Иногда разработчики различных веб-проектов сталкиваются с необходимостью обработки больших объемов данных или использованием ресурсозатратного алгоритма. Старые инструменты уже не дают необходимой производительности, приходится арендовать/покупать дополнительные вычислительные мощности, что подталкивает к мысли переписать медленные участки кода на C++ или других быстрых языках.
В этой статье я расскажу о том, как можно попробовать ускорить работу Node.JS (который сам по себе считается довольно быстрым). Речь пойдет о нативных расширениях, написанных с помощью C++.
Итак, у вас имеется веб-сервер на Node.JS и вам поступила некая задача с ресурсозатратным алгоритмом. Для выполнения задачи было принято решение написать модуль на C++. Теперь нам надо разобраться с тем, что же это такое — нативное расширение.
Архитектура Node.JS позволяет подключать модули, упакованные в библиотеки. Для этих библиотек создаются js-обертки, с помощью которых вы можете вызывать функции этих модулей прямо из js-кода вашего сервера. Многие стандартные модули Node.JS написаны на C++, однако это не мешает пользоваться ими с таким удобством, как будто они были бы написаны на самом javascript'e. Вы можете передавать в свое расширение любые параметры, отлавливать исключения, выполнять любой код и возвращать обработанные данные обратно.
По ходу статьи мы разберемся в том, как создавать нативные расширения и проведем несколько тестов производительности. Для тестов возьмем не сложный, но ресурсозатратный алгоритм, который выполним на js и на C++. Например — вычислим двойной интеграл.
Возьмем функцию:
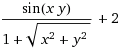
Эта функция задает следующую поверхность:
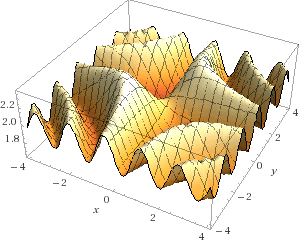
Для нахождения двойного интеграла нам необходимо найти объем фигуры, ограниченной данной поверхностью. Для этого разобьем фигуру на множество параллелепипедов, с высотой, равной значению функции. Сумма их объемов даст нам объем всей фигуры и численное значение самого интеграла. Для нахождения объема каждого параллелепипеда разобьем площадь под фигурой на множество маленьких прямоугольников, затем перемножим их площади ��а значение нашей функции в точках на краях этих прямоугольников. Чем больше параллелепипедов, тем выше точность.
Код на js, который выполняет это интегрирование и показывает нам время выполнения:
Теперь выполним все те же операции на C++. Лично я использовал Microsoft Visual Studio 2010. Для начала нам необходимо скачать исходники Node.JS. Идем на официальный сайт и подтягиваем последнюю версию исходников. В папке с исходниками лежит файл vcbuild.bat, который создает необходимые проекты для Visual Studio и конфиги. Для работы батника необходим установленный Python. Если у вас его нет — ставим с офф сайта. Прописываем пути к питону в переменную среды Path (для питона 2.7 это будут C:\Python27;C:\Python27\Scripts). Запускаем батник, получаем необходимые файлы. Далее создаем .cpp файл нашего модуля. Далее пишем описание нашего модуля в json-формате:
Сохраняем как binding.gyp и натравливаем на него утилиту, которую ставим с помощью npm. Эта утилита создает правильно настроенный файл студии vcxproj для windows или же makefile для linux. Так же одним товарищем был создан батник, еще сильнее упрощающий настройку и создание проекта для студии. Можете взять у него, вместе с примером helloworld-модуля. Редактируете файл, запускаете батник — получаете готовый .node модуль. Можно создать вручную проект Visual Studio и так же вручную вбить все настройки — пути к либам и хедерам node.js, configuration type ставим в .dll, target extension — .node.
Все настроено, приступаем к написанию кода.
В .cpp файле мы должны объявить класс, унаследованный от ObjectWrap. Все методы этого класса должны быть статичными.
