Давно была идея собрать воедино интересные вопросы, касающиеся сетей.
Объединяет их то, что все они довольно простые, но мы подчас о них не задумываемся (я во всяком случае о них не задумывался).
В общем я их собрал, подбил, нашёл ответы.
Итак, блиц опрос:

Согласно стандарту 802.3, мы имеем:

Почему при расчёте overhead размер служебных данных Ethernet берётся 14 байтов, а не 38 или 18 (Dest+Source+Legth+FCS).
С другой стороны сейчас общепринят стандарт Ethernet II.

В чём же отличие кадров Ethernet II от кадров 802.3 и почему он вообще II?

Здесь коммутаторы подключены двумя оптическими интерфейсами, объединёнными в LAG. В качестве среды используется два оптических кабеля — один для приёма, другой для передачи. Что произойдёт после обрыва одного кабеля?

И почему такой пинг не работает:

1. te2-4 PAO2 bl (69 22 1 3 209) 1 160 1 060 1 029 4.ar5.PAO2.gblx.net (69.22.153.209) 1.160 ms 1.060 ms 1.029 ms
2. 192.205.34.245 (192.205.34.245) 3.984 ms 3.810 ms 3.786 ms
3. tbr1 sffca ip att net (12 123 12 25) 74 848 ms 74 859 ms 74 936 ms tbr1.sffca.ip.att.net (12.123.12.25) 74.848 ms 74.859 ms 74.936 ms
4. cr1.sffca.ip.att.net (12.122.19.1) 74.344 ms 74.612 ms 74.072 ms
5. cr1.cgp ( ) cil.ip.att.net (12.122.4.122) 74.827 ms 75.061 ms 74.640 ms
6. cr2.cgcil.ip.att.net (12.122.2.54) 75.279 ms 74.839 ms 75.238 ms
7. cr1.n54ny.ip.att.net (12.122.1.1) 74.667 ms 74.501 ms 77.266 ms
8. gbr7.n54ny.ip.att.net (12.122.4.133) 74.443 ms 74.357 ms 75.397 ms
9. ar3.n54ny.ip.att.net (12.123.0.77) 74.648 ms 74.369 ms 74.415 ms
10.12 126 0 29 (12 126 0 29) 76 104 76 283 76 174 12.126.0.29 (12.126.0.29) 76.104 ms 76.283 ms 76.174 ms
11.route-server.cbbtier3.att.net (12.0.1.28) 74.360 ms 74.303 ms 74.272 ms


Но людям из 1597 он уже писал) там уже адреса не валидные.
А вот второе письмо оказалось более результативным:
Неотвеченными остался только один интересный, но, возможно, надуманный вопрос. Как я его ни крутил, как ни гуглил, но его тайна пока не раскрыта.
Для чего нужен адрес сети? Почему его нельзя назначить хосту?
Логичный первый вариант — он определяет сеть. Ну а что, так уж нужен для этого отдельный адрес? 192.168.1.110/24 определяет сеть точно так же хорошо, как и 192.168.1.0/24. Да и это всё равно не мешает назначать этот адрес хосту.
Вторая идея — так прописываются маршруты на роутерах. Это же не более, чем условность, ведь по сути см. первый вариант.
Встречал я также описание того, что некоторые вендоры преобразуют пинг на адрес сети в широковещательный кадр, но какой в этом смысл?
Если вы мне скажете, что так просто решили формализовать сеть, то я, видимо, обречённо приму.
Симметричный вопрос:
Или для чего нужен широковещательный адрес? Можно было бы использовать для него адрес сети.
UPD На данный вопрос приблизительный ответ дал один из читателей:
Спасибо.
Объединяет их то, что все они довольно простые, но мы подчас о них не задумываемся (я во всяком случае о них не задумывался).
В общем я их собрал, подбил, нашёл ответы.
Итак, блиц опрос:
Начнём с самых низких уровней и с самых простых вопросов
В1. Почему для витой пары выбран такой странный порядок: синяя пара на 4-5, разрывая зелёную, которая на 3, 6?
Ответ
О1: Сделано это в угоду двухконтактному телефонному разъёму. Таким образом, например, в патч-панель можно вставить как телефонный кабель, так и витую пару.
Можно даже через один кабель вывести и сеть и телефонию, но я вам этого не говорил!
habrahabr.ru/post/158177.
Можно даже через один кабель вывести и сеть и телефонию, но я вам этого не говорил!
habrahabr.ru/post/158177.
В2. В стандарте Ethernet между кадрами всегда имеется промежуток, называемый IFG (Inter Frame Gap) длиною 12 байтов. Для чего он нужен, и почему он присутствует в современных стандартах?
Ответ
О2: IFG использовался активно во времена расцвета CSMA/CD. Это пауза, которую должно делать передающее устройство перед отправкой фрейма, чтобы избежать коллизий.
Дело в том, что в когда несколько хостов подключены в хаб, высока вероятность того, что они начнут отправлять данные в одно время, и возникнет коллизия или одна станция оккупирует монопольно канал.
При использовании IFG пока один хост ждёт, другой, может отправлять.
Вообще говоря, IFG измеряется в микросекундах. Его длительность для Fast Ethernet составляет 0,96 микросекунды.
Уже в гигабите CSMA/CD есть только условно, а в 10G его нет вовсе. Это потому, что домен коллизий современных коммутаторов ограничен одним интерфейсом/кабелем, плюс работают в полнодуплексном режиме.
Так для чего же мы до сих пор теряем драгоценные 12 байтов?
Просто никто не хочет менять стандарт.
Красочное описание Искать по словам «Now what is not shown»
Дело в том, что в когда несколько хостов подключены в хаб, высока вероятность того, что они начнут отправлять данные в одно время, и возникнет коллизия или одна станция оккупирует монопольно канал.
