Как известно, для обработки соединений NGINX использует асинхронный событийный подход. Вместо того, чтобы выделять на каждый запрос отдельный поток или процесс (как это делают серверы с традиционной архитектурой), NGINX мультиплексирует обработку множества соединений и запросов в одном рабочем процессе. Для этого применяются сокеты в неблокирующем режиме и такие эффективные методы работы с событиями, как epoll и kqueue.
За счет малого и постоянного количества полновесных потоков обработки (обычно по одному на ядро) достигается экономия памяти, а также ресурсов процессора на переключении контекстов. Все преимущества данного подхода вы можете хорошо наблюдать на примере самого NGINX, который способен обрабатывать миллионы запросов одновременно и хорошо масштабироваться.
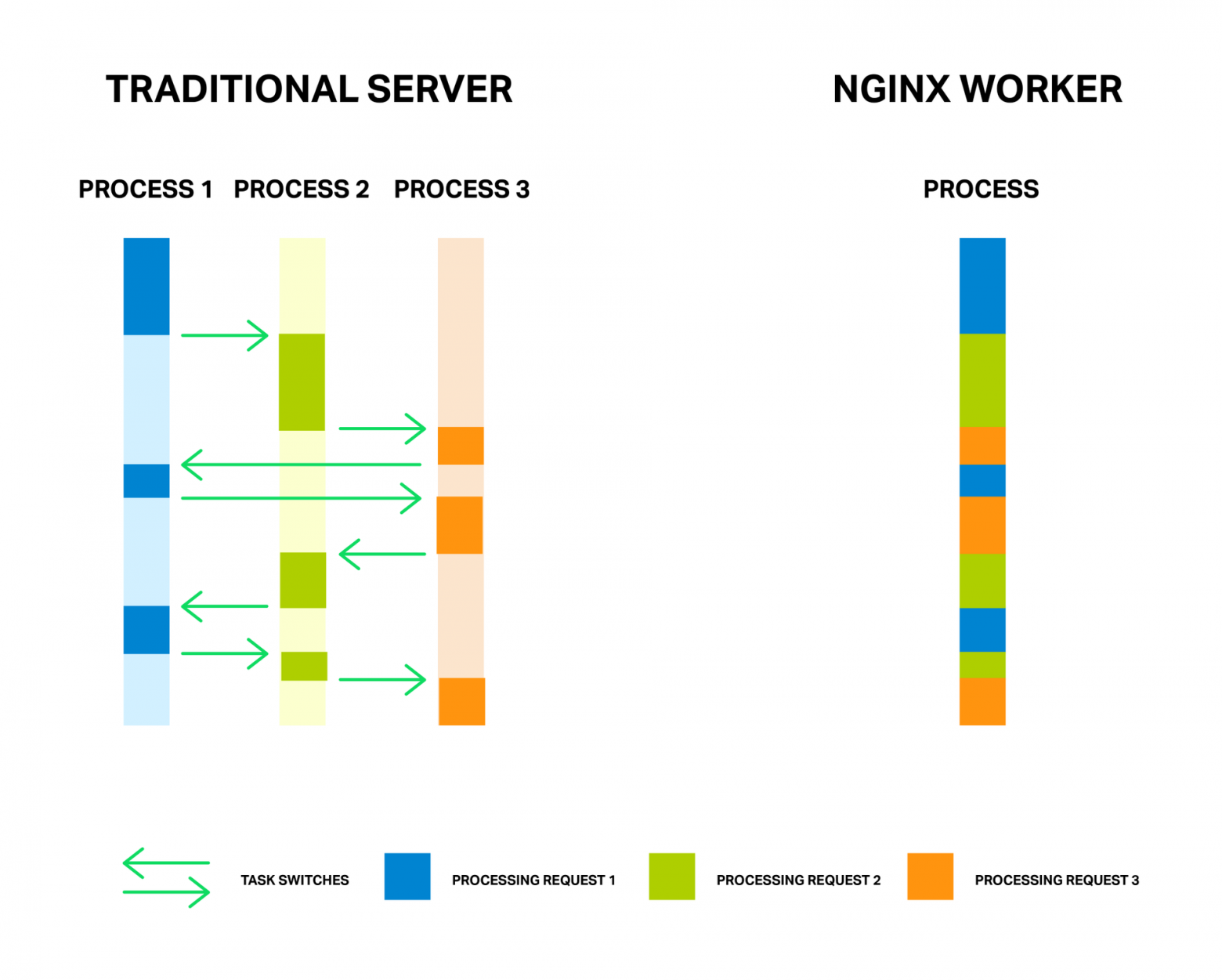 Каждый процесс расходует память и каждое переключение между ними требует дополнительных циклов процессора, а также приводит к вымыванию L-кэшей
Каждый процесс расходует память и каждое переключение между ними требует дополнительных циклов процессора, а также приводит к вымыванию L-кэшей
У медали есть и обратная сторона. Главной проблемой асинхронного подхода, а лучше даже сказать «врагом» — являются блокирующие операции. И, к сожалению, многие авторы сторонних модулей, не понимая принципов функционирования NGINX, пытаются выполнять блокирующие операции в своих модулях. Такие операции способны полностью убить производительность NGINX и их следует избегать любой ценой.
Но даже в текущей реализации NGINX не всегда возможно избежать блокировок. И для решения данной проблемы в NGINX версии 1.7.11 был представлен новый механизм «пулов потоков». Что это такое и как его применять разберем далее, а для начала познакомимся с нашим врагом в лицо.
