
Стильно, модно, молодежно сегодня делать сайт на AJAX, с точки зрения пользователя — это быстро и удобно, а у поисковых роботов с такими сайтами могут быть проблемы.
Самым правильным решением является использовать обычные ссылки, но подгружать контент ajax-ом, оставляя возможность получить контент по обычной ссылке для пользователей c отключенным JS (мало ли) и роботов. То есть инзачально нужно разрабатывать по старинке, с обычными ссылками, layout-ом и view-шками, затем можно обработать все ссылки javascript-ом, навесить на них подгрузку контента через ajax используя ссылку из аттрибута href, тега a, в очень упрощенном виде это должно выглядеть примерно так:
$(document).on('click', 'a.ajaxlinks', 'function(e) { e.stopPropagation(); e.preventDefault(); var pageurl = $(this).attr('href'); $.ajax({ url: pageurl, data: { ajax: 1 }, success: function( resp ) { $('#content').html(resp); } }); });
Здесь мы просто подгружаем те же страницы, но ajax-ом, при этом на бэкэнде нужно обработать специальный GET-параметр ajax и при его наличии отдавать страницу без layout-а, ну если грубо.
Но не всегда архитектура на это расчитана, к тому же сайты на angularjs, и ему подобным, работают несколько сложнее, и подставляют контент на подгруженный html-шаблон с переменными. Для таких сайтов (или можно уже назвать их приложениями) поисковые системы придумали технологию HashBang, в кратце — это ссылка вида example.com/#!/cats/grumpy-cat, когда поисковый робот видит #! он делает запрос на сервер по адресу example.com/?_escaped_fragment_=/cats/grumpy-cat, т.е. заменяет «#!» на «?_escaped_fragment_=», и сервер должен отдать сгенерированный html поисковику, идентичный тому, который увидел бы по изначальной ссылке пользователь. Но если в приложении используется HTML5 History API, и не применяются ссылки вида #!, нужно добавить в секцию head специальный мета тег:
<meta name="fragment" content="!" />
При виде этого тега, поисковый робот будет понимать, что сайт работает на ajax, и будет переадресовывать все запросы на получение контента сайта на ссылку: example.com/?_escaped_fragment_=/cats/grumpy-cat вместо example.com/cats/grumpy-cat.
Можно обрабатывать эти запросы средствами используемого фреймворка, но в сложном приложении с angularjs — это куча лишнего кода.
Путь которым мы пойдем описан на следующей схеме от гугл:
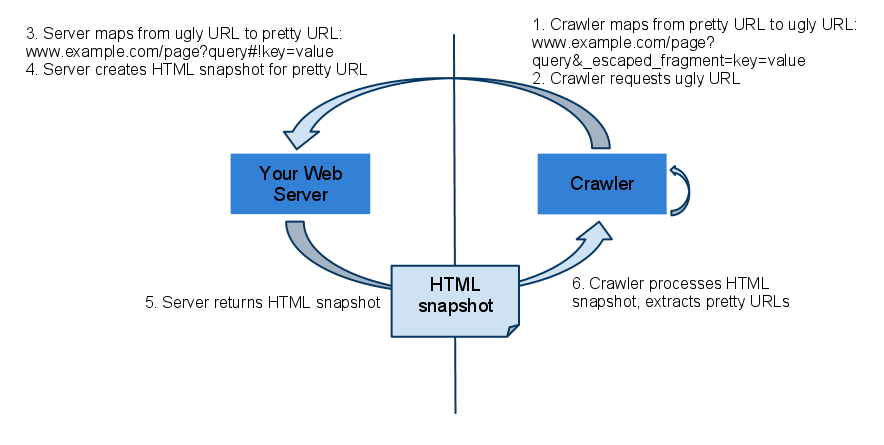
Для этого мы будем ловить все запросы с _escaped_fragment_ и отправлять их на phantom.js на сервере, который средствами серверного webkit будет генерировать html-слепок запрашиваемой страницы и отдавать его краулеру. Пользователи же останутся работать на прямую.
Для начала установим необходимый софт, если не установлен еще, примерно так:
yum install screen npm instamm phantomjs ln -s /usr/local/node_modules/phantomjs/lib/phantom/bin/phantomjs /usr/local/bin/phantomjs
Далее напишем (ну или возьмем готовый) серверный js-скрипт (server.js), который будет делать html-слепки:
var system = require('system'); if (system.args.length < 3) { console.log("Missing arguments."); phantom.exit(); } var server = require('webserver').create(); var port = parseInt(system.args[1]); var urlPrefix = system.args[2]; var parse_qs = function(s) { var queryString = {}; var a = document.createElement("a"); a.href = s; a.search.replace( new RegExp("([^?=&]+)(=([^&]*))?", "g"), function($0, $1, $2, $3) { queryString[$1] = $3; } ); return queryString; }; var renderHtml = function(url, cb) { var page = require('webpage').create(); page.settings.loadImages = false; page.settings.localToRemoteUrlAccessEnabled = true; page.onCallback = function() { cb(page.content); page.close(); }; // page.onConsoleMessage = function(msg, lineNum, sourceId) { // console.log('CONSOLE: ' + msg + ' (from line #' + lineNum + ' in "' + sourceId + '")'); // }; page.onInitialized = function() { page.evaluate(function() { setTimeout(function() { window.callPhantom(); }, 10000); }); }; page.open(url); }; server.listen(port, function (request, response) { var route = parse_qs(request.url)._escaped_fragment_; // var url = urlPrefix // + '/' + request.url.slice(1, request.url.indexOf('?')) // + (route ? decodeURIComponent(route) : ''); var url = urlPrefix + '/' + request.url; renderHtml(url, function(html) { response.statusCode = 200; response.write(html); response.close(); }); }); console.log('Listening on ' + port + '...'); console.log('Press Ctrl+C to stop.');
И запустим его в скрине с помощью phantomjs:
screen -d -m phantomjs --disk-cache=no server.js 8888 http://example.com
Далее сконфигурируем nginx (apache аналогично) на проксирование запросов на запущенный демон:
server { ... if ($args ~ "_escaped_fragment_=(.+)") { set $real_url $1; rewrite ^ /crawler$real_url; } location ^~ /crawler { proxy_pass http://127.0.0.1:8888/$real_url; } ... }
Теперь при запросе example.com/cats/grumpy-cat поисковые роботы будут обращаться по ссылке example.com/?_escaped_fragment_=cats/grumpy-cat, которая перехватится nginx-ом, отправится phantomjs-у, который на сервере через браузерный движок сгенерирует html и отдаст его роботу.
Кроме поисковых роботов гугла, яндекса и бинга, это будет также работать и для шаринга ссылки через facebook.
Ссылки:
https://developers.google.com/webmasters/ajax-crawling/docs/getting-started
https://help.yandex.ru/webmaster/robot-workings/ajax-indexing.xml
UPD (2.12.16):
Конфиги для apache2 от kot-ezhva:
В случае если используется html5mode:
RewriteEngine on RewriteCond %{QUERY_STRING} (.*)_escaped_fragment_= RewriteRule ^(.*) 127.0.0.1:8888/$1 [P] ProxyPassReverse / 127.0.0.1:8888/
Если урлы с решеткой:
RewriteEngine on RewriteCond %{QUERY_STRING} _escaped_fragment_=(.*) RewriteRule ^(.*) 127.0.0.1:8888/$1 [P] ProxyPassReverse / 127.0.0.1:8888/