При использовании IFG пока один хост ждёт, другой, может отправлять.
Вообще говоря, IFG измеряется в микросекундах. Его длительность для Fast Ethernet составляет 0,96 микросекунды.
Уже в гигабите CSMA/CD есть только условно, а в 10G его нет вовсе. Это потому, что домен коллизий современных коммутаторов ограничен одним интерфейсом/кабелем, плюс работают в полнодуплексном режиме.
Так для чего же мы до сих пор теряем драгоценные 12 байтов?
Просто никто не хочет менять стандарт.
Красочное описание Искать по словам «Now what is not shown»
В3. Чем вызвано ограничение на длину сегмента Ethernet и минимальный размер кадра?
Ответ
О3: Обычно объясняют этот факт тем, что в кабеле на большИх длинах возникают затухания и и сигнал просто сильно искажется на втором конце.
Истинная причина кроется всё в том же механизме CSMA/CD.
Чтобы коллизия в линии была успешно обнаружена, в тот момент, когда на удалённой стороне будет принят первый бит, станция ещё не должна закончить передачу текущей порции данных.
Объясню на пальцах. Берём полудуплексную сеть. Допустим станция 1 начинает передачу данных. Следом за ней, что-то пытается передать станция 2. До неё ещё не дошёл сигнал от Станции 1 и поэтому ей можно. Сигнал от станции 2 досигнет станции 1 ещё до того, как она закончит передачу своих данных. Обе станции обнаруживают коллизию и прекращают передачу. Всё отлично. Данные не потеряны и в следующий раз у них обязательно получится.
Теперь предположим другую ситуаицию. Станция 1 передала порцию данных и готовится к следующей. Но до станции 2 сигнал ещё не дошёл, она понимает, что можно передавать.
Ага, где-то посередине они пересеклись. Станция 2 это поняла и прекратила передачу, а Станция 1 получила искорёженные данные, при этом продолжая думать, что свою задачу по передаче сигнала выполнила, и потому берётся за следующую порцию.
В итоге потерян кадр, потому что на обратной стороне его собрать не сумели — не всё получили. Да, вышестоящие протоколы это смогут детектировать, перезапросить их повторно, но сколько напрасных миллисекунд на это будет затрачено?
Такая ситуация исключена, если выполняется условие, озвученное в начале: когда принят первый бит в конце сегмента, отправитель ещё не передал последний бит. Тогда ничто не будет потеряно.
Но, вернёмся к длине сегмента. Вероятно, вы уже начали догадываться, в чём соль? Длина должна быть такой, чтобы было удовлетворено это самое условие.
Так вот, отбросив хитрые способы подсчёта, 100 м — это именно то расстояние, на котором при получении первого бита удалённой стороной ещё не отправлен последний отправляющей.
Осталось определиться с размером этого блока данных.
Минимальная порция данных для стандарта Fast Ethernet составляет 512 бит или 64 байта — это так называемый Slot time. Ничего эта цифра не напоминает? Минимальный размер Ethernet-кадра, возможно? (Для Gigabit Ethernet это значениу увелично до 512 байтов).
Вот именно эти 64 байта и должны растянуться на всю длину сегмента.
Я попытался подробнее разобраться в этой теме и подготовил отдельный материал, чтобы вам было проще разобраться: 100 метров Ethernet.
www.ixbt.com/comm/tech-fast-ethernet.shtml#_Toc91050385
Истинная причина кроется всё в том же механизме CSMA/CD.
Чтобы коллизия в линии была успешно обнаружена, в тот момент, когда на удалённой стороне будет принят первый бит, станция ещё не должна закончить передачу текущей порции данных.
Объясню на пальцах. Берём полудуплексную сеть. Допустим станция 1 начинает передачу данных. Следом за ней, что-то пытается передать станция 2. До неё ещё не дошёл сигнал от Станции 1 и поэтому ей можно. Сигнал от станции 2 досигнет станции 1 ещё до того, как она закончит передачу своих данных. Обе станции обнаруживают коллизию и прекращают передачу. Всё отлично. Данные не потеряны и в следующий раз у них обязательно получится.
Теперь предположим другую ситуаицию. Станция 1 передала порцию данных и готовится к следующей. Но до станции 2 сигнал ещё не дошёл, она понимает, что можно передавать.
Ага, где-то посередине они пересеклись. Станция 2 это поняла и прекратила передачу, а Станция 1 получила искорёженные данные, при этом продолжая думать, что свою задачу по передаче сигнала выполнила, и потому берётся за следующую порцию.
В итоге потерян кадр, потому что на обратной стороне его собрать не сумели — не всё получили. Да, вышестоящие протоколы это смогут детектировать, перезапросить их повторно, но сколько напрасных миллисекунд на это будет затрачено?
Такая ситуация исключена, если выполняется условие, озвученное в начале: когда принят первый бит в конце сегмента, отправитель ещё не передал последний бит. Тогда ничто не будет потеряно.
Но, вернёмся к длине сегмента. Вероятно, вы уже начали догадываться, в чём соль? Длина должна быть такой, чтобы было удовлетворено это самое условие.
Так вот, отбросив хитрые способы подсчёта, 100 м — это именно то расстояние, на котором при получении первого бита удалённой стороной ещё не отправлен последний отправляющей.
Осталось определиться с размером этого блока данных.
Минимальная порция данных для стандарта Fast Ethernet составляет 512 бит или 64 байта — это так называемый Slot time. Ничего эта цифра не напоминает? Минимальный размер Ethernet-кадра, возможно? (Для Gigabit Ethernet это значениу увелично до 512 байтов).
Вот именно эти 64 байта и должны растянуться на всю длину сегмента.
