При написании приложений, одной из важнейших вопросов являются потребление памяти и отзывчивость (скорость работы).
Считается, что сборщик мусора – черный ящик, работу которого нельзя предугадать.
А еще говорят, что GC в .NET практически не настраиваемый. А еще, что нельзя посмотреть исходники как классов .NET Framework, так и CLR, GC и т.п.
А я скажу как бы ни так!
В данной статье мы рассмотрим:
Однажды я уже писал про определение размеров CLR-объектов. Чтобы не пересказывать статью, давайте лишь вспомним основные моменты.
Для переменных ссылочных типов при использовании CIL-инструкции newobj или, например, оператора new в C#, в стек помещается значение фиксированного размера (4 байта, например, для x86, тип DWORD), содержащее адрес экземпляра объекта, созданного в обычной куче (не забываем что управляемая куча делится на Small Object Heap и Large Object Heap — об этом чуть позже в параграфе про GC). Так, в C++ это значение называется указателем на объект, а в мире .NET — ссылкой на объект.
Ссылка живет в стеке при выполнении любого метода, либо живет в поле какого-либо класса.
Вы не можете создать объект в вакууме без создания ссылки.
Чтобы не было спекуляций по поводу размеров объектов и проведения каких-либо тестов с помощью SOS (Son of Strike), измерения GC.TotalMemory и т.п. — просто посмотрим на исходники CLR, а точнее Shared Source Common Language Infrastructure 2.0, являющийся своего рода исследовательским проектом.
Каждый тип имеет свой MethodTable, и все экземпляры объектов одного и того же типа ссылаются на один и тот же MethodTable. Данная таблица хранит информацию о самом типе (интерфейс, абстрактный класс и т.д.).
Каждый объект содержит два дополнительных поля – заголовок объекта, в котором хранится адрес SyncTableEntry (запись syncblk), и Method Table Pointer (TypeHandle).
SyncTableEntry – структура, хранящая ссылку на CLR-объект и ссылку на сам SyncBlock.
SyncBlock – структура данных, в которой хранится хеш-код для любого объекта.
Говоря «для любого» значит, что CLR заранее инициализирует определенное количество SyncBlock’ов. Далее при вызове GetHashCode(), либо Monitor.Enter() среда просто вставляет в заголовок объекта указатель на уже готовый SyncBlock, попутно вычисляя хеш-код.
Делается это вызовом метода GetSyncBlock (смотрим файл
Метод System.Object.GetHashCode полагается на структуру SyncBlock вызывая метод SyncBlock::GetHashCode.
Первоначальное значение syncblk равно 0 для CLR 2.0, но начиная с CLR 4.0 значение равняется -1.
При вызове Monitor.Exit() syncblk опять становится равной -1.
Хочется также заметить, что массив SyncBlock’ов хранится в отдельной памяти, недоступной GC.
Как же так? Спросите Вы.
Ответ прост – слабые ссылки. CLR создает слабую ссылку на запись в SyncBlock массиве. Когда CLR-объект умирает, SyncBlock обновляется.
Реализация метода Monitor.Enter() зависит от платформы и самого JIT. Так псевдонимом для данного метода в исходниках SSCLI является JIT_MonEnter.
Возвращаясь к теме размещения объектов в памяти и их размеров, хочется вспомнить, что любой экземпляр объекта (пустой класс) занимает минимум 12 байт в x86, а в x64 уже 24 байта.
Убедимся в этом без запуска SOS.
Переходим в файл
В комментариях к той статье про размеры CLR-объектов меня упрекнули в неточности расчета размера System.String без каких-либо доказательств.
Однако я больше доверяю цифрам и … исходному коду!
System.String в .NET 4.0 состоит из следующих членов:
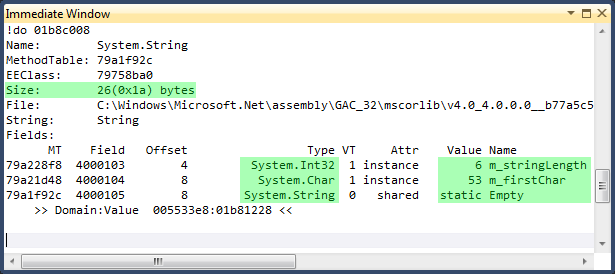
Empty в расчет не берем, т.к. это пустая статичная строка.
m_stringLength указывает длину строки.
m_firstChar является указателем (!!!) на начало хранения массива юникодных символов, а не первым символом в массиве.
Здесь не используется какая-либо магия – CLR просто находит оффсет.
Чтобы в этом убедиться снова открываем файл %папка с архивом%\sscli20\clr\src\vm\object.h
В самом начале файла видим комментарии к коду:
Вот это и есть внутренняя структура хранения строковых данных.
Далее находим класс StringObject и его метод GetBuffer().
Что ж, буфер (он же массив символов) просто вычисляется оффсетом.
А как же обстоит дело с самим System.String?
Открываем файл %папка с архивом%\sscli20\clr\src\bcl\system\string.cs
Видим следующие строки:
Однако System.String в своей работе полагается на COMString, реализующим сам конструктор, а также многие методы (PadLeft и т.п.).
Чтобы правильно сопоставить названия методов из фреймворка и внутренних C++ реализаций советую посмотреть файл
Ну и чтобы окончательно убедиться в том, что m_firstChar является указателем, рассмотрим, например, часть кода метода Join:
Немного другой вариант с подсчетом (но с такими же результатами) приводит знаменитый Jon Skeet.
Перед тем как двигаться вперед, хотелось бы вспомнить и про стек.
Стек – контейнер, создаваемый средой при каждом вызове любого метода. В нем хранятся все данные, необходимые для завершения вызова (адреса локальных переменных, параметры и т.д.).
Таким образом, вызовы дерево вызовов представляют собой FIFO-контейнер, состоящий из стеков. При завершении вызова текущего метода, стек очищается и уничтожается, возвращая управление родительской ветке.