Для лучшего понимания проблемы сперва разберемся подробнее в основных моментах относительно того, как работает NGINX.
По принципу работы NGINX из себя представляет такой обработчик событий, контроллер, который получает из ядра информацию обо всех событиях, произошедших в соединениях, а затем отдает команды операционной системе, что же ей делать. Фактически NGINX решает самую сложную задачу по манипулированию ресурсами системы, а операционная система занимается всей рутиной, чтением и отправкой байт информации. Так очень большое значение имеет то, насколько быстро и своевременно рабочий процесс NGINX будет реагировать на события.
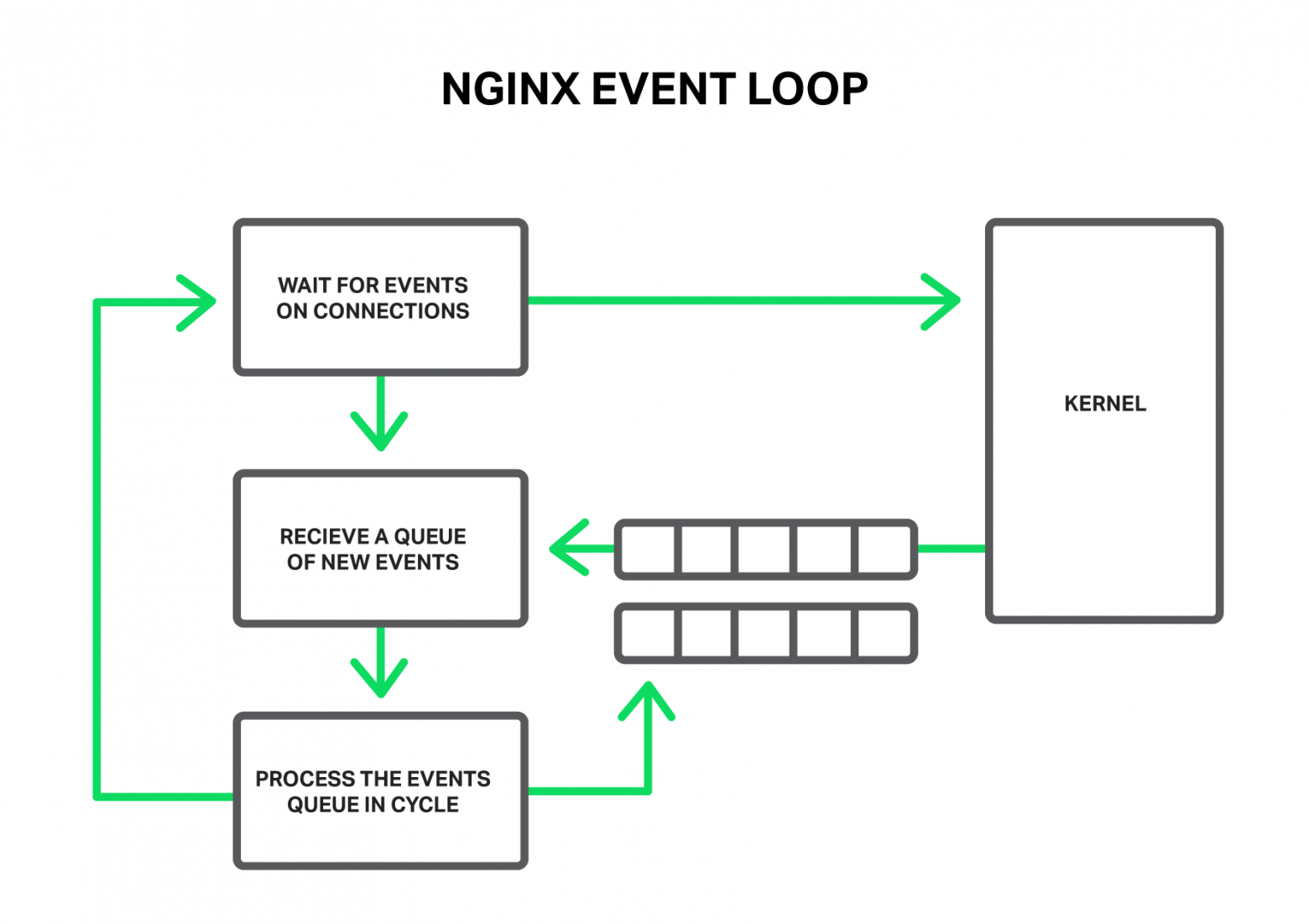 Рабочий процесс получает события из ядра и обрабатывает их.
Рабочий процесс получает события из ядра и обрабатывает их.
Такими событиями могут быть: события таймера, поступление новых данных или отправка ответа и освобождение места в буфере, уведомления об ошибках в соединении или его закрытие. NGINX получает пачку таких событий и начинает их по очереди обрабатывать, выполняя необходимые действия. Так вся обработка очереди событий происходит в простом цикле в одном потоке. NGINX извлекает из очереди события одно за другим и производит какие-то действия, например, пишет в сокет данные или читает. В большинстве случаев это происходит настолько быстро (чаще всего это просто копирования небольших объемов данных в памяти), что можно считать обработку всех событий мгновенной.
 Вся обработка происходит простым циклом в одном потоке.
Вся обработка происходит простым циклом в одном потоке.
Но что произойдет, если попытаться выполнить какую-то долгую и тяжелую операцию? Весь цикл обработки событий остановится на ожидании завершения этой операции.