Я попытался подробнее разобраться в этой теме и подготовил отдельный материал, чтобы вам было проще разобраться: 100 метров Ethernet.
www.ixbt.com/comm/tech-fast-ethernet.shtml#_Toc91050385
В4. Как вычисляется Ethernet Overhead
Согласно стандарту 802.3, мы имеем:
Почему при расчёте overhead размер служебных данных Ethernet берётся 14 байтов, а не 38 или 18 (Dest+Source+Legth+FCS).
Ответ
О4: Легко понять, почему в расчёт не идут Преамбула и IFG. Как вам известно Ethernet совмещает в себе функции канального и физического уровня модели OSI. И в то время, как MAC DST, MAC SRC, Type и FCS — являются атрибутами канального уровня, преамбула и IFG — физического. Логично, что при обработке кадра устройство ориентируется только на его полезную длину, без служебных байтов физического уровня.
При этом заметьте, что при расчёте пропускной способоности, всё-таки учитывается полная длина: 38 байтов + полезная нагрузка.
Хорошо, но как быть с FCS? Ведь его чаще всего не учитывают при вычислении накладных расходов (overhead) и к длине полезной нагрузки добавляют только 14 байтов (MAC DST+MAC SRC+Type).
Тут дьявол в мелочах и чтобы найти ответ, нужно обратиться к самой сути FCS — Frame Check Sequence. IP не имеет встроенных средств контроля целостности исходной информации, поэтому эти функции берут на себя TCP (общий контроль — все ли данные доставлены корректно) и Ethernet. Последний проверяет на повреждения каждый конкретный кадр, высчитывай контрольную сумму. То есть он берёт весь полностью кадр за исключением поля FCS, обрабатыавет его и сравнивает полученнй результат с исходным значением контрольной суммы, если не совпадает — отбрасывает. Если совпадает, сначала поле FCS снимается, затем оставшийся кадр передаётся вышестоящим инстанциям. Фактически эта обработка происходит в железе на самом раннем этапе и те процессы, которые занимаются собственно кадром и вычисляют его размер, получают на самом деле только 14 избыточных байтов заголовка.
Такая интересная арифметика.
forum.nil.com/viewtopic.php?f=12&p=582
При этом заметьте, что при расчёте пропускной способоности, всё-таки учитывается полная длина: 38 байтов + полезная нагрузка.
Хорошо, но как быть с FCS? Ведь его чаще всего не учитывают при вычислении накладных расходов (overhead) и к длине полезной нагрузки добавляют только 14 байтов (MAC DST+MAC SRC+Type).
Тут дьявол в мелочах и чтобы найти ответ, нужно обратиться к самой сути FCS — Frame Check Sequence. IP не имеет встроенных средств контроля целостности исходной информации, поэтому эти функции берут на себя TCP (общий контроль — все ли данные доставлены корректно) и Ethernet. Последний проверяет на повреждения каждый конкретный кадр, высчитывай контрольную сумму. То есть он берёт весь полностью кадр за исключением поля FCS, обрабатыавет его и сравнивает полученнй результат с исходным значением контрольной суммы, если не совпадает — отбрасывает. Если совпадает, сначала поле FCS снимается, затем оставшийся кадр передаётся вышестоящим инстанциям. Фактически эта обработка происходит в железе на самом раннем этапе и те процессы, которые занимаются собственно кадром и вычисляют его размер, получают на самом деле только 14 избыточных байтов заголовка.
Такая интересная арифметика.
forum.nil.com/viewtopic.php?f=12&p=582
В5. Знаете ли вы, что реальная битовая скорость Fast Ethernet 125 Мб/с? Почему так?
Ответ
О5: Ethernet заимствует у FDDI метод кодирования 4B/5B, когда любые четыре бита MAC-подуровня представляются пятью физическими битами с чередующимися нулями и единицами. Для чего это делается — уже глубокая физика.
При этом исходные данные должны передаваться со скоростью 100 Мб/с согласно стандарту Ethernet. Из-за этого избыточного бита действительная скорость на 25% больше (5 больше 4 на 25%), что составляет, разумеется, 125 Мб/c.
citforum.ru/nets/lvs/glava_5.shtml
При этом исходные данные должны передаваться со скоростью 100 Мб/с согласно стандарту Ethernet. Из-за этого избыточного бита действительная скорость на 25% больше (5 больше 4 на 25%), что составляет, разумеется, 125 Мб/c.
citforum.ru/nets/lvs/glava_5.shtml
В6. Всем известно, что комитет 802 занимается стандартами по ЛВС. Также, общеизвестно, что Ethernet — это 802.3
С другой стороны сейчас общепринят стандарт Ethernet II.
В чём же отличие кадров Ethernet II от кадров 802.3 и почему он вообще II?
Ответ
О6: Кадры формата 802.3 содержат поле Length вместо привычного нам Type (EtherType). Исторически сложилось, что существует несколько стандартов для кадров Ethernet (помимо перечисленных).
Потом DEC, Intel и Xerox доработали их до универсального красивого решения Ethernet II (Ethernet DIX по первым буквам компаний), которое стало экстремально популярным — IP работает именно поверх него.
Поле Length прежде говорило о общем размере полезной нагрузки, что было в общем-то мало информативно и тем более такой кадр мог нести только один тип вышестоящего протокола. Значения Length могут быть до 1500 (0x05dc).
В кадре Ethernet II отказались от поля Length и осовобившиеся 2 байта использовали под поле Type (EtherType), которое определяет тип вышестоящего протокола. Чтобы чётко отличать их от 802.3 берутся значения, выше 1536 (0x0600).
Так например, если кадр несёт IPv4, то тип будет 0х0800, ARP — 0x0806, VLAN (802.1q) — 0x8100, IPv6 — 0x86DD, QinQ — 0x9100 итд.
pascal.tsu.ru/other/frames.html#as-h4-2325214
Потом DEC, Intel и Xerox доработали их до универсального красивого решения Ethernet II (Ethernet DIX по первым буквам компаний), которое стало экстремально популярным — IP работает именно поверх него.
