Я хотел написать статью про линейную регрессию, но потом подумал, да ну её, лучше куплю квартиру. И пошёл искать, что предлагают. А предлагают, как оказалось, много чего. В подходящий мне ценовой диапозон попало больше 500 квартир. И что, мне теперь все это просматривать? Ну нееет, программист я в конце концов или не программист. Надо это дело как-то автоматизировать.
Прежде чем что-то решать, было бы неплохо взглянуть на общую картину, увидеть некую выжимку из данных. А для этого данные нужно сначала собрать. Меня интересовали квартиры в Минске до $60k (надеюсь, москвичи не подавились слюной, узнав, что за такие деньги реально купить квартиру?). Google сразу выдал несколько сайтов о недвижимости, среди которых наибольшее количество нужных мне настроек поиска оказалось на irr.by. Дизайн у него, конечно, не фонтан, но и я не девочка блондинка, чтобы выбирать сайт недвижимости по цвету. Да и данные в виде HTML-страниц меня в любом случае не устраивали.
За пару часов я накидал парсер, который принимал на вход строку поиска, пробегал по 5 первым страницам результатов и собирал интересующие меня параметры. А интересовали меня следующие вещи:
Единственное, что вызвало вопросы, — это расстояние до метро. Сайты недвижимости обычно не предоставляют такой информации. Есть только название улицы, номер дома и ближайшая станция, а вот сколько до неё идти — об этом ни слова. К счастью, оказалось, что проблема определения координат по адресу не нова, и называется соответсвующий процесс не иначе как геокодирование, а Корпорация Бабла даже предоставляет бесплатный сервис для этого доброго дела. После получаса программирования с перерывом на кофе и печеньки модуль определения расстояния до метро по адресу был готов. (Следует отметить, что результаты оказались весьма точными — из примерно 50 проверенных адресов только 2 указали на улицу, но не на дом; остальные же были полностью корректны. Также стоит обратить внимание на то, что сервис лучше не DDOS-ить — если не делать небольшие перерывы между запросами, могут возникать ошибки.)
Поскольку продавцы далеко не всегда тщательно и аккуратно заполняют поля для описания квартиры, данные были неполны. По-хорошему, незаполненные поля нужно было отмечать как NA (Not Available) и передавать их дальше в таком виде. Но дело было вечером, а делать ещё было чего, поэтому я решил пойти по упрощённой схеме и ещё на этапе сбора данных забивать значения по умолчанию. При отсутствии информации о годе постройки я забивал 1980 (соответственно, возраст — 32 года), расстояние до метро — 2000 метров, этаж — 4, этажность — 7. Очень просто и почти наугад. Количество комнат, площадь и цена были обязательными параметрами, и при их отсутствии квартира просто отбрасывалась (хотя в итоге ни одного случая отсутствия хотя бы одного из этих параметров выявлено не было).
Отдельно нужно рассказать про тип санузла. Предвидя числовые вычисления я понимал, что работать со значениями «общий/раздельный» гораздо сложней, чем с числами, поэтому пришлось завести 2 отдельные переменные, по одной на каждый тип. При этом если одна переменная была равна 1, то вторая обязательно равнялась 0. В статистике это называется фиктивными или индикаторными переменными.
Но хватит про туалеты, пора посмотреть на данные.
Одним из самых популярных средств анализа данных является проект R. R представляет собой среду разработки и язык программирования с широкими возможностями для манипулирования и визуализации данных, а также статистического анализа и машинного обучения. Существует несколько сред разработки для удобного редактирования скриптов, таких как RStudio и плагин для Emacs, но для большинства задач достаточно обычной консоли. Всё это кроссплатформено и совершенно бесплатно, то есть даром. R несомненно заслуживает отдельной развёрнутой статьи, здесь же я ограничусь описанием тех функций и конструкций языка, которые непосредственно буду использовать.
