
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
Traceback (most recent call last):
File "/base/python_runtime/python_lib/versions/1/google/appengine/ext/webapp/_webapp25.py", line 710, in __call__
handler.get(*groups)
File "/base/data/home/apps/s~kino2rss/1.361339873621337288/kino2rss.py", line 117, in get
movie_id = models.get_latest_movie_id()
File "/base/data/home/apps/s~kino2rss/1.361339873621337288/models.py", line 94, in get_latest_movie_id
movie = movies.get(keys_only = True)
File "/base/python_runtime/python_lib/versions/1/google/appengine/ext/ndb/query.py", line 1150, in get
return self.get_async(**q_options).get_result()
File "/base/python_runtime/python_lib/versions/1/google/appengine/ext/ndb/tasklets.py", line 323, in get_result
self.check_success()
File "/base/python_runtime/python_lib/versions/1/google/appengine/ext/ndb/tasklets.py", line 362, in _help_tasklet_along
value = gen.throw(exc.__class__, exc, tb)
File "/base/python_runtime/python_lib/versions/1/google/appengine/ext/ndb/query.py", line 1163, in _get_async
res = yield self.fetch_async(1, **q_options)
File "/base/python_runtime/python_lib/versions/1/google/appengine/ext/ndb/tasklets.py", line 362, in _help_tasklet_along
value = gen.throw(exc.__class__, exc, tb)
File "/base/python_runtime/python_lib/versions/1/google/appengine/ext/ndb/query.py", line 921, in _run_to_list
batch = yield rpc
File "/base/python_runtime/python_lib/versions/1/google/appengine/ext/ndb/tasklets.py", line 443, in _on_rpc_completion
result = rpc.get_result()
File "/base/python_runtime/python_lib/versions/1/google/appengine/api/apiproxy_stub_map.py", line 604, in get_result
return self.__get_result_hook(self)
File "/base/python_runtime/python_lib/versions/1/google/appengine/datastore/datastore_query.py", line 2452, in __query_result_hook
self._batch_shared.conn.check_rpc_success(rpc)
File "/base/python_runtime/python_lib/versions/1/google/appengine/datastore/datastore_rpc.py", line 1222, in check_rpc_success
rpc.check_success()
File "/base/python_runtime/python_lib/versions/1/google/appengine/api/apiproxy_stub_map.py", line 570, in check_success
self.__rpc.CheckSuccess()
File "/base/python_runtime/python_lib/versions/1/google/appengine/api/apiproxy_rpc.py", line 133, in CheckSuccess
raise self.exception
OverQuotaError: The API call datastore_v3.RunQuery() required more quota than is available.
Traceback (most recent call last):
File "/base/python_runtime/python_lib/versions/1/google/appengine/ext/webapp/_webapp25.py", line 710, in __call__
handler.get(*groups)
File "/base/data/home/apps/s~kino2rss/1.361339873621337288/kino2rss.py", line 117, in get
movie_id = models.get_latest_movie_id()
File "/base/data/home/apps/s~kino2rss/1.361339873621337288/models.py", line 94, in get_latest_movie_id
movie = movies.get(keys_only = True)
File "/base/python_runtime/python_lib/versions/1/google/appengine/ext/ndb/query.py", line 1150, in get
return self.get_async(**q_options).get_result()
File "/base/python_runtime/python_lib/versions/1/google/appengine/ext/ndb/tasklets.py", line 323, in get_result
self.check_success()
File "/base/python_runtime/python_lib/versions/1/google/appengine/ext/ndb/tasklets.py", line 362, in _help_tasklet_along
value = gen.throw(exc.__class__, exc, tb)
File "/base/python_runtime/python_lib/versions/1/google/appengine/ext/ndb/query.py", line 1163, in _get_async
res = yield self.fetch_async(1, **q_options)
File "/base/python_runtime/python_lib/versions/1/google/appengine/ext/ndb/tasklets.py", line 362, in _help_tasklet_along
value = gen.throw(exc.__class__, exc, tb)
File "/base/python_runtime/python_lib/versions/1/google/appengine/ext/ndb/query.py", line 921, in _run_to_list
batch = yield rpc
File "/base/python_runtime/python_lib/versions/1/google/appengine/ext/ndb/tasklets.py", line 443, in _on_rpc_completion
result = rpc.get_result()
File "/base/python_runtime/python_lib/versions/1/google/appengine/api/apiproxy_stub_map.py", line 604, in get_result
return self.__get_result_hook(self)
File "/base/python_runtime/python_lib/versions/1/google/appengine/datastore/datastore_query.py", line 2452, in __query_result_hook
self._batch_shared.conn.check_rpc_success(rpc)
File "/base/python_runtime/python_lib/versions/1/google/appengine/datastore/datastore_rpc.py", line 1222, in check_rpc_success
rpc.check_success()
File "/base/python_runtime/python_lib/versions/1/google/appengine/api/apiproxy_stub_map.py", line 570, in check_success
self.__rpc.CheckSuccess()
File "/base/python_runtime/python_lib/versions/1/google/appengine/api/apiproxy_rpc.py", line 133, in CheckSuccess
raise self.exception
OverQuotaError: The API call datastore_v3.RunQuery() required more quota than is available.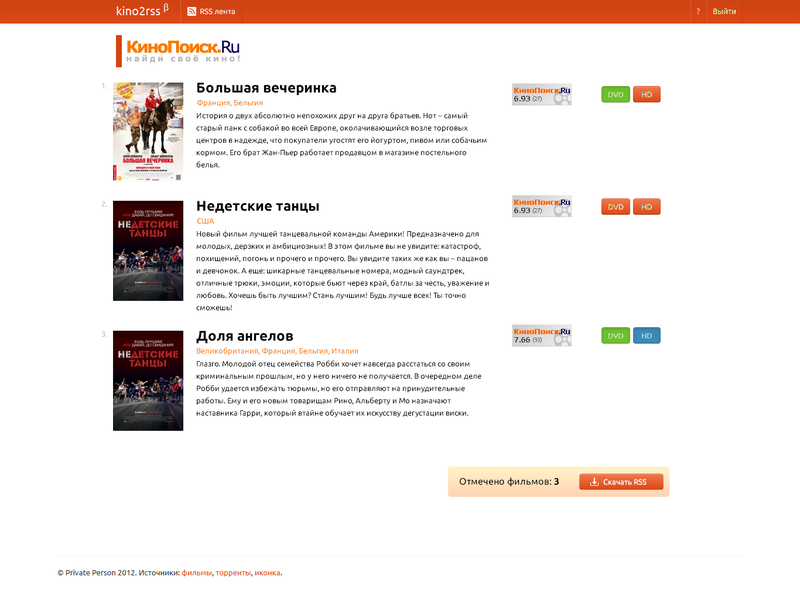

Автоматическое скачивание киноновинок