Поле Length прежде говорило о общем размере полезной нагрузки, что было в общем-то мало информативно и тем более такой кадр мог нести только один тип вышестоящего протокола. Значения Length могут быть до 1500 (0x05dc).
В кадре Ethernet II отказались от поля Length и осовобившиеся 2 байта использовали под поле Type (EtherType), которое определяет тип вышестоящего протокола. Чтобы чётко отличать их от 802.3 берутся значения, выше 1536 (0x0600).
Так например, если кадр несёт IPv4, то тип будет 0х0800, ARP — 0x0806, VLAN (802.1q) — 0x8100, IPv6 — 0x86DD, QinQ — 0x9100 итд.
pascal.tsu.ru/other/frames.html#as-h4-2325214
Немного повыше поднимаемся
В7. LACP применяется для управления интерфейсами в LAG. Сможет ли он отследить вот такую ситуацию
Здесь коммутаторы подключены двумя оптическими интерфейсами, объединёнными в LAG. В качестве среды используется два оптических кабеля — один для приёма, другой для передачи. Что произойдёт после обрыва одного кабеля?
Ответ
О7: Вообще говоря LACP — примтивнейший протокол. Он принимает решение о том добавить или удалить интерфейс из LAG практически лишь на основе того какое состояние у интерфейса — Up или Down.
В случае обрыва только одного кабеля прекратится передача в одном направлении — исчезнет сигнал лазера. Как правило коммутатор, как только перестаёт видеть сигнал удалённой стороны, переводит интерфейс в сотояние Down. В ситуации, как на рисунке, SW2 сигнал видеть перестаёт, потому что кабель повреждён, и переводит интерфейс Gi0/0/1 в Down. В то же время SW1 сигнал видит и его интерфейс Gi0/0/1 в Up'е.
На SW2 LACP удаляет Gi0/0/1 из LAG, а на SW1 нет. Таким образом получается проблема с передачей данных.
Для избежания таких ситуаций необходимо воспользоваться одним из протоколов UDLD (UniDirectional Link Detection), например BFD или EFM OAM.
UPD: Пользователь Karroplan внёс поправки в этот вопрос:
В случае обрыва только одного кабеля прекратится передача в одном направлении — исчезнет сигнал лазера. Как правило коммутатор, как только перестаёт видеть сигнал удалённой стороны, переводит интерфейс в сотояние Down. В ситуации, как на рисунке, SW2 сигнал видеть перестаёт, потому что кабель повреждён, и переводит интерфейс Gi0/0/1 в Down. В то же время SW1 сигнал видит и его интерфейс Gi0/0/1 в Up'е.
На SW2 LACP удаляет Gi0/0/1 из LAG, а на SW1 нет. Таким образом получается проблема с передачей данных.
Для избежания таких ситуаций необходимо воспользоваться одним из протоколов UDLD (UniDirectional Link Detection), например BFD или EFM OAM.
UPD: Пользователь Karroplan внёс поправки в этот вопрос:
LACP прекрасно определяет unidirectional links. Тайм-аут либо 1, либо 30 секунд — есть два механизма в lacp, fast и slow transmission.
UDLD/BFD нужны только для уменьшения времени реакции. Более того, в свое время пришлось выпустить отдельный RFC по BFD поверх LACP, т.к. BFD изначально протокол L3 и воспринимает весь PortChannel как один агрегированный линк и может определить только падение всего линка.
Ещё выше
В8. Смогут ли пинговать друг друга два компьютера в таких условиях
Ответ
О8: Да смогут. Несмотря на то, что шлюз по умолчанию находится в другой подсети, ARP-запросы будут отправляться в его поисках.
То есть ПК1 отправляет шиоковещательный ARP запрос «Кто тут 192.168.0.1?». ПК2 его получает и, естественно, отвечает, что это он и есть. ПК1 получает ARP-ответ и вносит его МАС-адрес и IP-адрес в свою таблицу. Далее ничего не препятствует им обмениваться данными.
UPD: Пользователь merlin-vrn дал более верный исчерпывающий ответ на этот вопрос:
Суть в том, что перед тем как добавлять такой маршрут по умолчанию (не находящийся в той же подсети), нужно чтобы в таблице маршрутизации уже был к нему маршрут, которого, разумеется, изначально нет. Но Windows скрыто его добавляет, поэтому пинг работает.
То есть ПК1 отправляет шиоковещательный ARP запрос «Кто тут 192.168.0.1?». ПК2 его получает и, естественно, отвечает, что это он и есть. ПК1 получает ARP-ответ и вносит его МАС-адрес и IP-адрес в свою таблицу. Далее ничего не препятствует им обмениваться данными.
UPD: Пользователь merlin-vrn дал более верный исчерпывающий ответ на этот вопрос:
Как компьютер ПК1 должен добираться до 192.168.0.1?
1. Смотрим, не локальный ли адрес это. Нет, не локальный.
2. Смотрим, нет находится ли он в любой из локальных сетей (здесь 192.168.1.0/24). Нет, не находится.
3. Ищем шлюз и делаем ARP-запрос к нему. А через какой интерфейс? Оп-па. Где искать 192.168.0.1? Мы не знаем.
Скажете, что «раз указали в настройках сетевухи 1, значит через неё и искать». Хорошо. Это эквивалентно маршруту «192.168.0.1/32 via сетевуха1», что, собственно, и сделает винда.
Т.е. приведённая в примере конфиуграция, на самом деле, устроена так:
ПК1: 192.168.1.1/32, 192.168.0.1/32 via e0,
ПК2: 192.168.0.1/32, 192.168.1.1/32 via e0.
Т.е. у нас есть два компа и локальные маршруты «непосредственно» друг до друга, хоть оно и в разных подсетях. Конечно, будет пинговаться.