Так, под блокирующей операцией мы подразумеваем любую операцию, которая задерживает цикл обработки событий на существенное время. Операции можно назвать блокирующими по разным причинам. Например, NGINX может быть занят долгой ресурсоемкой вычислительной операцией, либо он может ожидать доступа к какому-то ресурсу (жесткому диску, мьютексу, библиотечному вызову, ожидающему ответа от базы данных в синхронном режиме, и т. д.). Ключевым моментом тут является то, что во время выполнения этих операций рабочий процесс не может делать более ничего полезного, не может обрабатывать другие события, хотя у нас зачастую есть еще свободные ресурсы, и события, ожидающие далее в очереди, могут их использовать.
Представьте себе продавца в магазине, к которому выстроилась огромная очередь из покупателей. И вот первый человек из очереди подходит к кассе и хочет купить товар, которого нет на витрине, но есть на дальнем складе. Продавец просит подождать пару часов и уезжает на склад за товаром. Можете себе вообразить реакцию остальных покупателей, стоящих в очереди? Теперь их время ожидания увеличилось на эти два часа, хотя для многих то, что им необходимо, лежит в нескольких метрах на прилавке.
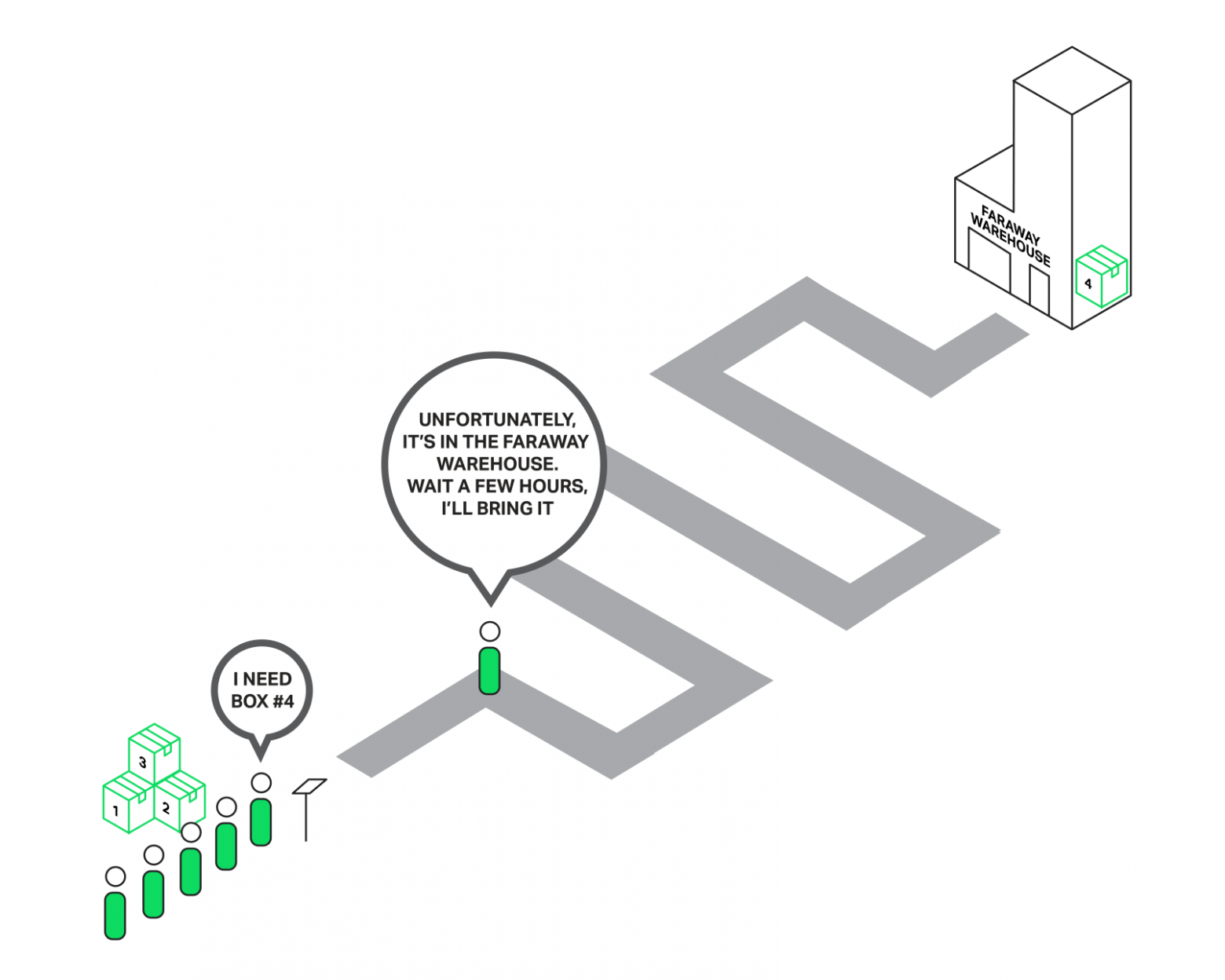 Вся очередь вынуждена ждать исполнения заказа для первого покупателя.
Вся очередь вынуждена ждать исполнения заказа для первого покупателя.
Похожая ситуация происходит в NGINX, когда файл, который нужно отправить, находится не в памяти, а на жестком диске. Диски медленные (особенно те, что вращаются), а остальные запросы, которые ждут своей обработки в очереди, могут не требовать доступа к жестком диску, но все равно вынуждены ждать. В результате растут задержки и ресурсы системы могут не использоваться полностью.