Парсер объявлений, который я описывал выше, сохранял полученные данные в виде CSV файла на диске. Чтобы загрузить его в R достаточно вызвать следующую функцию:
Первое, что бросается в глаза, это необычный оператор присваивания `<-`. Вместо него можно использовать и привычный символ `=`, однако это не приветствуется. Кроме того, стрелочный оператор может быть и инвертирован, т.е. предыдущую строку можно было эквивалетно переписать как:
Объект dat (имя «data» уже используется для функции загрузки встроенных наборов данных) имеет тип `data.frame`. Пусть вас не смущает точка в имени типа — в R точки являются абсолютно легальной частью идентификатора, как, например, `_` в C или `-` в Lisp (имена с точкой часто встречаются в старом коде, сейчас, по крайней мере для функций, их стараются не использовать из-за введения систем объектно-ориентированного программирования, интерпретирующих точки по своему). Фрейм данных напоминает собой таблицу в реляционных БД: колонки могут иметь разные типы, а доступ к ним можно осуществлять как по индексу, так и по имени колонки. Например, чтобы получить все данные из колонки price (6-ой по счёту) достаточно написать:
или
Синтаксис доступа к отдельным элементам фрейма данных похож на синтаксис доступа к элементам матрицы в традиционных языках программирования:
Однако есть и несколько нестандартных функций:
Как я уже говорил, R предоставляет прекрасные средства визуализации данных. Одним из них является функция plot(). Эта функция полиморфна и может быть использована для объектов разных типов, но в простейшем случае она принимает просто 2 вектора (или любых типа, которые можно привести к вектору) одинаковой длины и отображает их точечную диаграму (scatter plot). Больше информации о функции plot() можно получить, напечатав в консоли R следующее:
Для начала меня интересовало, на сколько комнат я могу рассчитывать за такие деньги. Следующая команда отображает точечную диаграмму зависимости цены от количества комнат:
Результат:
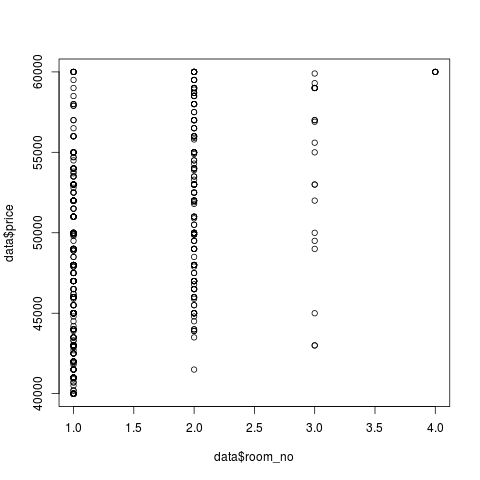
Ого! Есть 3-хкомнатные и даже 4-хкомнатные квартиры! Но всё не может быть так просто. Обычно на цену сильно влияет расстояние до метро. Посмотрим на значение переменной dist_to_subway для этих квартир:
В первой строке мы вначале фильтруем данные, оставляя только квартиры с 4 комнатами (`dat[dat$room_no == 4, ]`), а затем бёрем значения интересующего нас атрибута (`$dist_to_subway`). Во второй строке — результат в виде вектора. Как можно видеть, все квартиры имеют либо значение по умолчанию (2000 метров), либо больше. В любом случае это значит, что топать до метро придётся долго. Возможно, кого-то это устраивает, но не меня. С трёхкомнатными та же ситуация. А вот среди двухкомнатных оказалось много квартир со вполне приемлимым расстоянием до метро. На них я и решил остановиться, выбросив из данных 1-, 3- и 4-хкомнатные, а также отбросив колонки с количеством комнат (оно у нас фиксировано) и с URL страницы с описанием квартиры (для вычислений он нам ни к чему). Также, как оказалось, все из отфильтрованных квартир имеют раздельный санузел, а значит колонки restroom_sep и restroom_com для всех записей одинаковы, а значит брать их в расчёт также нет смысла.
На этом этапе мы уже можем чётко сформулировать задачу: выделить из всего набора квартир те, которые имеют наилучшее соотношение цена/качество.
Прежде чем идти дальше, посмотрим, насколько сильно атрибуты коррелируют друг с другом. Функция cor(), вызванная для фрейма данных, вычисляет корреляционную матрицу, элементы которой как раз и показывают, насколько один атрибут зависит от другого (формат вывода результата сохранён):
Как видно из матрицы, большая корреляция (> 0.6) наблюдается только между общей и жилой площадью, а также между общей площадью и площадью кухни. Это позволяет нам пренебречь ещё 2-мя атрибутами — living_space и kitchen_space — положившись на total_space.