Суть в том, что перед тем как добавлять такой маршрут по умолчанию (не находящийся в той же подсети), нужно чтобы в таблице маршрутизации уже был к нему маршрут, которого, разумеется, изначально нет. Но Windows скрыто его добавляет, поэтому пинг работает.
В9. В чём разница между Directed Broadcast (192.168.0.255) и Limited broadcast (255.255.255.255)
Ответ
О9: Пакет, отправленный на адрес 255.255.255.255 ограничен лишь той сетью, где он зародился — МАС-адрес выставляется в ffff-ffff-ffff. Если пакет отправляется на 192.168.0.255, то сначала согласно всем правилам маршрутизации пакет достигает сети назначения 192.168.0.0, а уже потом рассылается всем хостам в этой сети.
В10: Может ли адрес 10.0.1.0 быть использован для адреса хоста?
Ответ
О10: Да, конечно, может, если например, на интерфейсе у вас применена конфигурация 10.0.0.0/23. Тогда диапазон доступных адресов будет 10.0.0.1-10.0.1.254 и все они могут быть использованы. В том числе 10.0.0.255.
UPD: Второй пример — использование маски /31, когда адрес сети и широковещательный адрес можно назначать узлам.
UPD: Второй пример — использование маски /31, когда адрес сети и широковещательный адрес можно назначать узлам.
В11. Чем принципиально отличается обратная маска от обычной?
Ответ
О11: Естественно, заметное отличие в инвертированности этой маски, то есть нулями обозначается та часть, которая должна быть неизменной. Но это не принципиально ведь.
Существенная разница в том, что здесь нули могут чередоваться с единицами. То есть если маска подсети не может содержать такой набор: 10110001, то обратная маска может.
Таким образом вы, например, сможете выделить во всех подсетях хосты с адресом 10.5.Х.123, например, и разрешить им доступ в Интернет. Или отделить все чётные адреса от нечётных и реализовать распределение трафика ровно пополам на основе адреса отправителя.
UPD: Отличие заключается также в том, что прямая маска оперирует сетями, а обратная — хостами.
Существенная разница в том, что здесь нули могут чередоваться с единицами. То есть если маска подсети не может содержать такой набор: 10110001, то обратная маска может.
Таким образом вы, например, сможете выделить во всех подсетях хосты с адресом 10.5.Х.123, например, и разрешить им доступ в Интернет. Или отделить все чётные адреса от нечётных и реализовать распределение трафика ровно пополам на основе адреса отправителя.
UPD: Отличие заключается также в том, что прямая маска оперирует сетями, а обратная — хостами.
В12. Для чего нужны адреса 169.254.0.0/16 (автонастройка APIPA в Windows и nonzeroconf в unix)
И почему такой пинг не работает:
Ответ
О12: Сеть 169.254.0.0/16 была изначально задумана как сеть Link-Local.
Суть её заключается в том, что, если хост не имеет статического IP-адреса и не может получить его автоматически, например, от DHCP-сервера, то он сам себе назначает адрес из диапазона 169.254.0.1-169.254.255.254. После этого он сможет общаться с другими хостами в этой сети, имеющими такие же адреса.
Адрес выбирается случайным образом благодаря генератору случайных чисел так, чтобы он не совпал с уже существующим адресом (проверяется ARP-запросом).
Примером применения может быть какая-нибудь Ad-Hoc сеть, где у станций задача — общаться между собой.
Но ключевая особенность такой сети в том, что взаимоотношения возможны только между станциями, находящимися в этом сегменте, отсюда и фраза Link-local в определении. Пакеты не могут передаваться дальше маршрутизатора. Более того, даже если у хостов будет указан адрес шлюза, по стандарту он не должен на него передавать пакеты ни при каких условиях.
Этим и объясняется то, что пинг, как на рисунке не работает. Всё согласно RFC.
Суть её заключается в том, что, если хост не имеет статического IP-адреса и не может получить его автоматически, например, от DHCP-сервера, то он сам себе назначает адрес из диапазона 169.254.0.1-169.254.255.254. После этого он сможет общаться с другими хостами в этой сети, имеющими такие же адреса.
Адрес выбирается случайным образом благодаря генератору случайных чисел так, чтобы он не совпал с уже существующим адресом (проверяется ARP-запросом).
Примером применения может быть какая-нибудь Ad-Hoc сеть, где у станций задача — общаться между собой.
Но ключевая особенность такой сети в том, что взаимоотношения возможны только между станциями, находящимися в этом сегменте, отсюда и фраза Link-local в определении. Пакеты не могут передаваться дальше маршрутизатора. Более того, даже если у хостов будет указан адрес шлюза, по стандарту он не должен на него передавать пакеты ни при каких условиях.
Этим и объясняется то, что пинг, как на рисунке не работает. Всё согласно RFC.
В13. А знаете ли сколько всего адресов пропадает, кроме известных всем приватных и 127/8?
Ответ
О13: На самом деле мы теряем:
Одну сеть класса А: 127.0.0.0/8
Одну сеть Класса В: 169.254.0.0/16
Одну сеть /10: 100.64.0.0/10
Одну сеть /15: 198.18.0.0/15
Пять сетей класса C: 192.0.0.0/24, 192.0.2.0/24, 192.88.99.0/24, 198.51.100.0/24, 203.0.113.0/24.
И одну сеть /4: 240.0.0.0/4
Итого 285410560 адресов.
Вот такие мы расточительные.
Одну сеть класса А: 127.0.0.0/8
Одну сеть Класса В: 169.254.0.0/16
Одну сеть /10: 100.64.0.0/10
Одну сеть /15: 198.18.0.0/15
Пять сетей класса C: 192.0.0.0/24, 192.0.2.0/24, 192.88.99.0/24, 198.51.100.0/24, 203.0.113.0/24.