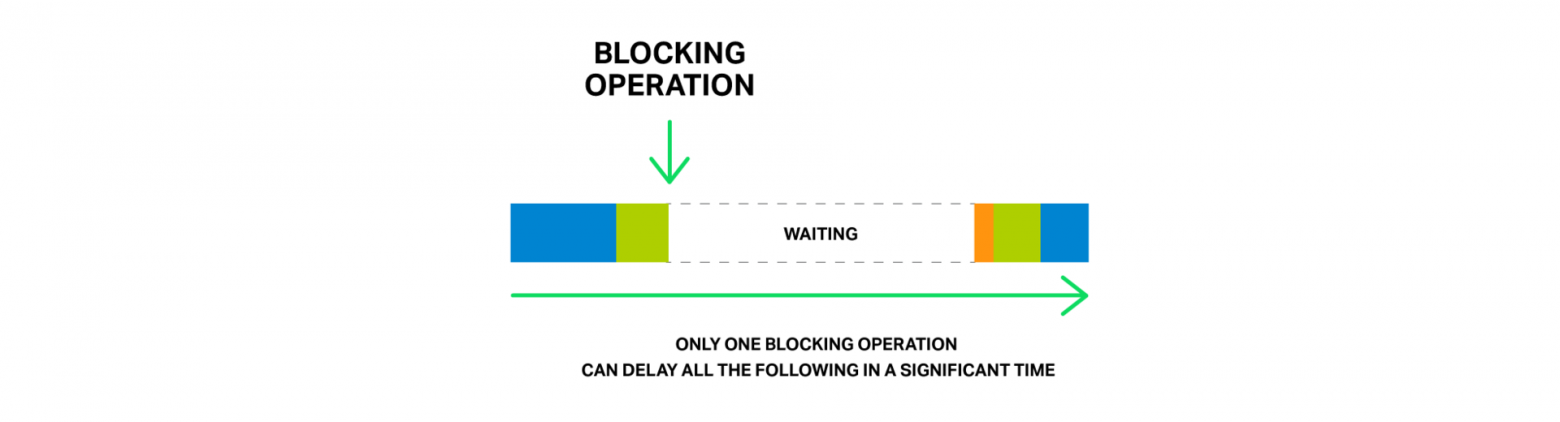 Всего одна блокирующая операция может существенно задержать обработку всех последующих.
Всего одна блокирующая операция может существенно задержать обработку всех последующих.
Некоторые операционные системы предоставляют интерфейсы для асинхронного чтения файлов и NGINX умеет эффективно использовать их (см. описание директивы aio). Хорошим примером такой системы является FreeBSD. К сожалению, нельзя сказать того же о Linux. Хотя в Linux и существует некий асинхронный интерфейс для чтения файлов, но он обладает рядом существенных недостатков. Одним из таких является требования к выравниванию чтений и буферов. С этим NGINX успешно с справляется, но вторая проблема хуже. Для асинхронного чтения требуется установка флага
В частности для решения данной проблемы в NGINX 1.7.11 и был представлен новый механизм пулов потоков. Они пока не включены в NGINX Plus, но вы можете связаться с отделом продаж, если желаете испытать сборку NGINX Plus R6 с пулами потоков.
А теперь разберем подробнее, что же они из себя представляют и как функционируют.