Здравый смысл подсказывает, что цена линейно зависит от общей площади. До формального определения линейной зависимости мы ещё дойдём, сейчас же ограничимся визуальным аспектом: если одна переменная (например, цена) линейно зависит от другой (например, площади квартиры), то на точечной диаграмме их зависимости должна просматриваться прямая линия. Ну что ж, проверим это предположение:
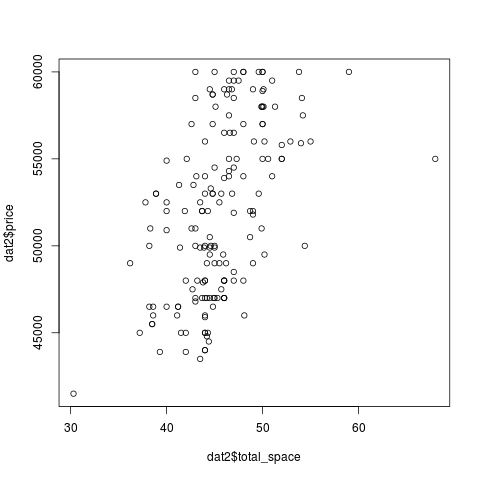
Да уж, с таким разбросом это больше похоже на облако. Тем не менее, если и проводить линию, отражающую зависимость, то она будет прямой, а не какой-нибудь параболой.
По идее, для расстояния от метро и возраста дома должна также наблюдаться линейная зависимость, но из-за большого количества записей со значением по умолчанию графики получаются скомканными:
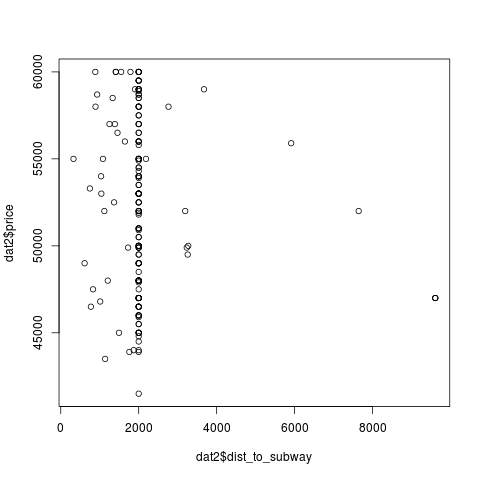
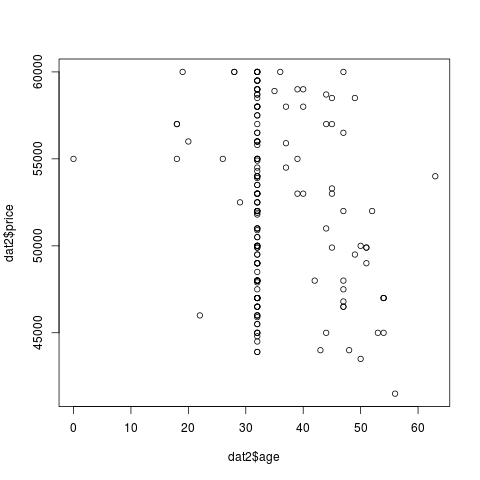
Как видно, если отбросить точки, соответсвующие значениям по умолчанию, то можно заметить вполне чёткую зависимость, однако эта зависимость обратная — чем больше расстояние до метро, тем меньше цена, и то же самое с возрастом дома.
Основываясь на информации, полученной при визуализации данных, можно сделать вывод, что цена линейно зависит от параметров квартиры. Также можно выдвинуть гипотезу, что среднестатистическая цена квартиры с некоторым набором параметров является показателем её «хорошести». В этом случае мы можем вывести функцию зависимости качества квартиры от её параметров. А имея такую функцию, легко посчитать, какие из имеющихся на рынке квартир переоценены их хозяевами, а какие сильно недооценены. Именно последние нас и будут интересовать — ведь заплатить за товар меньше, чем он реально стоит, всегда приятней, чем наоборот.
Так всё-таки, что такое линейная зависимость? И почему она так называется? Чтобы понять это, вспомним школьный курс математики, а именно уравнение линии на плоскости:
Знакомо? Думаю, да. Именно это уравнение и выражает линейную зависимость переменной y от переменной x, и именно его (хотя и с большим количеством «шума») мы видели на графиках зависимости цены от таких параметров как площадь, возраст и расстояние от метро.
А что, если у нас 2 свободные переменные? Тогда речь уже идёт об уравнении плоскости в пространстве:
Если обобщить эту идею до n свободных переменных, то мы получим уравнение так называемой гиперплоскости в гиперпространстве:
Здесь
В случае нашего (уменьшенного) фрейма данных уравнение имеет вид:
Ну что ж, осталось только найти коэффициенты
Здесь символ ~ указывает на то, что мы передаём в функцию lm() аргумент типа «формула». Формула описывает общий вид уравнения, для которого мы хотим вычислить коэффициенты, в данном случае R понимает, что мы хотим получить уравнение, аналогичное указанному выше. Второй аргумент (в данном случае именованный) показывает, в каком фрейме данных искать указанные переменные (age, balcony, etc.). То же самое можно записать и короче:
Здесь точка указывает, что левая часть уравнения зависит от всех переменных указанного фрейма данных (кроме как от себя сомой, разумеется).
