
Введение
Если вы завязаны в разработке, то так или иначе сталкивались с баг-трекерными системами. В наши дни обойтись без них в процессе разработки программного обеспечения не просто трудно, а невозможно. Естественно, и нас это не обошло стороной. В компании мы пользуемся системой Redmine. Тут есть все, что нам необходимо:
— Отслеживание состояния задач
— Группировка задач в трекере
— Внутрипроектное обсуждение при необходимости
— Ведение документации (хоть и возможности весьма ограничены)
— Учет времени сотрудников и видов их деятельности
Все эти данные собираются не просто так. Каждая из перечисленных составляющих так или иначе включены во внутренние метрики компании, которые позволяют оценивать эффективность производственного процесса и анализировать слабые места проектов, чтобы не повторять ошибок и в следующий раз сделать лучше.
Задача
Очевидно, что сбор данных должен производиться постоянно, чтобы можно было оперативно отреагировать на негативные изменения и попытаться направить усилия в правильное русло. Однако, из-за большого объема данных, с которыми приходится работать, ручная обработка становится проблематичной. Помимо этого, необходимо обеспечить доступ сотрудников к такому документу, чтобы каждый мог зайти и оценить ситуацию на проекте самостоятельно.
Из этой проблемы и вытекает задача — автоматизировать сбор данных из баг-трекерной системы в более удобные для чтения и визуализации источники.
Подбор решения
В качестве удобного источника идеально подходит электронная таблица — данные в ней можно хорошо структурировать, чтобы они были читаемы, а так же есть возможность воспользоваться функциями визуализации массивов данных (графики, диаграммы и т.п.).
В наборе GoogleDocs есть электронные таблицы, с которыми можно работать из любой точки мира, если у вас есть интернет, а так же управлять правами доступа к ним. Так же GoogleDocs предоставляют возможность пользоваться сервисом GoogleScript для обработки данных как внутри, так и вне документа. Доступ и управление внешними ресурсами осуществляется через API соответствующего сервиса.
Redmine предоставляет возможность получить данные с помощью своего API.
Такое сочетание идеально подходит, потому что решает поставленные задачи.
С чего начать?
Для начала необходимо подключиться из таблицы к API Redmine. Для этого проделываем ряд нехитрых действий:
1. Создаем новый скрипт внутри нашей таблицы (Инструменты -> Редактор скриптов…)
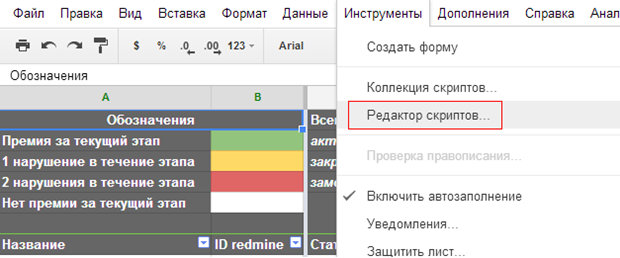
2. В открывшемся окне со сккриптом нужно убрать созданную функцию — мы будем писать свои.
Для начала нам потребуется следующая информация: ссылка, по которой доступен Redmine и API-key. С первым проблем не должно возникнуть — если вы пользуетесь баг-трекером, то точно знаете по какому адресу доступна стартовая страница (у нас, например, это redmine.greensight.ru). С ключом чуть сложнее. Достать его можно, отправив какой-нибудь запрос к API. Открываем FireFox, и пытаемся, например, получить список проектов. Для этого в адресной строке вводим <ссылка на редмайн>/projects.xml:
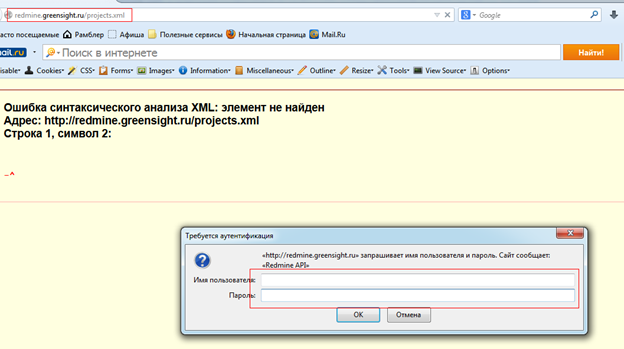
Вводим логин и пароль пользователя, зарегистрированного в системе. Далее в панели разработчика переходим во вкладку “Сеть” подраздел “Заголовки запроса”. То, что написано в поле “Authorization” после слова “Basic” и будет нужным нам ключом.