Обязательно должна быть функция инициализации, которую мы вбиваем в макрос NODE_MODULE. В функции инициализации с помощью макроса NODE_SET_PROTOTYPE_METHOD мы указываем методы, которые будут доступны из Node.JS. Мы можем получать передаваемые параметры, проверять их количество и типы и при необходимости выдавать исключения. Подробное описание всех необходимых вещей, для создания расширения вы можете найти тут
Скомпилировав этот код получим .node файл (обычная DLL с другим расширением), который можно подключать к нашему Node.JS проекту. Файл содержит прототип js-объекта NativeIntegrator, который имеет метод integrateNative. Подключим полученный модуль:
Добавляем этот код к уже готовому проекту на Node.JS, вызываем функции, сравниваем:
Получаем результат:
JS result = 127.99999736028109
JS time = 127
Native result = 127.999997
Native time = 103
Разница минимальна. Увеличим количество итераций по осям в 8 раз. Получим следующие результаты:
JS result = 127.99999995875444
JS time = 6952
Native result = 128.000000
Native time = 6658
Результат удивляет. Мы не получили практически никакого выигрыша. Результат на Node.JS получается почти точно таким же, какой получается на чистом С++. Мы догадывались что V8 быстрый движок, но чтоб настолько… Да, даже чисто математические операции можно писать на чистом js. Потеряем мы от этого немного, если вообще что-то потеряем. Чтобы получить выигрыш от нативного расширения мы должны использовать низкоуровневую оптимизацию. Но это будет уже слишком. Выигрыш в производительности от нативного модуля далеко не всегда окупит затраты на написание сишного или даже ассемблерного кода. Что же делать? Первое что приходит на ум — использование openmp или нативных потоков, для параллельного решения задачи. Это ускорит решение каждой отдельно взятой задачи, но не увеличит количество решаемых задач в единицу времени. Так что такое решение подойдет не каждому. Нагрузка на сервер не снизится. Возможно мы так же получим выигрыш при работе с большим объемом памяти — у Node.JS все таки будут дополнительные накладные расходы и общий занимаемый объем памяти будет больше. Но память сейчас далеко не так критична, как процессорное время. Какие выводы мы можем сделать из данного исследования?
А давайте-ка все таки попробуем ускорить работу нашего кода? Раз у нас есть доступ из нативного расширения к чему угодно, то есть доступ и к видеокарте. Используем CUDA!
Для этого нам понадобится CUDA SDK, который можно найти на сайте Nvidia. Не буду рассказывать тут про установку и настройку, для этого и так есть множество мануалов. После установки SDK нам понадобится внести некоторые изменения в проект — переименуем исходник с .cpp на .cu. В настройки построения добавляем поддержку CUDA. В настройки компилятора CUDA добавляем необходимые зависимости. Вот новый код расширения, с комментариями к изменениям и добавлениям:
Напишем обработчик на js:
Запустим тестирование на следующих данных:
Получим результаты:
JS result = 127.99999736028109
JS time = 119
Native result = 127.999997
Native time = 122
CUDA result = 127.999997
CUDA time = 17
Как мы видим, обработчик на видеокарте уже показывает сильный отрыв. И это при том, что результаты работы каждого потока видеокарты я суммировал на CPU. Если написать алгоритм, полностью работающий на GPU, без использования центрального процессора, то выигрыш в производительности будет еще ощутимее.
Протестируем на следующих данных:
Получим результат:
JS result = 127.99999998968899
JS time = 25401
Native result = 128.000000
Native time = 28405
CUDA result = 128.000000
CUDA time = 3568
Как мы видим, разница огромна. Оптимизированный алгоритм на CUDA дал бы нам разницу в производительности более чем на порядок. (А C++ код на этом тесте даже отстал по производительности от Node.JS).
Ситуация, рассмотренная нами довольно экзотическая. Ресурсозатратные вычисления на веб-сервере с Node.JS, который стоит на машине с видеокартой, поддерживающей технологию CUDA. Такое не часто встретишь. Но если вам вдруг когда-нибудь придется с таким столкнуться — знайте, такие вещи реальны. Фактически в свой сервер на Node.JS вы можете встроить любую штуку, которую можно написать на C++. То есть все что угодно.
В этой статье я расскажу о том, как можно попробовать ускорить работу Node.JS (который сам по себе считается довольно быстрым). Речь пойдет о нативных расширениях, написанных с помощью C++.
Коротко о расширениях
Итак, у вас имеется веб-сервер на Node.JS и вам поступила некая задача с ресурсозатратным алгоритмом. Для выполнения задачи было принято решение написать модуль на C++. Теперь нам надо разобраться с тем, что же это такое — нативное расширение.