Как я уже писал выше, для переменных ссылочных типов, в стек помещается значение фиксированного размера (4 байта, например, для x86, тип DWORD), содержащее адрес экземпляра объекта, созданного в обычной куче.
В стеке по-умолчанию размещаются экземпляры примитивных типов, не участвующих в упаковке (boxing).
Однако при некоторых оптимизациях JIT- может сразу же расположить значения переменных в регистрах процессора, минуя ОЗУ.
Вспомним, что такое регистр процессора — блок ячеек памяти, образующий сверхбыструю оперативную память внутри процессора, использующаяся самим процессором и большой частью недоступен программисту.
Чем больше кэш CPU, тем более высокую производительность Вы можете получить, независимо от программной платформы.
Как известно, управлением памятью (созданием и уничтожением объектов) занимается сборщик мусора – он же Garbage Collector (GC).
Для работы приложения CLR сразу же инициализирует два сегмента виртуального адресного пространства – Small Object Heap и Large Object Heap.
Небольшая заметка: виртуальная память представляет собой логическое представление памяти, а не физическое. Физическая память выделяется только по мере необходимости. Каждому процессу в современной операционной системе выделяется виртуальное адресное пространство максимально адресуемого размера (4GB для 32-х битных ОС) с разделением на страницы (для платформ x86, IA-64, PowerPC-64 минимальный размер составляет 4KB, SPARC – 8 KB). Благодаря этому становится возможным изолирование адресного пространства одного процесса от другого, а также появляется возможность использования подкачки на диске.
Для выделения и возвращения обратно системе памяти GC использует Win32-функции VirtualAlloc и VirtualFree.
Сборщик мусора в .NET является generational, т.е. управляемая куча (соответственно и объекты) делится на поколения. Все объекты делятся по жизненному циклу на несколько поколений.
Источником ссылок на объекты служат так называемые GC roots:
В данном случае всего существует 3 поколения:
Первоначальный размер каждого сегмента (SOH, LOH) варьируется и зависит от конкретной машины (обычно это 16 MB для десктопа и 64MB для сервера). Хочу заметить, что это именно виртуальная память – приложение может занимать вообще 5 MB физической памяти.
В LOH попадают объекты не только размером более 85 000 байт, но также некоторые типы массивов.
Так массив из System.Double при размере 10 600 элементов (85000 / 8 байт) должен попасть в LOH. Однако это происходит уже при размере 1000+.
Объекты в управляемой куче располагаются один за другим, что в случае удаления большого количества объектов может приводить к фрагментации.
Однако для решения данной проблемы CLR – всегда (за исключением ручного управления памятью) дефрагментирует Small Object Heap.
Процесс выглядит следующим образом: текущие объекты копируются в свободную память (пробелы в куче, которые автоматически исчезают).
Таким образом, достигается минимальное потребление памяти, однако это требует и определенного процессорного времени. Однако это не должно волновать, т.к. для объектов Gen0, Gen1 задержка составляет всего лишь 1 мс.
Что же насчет Large Object Heap? Она никогда не дефрагментируется (почти никогда). Это потребовало бы большое количество времени, что может сказаться плохо на работе приложения. Однако это не значит, что CLR начинает потреблять все больше и больше памяти просто так. Во время Full-GC (Gen0, Gen1, Gen2) система все же возвращает ОС память, освобождаясь от уже мертвых объектами из LOH (или дефрагментацией SOH).
Также CLR располагает новые объекты в LOH не только один за другим, как в SOH, например, но и на местах уже свободной памяти, не дожидаясь Full-GC.
Запуск GC не детерминирован, за исключением вызова метода GC.Collect().
Однако все же существуют приблизительные критерии, по которым можно это предсказать (следует помнить, что нижеперечисленные условия приблизительны и CLR сама приспосабливается к поведению приложения, многое еще зависит и от вида сборщика мусора):
Также сборка мусора запускается при нехватке системой памяти. CLR для этого использует Win32-функции CreateMemoryResourceNotification и QueryMemoryResourceNotification.
Еще одним моментом, при работе с памятью является использование неуправляемых ресурсов.
Т.к. неуправляемые ресурсы могут содержать любые объекты вне зависимости от длительности жизни и GC не детерминирован, то для этих целей существует финализатор.
При запуске приложения, CLR находит типы с финализаторами и исключает их из обычной сборки мусора (но это не означает, что объекты не привязаны к поколениям).
После окончания работы GC, в отдельном потоке обрабатываются финализируемые объекты (вызов метода Finalize).
Пример реализации паттерна Dispose:
Рассмотрим теперь сами GC, доступные в .NET Framework.
До выхода .NET 4.0 были доступны два режима Server и Workstation.
Workstation mode – GC максимально оптимизирован для работы на клиентских машинах. Старается особо не загружать процессор, а также работает с минимальными задержками для приложений с UI. Доступен в двух режимах – параллельном и синхронном.
При параллельном режиме GC запускается в отдельном потоке (с приоритетом normal) для Gen2-поколения, блокируя при этом работу эфемерных поколений (аллокации новых объектов не возможны, все потоки приостановлены).
Если приложению доступно очень (!!!) много свободной памяти, то SOH не становится компактным (GC жертвует память, ради отзывчивости приложения).
Таким образом, Workstation mode – идеально подходит для GUI-приложений.
Кроме того, если необходимо использовать именно серверный GC, то включить его можно так:
Для проверки можно использовать в коде свойство GCSettings.IsServerGC.
Для принудительного отключения Workstation Concurrent GC, используем следующие параметры:
По-умолчанию, параллельный режим включен для Workstation GC. Однако, если процессор – одноядерный, то GC автоматически переходит в синхронный режим.
Рассмотрим теперь Server GC.
Server GC разделяет управляемую кучу на сегменты, количество которых равно количеству логических процессоров, используя для обработки каждого из них по одному потоку.