Вернемся к нашему незадачливому продавцу. Но на этот раз он оказался находчивее (или это после того, как его побили разъяренные покупатели?) и организовал курьерскую службу. Теперь, когда покупатель запрашивает товар, которого нет на прилавке, то вместо того, чтобы покидать прилавок, отправляясь за товаром самостоятельно и вынуждая всех остальных ждать, он отправляет запрос на доставку товара в курьерскую службу и продолжает обслуживать очередь покупателей. Таким образом только те покупатели, чьих заказов не оказалось в магазине, ожидают доставки, а продавец тем временем может без проблем обслуживать остальных.
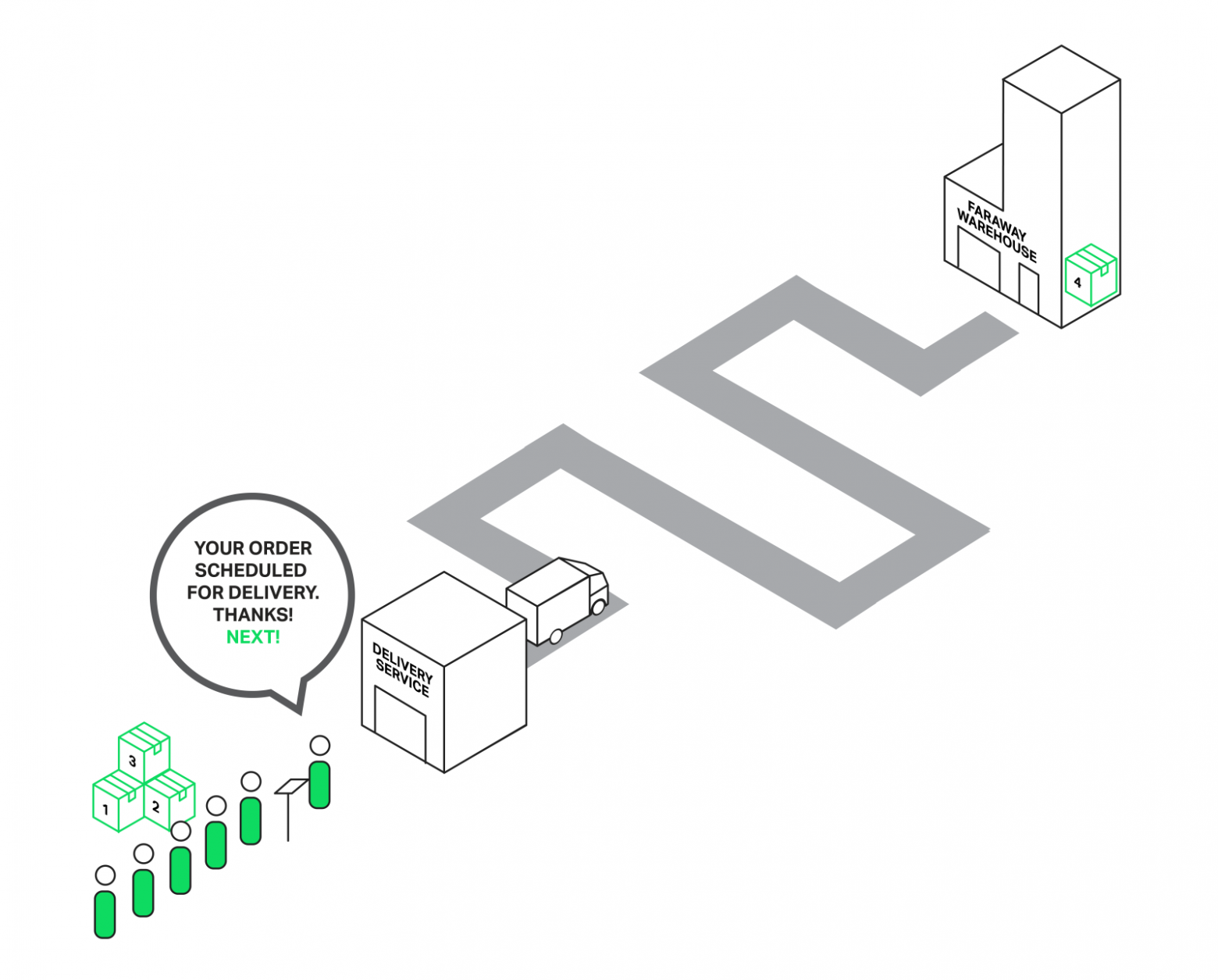 Обработка заказов курьерской службой не блокирует очередь.
Обработка заказов курьерской службой не блокирует очередь.
В случае NGINX роль курьерской службы выполняет пул потоков. Он состоит из очереди заданий и набора отдельных легковесных потоков, которые обрабатывают эту очередь. Когда рабочему процессу требует выполнить какую-то потенциально долгую операцию, то он вместо того, чтобы заниматься этим самостоятельно, помещает задание на обработку в очередь пула, откуда его сразу же может забрать любой свободный поток в обработку.
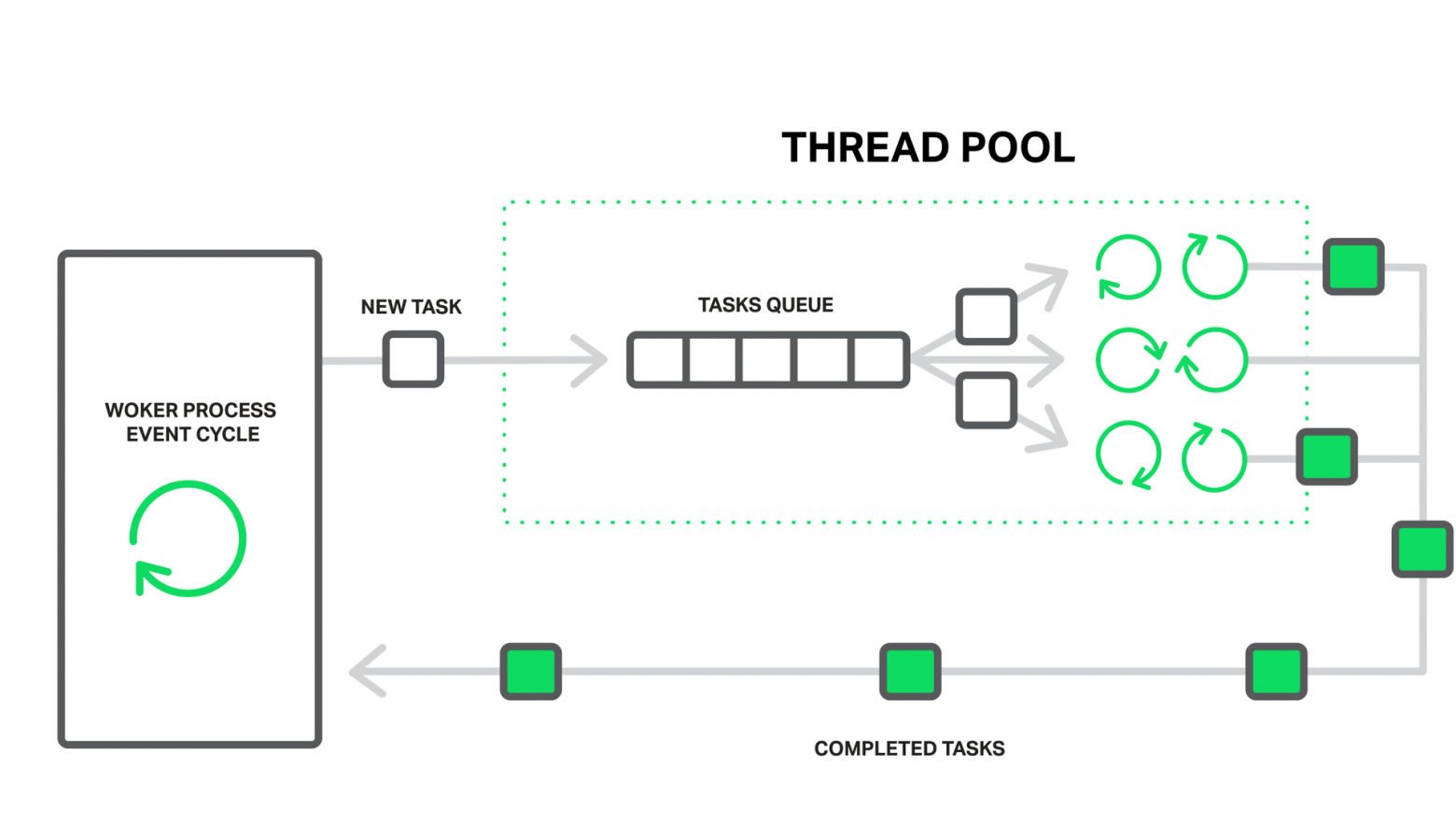 Рабочий процесс отдает обработку блокирующих операций в пул потоков.