Теперь попробуем получить то же самое с помощью GoogleScript. Возвращаемся в созданный нами скрипт в таблице и пишем следующий код:
var baseUrl = "<ссылка в Redmine>"; var key = "<API-key>"; function APIRequest (reqUrl) { var url = encodeURI(baseUrl + reqUrl); var payload = { 'Authorization' : 'Basic ' + key}; var opt = { 'method' : 'GET', 'headers' : payload, 'muteHttpExceptions' : true }; var response = UrlFetchApp.fetch(url, opt); return XmlService.parse(response.getContentText()).getRootElement(); } function getRedmineProjects () { var response = APIRequest (‘projects.xml’); Logger.log(response); }
Здесь необходимо заменить <ссылка в Redmine> и <API-key> на то, что вы получили выше. Теперь немного поподробнее о том, что мы сделали.
Переменная baseURL хранит в себе ссылку на главную страницу Redmine. Она нужна, чтобы в дальнейшем лишний раз не прописывать ее в функциях вызова методов API. Соответственно, переменная key нужна для того, чтобы Redmine предоставлял данные в ответ на запрос (подробнее можно почитать любую статью по Basic Authorization). Функция APIRequest осуществляет запрос к Redmine и возвращает ответ от него. opt — это объект, который хранит в себе параметры обращения к API — метод GET, заголовки, содержащие в себе данные о пользователе, который осуществляет запрос, игнорирование исключений.
UrlFetchApp — это класс GoogleScript, позволяющий работать с запросами к внешним сервисам. В данном случае мы пользуемся методом fetch, в который передаем запрос и его параметры.
Redmine умеет возвращать ответы на запросы в двух различных формах — xml и JSON. в данном варианте я пользовался xml-представлением ответа, поэтому в функции возврата ответа на запрос находится XmlService.parse(). Функция getRedmineProjects получает список проектов и выводит их в лог исполнения скрипта (чтобы выполнить скрипт нужно выбрать в меню Выполнить -> getRedmineProjects, а чтобы посмотреть результаты нажать Ctrl+Enter).
Собираем данные
Для сбора данных осталось только обратиться к результатам выполнения функции APIRequest и правильно взять из них данные. Я покажу на примере одного xml-файла как снимать данные. Механизм сбора для остальных аналогичный, а список доступных файлов описан по ссылке выше. Пусть это будет одна из метрик, которая будет полезна всем — списанное время (эта метрика взята для примера, чтобы показать как доставать данные, у нас, конечно же, более сложные метрики на проектах). Для этого будем брать данные из файла time_entries.xml. Их можно отфильтровать средствами Redmine, например, параметр spent_on отвечает за время, списанное в определенную дату или промежуток, а project_id — за время, списанное в определенный проект (более подробное описание есть в документации к API). Посмотрим что из себя представляет этот файл:
<time_entries type="array" total_count="11" limit="25" offset="0"> <time_entry> <id>11510</id> <project name="Тестовый проект" id="150"/> <issue id="7666"/> <user name="Чудесный Разработчик" id="62"/> <activity name="Разработка" id="9"/> <hours>1.5</hours> <comments/> <spent_on>2014-06-10</spent_on> <created_on>2014-06-09T20:23:34Z</created_on> <updated_on>2014-06-09T20:23:34Z</updated_on> </time_entry> <time_entry> <id>11520</id> <project name="Боевой проект" id="87"/> <issue id="7484"/> <user name="Отличный Верстальщик" id="23"/> <activity name="Верстка" id="9"/> <hours>7.5</hours> <comments/> <spent_on>2014-06-10</spent_on> <created_on>2014-06-10T07:57:09Z</created_on> <updated_on>2014-06-10T07:57:09Z</updated_on> </time_entry>
Родительский узел показывает информацию, которая нам так же потребуется при обработке информации: total_count — сколько найдено записей по данному запросу, limit — количество записей на странице, offset — отступ от начала списка. Параметры limit и offset можно так же регулировать в самом запросе. Например, стоит сделать limit побольше, чтобы было меньше запросов при сборе данных.