Небольшая заметка: логический процессор необязательно соответствует физическому процессору. Системы с несколькяими физическими процессорами (т.е. несколькими сокетами) и многоядерные процессоры предоставляют ОС множество логических процессоров, причем ядро (!!!) также может представлять собой более 1 логического процессора (например, при использовании технологии Hyper-threading от Intel).
Также одним из главных отличий является свойство GCSettings.LatencyMode, доступное с .NET Framework 3.5 SP1 (состоящее из трех режимов).
По-умолчанию, LatencyMode для Workstation Concurrent GC установлен как Interactive, Server – Batch.
Существует еще и LowLatency, но его использование может привести к OutOfMemoryException, т.к. в данном режиме GC Полная сборка мусора происходит только в случае высокой нагрузки на память. Также его нельзя включить для Server GC.
В чем же разница между Batch и Interactive?
Т.к. Server GC делит управляемую кучу на несколько сегментов (каждый их которых обслуживает отдельный логический процессор), то в параллельной сборке мусора уже нет необходимости (если бы еще один поток запускался на др. логическом процессоре). Этот режим принудительно переопределяет параметр gcConcurrent. Если включен режим gcConcurrent, режим Batch будет препятствовать дальнейшей параллельной сборке мусора (!!!). Batch эквивалентен непараллельной сборке мусора на рабочей станции. При использовании такого режима характерна обработка больших (!!!) объемов данных.
Следует помнить, что изменение значения GCLatencyMode влияет на текущие запущенные потоки, что означает воздействие на саму среду исполнения и неуправляемый код.
А т.к. потоки могут выполняться на различных логических процессорах, то отсутствует гарантия мгновенного перевода режима GC.
А что если другой поток, захочет изменить данное значение. А если потоков 100?
Чувствуете, что назревает проблема для многопоточного приложения? И особенно для CLR – ведь может быть вызвано исключение в самой среде, а не в коде приложения.
Именно для таких случаев и существует constrained execution region (CER) – гарантия обработки всех исключений (как синхронных, таки асинхронных).
В блоке кода, помеченного как CER, среде исполнения запрещается бросать некоторые асинхронные исключения.
Например, при вызове Thread.Abort() поток, исполняемый под CER, не будет прерван до тех пор, пока не завершится исполнение CER-защищенного кода.
Также CLR при инициализации подготавливает CER, чтобы гарантировать работу даже при нехватке памяти.
Рекомендуется не использовать CER для больших участков кода, т.к. существует ряд ограничений для такого рода кода: boxing, вызов виртуальных методов, вызов методов через reflection, использование Monitor.Enter и т.д.
Но не будем углубляться в это дело и посмотрим, как безопасно переключить режим LatencyMode.
Что же, мы уже рассмотрели основную часть работы GC в .NET – никаких вопросов не возникло?
Точно нет? И даже ничего не смутило?
Хм…неужели вопрос о невозможности аллокации новых объектов в эфемерных поколениях никак не заинтересовал?
А вот команду .NET – да :)
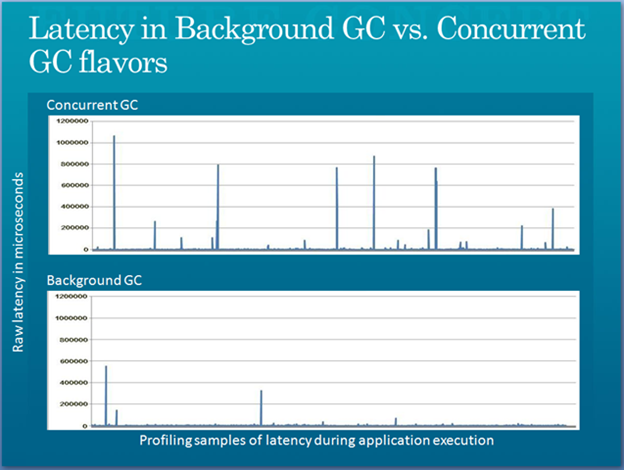
Теперь нам доступен новый Background GC для Workstation mode (начиная с .NET 4.5 и для Server).
Целью его создания было уменьшение задержек при Full-GC, в частности Gen2.
Background GC – это тот же самый Concurrent GC, за одним исключением – при Full-GC эфемерные поколения не блокируется для аллокации новых объектов.
Согласитесь, что обработка Gen2 и LOH весьма затратное дело. А блокирование Gen0, Gen1 – т.е. обычной работы приложения может вызывать задержки (при определенных ситуациях).
Еще один вопрос, который адресует новый GC – откладывание аллокации новых объектов при достижении лимита размеров управляемой кучи (16 MB – desktop, 64 – server).
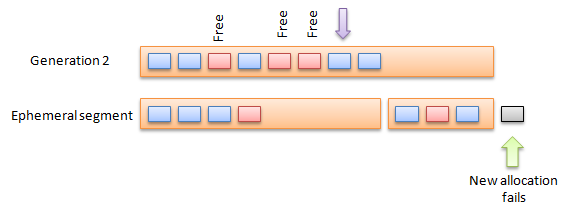
Теперь для предотвращения такой ситуации действует не только background thread для Gen2, но еще и foreground thread (да-да, у нас есть еще и Foreground GC), который помечает мертвые объекты из эфемерных поколений и объединяет текущие эфемерные поколения с Gen2 (т.к. объединение менее затратная операция, чем копирование) и передает их на обработку background thread, тем самым позволяя выделять память под новые объекты (напоминаю, что в Background GC Gen0, Gen1 не блокируются во время работы GC для Gen2).

Уменьшение количества задержек можно сравнить на нижеприведенном графике:
Одним из самых интересных и необычных возможностей CLR и, в частности, C#- ручное управление памятью, т.е. работа с указателями.
Вообще, это уже третий тип в .NET — Pointer Type. Представляет он собой DWORD-адрес на конкретный экземпляр либого Value Type. Т.е. нам недоступны Reference Types.