И одну сеть /4: 240.0.0.0/4
Итого 285410560 адресов.
Вот такие мы расточительные.
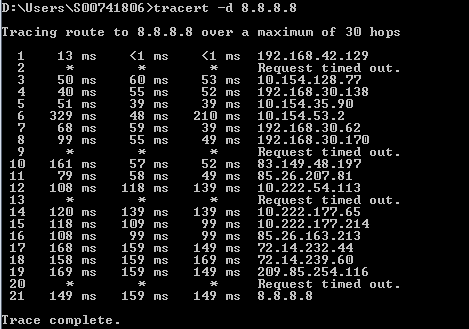
Почему во время трассировки могут быть такие ситуации
В14. На одном из хопов по всем трём результатам трассировки величина задержки выше, чем на следующем
[eucariot]$ traceroute 8.8.8.8
traceroute to 8.8.8.8 (8.8.8.8), 30 hops max, 40 byte packets
...
6 vl545.mag02.lon01.atlas.cogentco.com (149.6.3.153) 11.464 ms 11.378 ms 11.347 ms
7 te0-7-0-5.ccr21.lon01.atlas.cogentco.com (154.54.74.109) 5.653 ms 4.725 ms 6.209 ms
8 te3-2.ccr01.lon18.atlas.cogentco.com (154.54.62.66) 4.951 ms te2-1.ccr01.lon18.atlas.cogentco.com (154.54.61.214) 5.050 ms te3-2.ccr01.lon18.atlas.cogentco.com (154.54.62.66) 5.086 ms
Ответ
О14: Если такая задержка единичная, то, скорее всего, это вопрос буфферизации/приоритезации. Например, временная перегрузка на линии.
UPD: Пользователь JDima внёс дополнения по этому вопросу:
Гораздо интереснее ситуация, когда такие результаты повторяются. Мы прекрасно понимаем, что 3 пролёта, например, пакет не может проходить быстрее, чем 2. Так в чём же дело?
А дело в том, что трассировка показывает только прямой путь от нас до интересующего сервера. При этом мы ничего абсолютно не знаем об обратном пути. Как бы мы этого ни хотели, узнать обратный путь можно, только отправив трассировку в обратную сторону.
Но, несмотря на это, задержка по сути — это Round Trip Timer, то есть время пути пакета туда и обратно.

Таким образом при TTL=3 пакет попадает на R4 одним путём, а возвращается другим. А R3 — это слабенькая старенькая 26-ая циска, которая уже загибается и не может пропихнуть 90 Мб/с. В итоге там случается перегрузка и именно на обратном пути возрасает задержка.
Зато, когда traceroute посылает следующий тестовый пакет с TTL=4 обратно он идёт тем же путём и задержка нормализуется.
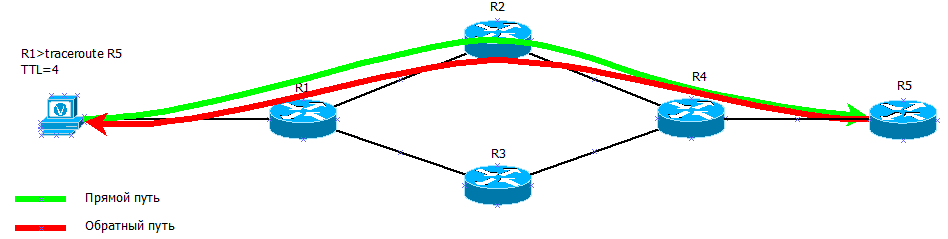
UPD: Пользователь JDima внёс дополнения по этому вопросу:
Коротко:
На хардварных платформах отправка отклика time exceeded реализована на совершенно других чипах, нежели передача транзитных пакетов.
Длинно:
Возьмем к примеру мой любимый Cat6500. Его «мозги» (то, что отзывается на пинги, обменивается маршрутами, принимает ssh соединения и т.д.) сосредоточены на супервизоре в MSFC. MSFC отвечает за программирование PFC (ну и DFC при их наличии), в котором и осуществляется обработка и передача пакетов. По хорошему, ни один транзитный пакет не должен попадать в MSFC.
Пакет с TTL 0 не может быть обработан PFC, так как тут требуется более интеллектуальная обработка, чем та, на которую он способен (требуется сгенерить time exceeded и отправить его назад отправителю (или вперед получателю в случае MPLS, да не суть)). Потому такой пакет переадресуется MSFC. А тот может в данный момент быть нагружен, ICMP на нем не в приоритете, потому он может на несколько миллисекунд отложить отправку ответа, пока не закончит с более важными делами.
Гораздо интереснее ситуация, когда такие результаты повторяются. Мы прекрасно понимаем, что 3 пролёта, например, пакет не может проходить быстрее, чем 2. Так в чём же дело?
А дело в том, что трассировка показывает только прямой путь от нас до интересующего сервера. При этом мы ничего абсолютно не знаем об обратном пути. Как бы мы этого ни хотели, узнать обратный путь можно, только отправив трассировку в обратную сторону.
Но, несмотря на это, задержка по сути — это Round Trip Timer, то есть время пути пакета туда и обратно.
Таким образом при TTL=3 пакет попадает на R4 одним путём, а возвращается другим. А R3 — это слабенькая старенькая 26-ая циска, которая уже загибается и не может пропихнуть 90 Мб/с. В итоге там случается перегрузка и именно на обратном пути возрасает задержка.
Зато, когда traceroute посылает следующий тестовый пакет с TTL=4 обратно он идёт тем же путём и задержка нормализуется.
В15. Иногда в трассировке появляются серые адреса (в середине или как последний хоп). Как так, ведь они не маршрутизируются в Интернете?
Ответ
О15: Согласно RFC такие адреса действительно не маршрутизируется в глобальном интернете, но речь идёт о маршрутизации между AS.