Что же мы можем делать с построенной моделью? Ну, в первую очередь, мы можем посмотреть значения вычисленных коэффициентов:
Однако наиболее важным для нас вариантом использования построенной модели является расчёт реальной стоимости квартиры. И в этом нам поможет полиморфная функция predict(), которая принимает на вход модель и фрейм данных, и возвращает вектор «предсказанных» значений зависимой переменной:
Ещё немного уличной магии для визуализации результата:

Точки, оказавшиеся над красной линией — это переоценённые квартиры. Оказавшиемя под линией — недооценённые. Причём чем дальше от линии, тем более недооценены эти квартиры. Из графика видно, что есть довольно много квартир с ценой гораздо ниже предсказанной стоимости. Именно с них и следует начинать происк.
Можно даже пойти дальше и посчитать коэффициенты недооценённости квартир. Для этого достаточно разделить
Как можно видеть, 343-я по счёту (в изначальном фрейме данных) квартира недооценена почти на 20% (а это около $10k, как никак), следующая за ней 233 — на 15% и т.д. Неплохая может получится экономия, не так ли?
Дополнительный бонус линейной регресси: при желании коэффициенты модели можно отредактировать вручную, добавив дополнительный вес тем из них, которые важны именно для нас, а затем повторить сравнение.
Весь анализ, включая написание парсера и исследование геокодинга, занял меньше 8 часов. В методе всё ещё много ошибок и недоработок: расстояние до метро можно было бы измерять гораздо точней, за значение по умолчанию следовало бы брать среднее арифметическое из известных записей, а также неплохо было бы использовать и другие признаки, такие как состояние квартиры и ремонт. Однако даже такого наивного подхода хватило, чтобы значительно уменьшить количество ручной работы в разы. Отсюда можно сделать несколько выводов. Во-первых, интеллектуальный анализ данных применим не только к большим промышленным системам, но и к обычным бытовым вопросам. Во-вторых, он позволяет получить значительно более точное представление о данных, чем простой перебор вручную. Ну и, в-третьих, он значительно экономит время на исследование.
Оформление документов на новую квартиру уже началось. Пора бы задуматься о ремонте. Так, где у нас там сайт стройматериалов?..
Ссылки:
1. Исходники парсера. Для использования парсера достаточно скачать flatparser.jar (нажать на соотсветствующую ссылку, затем на View Raw) и запустить в соответствии с README.
2. Курс по машинному обучению на Coursera, где, в частности, подробно рассказывается про линейную регрессию.
Сбор данных
Прежде чем что-то решать, было бы неплохо взглянуть на общую картину, увидеть некую выжимку из данных. А для этого данные нужно сначала собрать. Меня интересовали квартиры в Минске до $60k (надеюсь, москвичи не подавились слюной, узнав, что за такие деньги реально купить квартиру?). Google сразу выдал несколько сайтов о недвижимости, среди которых наибольшее количество нужных мне настроек поиска оказалось на irr.by. Дизайн у него, конечно, не фонтан, но и я не девочка блондинка, чтобы выбирать сайт недвижимости по цвету. Да и данные в виде HTML-страниц меня в любом случае не устраивали.
За пару часов я накидал парсер, который принимал на вход строку поиска, пробегал по 5 первым страницам результатов и собирал интересующие меня параметры. А интересовали меня следующие вещи:
- цена (далее — переменная price)
- возраст (age)
- расстояние до метро (dist_to_subway)
- этаж (storey) и этажность дома (storey_no)
- наличие балкона или лоджии (balcony)
- общая (total_space) и жилая площадь (living_space), а также площадь кухни (kitchen_space)
- количество раздельных комнат (room_no)
- тип санузла (restroom_com для общего, restroom_sep для раздельного)
Единственное, что вызвало вопросы, — это расстояние до метро. Сайты недвижимости обычно не предоставляют такой информации. Есть только название улицы, номер дома и ближайшая станция, а вот сколько до неё идти — об этом ни слова. К счастью, оказалось, что проблема определения координат по адресу не нова, и называется соответсвующий процесс не иначе как геокодирование, а Корпорация Бабла даже предоставляет бесплатный сервис для этого доброго дела. После получаса программирования с перерывом на кофе и печеньки модуль определения расстояния до метро по адресу был готов. (Следует отметить, что результаты оказались весьма точными — из примерно 50 проверенных адресов только 2 указали на улицу, но не на дом; остальные же были полностью корректны. Также стоит обратить внимание на то, что сервис лучше не DDOS-ить — если не делать небольшие перерывы между запросами, могут возникать ошибки.)