Но также мы можем работать с неуправляемым кодом.
Для таких целей создана структура System.Runtime.InteropServices.GCHandle – объекты с фиксированным адресом, предоставляющие возможность доступа к управляемому объекту из неуправляемой памяти.
Для GCHandle CLR использует отдельную таблицу для каждого AppDomain.
GCHandle уничтожаются при вызове GCHandle.Free(), либо при выгрузке AppDomain.
Для создания используется метод GChandle.Alloc().
Доступны следующие режимы аллокации:
Более подробно про GCHandle — MSDN.
Когда может понадобиться ручная работа с памятью, спросите Вы?
Например, для копирования массива байтов.
Помните, что GC дефрагментирует SOH? При некоторых ситуациях фиксация объектов в куче может привести к неэффективной дефрагментации SOH.
Адреса объектов постоянно меняются (в .NET мы этого не чувствуем — среда сама обновляет ссылки). Но для неуправляемого кода – это непозволительно.
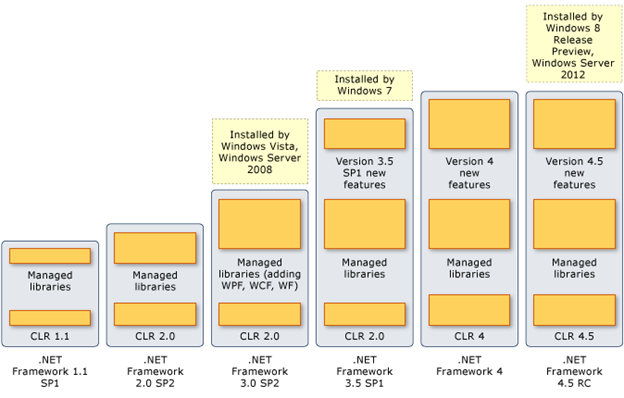
Приложение, написанное на .NET 2.0, спокойно может без изменения ни единой строчки кода и перекомпиляции работать на .NET 4.0.
[.NET Framework Versions and Dependencies]
Из обзора следует исключить .NET 1.1, так как современный, который мы знаем, начинается с версии 2.0.
.NET 3.5 состоит из CLR 2.0, версии библиотек 2.0 + новые для 3.0 + 3.5. Никаких значительных изменений в памяти, многопоточности, обработке исключений и т.п. не происходило.
Но .NET 4.0 принес массу приятных нововведений:
Для запуска CLR 2.0 приложений под CLR 4.0 необходимо указать следующие параметры:
Для использования старой модели безопасности:
Обработка системных SEH-исключений изменилась, но для обратной совместимости вносим следующие строчки в конфигурационный файл:
Если же Ваше приложение использует также и нативный код, то:
Таким образом, без изменения единой строчки кода и перекомпиляции мы спокойно можем использовать .NET 4.0.
Первой оптимизацией, которую проводит JIT – оптимизация, присущая и компилятору VC++, а именно – FastCall.
Суть метода заключается в том, что в регистры ECX, EDX записываются первые 2 параметра метода.
При платформе x64 – используются регистры RCX, RDX, R8, R9.
Что же это дает?
Например, при реализации какого-либо алгоритма наиболее часто используемый параметр следует выставить первым (пусть это и микрооптимизация, но все же).
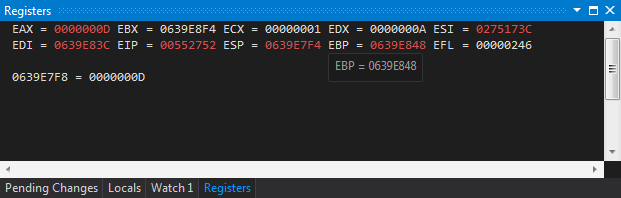
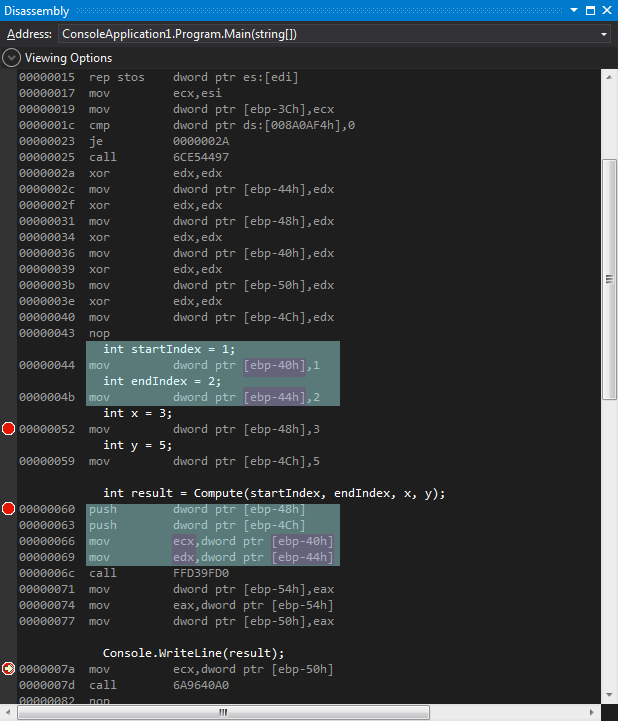
Так для вышеприведенного кода переменные startIndex и endIndex будут находиться именно в регистрах ECX, EDX, остальные (x, y) в стеке.
Проверим – для этого запустим дебаггер.
Для того чтобы посмотреть в текущие регистры наберем команду
Для просмотра сгенерированного ассемблера
Надеюсь, статья окажется полезной и интересной!
Спасибо за внимание!
Считается, что сборщик мусора – черный ящик, работу которого нельзя предугадать.
А еще говорят, что GC в .NET практически не настраиваемый. А еще, что нельзя посмотреть исходники как классов .NET Framework, так и CLR, GC и т.п.
