Введение
Каждый, кто пришел в этот мир, проходил через путь познания языка. При этом человек обучается языку отнюдь не по правилам или грамматике. Даже, более того, каждый человек, будучи еще ребенком, сначала учит такое странное явление как язык, а уже позднее, с возрастом, начинает учить его правила (в садике и школе). Это объясняет забавный факт, каждый, кто изучает иностранный язык в зрелом возрасте, когда он уже менее склонен к изучению новых языков, знает о предмете своего изучения больше, чем большинство носителей этого языка.
Это простое наблюдение дает возможность предполагать, что для понимания языка вовсе не нужно иметь знания о нем. Достаточно лишь эмпирии (опыта), который можно почерпнуть от окружающих. Но именно об этом забывают практически все современные НЛП библиотеки, пытаясь построить все-обемлящую языковую модель.
Для более четкого понимания представьте себя слепым и глухим. И, даже родись в таком состоянии, вы бы могли взаимодействовать с миром и освоить язык. Само собой, что ваше представление о мире было бы иным, нежели у всех вокруг. Но вы могли бы все таким же образом взаимодействовать с миром. Некому бы было объяснить Вам что происходит и что такое язык ив се же, как то, тактильно анализирую шрифт Брайля Вы бы понемного сдвинулись с мертвой точки.
А это значит, что для понимания сообщения на каком-либо языке нам не нужно ничего, кроме самого сообщения. При условии, что это сообщение достаточно большое. Именно эта идея и положена в основу библиотеки под названием AIF. За деталями прошу пожаловать под кат.
Вначале совсем немного теории о том как уныло все вокруг
Есть очень хороший курс Стэнфорда посвященный NLP: www.coursera.org/course/nlp. Если еще по каким-то причинам его не видели, то очень зря. Просмотрев хотя бы первые 2 недели, становится понятно что такое вероятностная модель языка, на которой строится большая часть всех существующих НЛП решений. Если коротко, то имея огромную кучу текстов, можно прикинуть с какой вероятностью каждое слово употребляется с другим словом. Это очень грубое объяснение, но оно, как мне кажется, точно отражает суть. В результате получается строить более-менее приличные переводы (привет Google Translate). Этот подход не приближает нас к пониманию текста, а лишь пытается найти похожие предложения и на их базе построить перевод.
Но не будем о грустном, поговорим о том, что потенциально можем дать мы:
Какие функции должна будет реализовать финальная версия нашей библиотеки?
- Поиск символов, используемых для разделения предложений в тексте.
- Извлечение лемм из текста (с весами).
- Построение семантического графа текста.
- Сравнение семантических графов текстов.
- Построение резюме текста.
- Извлечение объектов из текстового (частичное NER).
- Определение связи между объектами.
- Определение темы текста.
- В текущей версии у нас уже есть реализация некоторых пунктов из этого списка.
Почему миру нужен AIF?
Учитывая, что уже есть довольно много подобных библиотек OpenNLP, StanfordNLP, — зачем создавать ещё одну?
В большинстве существующих НЛП библиотеках есть существенные недостатки:
- привязанность к конкретным языкам (качество результата работы может сильно варьироваться от языка к языку);
- привязанность к точной грамматической структуре (было бы классно видеть, как каждый пишет подобно Шекспиру или Толстому, но это далеко от реальности);
- привязанность к кодировке (так как языковые модели часто заточены под определенную кодировку).
В таких библиотеках присутствует очень высокая корреляция между качеством текста, подаваемого на вход, и результатом, получаемым на выходе.
Языковые модели не могут провести семантический анализ текста. Они избегают понимания текста на этапе синтаксического анализа. Модель языка может помочь разбить текст на предложения, провести извлечение сущностей (NER), feeling extraction. Тем не менее модель не может определить смысл текста, к примеру, не сможет составить приемлемое резюме текста.
Проиллюстрируем вышеуказанные пункты на примере.
Возьмем отсканированный текст https://archive.org/details/legendaryhistor00veld . Этот текст имеет ряд нестандартно закодированных символов, но мы сделаем его еще хуже, заменив символ “." на "¸". Эта замена не будет препятствовать читаемости для обычного пользователя, однако делает текст практически не обрабатываемым для библиотек NLP.
Попробуем разбить этот текст на предложения при помощи таких библиотек как: OpenNLP, StanfordNLP и AIF:
В результате библиотеки смогли выделить следующие количество предложений:
- StanfordNLP: 13
- OpenNLP: 3
- AIF: 2240
Но даже более простые проблемы, чем эта, часто неразрешимы для большинства библиотек НЛП. Основная причина в том, что они не такие уж и умные. Они основаны на моделях, которые представляют собой набор статических правил и значений. Изменения в правилах или значениях зачастую требуют переобучения модели. А это довольно долго и затратно. Избежать этого (использования языковых моделей) — фундаментальная идея нашей библиотеки.