Поскольку продавцы далеко не всегда тщательно и аккуратно заполняют поля для описания квартиры, данные были неполны. По-хорошему, незаполненные поля нужно было отмечать как NA (Not Available) и передавать их дальше в таком виде. Но дело было вечером, а делать ещё было чего, поэтому я решил пойти по упрощённой схеме и ещё на этапе сбора данных забивать значения по умолчанию. При отсутствии информации о годе постройки я забивал 1980 (соответственно, возраст — 32 года), расстояние до метро — 2000 метров, этаж — 4, этажность — 7. Очень просто и почти наугад. Количество комнат, площадь и цена были обязательными параметрами, и при их отсутствии квартира просто отбрасывалась (хотя в итоге ни одного случая отсутствия хотя бы одного из этих параметров выявлено не было).
Отдельно нужно рассказать про тип санузла. Предвидя числовые вычисления я понимал, что работать со значениями «общий/раздельный» гораздо сложней, чем с числами, поэтому пришлось завести 2 отдельные переменные, по одной на каждый тип. При этом если одна переменная была равна 1, то вторая обязательно равнялась 0. В статистике это называется фиктивными или индикаторными переменными.
Но хватит про туалеты, пора посмотреть на данные.
Первый взгляд на данные
Одним из самых популярных средств анализа данных является проект R. R представляет собой среду разработки и язык программирования с широкими возможностями для манипулирования и визуализации данных, а также статистического анализа и машинного обучения. Существует несколько сред разработки для удобного редактирования скриптов, таких как RStudio и плагин для Emacs, но для большинства задач достаточно обычной консоли. Всё это кроссплатформено и совершенно бесплатно, то есть даром. R несомненно заслуживает отдельной развёрнутой статьи, здесь же я ограничусь описанием тех функций и конструкций языка, которые непосредственно буду использовать.
Парсер объявлений, который я описывал выше, сохранял полученные данные в виде CSV файла на диске. Чтобы загрузить его в R достаточно вызвать следующую функцию:
> dat <- read.csv("/path/to/dataset.csv")
Первое, что бросается в глаза, это необычный оператор присваивания `<-`. Вместо него можно использовать и привычный символ `=`, однако это не приветствуется. Кроме того, стрелочный оператор может быть и инвертирован, т.е. предыдущую строку можно было эквивалетно переписать как:
> read.csv("/path/to/dataset.csv") -> dat
Объект dat (имя «data» уже используется для функции загрузки встроенных наборов данных) имеет тип `data.frame`. Пусть вас не смущает точка в имени типа — в R точки являются абсолютно легальной частью идентификатора, как, например, `_` в C или `-` в Lisp (имена с точкой часто встречаются в старом коде, сейчас, по крайней мере для функций, их стараются не использовать из-за введения систем объектно-ориентированного программирования, интерпретирующих точки по своему). Фрейм данных напоминает собой таблицу в реляционных БД: колонки могут иметь разные типы, а доступ к ним можно осуществлять как по индексу, так и по имени колонки. Например, чтобы получить все данные из колонки price (6-ой по счёту) достаточно написать:
> dat[6]
или
> dat["price"] # есть также специальный синтаксис - dat$price
Синтаксис доступа к отдельным элементам фрейма данных похож на синтаксис доступа к элементам матрицы в традиционных языках программирования:
> dat[3, 6] # 3 запись из 6 колонки
Однако есть и несколько нестандартных функций:
> dat[1:10, 1:6] # подфрейм, образованный из первых 10 строк и первых 6 колонок > dat[1:10, c(3, 5)] # первые 10 строк и колонки 3 и 5 > dat[, 6] # все строки 6-й колонки (аналогично dat[6]) > dat[, -6] # все строки всех колонок, кроме 6 > dat[,] # все строки всех колонок (аналогично dat)