При этом, если где-то в сети провайдера, один из маршрутизаторов будет подключен через приватные адреса, то такая ситуация становится возможной. Дело в том, что маршрутизатор должен в ответном сообщении TTL expired установить в качестве адреса отправителя адрес того интерфейса, на который пришло изначальное сообщение от traceroute.
Станция, с которой запускался трейс покажет именно этот адрес.

И в такой ситуации вы как раз увидите приватный адрес.
При этом, если где-то в сети провайдера, один из маршрутизаторов будет подключен через приватные адреса, то такая ситуация становится возможной. Дело в том, что маршрутизатор должен в ответном сообщении TTL expired установить в качестве адреса отправителя адрес того интерфейса, на который пришло изначальное сообщение от traceroute.
Станция, с которой запускался трейс покажет именно этот адрес.
И в такой ситуации вы как раз увидите приватный адрес.
В16. Чем обусловлены такие задержки при трассировке?
1. te2-4 PAO2 bl (69 22 1 3 209) 1 160 1 060 1 029 4.ar5.PAO2.gblx.net (69.22.153.209) 1.160 ms 1.060 ms 1.029 ms
2. 192.205.34.245 (192.205.34.245) 3.984 ms 3.810 ms 3.786 ms
3. tbr1 sffca ip att net (12 123 12 25) 74 848 ms 74 859 ms 74 936 ms tbr1.sffca.ip.att.net (12.123.12.25) 74.848 ms 74.859 ms 74.936 ms
4. cr1.sffca.ip.att.net (12.122.19.1) 74.344 ms 74.612 ms 74.072 ms
5. cr1.cgp ( ) cil.ip.att.net (12.122.4.122) 74.827 ms 75.061 ms 74.640 ms
6. cr2.cgcil.ip.att.net (12.122.2.54) 75.279 ms 74.839 ms 75.238 ms
7. cr1.n54ny.ip.att.net (12.122.1.1) 74.667 ms 74.501 ms 77.266 ms
8. gbr7.n54ny.ip.att.net (12.122.4.133) 74.443 ms 74.357 ms 75.397 ms
9. ar3.n54ny.ip.att.net (12.123.0.77) 74.648 ms 74.369 ms 74.415 ms
10.12 126 0 29 (12 126 0 29) 76 104 76 283 76 174 12.126.0.29 (12.126.0.29) 76.104 ms 76.283 ms 76.174 ms
11.route-server.cbbtier3.att.net (12.0.1.28) 74.360 ms 74.303 ms 74.272 ms
Ответ
О16: Это явный указатель на то, что трассировка прошла сквозь MPLS-сеть.
В такой сети, когда используется коммутация на основе меток MPLS, а не IP-адресов, трассировка ведёт себя кардинально иначе.
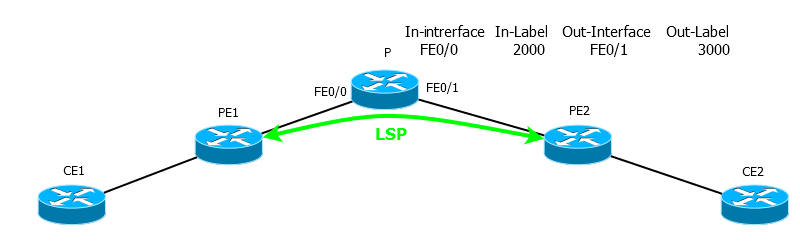
Вот допустим с CE1 запускаем трассировку на CE2. Между PE1 и PE2 установлен LSP.
И вот CE1 отправляет пакет с TTL=2. Он доходит до маршрутизатора P с MPLS-меткой, например 2000. TTL к этому времени равен 1, P уменьшает его и понимает, что оригинальный пакет нужно выбросить, а вместо него отправить TTL-expired на адрес CE1. Он подготавливает ICMP-пакет, в качестве получателя ставит CE1, НО! согласно таблице меток MPLS метка 2000 должна быть заменена на 3000 и соответственно, пакет отправлен на интерфейс FE0/1. То есть в сторону обратную от получателя.
Пакет долетает до РE2, который раздевает его и отправляет на СЕ2 уже чистый IP.
СЕ2 благополучно согласно своей таблице маршрутизации отправляет этот пакет назад в MPLS сеть.
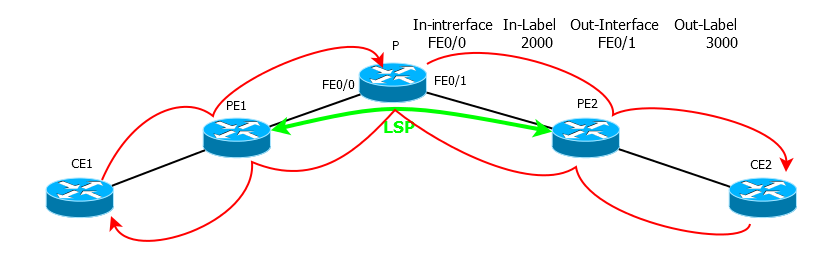
То есть несмотря на то, что пакет должен был пролететь 2 хопа и вернуться, он прошё весь путь от источника до получателя и назад.
Аналогично при TTL=3, после PE2 пакет сначала передаётся на СЕ2 вместо того, чтобы сразу вернуться на СЕ1 — снова проходит весь путь.

Именно поэтому на всех практически хопах задержки оказываются примерно одинаковыми — путь-то они прошли один.
UPD: На рисунке и в описании ошибка, «разворачивает» пакет TTL exceed уже РЕ2, до СЕ он не доходит.
В такой сети, когда используется коммутация на основе меток MPLS, а не IP-адресов, трассировка ведёт себя кардинально иначе.
Вот допустим с CE1 запускаем трассировку на CE2. Между PE1 и PE2 установлен LSP.