Рабочий процесс отдает обработку блокирующих операций в пул потоков.
Кажется, что тут у нас еще одна очередь образовалась. Так и есть. Но в данном случае эта очередь ограничена конкретным ресурсом. Мы не можем читать с диска быстрее, чем на это способен он сам, но по крайней мере ожидание чтения теперь не задерживает обработку других событий.
Чтение с диска взято, как наиболее частый пример блокирующей операции, но на самом деле пулы потоков в NGINX могут применяться и для любых других задач, которые нерационально выполнять внутри основного рабочего цикла.
В настоящий момент выгрузка операций в пул потоков реализована только для системного вызова read() на большинстве операционных систем, а также для sendfile() на Linux. Мы продолжим исследования данного вопроса и, вероятно, в будущем реализуем выполнение и других операций пулом потоков, если это даст выигрыш в производительности.
Пора перейти от теории к практике. Для демонстрации эффекта от использования пулов потоков проведем небольшой эксперимент. А именно воссоздадим наиболее тяжелые условия, заставив NGINX выполнять смесь блокирующих и неблокирующих чтений, когда проблема блокировок на обращениях к диску проявит себя в полной мере.
Для это требуется набор данных, который гарантированно не поместится в кэш операционной системы. На машине с объемом оперативной памяти в 48 Гб было сгенерировано 256 Гб файлов по 4 Мб каждый, содержащих рандомные данные и запущен NGINX версии 1.9.0 для их раздачи.
Конфигурация достаточно проста:
Как вы можете заметить, для получения лучших показателей произведен небольшой тюнинг: отключено логирование, отключен accept_mutex, включен sendfile и настроено значение sendfile_max_chunk. Последнее позволяет сократить время блокировки на вызове
Машина снабжена двумя процессорами Intel Xeon E5645 (всего 12 ядер, 24 HyperThreading потока) и сетевым интерфейсом 10 ГБит. Дисковая подсистема представляет из себя 4 жестких диска Western Digital WD1003FBYX объединенных в RAID10 массив. Все это управляется операционной системой Ubuntu Server 14.04.1 LTS.
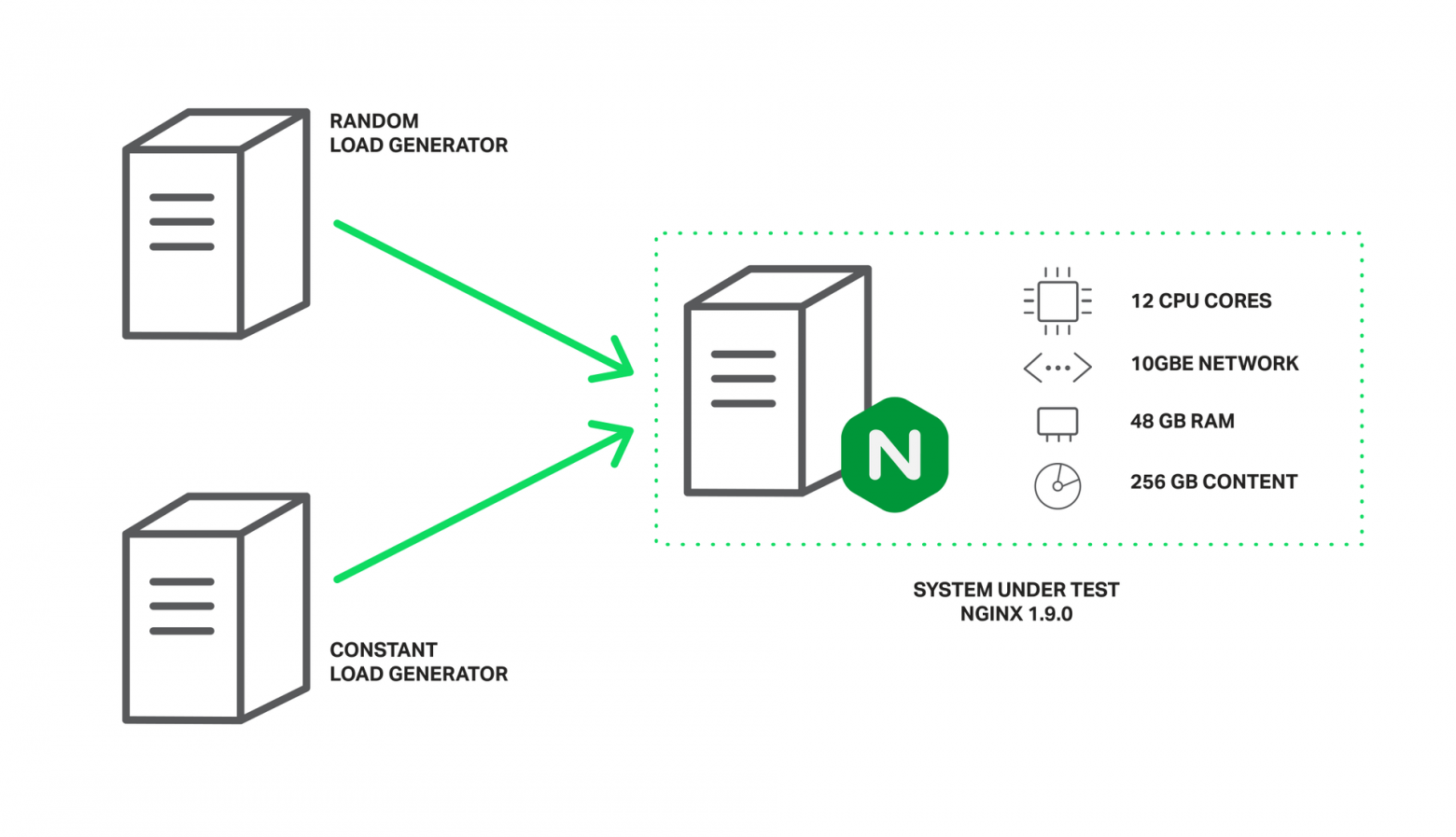 Конфигурация тестового стенда.
Конфигурация тестового стенда.
В качестве клиентов выступают две аналогичные по характеристикам машины. На одной из них запущен wrk, создающий постоянную нагрузку Lua-скриптом. Скрипт запрашивает файлы из хранилища в случайном порядке используя 200 параллельных соединений. Назовем данную нагрузку паразитной.
С другой машины-клиента мы будем запускать
Производительность мы будем измерять по показателям
Итак, первый запуск без использования пулов потоков показывает очень скромные результаты:
Как видно с данной конфигурацией и под такой нагрузкой сервер способен выдавать порядка одного гигабита в секунду. При этом в top-е можно наблюдать, что все рабочие процессы NGINX находятся большую часть времени в состоянии блокировки на I/O (помечены буквой
В данном случае все упирается в производительность дисковой подсистемы, при этом процессор большую часть времени простаивает. Результаты
