз. В то же время из-за особенностей алгоритма общее количество работы, выполняемое CMS, становится больше по сравнению с последовательным сборщиком мусора (например, из-за необходимости повторной маркировки), и в результате этого при использовании CMS общая производительность приложения может несколько уменьшиться.
IBM J9 optthruput делает практически то же самое.
Oracle HotSpot G1GC (Garbage First)
Сборщик мусора с поколениями, но принцип работы другой. Вся heap разбита на регионы фиксированного размера. Набор регионов генерируются динамически и могут быть eden, survivor space или старшим поколением(OG). Если объект не помещается в один регион, то он храниться в наборе смежных регионов и называется “humongous”. Предполагается, что некоторые регионы обладают бОльшой популярность, чем другие. При выполнении процедуры очистки памяти происходит следующее:
1) Выбираются регионы, где будет проходить GC – все молодое поколение и непопулярные регионы из старшего поколения, где нет живых объектов
2) Повторная маркировка для отлавливания новых объектов и модифицированных ссылок, на короткий промежуток времени устанавливается stop-the-world
3) Копирование в регионы, помеченные, как “To”, за счет этого происходит частичное «сжатие»
Также есть Remembered Set – информация о местонахождении ссылок на объекты из региона, которая позволяет использовать несколько независимых регионов в разных частях памяти, и отказаться от т.н. free list. Этот GC работает с большим heap-ом лучше предыдущих, и, в принципе, может предложить приемлемую производительность для heap-a размером в 10-15GB. Тем не менее, огромное количество багов, а также тот факт, что со временем G1 все равно вынужден прибегать к stop-the-world из-за сильной фрагментированности популярных регионов, не добавляет ему привлекательности. Также недостатком этого GC является снижение максимальной пропускной способности по сравнению с остальными GC.
IBM J9 balanced делает то же самое.
Azul C4
Наибольший интерес вызывает именно этот сборщик мусора, так как в своем описании он декларирует следующее:
«По-настоящему полностью фоновый, одновременный сборщик мусора, использующий свой собственный алгоритм C4 (Continuously Concurrent Compacting Collector), эксплуатируемый в Azul JVM. С4 одновременно дефрагментирует оба поколения, молодое и старшее. В отличии от других алгоритмов, он не «в большинстве случаев одновременный», а действительно работает с потоками приложения всегда одновременно, т.е. stop-the-world не вызывается никогда. С4 использует Loaded Value Barrier (LVB) для проверки каждой ссылки, а каждая модифицированная ссылка отлавливается с помощью “self-healing” метода. С4 гарантирует, что все ссылки будут маркированы за один проход GC. Также гарантируется, что объекты будут перемещены, а ссылки на них модифицированы одновременно с работой приложения, не препятствуя его работе и не вызывая «stop-the-world»»
Также в описания этого продукта приводятся следующие графики сравнения с некоторыми текущими реализациями GC:
По пропускной способности:
По времени отклика:
Если по пропускной способности наблюдается некий паритет, а в большинстве случаев видно, что Parallel GC работает лучше, то на графике, показывающем зависимость времени отклика от размера heap-a, можно увидеть, что Azul C4 безусловно лидирует во всех случаях. Однако было бы неправильным поверить этим графикам, просто посмотрев на них, и не вникания в детали, которые могли бы дать нам понимание, откуда берётся столь существенная разница по сравнению с «традиционными» GC? Для того чтобы сделать это надо разобрать алгоритм, по которому действует Azul C4.
Выше я упоминал две основные причины, приводящие к возникновению “stop-the-world” пауз. Это фрагментация области памяти со старшим поколением и маркировка живых объектов. Если мы не будем дефрагментировать память, то рано или поздно получим “Out of memory”, если дефрагментировать память одновременно с работой приложения, то получим неправильные данные. В случае же с маркировкой есть опасность удалить «живые» объекты из памяти, что потом приведет к сообщениям об их недоступности.
Для разрешения этих проблем в алгоритме сборщика мусора Azul C4 используется аппаратная эмуляция так называемого «барьера на чтение» (read barrier). В Azul C4 он имеет название LVB (Load Value Barrier), и именно он помогает гарантировать работу сборщика мусора и приложения в параллельном режиме.
Azul C4 также использует два поколения – молодое и старшее, память занимаемая этими поколениями, дефрагментируются одновременно с выполнением приложения. На рисунке ниже представлены основные этапы очистки мусора. Всего их три – Mark, Relocate, Remap. Хотелось бы заметить, что Remap и Mark могут выполняться в одно и то же время. Что же происходить на каждом этапе?