А я скажу как бы ни так!
В данной статье мы рассмотрим:
- структура организации размещения объектов в памяти
- CLR 4.5 Background Server GC
- правильная настройка сборщика мусора
- эффективный апгрейд приложений до .NET 4.0+
- правильное ручное управление памятью
▌Структура организации размещения объектов в памяти
Однажды я уже писал про определение размеров CLR-объектов. Чтобы не пересказывать статью, давайте лишь вспомним основные моменты.
Для переменных ссылочных типов при использовании CIL-инструкции newobj или, например, оператора new в C#, в стек помещается значение фиксированного размера (4 байта, например, для x86, тип DWORD), содержащее адрес экземпляра объекта, созданного в обычной куче (не забываем что управляемая куча делится на Small Object Heap и Large Object Heap — об этом чуть позже в параграфе про GC). Так, в C++ это значение называется указателем на объект, а в мире .NET — ссылкой на объект.
Ссылка живет в стеке при выполнении любого метода, либо живет в поле какого-либо класса.
Вы не можете создать объект в вакууме без создания ссылки.
Чтобы не было спекуляций по поводу размеров объектов и проведения каких-либо тестов с помощью SOS (Son of Strike), измерения GC.TotalMemory и т.п. — просто посмотрим на исходники CLR, а точнее Shared Source Common Language Infrastructure 2.0, являющийся своего рода исследовательским проектом.
Каждый тип имеет свой MethodTable, и все экземпляры объектов одного и того же типа ссылаются на один и тот же MethodTable. Данная таблица хранит информацию о самом типе (интерфейс, абстрактный класс и т.д.).
Каждый объект содержит два дополнительных поля – заголовок объекта, в котором хранится адрес SyncTableEntry (запись syncblk), и Method Table Pointer (TypeHandle).
SyncTableEntry – структура, хранящая ссылку на CLR-объект и ссылку на сам SyncBlock.
SyncBlock – структура данных, в которой хранится хеш-код для любого объекта.
Говоря «для любого» значит, что CLR заранее инициализирует определенное количество SyncBlock’ов. Далее при вызове GetHashCode(), либо Monitor.Enter() среда просто вставляет в заголовок объекта указатель на уже готовый SyncBlock, попутно вычисляя хеш-код.
Делается это вызовом метода GetSyncBlock (смотрим файл
%папка с архивом%\sscli20\clr\src\vm\syncblk.cpp). В теле метода мы можем видеть следующий код:else if ((bits & BIT_SBLK_IS_HASHCODE) != 0) { DWORD hashCode = bits & MASK_HASHCODE; syncBlock->SetHashCode(hashCode); }
Метод System.Object.GetHashCode полагается на структуру SyncBlock вызывая метод SyncBlock::GetHashCode.
Первоначальное значение syncblk равно 0 для CLR 2.0, но начиная с CLR 4.0 значение равняется -1.
При вызове Monitor.Exit() syncblk опять становится равной -1.
Хочется также заметить, что массив SyncBlock’ов хранится в отдельной памяти, недоступной GC.
Как же так? Спросите Вы.
Ответ прост – слабые ссылки. CLR создает слабую ссылку на запись в SyncBlock массиве. Когда CLR-объект умирает, SyncBlock обновляется.
Реализация метода Monitor.Enter() зависит от платформы и самого JIT. Так псевдонимом для данного метода в исходниках SSCLI является JIT_MonEnter.
Возвращаясь к теме размещения объектов в памяти и их размеров, хочется вспомнить, что любой экземпляр объекта (пустой класс) занимает минимум 12 байт в x86, а в x64 уже 24 байта.
Убедимся в этом без запуска SOS.
Переходим в файл
%папка с архивом%\sscli20\clr\src\vm\object.h#define MIN_OBJECT_SIZE (2*sizeof(BYTE*) + sizeof(ObjHeader)) class Object { protected: MethodTable* m_pMethTab; }; class ObjHeader { private: DWORD m_SyncBlockValue; // the Index and the Bits };
В комментариях к той статье про размеры CLR-объектов меня упрекнули в неточности расчета размера System.String без каких-либо доказательств.
Однако я больше доверяю цифрам и … исходному коду!
System.String в .NET 4.0 состоит из следующих членов:
- m_firstChar
- m_stringLength
- Empty
Empty в расчет не берем, т.к. это пустая статичная строка.
m_stringLength указывает длину строки.
m_firstChar является указателем (!!!) на начало хранения массива юникодных символов, а не первым символом в массиве.
Здесь не используется какая-либо магия – CLR просто находит оффсет.
Чтобы в этом убедиться снова открываем файл %папка с архивом%\sscli20\clr\src\vm\object.h
В самом начале файла видим комментарии к коду:
/* * StringObject - String objects are specialized objects for string * storage/retrieval for higher performance */
Вот это и есть внутренняя структура хранения строковых данных.
Далее находим класс StringObject и его метод GetBuffer().
WCHAR* GetBuffer() { LEAF_CONTRACT; _ASSERTE(this); return (WCHAR*)( PTR_HOST_TO_TADDR(this) + offsetof(StringObject, m_Characters) ); }
Что ж, буфер (он же массив символов) просто вычисляется оффсетом.
А как же обстоит дело с самим System.String?
Открываем файл %папка с архивом%\sscli20\clr\src\bcl\system\string.cs
Видим следующие строки:
//NOTE NOTE NOTE NOTE //These fields map directly onto the fields in an EE StringObject. See object.h for the layout. // [NonSerialized]private int m_stringLength; [NonSerialized]private char m_firstChar;
Однако System.String в своей работе полагается на COMString, реализующим сам конструктор, а также многие методы (PadLeft и т.п.).