Как я уже говорил, R предоставляет прекрасные средства визуализации данных. Одним из них является функция plot(). Эта функция полиморфна и может быть использована для объектов разных типов, но в простейшем случае она принимает просто 2 вектора (или любых типа, которые можно привести к вектору) одинаковой длины и отображает их точечную диаграму (scatter plot). Больше информации о функции plot() можно получить, напечатав в консоли R следующее:
> ?plot
Для начала меня интересовало, на сколько комнат я могу рассчитывать за такие деньги. Следующая команда отображает точечную диаграмму зависимости цены от количества комнат:
> plot(dat$room_no, dat$price)
Результат:
Ого! Есть 3-хкомнатные и даже 4-хкомнатные квартиры! Но всё не может быть так просто. Обычно на цену сильно влияет расстояние до метро. Посмотрим на значение переменной dist_to_subway для этих квартир:
> dat[dat$room_no == 4, ]$dist_to_subway [1] 2000.000 2000.000 2000.000 2000.000 4305.613
В первой строке мы вначале фильтруем данные, оставляя только квартиры с 4 комнатами (`dat[dat$room_no == 4, ]`), а затем бёрем значения интересующего нас атрибута (`$dist_to_subway`). Во второй строке — результат в виде вектора. Как можно видеть, все квартиры имеют либо значение по умолчанию (2000 метров), либо больше. В любом случае это значит, что топать до метро придётся долго. Возможно, кого-то это устраивает, но не меня. С трёхкомнатными та же ситуация. А вот среди двухкомнатных оказалось много квартир со вполне приемлимым расстоянием до метро. На них я и решил остановиться, выбросив из данных 1-, 3- и 4-хкомнатные, а также отбросив колонки с количеством комнат (оно у нас фиксировано) и с URL страницы с описанием квартиры (для вычислений он нам ни к чему). Также, как оказалось, все из отфильтрованных квартир имеют раздельный санузел, а значит колонки restroom_sep и restroom_com для всех записей одинаковы, а значит брать их в расчёт также нет смысла.
> dat2 <- dat[dat$room_no == 2, -с(7, 8, 9, 13)]
На этом этапе мы уже можем чётко сформулировать задачу: выделить из всего набора квартир те, которые имеют наилучшее соотношение цена/качество.
Прежде чем идти дальше, посмотрим, насколько сильно атрибуты коррелируют друг с другом. Функция cor(), вызванная для фрейма данных, вычисляет корреляционную матрицу, элементы которой как раз и показывают, насколько один атрибут зависит от другого (формат вывода результата сохранён):
> cor(dat2) age balcony dist_to_subway kitchen_space living_space age 1.0000000 0.23339483 0.23677636 -0.30167358 -0.18938523 balcony 0.2333948 1.00000000 -0.06881481 0.05694279 -0.03505876 dist_to_subway 0.2367764 -0.06881481 1.00000000 0.22700865 -0.21201038 kitchen_space -0.3016736 0.05694279 0.22700865 1.00000000 0.10018058 living_space -0.1893852 -0.03505876 -0.21201038 0.10018058 1.00000000 price -0.2246434 0.18848129 -0.11713353 0.35152990 0.22979332 storey -0.1740015 0.12504337 -0.03107719 0.22760853 0.09702503 storey_no -0.4683041 -0.28689325 -0.15872038 0.10098619 0.02122686 total_space -0.3732784 0.02748897 0.03466465 0.62723545 0.61874577 price storey storey_no total_space age -0.2246434 -0.17400151 -0.46830412 -0.37327839 balcony 0.1884813 0.12504337 -0.28689325 0.02748897 dist_to_subway -0.1171335 -0.03107719 -0.15872038 0.03466465 kitchen_space 0.3515299 0.22760853 0.10098619 0.62723545 living_space 0.2297933 0.09702503 0.02122686 0.61874577 price 1.0000000 0.35325897 0.24603010 0.51735302 storey 0.3532590 1.00000000 0.26811766 0.18082811 storey_no 0.2460301 0.26811766 1.00000000 0.14940533 total_space 0.5173530 0.18082811 0.14940533 1.00000000
Как видно из матрицы, большая корреляция (> 0.6) наблюдается только между общей и жилой площадью, а также между общей площадью и площадью кухни. Это позволяет нам пренебречь ещё 2-мя атрибутами — living_space и kitchen_space — положившись на total_space.