Достаточно существенные задержки даже на раздаче всего одного файла из памяти. Все рабочие процессы заняты чтением с диска для обслуживания 200 соединений с первой машины, создающей паразитную нагрузку, и не могут своевременно обработать данные тестовые запросы.
А теперь подключим пул потоков, для чего добавим директиву
и попросим наш NGINX перезагрузить конфигурацию.
Повторим тест:
Теперь наш сервер выдает 9,5 ГБит/сек (против ~1 ГБит/сек без пулов потоков)!
Вероятно он мог бы отдавать и больше, но это является практическим пределом для данного сетевого интерфейса и NGINX упирается в пропускную способность сети. Рабочие процессы большую часть времени спят в ожидании событий (находятся в состоянии
И у нас еще есть солидный запас по ресурсам процессора.
Результаты
Среднее время отдачи 4 Мб файла сократилось с 7.42 секунд до 226.32 миллисекунд, т.е. в ~33 раза, а количество обрабатываемых запросов в секунду возросло в 31 раз (250 против 8)!
Объясняется все это тем, что теперь запросы более не ждут в очереди на обработку, пока рабочие процессы заблокированы на чтении с диска, а обслуживаются свободными потоками. И пока дисковая подсистема делает свою работу как может, обслуживая наш “паразитный” трафик с первой машины, NGINX использует оставшиеся ресурсы процессора и пропускную способность сети, чтобы обслужить второго клиента из памяти.
После всех страшилок про блокирующие операции и таких потрясающих результатов, многие из вас захотят скорее включит пулы потоков на своих серверах. Не спешите.
Правда в том, что, к счастью, в большинстве случаев операции с файлами не приводят к чтению с медленного жесткого диска. Если у вас хватает оперативной памяти, то современные операционные системы достаточно умны, чтобы закэшировать файлы, к которым часто происходит обращение в так называемом кэше страниц (page cache).
Кэш страниц справляется достаточно хорошо и это всегда позволяло NGINX демонстрировать высокую производительность в наиболее распространенных ситуациях. Чтения из кэша страниц происходят очень быстро и такую операцию нельзя назвать блокирующей. В то же время, взаимодействие с пулом потоков несет дополнительные издержки на синхронизацию.
Так что если у вас достаточно оперативной памяти и небольшой объем горячих данных, то у вас уже все хорошо и NGINX работает наиболее оптимальным образом без использования пулов потоков.
В действительности выгрузка операций чтения в отдельный пул потоков решает довольно узкий спектр задач. Он ограничен ситуациями, когда объем регулярно запрашиваемых данных не помещается в оперативной памяти, что делает кэш страниц операционной системы неэффективным. Таким примером может являться высоконагруженный сервис раздачи медиаданных. Данную ситуацию мы и симулировали в нашем тесте.
Выгрузку операций чтения в пулы потоков можно было бы сделать более универсальной для операций чтения и снизить задержки, если бы существовал эффективный способ узнать заранее, находятся ли необходимые данные в памяти или нет, и только в последнем случае выгружать операцию в отдельный поток.