Чтобы правильно сопоставить названия методов из фреймворка и внутренних C++ реализаций советую посмотреть файл
%папка с архивом%\sscli20\clr\src\vm\ecall.cppНу и чтобы окончательно убедиться в том, что m_firstChar является указателем, рассмотрим, например, часть кода метода Join:
fixed (char* ptr = &text.m_firstChar) { UnSafeCharBuffer unSafeCharBuffer = new UnSafeCharBuffer(ptr, num); unSafeCharBuffer.AppendString(value[startIndex]); for (int j = startIndex + 1; j <= num2; j++) { unSafeCharBuffer.AppendString(separator); unSafeCharBuffer.AppendString(value[j]); } }
Немного другой вариант с подсчетом (но с такими же результатами) приводит знаменитый Jon Skeet.
Перед тем как двигаться вперед, хотелось бы вспомнить и про стек.
Стек – контейнер, создаваемый средой при каждом вызове любого метода. В нем хранятся все данные, необходимые для завершения вызова (адреса локальных переменных, параметры и т.д.).
Таким образом, вызовы дерево вызовов представляют собой FIFO-контейнер, состоящий из стеков. При завершении вызова текущего метода, стек очищается и уничтожается, возвращая управление родительской ветке.
Как я уже писал выше, для переменных ссылочных типов, в стек помещается значение фиксированного размера (4 байта, например, для x86, тип DWORD), содержащее адрес экземпляра объекта, созданного в обычной куче.
В стеке по-умолчанию размещаются экземпляры примитивных типов, не участвующих в упаковке (boxing).
Однако при некоторых оптимизациях JIT- может сразу же расположить значения переменных в регистрах процессора, минуя ОЗУ.
Вспомним, что такое регистр процессора — блок ячеек памяти, образующий сверхбыструю оперативную память внутри процессора, использующаяся самим процессором и большой частью недоступен программисту.
Чем больше кэш CPU, тем более высокую производительность Вы можете получить, независимо от программной платформы.
▌Устройство GC
Как известно, управлением памятью (созданием и уничтожением объектов) занимается сборщик мусора – он же Garbage Collector (GC).
Для работы приложения CLR сразу же инициализирует два сегмента виртуального адресного пространства – Small Object Heap и Large Object Heap.
Небольшая заметка: виртуальная память представляет собой логическое представление памяти, а не физическое. Физическая память выделяется только по мере необходимости. Каждому процессу в современной операционной системе выделяется виртуальное адресное пространство максимально адресуемого размера (4GB для 32-х битных ОС) с разделением на страницы (для платформ x86, IA-64, PowerPC-64 минимальный размер составляет 4KB, SPARC – 8 KB). Благодаря этому становится возможным изолирование адресного пространства одного процесса от другого, а также появляется возможность использования подкачки на диске.
Для выделения и возвращения обратно системе памяти GC использует Win32-функции VirtualAlloc и VirtualFree.
Сборщик мусора в .NET является generational, т.е. управляемая куча (соответственно и объекты) делится на поколения. Все объекты делятся по жизненному циклу на несколько поколений.
Источником ссылок на объекты служат так называемые GC roots:
- стек
- статичные (глобальные) объекты
- финализируемые объекты
- неуправляемые Interop-объекты (CLR-объекты, принимающие участие в COM/unmanaged вызовах)
- регистры процессора
- другие CLR-объекты со ссылками
В данном случае всего существует 3 поколения:
- Generation 0. Жизненный цикл объектов этого поколения самый короткий. Обычно к Gen0 относятся временные переменные, созданные в теле методов.
- Generation 1. Жизненный цикл объектов этого поколения также короткий. К нему относятся объекты с промежуточным временем жизни – объекты, переходящие из Gen0 в Gen2.
- Generation 2. Представляет собой наиболее долгоживущие объекты. Также объекты размером более 85 000 байт автоматически попадают в Large Object Heap и помечаются как Gen2.
Первоначальный размер каждого сегмента (SOH, LOH) варьируется и зависит от конкретной машины (обычно это 16 MB для десктопа и 64MB для сервера). Хочу заметить, что это именно виртуальная память – приложение может занимать вообще 5 MB физической памяти.
В LOH попадают объекты не только размером более 85 000 байт, но также некоторые типы массивов.
Так массив из System.Double при размере 10 600 элементов (85000 / 8 байт) должен попасть в LOH. Однако это происходит уже при размере 1000+.
Объекты в управляемой куче располагаются один за другим, что в случае удаления большого количества объектов может приводить к фрагментации.
Однако для решения данной проблемы CLR – всегда (за исключением ручного управления памятью) дефрагментирует Small Object Heap.
Процесс выглядит следующим образом: текущие объекты копируются в свободную память (пробелы в куче, которые автоматически исчезают).
Таким образом, достигается минимальное потребление памяти, однако это требует и определенного процессорного времени. Однако это не должно волновать, т.к. для объектов Gen0, Gen1 задержка составляет всего лишь 1 мс.
Что же насчет Large Object Heap? Она никогда не дефрагментируется (почти никогда). Это потребовало бы большое количество времени, что может сказаться плохо на работе приложения. Однако это не значит, что CLR начинает потреблять все больше и больше памяти просто так. Во время Full-GC (Gen0, Gen1, Gen2) система все же возвращает ОС память, освобождаясь от уже мертвых объектами из LOH (или дефрагментацией SOH).
Также CLR располагает новые объекты в LOH не только один за другим, как в SOH, например, но и на местах уже свободной памяти, не дожидаясь Full-GC.
Запуск GC не детерминирован, за исключением вызова метода GC.Collect().
Однако все же существуют приблизительные критерии, по которым можно это предсказать (следует помнить, что нижеперечисленные условия приблизительны и CLR сама приспосабливается к поведению приложения, многое еще зависит и от вида сборщика мусора):
- При достижении поколения Gen0 размера в 256 KB
- При достижении поколения Gen1 размера в 2 MB
- При достижении поколения Gen2 размера в 10 MB
Также сборка мусора запускается при нехватке системой памяти. CLR для этого использует Win32-функции CreateMemoryResourceNotification и QueryMemoryResourceNotification.