Визуализация зависимостей
Здравый смысл подсказывает, что цена линейно зависит от общей площади. До формального определения линейной зависимости мы ещё дойдём, сейчас же ограничимся визуальным аспектом: если одна переменная (например, цена) линейно зависит от другой (например, площади квартиры), то на точечной диаграмме их зависимости должна просматриваться прямая линия. Ну что ж, проверим это предположение:
> plot(dat2$dist_to_subway, dat2$price)
Да уж, с таким разбросом это больше похоже на облако. Тем не менее, если и проводить линию, отражающую зависимость, то она будет прямой, а не какой-нибудь параболой.
По идее, для расстояния от метро и возраста дома должна также наблюдаться линейная зависимость, но из-за большого количества записей со значением по умолчанию графики получаются скомканными:
> plot(dat2$dist_to_subway, dat2$price)
> plot(dat2$age, dat2$price)
Как видно, если отбросить точки, соответсвующие значениям по умолчанию, то можно заметить вполне чёткую зависимость, однако эта зависимость обратная — чем больше расстояние до метро, тем меньше цена, и то же самое с возрастом дома.
Линейная модель
Основываясь на информации, полученной при визуализации данных, можно сделать вывод, что цена линейно зависит от параметров квартиры. Также можно выдвинуть гипотезу, что среднестатистическая цена квартиры с некоторым набором параметров является показателем её «хорошести». В этом случае мы можем вывести функцию зависимости качества квартиры от её параметров. А имея такую функцию, легко посчитать, какие из имеющихся на рынке квартир переоценены их хозяевами, а какие сильно недооценены. Именно последние нас и будут интересовать — ведь заплатить за товар меньше, чем он реально стоит, всегда приятней, чем наоборот.
Так всё-таки, что такое линейная зависимость? И почему она так называется? Чтобы понять это, вспомним школьный курс математики, а именно уравнение линии на плоскости:
y = k * x + b
Знакомо? Думаю, да. Именно это уравнение и выражает линейную зависимость переменной y от переменной x, и именно его (хотя и с большим количеством «шума») мы видели на графиках зависимости цены от таких параметров как площадь, возраст и расстояние от метро.
k здесь показывает угол наклона графика функции к оси X, а b — смещение по оси Y относительно начала координат. А что, если у нас 2 свободные переменные? Тогда речь уже идёт об уравнении плоскости в пространстве:
z = k1 * x + k2 * y + b
Если обобщить эту идею до n свободных переменных, то мы получим уравнение так называемой гиперплоскости в гиперпространстве:
h(X) = k0 + k1 * x1 + k2 * x2 + ... + kn * xn
Здесь
x1..xn — это измерения гиперпространства, а h(X) — положение зависимой точки на гиперплоскости при заданных значениях переменных вектора X. В случае нашего (уменьшенного) фрейма данных уравнение имеет вид:
price = k0 + k1 * age + k2 * balcony + k3 * dist_to_subway + k4 * storey + k5 * storey_no + k6 * total_space
Ну что ж, осталось только найти коэффициенты
k0..k6 и формула готова! Однако, как подобрать эти коэффициенты так, чтобы вычисленная цена наиболее точно соответствовала реальным данным? Здесь в ход и идёт линейная регрессия. Линейная регрессия пытается подобрать коэффициенты так, чтобы минимизировать квадрат разности между предсказанным значением зависимой переменной (цены, в нашем случае) и его реальным, известным из статистических данных. Более подробно про вычисление коэффициентов можно послушать по ссылкам в конце статьи, а здесь же я воспользуюсь средствами R, а именно функцией lm() (сокращение от Linear Model): > model <- lm(price ~ age + balcony + dist_to_subway + storey + storey_no + total_space, data = dat2)
Здесь символ ~ указывает на то, что мы передаём в функцию lm() аргумент типа «формула». Формула описывает общий вид уравнения, для которого мы хотим вычислить коэффициенты, в данном случае R понимает, что мы хотим получить уравнение, аналогичное указанному выше. Второй аргумент (в данном случае именованный) показывает, в каком фрейме данных искать указанные переменные (age, balcony, etc.). То же самое можно записать и короче:
> model <- lm(price ~ ., data = dat2)
Здесь точка указывает, что левая часть уравнения зависит от всех переменных указанного фрейма данных (кроме как от себя сомой, разумеется).