Mark
На этом этапе происходит маркировка всех объектов, достижимых из корневых объектов, в памяти. Такие объекты помечаются, как «живые», все прочие подразумеваются, как «мертвые» и могут быть очищены. Он проходит одновременно с работой приложения и не вызывает «stop-the-world» паузу. В целом, он похож на стадию «concurrent mark» для CMS, но имеет несколько важных отличий. Во-первых, в дополнение к маркировке, Azul C4 также подсчитывает количество «живых» объектов в каждой странице памяти. Эта информация используется в дальнейшем для выбора страниц для переноса и дефрагментации в памяти. Во-вторых, алгоритм Azul C4 отслеживает все ссылки «живых» объектов с помощью архитектурно зарезервированного бита NMT в 64-битных ссылках. Этот бит, NMT (Not Marked Through), предназначен для отметки ссылки, как “marked through” в случае, если GC «прошел» её или, в противном случае, “not marked through”. Таким образом, Azul C4 отмечает все достижимые объекты, как «живые», и также, все ссылки, которые он «прошел», как «marked through». Как только этап Mark начался, потоки приложения, пытающиеся «пройти» по ссылке с битом NMT, выставленным в «not marked through», будут перехвачены «барьером на чтение» LVB. Аппаратная эмуляция этого барьера знает о функции бита NMT и может гарантировать, что потоки приложения никогда не получат доступ к ссылке, отмеченной как «not marked through». Если какой-либо из потоков приложения попробует сделать это, то процессор вызовет прерывание(trap) GC. Прерывание обработает ситуацию, вызвавшую его, следующим образом: поместит ссылку в список GC, поставит бит NMT в положение «marked through» и проверит бит NMT для объекта, откуда была загружена ссылка на правильность (должен иметь состояние “marked through”). После того, как прерывание будет обработано, работа потоков приложения возобновится. Использование этого механизма позволяет отметить все «живые» объекты за один проход, не вызывая повторную маркировку (как это делает CMS) и «stop-the-world» паузу. Также, устранение причины, вызвавшей прерывание, при обработке этого самого прерывания, оказывает эффект «самолечения», т.е. не позволяет этой же причине вызвать прерывание еще раз, что гарантирует конечный и предсказуемый объем работ по маркировке.
В целом, механизм прерываний позволяет проводить маркировку «живых» объектов за один проход, и при этом не вызывать «stop-the-world» паузу.
Relocate
На этом этапе GC освобождает память, занимаемую «мертвыми» объектами. При этом «живые» объекты он переносит в другую область памяти, тем самым дефрагментируя и уплотняя её. Для большей эффективности Azul C4 использует количество подсчитанных объектов на прошлом этапе (Mark) для того, чтобы первыми очистить страницы, в которых количество «мертвых» объектов сравнительно велико. Так как «живых» объектов в этих страницах мало, то их перенос занимает небольшой промежуток времени, в то же время, позволяя освобождать бОльшие объемы памяти в первую очередь, делая их доступными для приложения. Этап заканчивается, когда память, занимаемая «мертвые» объектами, будет полностью очищена. При этом «живые» объекты переносятся только из сильно фрагментированных страниц.
В начале этапа, используя механизм защиты памяти для того, чтобы ограничить доступ к определенным страницам памяти, сборщик мусора начинает перенос «живых» объектов в другие страницы памяти. Информация о начальном и новом адресе хранится в специальном массиве с «переадресацией указателей» (Forwarding Pointers), вынесенном отдельно от “From” пространства. Как только все «живые» объекты будут перенесены, физическая память становится доступной для потоков приложения. LVB используется для определения попыток доступа потоков к страницам памяти, в которых происходит процесс переноса «живых» объектов или переопределения адресов для этого объекта. Он перехватывает обращения потоков и сравнивает значение ссылки с имеющимися у него ссылками в буфере Translation Look-aside Buffer (TLS). Если значение совпадает со ссылкой, для которой сейчас происходит процесс перемещения, то вызывается прерывание. Это прерывание выполняет следующие действия: при помощи информации, находящейся в массиве Forwarding Pointers, определяется, перемещен ли уже объект или нет. Если объект уже перемещен в новую страницу памяти, то потоку возвращается новая ссылка на объект, а также переопределяется адрес для ссылки на объект, из которого он был загружен, для того, чтобы в дальнейшем он использовал новую ссылку. В случае, если объект еще не перемещен, то прерывание перемещает этот объект, не ожидая пока сборщик мусора обработает страницу памяти, где этот объект находится. После этого работа потока возобновляется. Использование того же эффекта «самолечения», что и на предыдущем этапе, дает возможность закончить этап перемещения в детерминированные сроки. Также, этап перемещения может быть завершен принудительно, если сборщик мусора решит, что сейчас выполнить этап маркирования будет эффективнее, чем продолжать этап перемещения объектов в памяти.