Еще одним моментом, при работе с памятью является использование неуправляемых ресурсов.
Т.к. неуправляемые ресурсы могут содержать любые объекты вне зависимости от длительности жизни и GC не детерминирован, то для этих целей существует финализатор.
При запуске приложения, CLR находит типы с финализаторами и исключает их из обычной сборки мусора (но это не означает, что объекты не привязаны к поколениям).
После окончания работы GC, в отдельном потоке обрабатываются финализируемые объекты (вызов метода Finalize).
Пример реализации паттерна Dispose:
class Foo : IDisposable { private bool _disposed; ~Foo() { Dispose(false); } public void Dispose() { Dispose(true); GC.SuppressFinalize(this); } protected virtual void Dispose(bool disposing) { if (!_disposed) { if (disposing) { // Free managed objects } // Free unmanaged objects _disposed = true; } } }
Рассмотрим теперь сами GC, доступные в .NET Framework.
До выхода .NET 4.0 были доступны два режима Server и Workstation.
Workstation mode – GC максимально оптимизирован для работы на клиентских машинах. Старается особо не загружать процессор, а также работает с минимальными задержками для приложений с UI. Доступен в двух режимах – параллельном и синхронном.
При параллельном режиме GC запускается в отдельном потоке (с приоритетом normal) для Gen2-поколения, блокируя при этом работу эфемерных поколений (аллокации новых объектов не возможны, все потоки приостановлены).
Если приложению доступно очень (!!!) много свободной памяти, то SOH не становится компактным (GC жертвует память, ради отзывчивости приложения).
Таким образом, Workstation mode – идеально подходит для GUI-приложений.
Кроме того, если необходимо использовать именно серверный GC, то включить его можно так:
<configuration> <runtime> <gcServer enabled="true"/> </runtime> </configuration>
Для проверки можно использовать в коде свойство GCSettings.IsServerGC.
Для принудительного отключения Workstation Concurrent GC, используем следующие параметры:
<configuration> <runtime> <gcConcurrent enabled="false"/> </runtime> </configuration>
По-умолчанию, параллельный режим включен для Workstation GC. Однако, если процессор – одноядерный, то GC автоматически переходит в синхронный режим.
Рассмотрим теперь Server GC.
Server GC разделяет управляемую кучу на сегменты, количество которых равно количеству логических процессоров, используя для обработки каждого из них по одному потоку.
Небольшая заметка: логический процессор необязательно соответствует физическому процессору. Системы с несколькяими физическими процессорами (т.е. несколькими сокетами) и многоядерные процессоры предоставляют ОС множество логических процессоров, причем ядро (!!!) также может представлять собой более 1 логического процессора (например, при использовании технологии Hyper-threading от Intel).
Также одним из главных отличий является свойство GCSettings.LatencyMode, доступное с .NET Framework 3.5 SP1 (состоящее из трех режимов).
По-умолчанию, LatencyMode для Workstation Concurrent GC установлен как Interactive, Server – Batch.
Существует еще и LowLatency, но его использование может привести к OutOfMemoryException, т.к. в данном режиме GC Полная сборка мусора происходит только в случае высокой нагрузки на память. Также его нельзя включить для Server GC.
В чем же разница между Batch и Interactive?
Т.к. Server GC делит управляемую кучу на несколько сегментов (каждый их которых обслуживает отдельный логический процессор), то в параллельной сборке мусора уже нет необходимости (если бы еще один поток запускался на др. логическом процессоре). Этот режим принудительно переопределяет параметр gcConcurrent. Если включен режим gcConcurrent, режим Batch будет препятствовать дальнейшей параллельной сборке мусора (!!!). Batch эквивалентен непараллельной сборке мусора на рабочей станции. При использовании такого режима характерна обработка больших (!!!) объемов данных.
Следует помнить, что изменение значения GCLatencyMode влияет на текущие запущенные потоки, что означает воздействие на саму среду исполнения и неуправляемый код.
А т.к. потоки могут выполняться на различных логических процессорах, то отсутствует гарантия мгновенного перевода режима GC.
А что если другой поток, захочет изменить данное значение. А если потоков 100?
Чувствуете, что назревает проблема для многопоточного приложения? И особенно для CLR – ведь может быть вызвано исключение в самой среде, а не в коде приложения.
Именно для таких случаев и существует constrained execution region (CER) – гарантия обработки всех исключений (как синхронных, таки асинхронных).
В блоке кода, помеченного как CER, среде исполнения запрещается бросать некоторые асинхронные исключения.
Например, при вызове Thread.Abort() поток, исполняемый под CER, не будет прерван до тех пор, пока не завершится исполнение CER-защищенного кода.
Также CLR при инициализации подготавливает CER, чтобы гарантировать работу даже при нехватке памяти.
Рекомендуется не использовать CER для больших участков кода, т.к. существует ряд ограничений для такого рода кода: boxing, вызов виртуальных методов, вызов методов через reflection, использование Monitor.Enter и т.д.
Но не будем углубляться в это дело и посмотрим, как безопасно переключить режим LatencyMode.
var oldMode = GCSettings.LatencyMode; System.Runtime.CompilerServices.RuntimeHelpers.PrepareConstrainedRegions(); try { GCSettings.LatencyMode = GCLatencyMode.Batch; // выполняем работу с большим объемом информации } finally { GCSettings.LatencyMode = oldMode; }
Что же, мы уже рассмотрели основную часть работы GC в .NET – никаких вопросов не возникло?
Точно нет? И даже ничего не смутило?
Хм…неужели вопрос о невозможности аллокации новых объектов в эфемерных поколениях никак не заинтересовал?
А вот команду .NET – да :)
Теперь нам доступен новый Background GC для Workstation mode (начиная с .NET 4.5 и для Server).