Как мы видим, файл обладает очень четкой структурой. Приступим к его обработке. Допустим, нам нужно написать функцию, которая собирает все время, списанное за сегодня на определенном проекте и посчитать сколько было потрачено на управление и разработку:
function getTimes(id, params) { var time = new Array(); var offset = 0; do { var response = APIRequest ("time_entries.xml?project_id=" + id + "&spent_on=><" + params + "&offset="+offset + "&limit=100"); for (i=0; i<response.getChildren('time_entry').length; i++) { var obj = new Array(); obj.push(response.getChildren('time_entry')[i].getChild('activity').getAttribute('name').getValue()); obj.push(response.getChildren('time_entry')[i].getChild('hours').getText()); time.push(obj); } offset += 100; } while (response.getChildren('time_entry').length != 0); var manage = 0; var dev = 0; for (i=0; i<time.length; i++) { if (time[i][0] == 'Управление') { manage += +time[i][1]; } else { dev += +time[i][1]; } } return (manage/(manage+dev)); }
Внутри цикла мы каждый раз достаем информацию о времени, списанном в проекте с id = id (посмотреть id проекта можно так же через API запросом к projects.xml), потраченным во время params. Каждый запрос к Redmine получает 100 записей и, если этого недостаточно, двигаемся на offset.
Далее, в цикле, мы выполняем response.getChildren('time_entry')[i].getChild('activity').getAttribute('name').getValue(). Эта команда получает название активности из каждой записи списанного времени:

Таким образом мы можем получить любое имя параметра любой вложенности любого из детей корневого элемента xml-файла.
Для получения самих значений используем response.getChildren('time_entry')[i].getChild('hours').getText(). По аналогии с командой выше мы получаем списанное время:

Дальнейшие действия функции направлены на подсчет времени управления и времени разработки по проекту.
Теперь нам осталось только организовать вывод посчитанных показателей. Для этого необходимо написать небольшую функцию, которая вставляет полученное значение в нужные ячейки нашей таблицы:
function getAllTimes() { var value; SpreadsheetApp.getActive().setActiveSheet(SpreadsheetApp.getActive().getSheetByName('Project')); var data = SpreadsheetApp.getActive().getDataRange().getValues(); for (k=0; k<data.length; k++) { value = 0; if ((data[k][2].toLowerCase()=='активный')&&(data[k][1].toString()!='')) { value = getTimes(data[k][1], data[3][9]); SpreadsheetApp.getActive().setActiveSelection("K" + (k+1)).setValue(value); } } }
Чтобы понять это необходимо немного пояснений. Список проектов у нас хранится на листе с названием “Project”. Там же в разных колонках записываются метрики. Временной промежуток, по которому фильтруется время записан так же в отдельной ячейке. В переменную data считывается вся информация из таблицы. Цикл далее находит все проекты в статусе “Активный” с присутствующим id проекта из Redmine, вызывает функцию подсчета определенной метрики для этого проета и записывает результат в столбец K (в данном случае).
Единственное, что теперь остается — это выполнить наш скрипт. Для этого необходимо выбрать пункт меню Выполнить-> <имя функции>. Так же можно настроить выполнение необходимых функций из меню документа или по динамическому триггеру на периодический запуск.
Вот такой вот способ автоматизировать снятие метрик для проекта. Пользуясь возможностями API Redmine, можно получать в автоматическом режиме сколь угодно сложные данные и не тратить время на ручной расчет.
Грабли
Естественно, в процессе выполнения задачи пришлось столкнуться с некоторыми неочевидными проблемами. Я постараюсь привести основные.
1. Ограничение на вывод количества записей по запросу — не более 100 штук. Даже если вы прописываете в запросе limit=500, выведется все равно не более 100.
2. Для того, чтобы вывести задачи во всех статусах, нужно добавлять в запрос “status_id=*”, иначе в выборку не будут попадать задачи в статусах “Закрыта”, “Отменена” и т.п.
3. Можно попытаться сделать пользовательскую функцию и потом вставлять ее в ячейку таблицы так же, как мы пользуемся любыми другими формулами в таблице (например, “=gettimes(id, params)”). Этот способ будет давать сбой при большом количестве данных и вместо того, чтобы увидеть данные по проектам, вы
будете видеть в ячейках ERROR.
4. Не рекомендуется выводить данные через Logger в консоль. Возникает похожая проблема с п.3 — не до конца выполняется скрипт и в итоге мы имеем не полную картину.
5. Очень внимательно следите за данными, которые могут всплыть (в основном, это в пользовательских полях) — если оно будет отсутствовать, то попытка чтения такого поля или свойства в записи через getChild() приведет к выдачи объекта null и дальнейшая работа с ним будет невозможна.