AIF изучает язык по входному тексту. Он не нуждается в языковых моделях, так как получает всю необходимую информацию о языке из самого текста. Единственным важным требованием является то, что входной текст должен быть больше, чем 20 предложений.
Так каким же образом AIF разбивает текст на предложения?
Для выделения символов, которые делят текст на предложения, мы разработали специальную формулу — для каждого символа вычисляется вероятность того, что именно он является разделителем.
Результаты расчёта вероятности того, что символ используется для разделения предложений приведены ниже
Пример №1 (The Legendary History of the Cross)
archive.org/details/legendaryhistor00veld
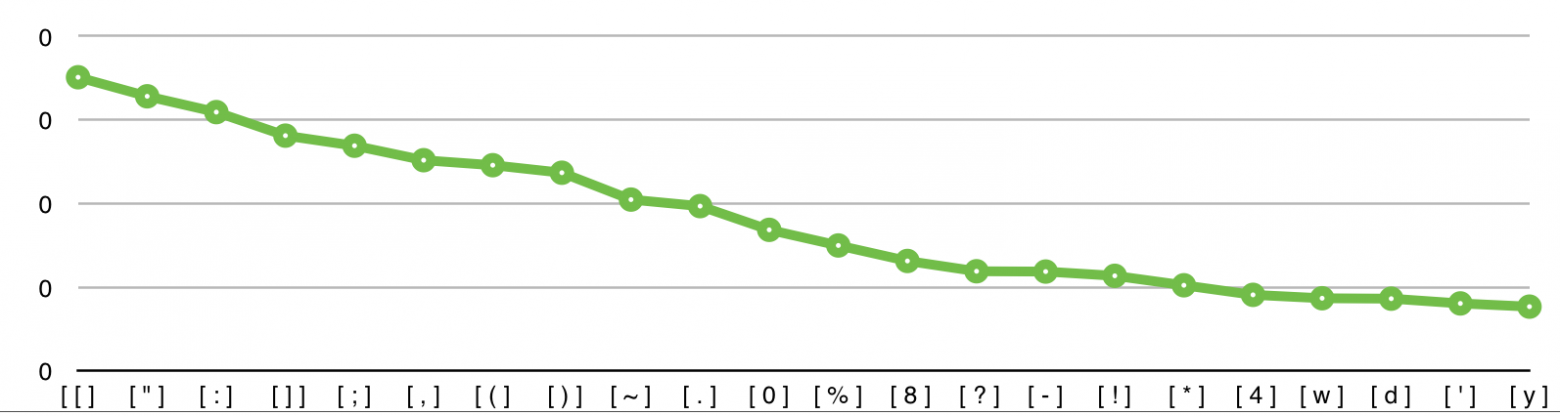
В этой диаграмме отображены символы, которые имеют наибольшую вероятность того, что именно они используются для разделения предложений.
Пример №2 (Punch, Or the London Charivari, Volume 107, December 8th, 1894)
www.gutenberg.org/ebooks/46816
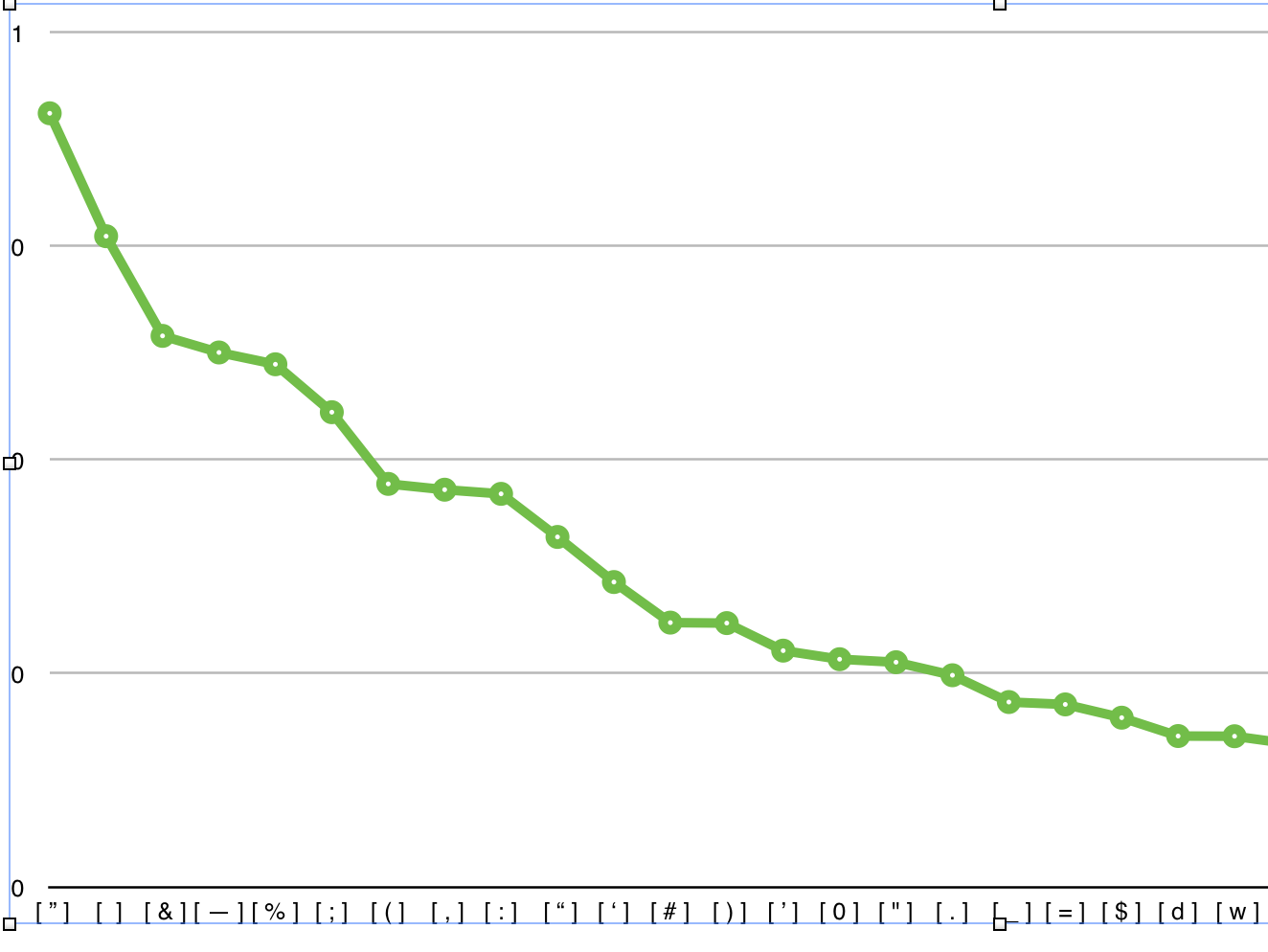
В этой диаграмме отображены символы, которые имеют наибольшую вероятность того, что именно они используются для разделения предложений.
Пример № 3 (William S.Burroughs. Naked lunch)
en.wikipedia.org/wiki/Naked_Lunch
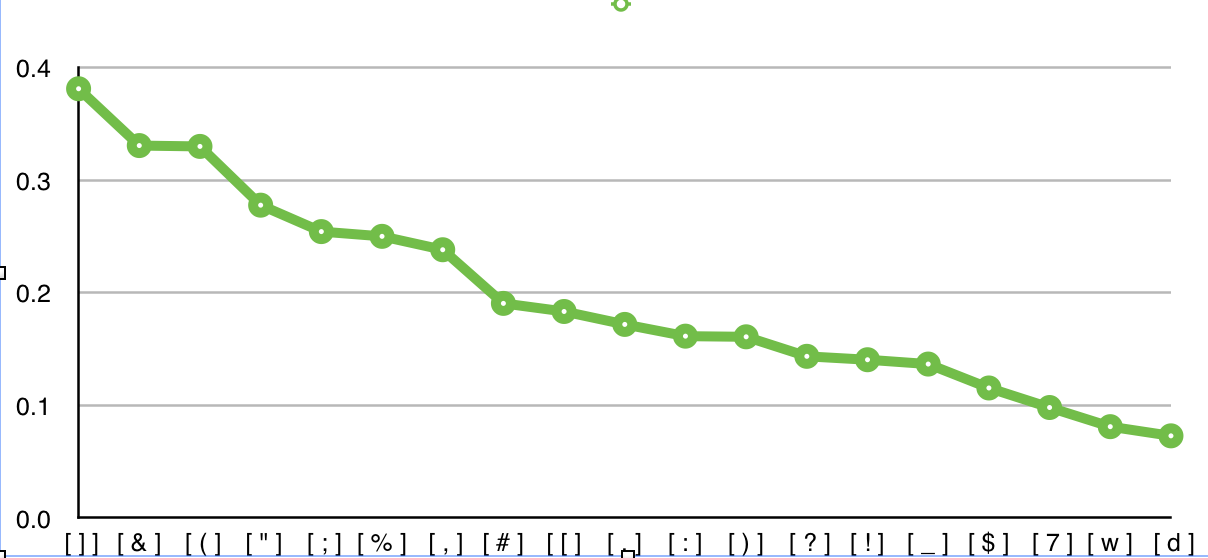
В этой диаграмме отображены символы, которые имеют наибольшую вероятность того, что именно они используются для разделения предложений.