Целью его создания было уменьшение задержек при Full-GC, в частности Gen2.
Background GC – это тот же самый Concurrent GC, за одним исключением – при Full-GC эфемерные поколения не блокируется для аллокации новых объектов.
Согласитесь, что обработка Gen2 и LOH весьма затратное дело. А блокирование Gen0, Gen1 – т.е. обычной работы приложения может вызывать задержки (при определенных ситуациях).
Еще один вопрос, который адресует новый GC – откладывание аллокации новых объектов при достижении лимита размеров управляемой кучи (16 MB – desktop, 64 – server).
Теперь для предотвращения такой ситуации действует не только background thread для Gen2, но еще и foreground thread (да-да, у нас есть еще и Foreground GC), который помечает мертвые объекты из эфемерных поколений и объединяет текущие эфемерные поколения с Gen2 (т.к. объединение менее затратная операция, чем копирование) и передает их на обработку background thread, тем самым позволяя выделять память под новые объекты (напоминаю, что в Background GC Gen0, Gen1 не блокируются во время работы GC для Gen2).
Уменьшение количества задержек можно сравнить на нижеприведенном графике:
▌Ручное управление памятью
Одним из самых интересных и необычных возможностей CLR и, в частности, C#- ручное управление памятью, т.е. работа с указателями.
Вообще, это уже третий тип в .NET — Pointer Type. Представляет он собой DWORD-адрес на конкретный экземпляр либого Value Type. Т.е. нам недоступны Reference Types.
Но также мы можем работать с неуправляемым кодом.
Для таких целей создана структура System.Runtime.InteropServices.GCHandle – объекты с фиксированным адресом, предоставляющие возможность доступа к управляемому объекту из неуправляемой памяти.
Для GCHandle CLR использует отдельную таблицу для каждого AppDomain.
GCHandle уничтожаются при вызове GCHandle.Free(), либо при выгрузке AppDomain.
Для создания используется метод GChandle.Alloc().
Доступны следующие режимы аллокации:
- Normal
- Weak
- Weak Track Resurrection
- Pinned
Более подробно про GCHandle — MSDN.
Когда может понадобиться ручная работа с памятью, спросите Вы?
Например, для копирования массива байтов.
static unsafe void Copy(byte[] source, int sourceOffset, byte[] target, int targetOffset, int count) { fixed (byte* pSource = source, pTarget = target) { // Set the starting points in source and target for the copying. byte* ps = pSource + sourceOffset; byte* pt = pTarget + targetOffset; // Copy the specified number of bytes from source to target. for (int i = 0; i < count; i++) { *pt = *ps; pt++; ps++; } } }
Помните, что GC дефрагментирует SOH? При некоторых ситуациях фиксация объектов в куче может привести к неэффективной дефрагментации SOH.
Адреса объектов постоянно меняются (в .NET мы этого не чувствуем — среда сама обновляет ссылки). Но для неуправляемого кода – это непозволительно.
▌Правильная настройка сборщика мусора || Вопросы по поводу .NET 4.0+
Приложение, написанное на .NET 2.0, спокойно может без изменения ни единой строчки кода и перекомпиляции работать на .NET 4.0.
[.NET Framework Versions and Dependencies]
Из обзора следует исключить .NET 1.1, так как современный, который мы знаем, начинается с версии 2.0.
.NET 3.5 состоит из CLR 2.0, версии библиотек 2.0 + новые для 3.0 + 3.5. Никаких значительных изменений в памяти, многопоточности, обработке исключений и т.п. не происходило.
Но .NET 4.0 принес массу приятных нововведений:
- новую CLR
- новый GC
- новую систему обработки системных исключений
- новый Thread Pool
- новая модель безопасности
Для запуска CLR 2.0 приложений под CLR 4.0 необходимо указать следующие параметры:
<configuration> <startup> <supportedRuntime version="v4.0" sku=".NETFramework,Version=v4.0"/> </startup> </configuration>
Для использования старой модели безопасности:
<runtime> <NetFx40_LegacySecurityPolicy enabled="true"/> </runtime>
Обработка системных SEH-исключений изменилась, но для обратной совместимости вносим следующие строчки в конфигурационный файл:
<configuration> <runtime> <legacyCorruptedStateExceptionsPolicy enabled="true"/> </runtime> </configuration>
Если же Ваше приложение использует также и нативный код, то:
<startup useLegacyV2RuntimeActivationPolicy="true"> <supportedRuntime version="v4.0" sku=".NETFramework,Version=v4.0"/> </startup>
Таким образом, без изменения единой строчки кода и перекомпиляции мы спокойно можем использовать .NET 4.0.
▌Регистры процессора || FastCall
Первой оптимизацией, которую проводит JIT – оптимизация, присущая и компилятору VC++, а именно – FastCall.
Суть метода заключается в том, что в регистры ECX, EDX записываются первые 2 параметра метода.
При платформе x64 – используются регистры RCX, RDX, R8, R9.
Что же это дает?
Например, при реализации какого-либо алгоритма наиболее часто используемый параметр следует выставить первым (пусть это и микрооптимизация, но все же).
class Program { static void Main(string[] args) { int startIndex = 1; int endIndex = 2; int x = 3; int y = 5; int result = Compute(startIndex, endIndex, x, y); Console.WriteLine(result); } public static int Compute(int startIndex, int endIndex, int x, int y) { int result = 0; for (int i = startIndex; i < endIndex; i++) { result += x * startIndex + y * endIndex; } return result; } }
Так для вышеприведенного кода переменные startIndex и endIndex будут находиться именно в регистрах ECX, EDX, остальные (x, y) в стеке.
Проверим – для этого запустим дебаггер.
Для того чтобы посмотреть в текущие регистры наберем команду
CTRL + D, R.Для просмотра сгенерированного ассемблера
CTRL + ALT + D.Надеюсь, статья окажется полезной и интересной!
Спасибо за внимание!