Архитектура Node.JS позволяет подключать модули, упакованные в библиотеки. Для этих библиотек создаются js-обертки, с помощью которых вы можете вызывать функции этих модулей прямо из js-кода вашего сервера. Многие стандартные модули Node.JS написаны на C++, однако это не мешает пользоваться ими с таким удобством, как будто они были бы написаны на самом javascript'e. Вы можете передавать в свое расширение любые параметры, отлавливать исключения, выполнять любой код и возвращать обработанные данные обратно.
По ходу статьи мы разберемся в том, как создавать нативные расширения и проведем несколько тестов производительности. Для тестов возьмем не сложный, но ресурсозатратный алгоритм, который выполним на js и на C++. Например — вычислим двойной интеграл.
Что считать?
Возьмем функцию:
Эта функция задает следующую поверхность:
Для нахождения двойного интеграла нам необходимо найти объем фигуры, ограниченной данной поверхностью. Для этого разобьем фигуру на множество параллелепипедов, с высотой, равной значению функции. Сумма их объемов даст нам объем всей фигуры и численное значение самого интеграла. Для нахождения объема каждого параллелепипеда разобьем площадь под фигурой на множество маленьких прямоугольников, затем перемножим их площади ��а значение нашей функции в точках на краях этих прямоугольников. Чем больше параллелепипедов, тем выше точность.
Код на js, который выполняет это интегрирование и показывает нам время выполнения:
var func = function(x,y){ return Math.sin(x*y)/(1+Math.sqrt(x*x+y*y))+2; } function integrateJS(x0,xN,y0,yN,iterations){ var result=0; var time = new Date().getTime(); for (var i = 0; i < iterations; i++){ for (var j = 0; j < iterations; j++){ //вычисление координат текущего прямоугольника var x = x0 + (xN - x0) / iterations * i; var y = y0 + (yN - y0) / iterations * j; var value = func(x, y); //вычисление значения функции //вычисление объема параллелепипеда и прибавка к общему объему result+=value*(xN-x0)*(yN-y0)/(iterations*iterations); } } console.log("JS result = "+result); console.log("JS time = "+(new Date().getTime() - time)); }
Подготовка к написанию расширения
Теперь выполним все те же операции на C++. Лично я использовал Microsoft Visual Studio 2010. Для начала нам необходимо скачать исходники Node.JS. Идем на официальный сайт и подтягиваем последнюю версию исходников. В папке с исходниками лежит файл vcbuild.bat, который создает необходимые проекты для Visual Studio и конфиги. Для работы батника необходим установленный Python. Если у вас его нет — ставим с офф сайта. Прописываем пути к питону в переменную среды Path (для питона 2.7 это будут C:\Python27;C:\Python27\Scripts). Запускаем батник, получаем необходимые файлы. Далее создаем .cpp файл нашего модуля. Далее пишем описание нашего модуля в json-формате:
{ "targets": [ { "target_name": "funcIntegrate", "sources": [ "funcIntegrate.cpp" ] } ] }
Сохраняем как binding.gyp и натравливаем на него утилиту, которую ставим с помощью npm. Эта утилита создает правильно настроенный файл студии vcxproj для windows или же makefile для linux. Так же одним товарищем был создан батник, еще сильнее упрощающий настройку и создание проекта для студии. Можете взять у него, вместе с примером helloworld-модуля. Редактируете файл, запускаете батник — получаете готовый .node модуль. Можно создать вручную проект Visual Studio и так же вручную вбить все настройки — пути к либам и хедерам node.js, configuration type ставим в .dll, target extension — .node.
Нативное расширение
Все настроено, приступаем к написанию кода.
В .cpp файле мы должны объявить класс, унаследованный от ObjectWrap. Все методы этого класса должны быть статичными.