Что же мы можем делать с построенной моделью? Ну, в первую очередь, мы можем посмотреть значения вычисленных коэффициентов:
> coef(model) (Intercept) age balcony dist_to_subway storey 21601.0057018 31.7479138 1981.3750585 -0.3962895 529.9350262 storey_no total_space 594.3711746 523.7914531
(Intercept) соответсвует коэффициенту k0 и может быть интерпретирован как минимальная стоимость квартиры при всех параметрах равных нулю (сложно, конечно, представить квартиру площадью ноль квадратных метров, но идею, я думаю, вы поняли). Названия остальных коэффициентов говорят сами за себя. Коэффициент при переменной total_space показывает реальную стоимость квадратного метра (в отличие от той, которую обычно расчитывают риэлторы, не учитывающие коэффициента сдвига — intercept). Наличие балкона прибавляет квартире сразу 2 тысячи долларов, а вот расстояние до метро уменьшает стоимость на 40 центов с каждым метром. Единственный параметр, который вызывает сомнения, это возраст. По логике, чем старше квартира, тем дешевле она должна быть. Однако коэффициент при этой переменной положительный, хотя и не очень большой. Объяснений для такого феномена может быть несколько. Во-первых, как можно было видеть из графиков, разброс цен очень сильный, а это добавляет огромное количество шума. Во-вторых, способ сбора данных далеко не совершенен, а значит многие квартиры, которые мы пометили как 32-летние (значение по умолчанию) на самом деле могли быть гораздо старше. Ну и в-третьих, мы просто не учитываем множества других факторов, таких как проведение капитального ремонта в доме, который сильно поднимает цену и который мы вообще не брали в расчёт. Однако наиболее важным для нас вариантом использования построенной модели является расчёт реальной стоимости квартиры. И в этом нам поможет полиморфная функция predict(), которая принимает на вход модель и фрейм данных, и возвращает вектор «предсказанных» значений зависимой переменной:
> predicted.cost <- predict(model, dat2)
Ещё немного уличной магии для визуализации результата:
> actual.price <- dat2$price # сохраняем вектор цен в отдельную переменную для удобства > plot(predicted.cost, actual.price) # предсказанная стоимость vs. цены из имеющихся данных > par(new=TRUE, col="red") # параметры графика: рисовать на той же конве, использовать красный > dependency <- lm(predicted.cost, actual.price) # ещё одна модель, на этот раз вспомогательная > abline(dependency) # отображаем вспомогательную модель в виде линии
Точки, оказавшиеся над красной линией — это переоценённые квартиры. Оказавшиемя под линией — недооценённые. Причём чем дальше от линии, тем более недооценены эти квартиры. Из графика видно, что есть довольно много квартир с ценой гораздо ниже предсказанной стоимости. Именно с них и следует начинать происк.
Можно даже пойти дальше и посчитать коэффициенты недооценённости квартир. Для этого достаточно разделить
> sorted <- sort(predicted.cost / actual.price, decreasing = TRUE) > sorted[1:10] 343 233 15 485 326 81 384 279 1.182516 1.154181 1.145964 1.144113 1.132918 1.132496 1.132098 1.129221 385 175 1.126982 1.115920
Как можно видеть, 343-я по счёту (в изначальном фрейме данных) квартира недооценена почти на 20% (а это около $10k, как никак), следующая за ней 233 — на 15% и т.д. Неплохая может получится экономия, не так ли?
Дополнительный бонус линейной регресси: при желании коэффициенты модели можно отредактировать вручную, добавив дополнительный вес тем из них, которые важны именно для нас, а затем повторить сравнение.
Заключение
Весь анализ, включая написание парсера и исследование геокодинга, занял меньше 8 часов. В методе всё ещё много ошибок и недоработок: расстояние до метро можно было бы измерять гораздо точней, за значение по умолчанию следовало бы брать среднее арифметическое из известных записей, а также неплохо было бы использовать и другие признаки, такие как состояние квартиры и ремонт. Однако даже такого наивного подхода хватило, чтобы значительно уменьшить количество ручной работы в разы. Отсюда можно сделать несколько выводов. Во-первых, интеллектуальный анализ данных применим не только к большим промышленным системам, но и к обычным бытовым вопросам. Во-вторых, он позволяет получить значительно более точное представление о данных, чем простой перебор вручную. Ну и, в-третьих, он значительно экономит время на исследование.
Оформление документов на новую квартиру уже началось. Пора бы задуматься о ремонте. Так, где у нас там сайт стройматериалов?..
Ссылки:
1. Исходники парсера. Для использования парсера достаточно скачать flatparser.jar (нажать на соотсветствующую ссылку, затем на View Raw) и запустить в соответствии с README.
2. Курс по машинному обучению на Coursera, где, в частности, подробно рассказывается про линейную регрессию.