Конечно, наличия таких вероятностей не дает сам результат. Вам все еще необходимо понять, где предел, который делит эти символы на «разделители» и «остальные символы» предложений. Также нужно уметь разделить символы на группы: те, которые разделяют текст на предложения и делят само предложение на части.
Полученные результаты легко воспроизвести, воспользовавшись CLI, который использует нашу библиотеку.
Простейший CLI для AIF
- Ссылка на GitGub: github.com/b0noI/aif-cli/wiki
- Для загрузки: s3.amazonaws.com/aif2/aif-cli/1.0/aif-cli.jar
Вы можете воспользоваться им следующий образом:
java -jar aif-cli.jar <key> <path_to_txt_file>
К примеру, вы можете разделить Ваш текст на предложения, используя команду:
java -jar aif-cli.jar —ssplit <path_to_txt_file>
Или же на токены:
java -jar aif-cli.jar —tsplit <path_to_txt_file>
Или же вы можете вывести символы с наибольшей вероятностью того, что они являются разделителями предложений:
java -jar aif-cli.jar —ess <path_to_txt_file>
Использование библиотеки AIF
Вы можете начать использовать нашу библиотеку версии Alpha 1 в вашем проекте. Для этого необходимо просто присоединить наш репозиторий Maven к проекту. Инструкция можно найти тут: github.com/b0noI/AIF2/wiki
На данный момент доступны лишь две функции:
Что планируется в следующей версии?
В первой Альфе мы не разделяем символы, которые являются разделитилями предложений на группы, к примеру:
- Группа 1: .!?
- Группа 2: “;’()
- Группа 3: ,:
Пока мы работаем со всеми «разделителями», как если бы они все находились в группе 1. Тем не менее начиная с Альфа2 версии у нас будет разделение на группы (совершенно верно, наша библиотека может подразделять «символы-разделители» без языковой модели!)
Также в Alpha 2 мы представим модуль лемматизации, который будет извлекать леммы из текста. И вновь, этот модуль будет работать полностью независимо от языка! AIF сможет извлекать леммы из текста, к примеру:
car, cars, car's, cars' => car
Поскольку в версии Alpha 2 НЕ БУДЕТ реализована возможность семантического анализа, то это означает, что мы не сможет извлечь леммы, как эта:
am, are, is => be
Но даже такую задачу возможно решить языково независимым способом. И она будет решена в последующих релизах.
Что планируется в следующей статье?
- сравнительный анализ качества разбития на предложения с другими ключевыми библиотеками;
- описание алгоритма выделения символов, которые разбивают текст на предложения;
- описание алгоритма деления символов на группы (те, что делят текст на предложения и сами предложения).
Послесловие
Само собой, текущая реализация не работает одинаково хорошо со всеми языками. Например, японский текст или языки, в которых не используют пробелы, все еще непонятный для AIF.
Наша команда
Kovalevskyi Viacheslav – algorithm developer, architecture design, team lead (viacheslav@b0noi.com / @b0noi)
Ifthikhan Nazeem – algorithm designer, architecture design, developer
Evgeniy Dolgikh(marcon@atsy.org.ua, marcon) – QA assistance, junior developer
Siarhei Varachai – QA assistance, junior developer
Balenko Aleksey (podorozhnick@gmail.com) – worked on Sentence Splitters for tests (using Stanford NLP and AIF NLP), added tokenization support for CLI, junior developer
Sviatoslav Glushchenko — REST design and implementation, developer
Oleg Kozlovskyi QA (integration and qaulity testing), developer.
Если у вас есть интересный проект NLP, свяжитесь с нами ;)
Ссылки на проект и подробности
- язык проекта: JDK8
- license: MIT license
- issue tracker: github.com/b0noI/AIF2/issues
- wiki: github.com/b0noI/AIF2/wiki
- source code: github.com/b0noI/AIF2
- developers mail list: aif2-dev@yahoogroups.com (subscribe: aif2-dev-subscribe@yahoogroups.com)
Послесловие ^2
Честно говоря, библиотека не является полной новинкой. В начале пути своей кандидатской я уже выкладывал часть алгоритмов в сыром виде и даже написал об этом статью на Хабр. Однако с тех пор много воды утекло, множество гипотез подтвердились, много было отвергнуто. Стала острая необходимость написать новую реализацию, которая воплощает накопленные и проверенные гипотезы в области НЛП.
Только в этот раз получилось привлечь к проекту больше разработчиков и мы пытаемся подойти к разработке более последовательно, нежели было в прошлый раз. Плюс получился очень неплохой проект на котором слушатели моего курса Java на Хекслет могут получить реальный опыт разработки проекта на Java в команде;)