И вот CE1 отправляет пакет с TTL=2. Он доходит до маршрутизатора P с MPLS-меткой, например 2000. TTL к этому времени равен 1, P уменьшает его и понимает, что оригинальный пакет нужно выбросить, а вместо него отправить TTL-expired на адрес CE1. Он подготавливает ICMP-пакет, в качестве получателя ставит CE1, НО! согласно таблице меток MPLS метка 2000 должна быть заменена на 3000 и соответственно, пакет отправлен на интерфейс FE0/1. То есть в сторону обратную от получателя.
Пакет долетает до РE2, который раздевает его и отправляет на СЕ2 уже чистый IP.
СЕ2 благополучно согласно своей таблице маршрутизации отправляет этот пакет назад в MPLS сеть.
То есть несмотря на то, что пакет должен был пролететь 2 хопа и вернуться, он прошё весь путь от источника до получателя и назад.
Аналогично при TTL=3, после PE2 пакет сначала передаётся на СЕ2 вместо того, чтобы сразу вернуться на СЕ1 — снова проходит весь путь.
Именно поэтому на всех практически хопах задержки оказываются примерно одинаковыми — путь-то они прошли один.
UPD: На рисунке и в описании ошибка, «разворачивает» пакет TTL exceed уже РЕ2, до СЕ он не доходит.
В17. При пинге с маршрутизатора cisco теряется первый пакет. Почему это происходит?
Ответ
О17: Принято считать, что маршрутизатор отправляет ICMP-запрос и, не получив ICMP-ответ, рисует точку. А ICMP-ответа нет, мол потому, что удалённое устройство должно сначала изучить ARP.
Заблуждение! Его легко проверить включив дебаг или собрав дамп с интерфейса:

Как видите, на самом деле первый ICMP-запрос не отправляется вовсе. ARP улетел и прилетел, а ICMP отброшен. Это видно по тому, что всего 4 ICMP-запроса и 4 ответа.
blog.ipspace.net/2007/04/why-is-first-ping-lost.html
Заблуждение! Его легко проверить включив дебаг или собрав дамп с интерфейса:
Как видите, на самом деле первый ICMP-запрос не отправляется вовсе. ARP улетел и прилетел, а ICMP отброшен. Это видно по тому, что всего 4 ICMP-запроса и 4 ответа.
blog.ipspace.net/2007/04/why-is-first-ping-lost.html
В18. Известно, что в качестве приватных подсетей были выбраны сети из разных классов: A, B, C. Но почему имено 10/8, 172.16/12, 192.168/16?
Ответ
О18: Я бы, наверно, так и не нашёл ответ на этот вопрос — тема совершенно не освещена ни в рунете, ни в большом Интернете. Но мой коллега подошёл к этому радикально. Он написала два письма в IANA.
Dear YYY,
Thanks for contacting us.
We do not have the answer to your question and suggest you contact the authors of «Address Allocation for Private Internets» (RFC 1597), the document first setting these ranges aside. You can find details about the document here: www.rfc-editor.org/info/rfc1597
Kind regards,
Dear YYY,
Thanks for contacting us.
We do not have the answer to your question and suggest you contact the authors of «Address Allocation for Private Internets» (RFC 1597), the document first setting these ranges aside. You can find details about the document here: www.rfc-editor.org/info/rfc1597
Kind regards,
Но людям из 1597 он уже писал) там уже адреса не валидные.
А вот второе письмо оказалось более результативным:
Dear YYY,
Thank you for your inquiry.
For more information about the private use space, see www.rfc-editor.org/rfc/rfc1918.txt.
As to why those specific blocks were chosen, we believe 10/8 was chosen because sri-nic.arpa (10.0.0.51) was embedded in pretty much every unix and multics system as the hardcoded source of hosts.txt and various other files. For the others, the decision was made that since a class A was allocated, there should be blocks of class Bs and Cs too. It could just be that those blocks were available.
Hope that helps.
Best regards,
Michelle Cotton
Manager, IANA Services
ICANN
В общем-то исчерпывающий ответ. Больше искать правду негде.
Неотвеченными остался только один интересный, но, возможно, надуманный вопрос. Как я его ни крутил, как ни гуглил, но его тайна пока не раскрыта.
Для чего нужен адрес сети? Почему его нельзя назначить хосту?
Логичный первый вариант — он определяет сеть. Ну а что, так уж нужен для этого отдельный адрес? 192.168.1.110/24 определяет сеть точно так же хорошо, как и 192.168.1.0/24. Да и это всё равно не мешает назначать этот адрес хосту.
Вторая идея — так прописываются маршруты на роутерах. Это же не более, чем условность, ведь по сути см. первый вариант.
Встречал я также описание того, что некоторые вендоры преобразуют пинг на адрес сети в широковещательный кадр, но какой в этом смысл?
Если вы мне скажете, что так просто решили формализовать сеть, то я, видимо, обречённо приму.
Симметричный вопрос:
Или для чего нужен широковещательный адрес? Можно было бы использовать для него адрес сети.
UPD На данный вопрос приблизительный ответ дал один из читателей:
По последнему вопросу, у Дугласа Комера в 4 издании «Interworking with TCP/IP» есть соответствующая глава. Нули в последнем октете не более чем соглашение, никакой технической подоплёки в этом нет. Там же указывается, что в раннем программном обеспечении протоколов в UNIX'ах пользовались инвентированным соглашением, т.е. для обозначения сети использовали единицы (192.168.1.255/24), а для широковещания — нули, но в последствии этот условный «баг» исправили.
По поводу маршрутизаторов. Они не хранят пути в табличном виде, а используют, например, дерево для эффективного поиска маршрута. Так зачем хранить ненужные листья, если они все равно не будут просматриваться? (Маршрутизатор будет продвигаться по дереву 192.168.1/24, а не по 192.168.1.110/24)
Спасибо.