Обязательно должна быть функция инициализации, которую мы вбиваем в макрос NODE_MODULE. В функции инициализации с помощью макроса NODE_SET_PROTOTYPE_METHOD мы указываем методы, которые будут доступны из Node.JS. Мы можем получать передаваемые параметры, проверять их количество и типы и при необходимости выдавать исключения. Подробное описание всех необходимых вещей, для создания расширения вы можете найти тут
Код
#include <node.h> //необходимые хедеры #include <v8.h> #include <math.h> using namespace node; using namespace v8; //функция, аналогичная тому что мы делали на js float func(float x, float y){ return sin(x*y)/(1+sqrt(x*x+y*y))+2; } char* funcCPU(float x0, float xn, float y0, float yn, int iterations){ double x,y,value,result; result=0; for (int i = 0; i < iterations; i++){ for (int j = 0; j < iterations; j++){ x = x0 + (xn - x0) / iterations * i; y = y0 + (yn - y0) / iterations * j; value = func(x, y); result+=value*(xn-x0)*(yn-y0)/(iterations*iterations); } } char *c = new char[20]; sprintf(c,"%f",result); return c; } //наш класс расширения, должен наследоваться от ObjectWrap class funcIntegrate: ObjectWrap{ public: //инициализация. Все методы класса должны быть объявлены как static static void Init(Handle<Object> target){ HandleScope scope; Local<FunctionTemplate> t = FunctionTemplate::New(New); Persistent<FunctionTemplate> s_ct = Persistent<FunctionTemplate>::New(t); s_ct->InstanceTemplate()->SetInternalFieldCount(1); //имя нашего класса для javascript s_ct->SetClassName(String::NewSymbol("NativeIntegrator")); //метод, вызываемый из javasript NODE_SET_PROTOTYPE_METHOD(s_ct, "integrateNative", integrateNative); target->Set(String::NewSymbol("NativeIntegrator"),s_ct->GetFunction()); } funcIntegrate(){ } ~funcIntegrate(){ } //этот метод будет вызываться Node.JS при создании объекта с помощью new static Handle<Value> New(const Arguments& args){ HandleScope scope; funcIntegrate* hw = new funcIntegrate(); hw->Wrap(args.This()); return args.This(); } //фукция интегрирования, доступная из javasript static Handle<Value> integrateNative(const Arguments& args){ HandleScope scope; funcIntegrate* hw = ObjectWrap::Unwrap<funcIntegrate>(args.This()); //считываем параметры из args, и приведя к double передаем в funcCPU. //Результат возвращаем в виде строки Local<String> result = String::New(funcCPU(args[0]->NumberValue(),args[1]->NumberValue(),args[2]->NumberValue(),args[3]->NumberValue(),args[4]->NumberValue())); return scope.Close(result); } }; extern "C" { static void init (Handle<Object> target){ funcIntegrate::Init(target); } NODE_MODULE(funcIntegrate, init); };
Скомпилировав этот код получим .node файл (обычная DLL с другим расширением), который можно подключать к нашему Node.JS проекту. Файл содержит прототип js-объекта NativeIntegrator, который имеет метод integrateNative. Подключим полученный модуль:
var funcIntegrateNative = require("./build/funcIntegrate.node"); nativeIntegrator = new funcIntegrateNative.NativeIntegrator(); function integrateNative(x0,xN,y0,yN,iterations){ var time = new Date().getTime(); result=nativeIntegrator.integrateNative(x0,xN,y0,yN,iterations); console.log("Native result = "+result); console.log("Native time = "+(new Date().getTime() - time)); }
Добавляем этот код к уже готовому проекту на Node.JS, вызываем функции, сравниваем:
function main(){ integrateJS(-4,4,-4,4,1024); integrateNative(-4,4,-4,4,1024); } main();
Получаем результат:
JS result = 127.99999736028109
JS time = 127
Native result = 127.999997
Native time = 103
Разница минимальна. Увеличим количество итераций по осям в 8 раз. Получим следующие результаты:
JS result = 127.99999995875444
JS time = 6952
Native result = 128.000000
Native time = 6658
Выводы
Результат удивляет. Мы не получили практически никакого выигрыша. Результат на Node.JS получается почти точно таким же, какой получается на чистом С++. Мы догадывались что V8 быстрый движок, но чтоб настолько… Да, даже чисто математические операции можно писать на чистом js. Потеряем мы от этого немного, если вообще что-то потеряем. Чтобы получить выигрыш от нативного расширения мы должны использовать низкоуровневую оптимизацию. Но это будет уже слишком. Выигрыш в производительности от нативного модуля далеко не всегда окупит затраты на написание сишного или даже ассемблерного кода. Что же делать? Первое что приходит на ум — использование openmp или нативных потоков, для параллельного решения задачи. Это ускорит решение каждой отдельно взятой задачи, но не увеличит количество решаемых задач в единицу времени. Так что такое решение подойдет не каждому. Нагрузка на сервер не снизится. Возможно мы так же получим выигрыш при работе с большим объемом памяти — у Node.JS все таки будут дополнительные накладные расходы и общий занимаемый объем памяти будет больше. Но память сейчас далеко не так критична, как процессорное время. Какие выводы мы можем сделать из данного исследования?