При рассмотрении этого этапа можно сказать, что такое поведение алгоритма и механизм прерываний гарантирует, что потоки не будут ожидать момента, пока сборщик мусора закончит работу с перемещением и переопределением адресов, тем самым позволяя сборщику мусора работать действительно одновременно с потоками и не вызывать «stop-the-world» паузу.
Remap
Этот этап завершает переопределение адресов для всех перемещенных объектных ссылок и гарантирует отсутствие ссылок на старое расположение в heap-е для перемещенных объектов. Эти ссылки могут существовать в начале этапа переопределения, так как heap может содержать ссылки на объекты, которые не посещались потоками после их перемещения. Когда этап переопределения адресов завершается, механизм защиты памяти отключается, а массив Forwarding Pointers становиться больше не нужен. Переопределение адресов выполняется следующим образом: сканируются все «живые» объекты в heap-e и переопределяются для них ссылки, если они указывают на объекты, перемещенные в новые страницы памяти. Этот этап совпадает с этапом маркировки, они выполняются одновременно, т.е. процесс маркировки находит живые объекты и помечает их, а также выставляет бит NMT, как «marked through». В то же время, процесс переназначения адресов находит ссылки на перемещенные объекты и переопределяет их соответственно новым адресам. На протяжении всего времени выполнения процессов маркировки и переопределения адресов механизм «барьера на чтение» продолжает «отлавливать» потоки приложения, обращающиеся к перенесенным объектам, вызывая прерывание, возвращающее потоку новый адрес расположения объекта.
Таким образом, Azul C4 может проводить одновременную маркировку, а также переопределение адресов, не вызывая «stop-the-world» паузу.
Подводя итог теоретическому описанию алгоритма Azul C4 можно сказать, что он действительно позволяет работать приложению одновременно со сборщиком мусора. Механизм LVB несколько понижает общую пропускную способность JVM, но стабилизирует время отклика на минимальном уровне, исключая паузы «stop-the-world» полностью. Для компаний, специализирующихся на предоставлении услуг через Интернет и приложений, где время отклика критично для бизнеса, Azul C4 выглядит наиболее привлекательной JVM.
Несмотря на всё это, теория должна подтверждаться практикой. В жизни Azul JVM поставляется как в виде «железки», так и в виде виртуальной машины. Аппаратная платформа Azul Vega 3 уже хорошо себя зарекомендована в финансовых компаниях. Виртуальная реализация Azul JVM приобретает всё большую популярность в мире, отчасти из-за того, что её можно развернуть на любом x86 железе, отчасти из-за того, что задачи, ставящиеся перед Java-приложениями, становятся серьезнее. Кстати, Azul C4 является не единственным преимуществом в Azul JVM, есть еще несколько отличий, выгодно отличающих Azul от конкурентов. Подробное описание этих достоинств займет столько же места, сколько занимает эта статья – поэтому лучше их оставить для отдельной статьи, где можно рассмотреть Azul JVM в общем виде. Если по названиям – то это DirectPathVMTM, Optimistic Thread Concurrency, мониторинг и профилирование выполнения приложений.
На сайте Azul Systems можно увидеть несколько десятков случаев из жизни, где преимущества Azul-a нашли свое применение.
Компании, использующие Azul JVM
Из личной практики могу представить пример реализации Azul JVM в жизни у крупного клиента – трейдинговой компании:
Конфигурация JVM:
| Native Configuration | Azul Configuration |
| -Xms2g -Xmx2g -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:TargetSurvivorRatio=80 -XX:CMSInitiatingOccupancyFraction=85 -XX:SurvivorRatio=8 -XX:MaxNewSize=320m -XX:NewSize=320m -XX:MaxTenuringThreshold=10 |
-Xms3g –Xmx3g |
Если подвести итог всему вышеизложенному, то можно сказать, что концепция, реализованная в Azul C4, действительно работает в реальной жизни, позволяет иметь heap размером до 1 Терабайта и избавить от головной боли, связанной с настройкой размера heap-a и тюнингом GC, при этом добиться стабильного и минимального времени отклика приложения.
Техническое описание алгоритма Azul C4