- Node.JS действительно очень быстр. Если вы не умеете писать качественный код на C++ с низкоуровневой оптимизацией, то нет смысла пытаться написать нативное расширение для ускорения производительности. Вы только получите лишние проблемы.
- Используйте нативные расширения там где это действительно нужно — например, где вам нужен доступ к некоторому системному API, которого нет в Node.JS.
We need to go deeper
А давайте-ка все таки попробуем ускорить работу нашего кода? Раз у нас есть доступ из нативного расширения к чему угодно, то есть доступ и к видеокарте. Используем CUDA!
Для этого нам понадобится CUDA SDK, который можно найти на сайте Nvidia. Не буду рассказывать тут про установку и настройку, для этого и так есть множество мануалов. После установки SDK нам понадобится внести некоторые изменения в проект — переименуем исходник с .cpp на .cu. В настройки построения добавляем поддержку CUDA. В настройки компилятора CUDA добавляем необходимые зависимости. Вот новый код расширения, с комментариями к изменениям и добавлениям:
Код
#include <node.h> #include <v8.h> #include <math.h> #include <cuda_runtime.h> //добавляем поддержку CUDA using namespace node; using namespace v8; //добавляем префиксы __device__ и__host__ //наша функция может работать как на CPU, так и на GPU. __device__ __host__ float func(float x, float y){ return sin(x*y)/(1+sqrt(x*x+y*y))+2; } //__global__ - вызываем с CPU, считаем на GPU __global__ void funcGPU(float x0, float xn, float y0, float yn, float *result){ float x = x0 + (xn - x0) / gridDim.x * blockIdx.x; float y = y0 + (yn - y0) / blockDim.x * threadIdx.x ; float value = func(x, y); result[gridDim.x * threadIdx.x + blockIdx.x] = value*(xn-x0)*(yn-y0)/(gridDim.x*blockDim.x); } char* funcCPU(float x0, float xn, float y0, float yn, int iterations){ double x,y,value,result; result=0; for (int i = 0; i < iterations; i++){ for (int j = 0; j < iterations; j++){ x = x0 + (xn - x0) / iterations * i; y = y0 + (yn - y0) / iterations * j; value = func(x, y); result+=value*(xn-x0)*(yn-y0)/(iterations*iterations); } } char *c = new char[20]; sprintf(c,"%f",result); return c; } class funcIntegrate: ObjectWrap{ private: static dim3 gridDim; //размерности сетки и блоков static dim3 blockDim; static float *result; static float *resultDev; public: static void Init(Handle<Object> target){ HandleScope scope; Local<FunctionTemplate> t = FunctionTemplate::New(New); Persistent<FunctionTemplate> s_ct = Persistent<FunctionTemplate>::New(t); s_ct->InstanceTemplate()->SetInternalFieldCount(1); s_ct->SetClassName(String::NewSymbol("NativeIntegrator")); NODE_SET_PROTOTYPE_METHOD(s_ct, "integrateNative", integrate); // добавим функцию интегрирования на GPU, доступную Node.JS NODE_SET_PROTOTYPE_METHOD(s_ct, "integrateCuda", integrateCuda); target->Set(String::NewSymbol("NativeIntegrator"),s_ct->GetFunction()); //Инициализация данных для CUDA gridDim.x = 256; blockDim.x = 256; result = new float[gridDim.x * blockDim.x]; cudaMalloc((void**) &resultDev, gridDim.x * blockDim.x * sizeof(float)); } funcIntegrate(){ } ~funcIntegrate(){ cudaFree(resultDev); } //Наша новая функция интегрирования static char* cudaIntegrate(float x0, float xn, float y0, float yn, int iterations){ cudaEvent_t start, stop; cudaEventCreate(&start); cudaEventCreate(&stop); //создаем ивенты для синхронизации CPU с GPU //Если шаг интегрирования очень большой и нам не хватает потоков на GPU - //разобьем задачу на несколько частей размерности bCount, и вызовем //функцию на GPU несколько раз int bCount = iterations/gridDim.x; float bSizeX=(xn-x0)/bCount; float bSizeY=(yn-y0)/bCount; double res=0; for (int i = 0; i < bCount; i++){ for (int j = 0; j < bCount; j++){ cudaEventRecord(start, 0); //начало синхронизации //вызов функции на GPU funcGPU<<<gridDim, blockDim>>>(x0+bSizeX*i, x0+bSizeX*(i+1), y0+bSizeY*j, y0+bSizeY*(j+1), resultDev); cudaEventRecord(stop, 0); cudaEventSynchronize(stop); //конец синхронизации //Копирование результатов вычислений из GPU в оперативную память cudaMemcpy(result, resultDev, gridDim.x * blockDim.x * sizeof(float), cudaMemcpyDeviceToHost); //Суммирование результатов вычислений for (int k=0; k<gridDim.x * blockDim.x; k++) res+=result[k]; } } cudaEventDestroy(start); cudaEventDestroy(stop); char *c = new char[200]; sprintf(c,"%f", res); return c; } static Handle<Value> New(const Arguments& args){ HandleScope scope; funcIntegrate* hw = new funcIntegrate(); hw->Wrap(args.This()); return args.This(); } static Handle<Value> integrate(const Arguments& args){ HandleScope scope; funcIntegrate* hw = ObjectWrap::Unwrap<funcIntegrate>(args.This()); Local<String> result = String::New(funcCPU(args[0]->NumberValue(),args[1]->NumberValue(),args[2]->NumberValue(),args[3]->NumberValue(),args[4]->NumberValue())); return scope.Close(result); } //Отсюда вызывается функция интегрирования на CUDA static Handle<Value> integrateCuda(const Arguments& args){ HandleScope scope; funcIntegrate* hw = ObjectWrap::Unwrap<funcIntegrate>(args.This()); Local<String> result = String::New(cudaIntegrate(args[0]->NumberValue() ,args[1]->NumberValue(),args[2]->NumberValue(),args[3]->NumberValue(),args[4]->NumberValue())); return scope.Close(result); } }; extern "C" { static void init (Handle<Object> target){ funcIntegrate::Init(target); } NODE_MODULE(funcIntegrate, init); }; dim3 funcIntegrate::blockDim; dim3 funcIntegrate::gridDim; float* funcIntegrate::result; float* funcIntegrate::resultDev;
Напишем обработчик на js:
function integrateCuda(x0,xN,y0,yN,iterations){ var time = new Date().getTime(); result=nativeIntegrator.integrateCuda(x0,xN,y0,yN,iterations); console.log("CUDA result = "+result); console.log("CUDA time = "+(new Date().getTime() - time)); }
Запустим тестирование на следующих данных:
function main(){ integrateJS(-4,4,-4,4,1024); integrateNative(-4,4,-4,4,1024); integrateCuda(-4,4,-4,4,1024); }
Получим результаты:
JS result = 127.99999736028109
JS time = 119
Native result = 127.999997
Native time = 122
CUDA result = 127.999997
CUDA time = 17
Как мы видим, обработчик на видеокарте уже показывает сильный отрыв. И это при том, что результаты работы каждого потока видеокарты я суммировал на CPU. Если написать алгоритм, полностью работающий на GPU, без использования центрального процессора, то выигрыш в производительности будет еще ощутимее.
Протестируем на следующих данных:
integrateJS(-4,4,-4,4,1024*16); integrateNative(-4,4,-4,4,1024*16); integrateCuda(-4,4,-4,4,1024*16);
Получим результат:
JS result = 127.99999998968899
JS time = 25401
Native result = 128.000000
Native time = 28405
CUDA result = 128.000000
CUDA time = 3568
Как мы видим, разница огромна. Оптимизированный алгоритм на CUDA дал бы нам разницу в производительности более чем на порядок. (А C++ код на этом тесте даже отстал по производительности от Node.JS).
Заключение
Ситуация, рассмотренная нами довольно экзотическая. Ресурсозатратные вычисления на веб-сервере с Node.JS, который стоит на машине с видеокартой, поддерживающей технологию CUDA. Такое не часто встретишь. Но если вам вдруг когда-нибудь придется с таким столкнуться — знайте, такие вещи реальны. Фактически в свой сервер на Node.JS вы можете встроить любую штуку, которую можно написать на C++. То есть все что угодно.
Полезные ссылки по созданию нативных расширений