Возвращаясь к аналогии с магазином и дальним складом, сейчас у продавца нет возможности узнать, что товар находится на витрине и он вынужден всегда работать посредством курьерской службы.
Дело в том, что отсутствует соответствующая поддержка со стороны ядра операционной системы. Первые попытки добавить такую возможность в Linux в виде системного вызова fincore() относятся к 2010 году, но «воз и ныне там». Позже были попытки в виде системного вызова
В то время, как пользователям FreeBSD не о чем беспокоиться, у них есть неплохо работающий механизм асинхронного чтения, реализованный в ядре. Именно его и рекомендуется использовать вместо пулов потоков.
Итак, если вы твердо уверены, что сможете извлечь выгоду из пула потоков для ваших задач, то непременно встает вопрос, как его включить и настроить.
Конфигурация достаточно простая и вместе с тем очень гибкая. Для начала вам потребуется NGINX версии 1.7.11 или выше, собранный с флагом
Это минимально возможный вариант настройки пулов потоков. На самом деле он является сокращенной версией такой конфигурации:
Она задает пул потоков
Такое возможно, если ваши потоки не справляются с объемом работы и очередь заполняется быстрее, чем обрабатывается. В этом случае вы можете попробовать увеличить максимальной размер очереди и если это не помогает, то значит ваша система просто не в состоянии обработать такое большое количество запросов.
Как можно заметить, с помощью директивы thread_pool у вас есть возможность задавать количество потоков, максимальный размер очереди, а также имя данного пула потоков. Последнее предполагает возможность сконфигурировать несколько независимых пулов и использовать их в разных частях конфигурации для разных задач:
Если параметр
А теперь представьте, что у вас есть сервер с тремя жесткими дисками, который должен выполнять роль кеширующего прокси для ваших бэкендов. При этом предполагаемый размер кэша многократно превосходит объем доступной оперативной памяти. По сути это что-то вроде кэш-ноды в вашей личной сети раздачи контента (CDN). В этом случае основная нагрузка по отдачи кэшированных данных будет ложиться на дисковую подсистему. Разумеется вы хотите извлечь максимум производительности из тех трех дисков, что имеются в наличии.
Одним из решений тут может стать организация RAID массива. У такого подхода конечно же есть свои плюсы и минусы. Но сегодня NGINX готов предложить вам другой подход:
В данной конфигурации используется три независимых кэша — по одному на каждый жесткий диск, и три независимых пула потоков, также по одному на диск.
Для равномерного распределения нагрузки между кэшами (а соответственно и жесткими дисками) используется модуль split_clients, который прекрасно для этого подходит.
Параметр
Все это вместе позволяет выжать максимум производительности из данной дисковой подсистемы, поскольку NGINX посредством отдельных пулов потоков взаимодействует с каждым диском параллельно и независимо. Каждый диск обслуживают 16 независимых потоков и для него формируется отдельная очередь заданий на чтение и отправку файлов.
Ведь ваши клиенты любят индивидуальных подход? Будьте уверены ваши жесткие диски тоже. ;)
Данный пример является демонстрацией огромной гибкости NGINX в конфигурировании непосредственно под ваше железо. Вы как бы инструктируете NGINX, каким образом лучше всего взаимодействовать с дисковой подсистемой на данном сервере и вашими данными. И такая тонкая настройка, когда программное обеспечение вплоть до пользовательского уровня работает с оборудованием самым оптимальным образом, обеспечивает наиболее эффективное использование всех ресурсов конкретной системы.
Пулы потоков — это замечательный механизм, который борется с основным и хорошо известным врагом асинхронного подхода — блокирующими операциями, и тем самым позволяет вывести NGINX на новый уровень производительности, особенно если мы говорим об очень больших объемах данных.
Как уже упоминалось ранее, пулы потоков могут быть использованы и для любых других операций и работы с библиотеками, не имеющими асинхронного интерфейса. Потенциально это открывает новые возможности для реализации модулей и функциональности, реализация которой без ущерба для производительности ранее была неосуществимой в разумные сроки. Можно потратить много усилий и времени на написание асинхронного варианта имеющийся библиотеки или в попытках добавить такой интерфейс, но возникал вопрос: «стоит ли игра свеч»? С пулами потоков данную задачу можно решить гораздо проще, создавая модули, работающие с блокирующими вызовами, и при этом не мешая NGINX выполнять свою основную задачу обрабатывая остальные запросы.
Так что много нового и интересного ждет NGINX в будущем. Оставайтесь с нами!
За счет малого и постоянного количества полновесных потоков обработки (обычно по одному на ядро) достигается экономия памяти, а также ресурсов процессора на переключении контекстов. Все преимущества данного подхода вы можете хорошо наблюдать на примере самого NGINX, который способен обрабатывать миллионы запросов одновременно и хорошо масштабироваться.
У медали есть и обратная сторона. Главной проблемой асинхронного подхода, а лучше даже сказать «врагом» — являются блокирующие операции. И, к сожалению, многие авторы сторонних модулей, не понимая принципов функционирования NGINX, пытаются выполнять блокирующие операции в своих модулях. Такие операции способны полностью убить производительность NGINX и их следует избегать любой ценой.
Но даже в текущей реализации NGINX не всегда возможно избежать блокировок. И для решения данной проблемы в NGINX версии 1.7.11 был представлен новый механизм «пулов потоков». Что это такое и как его применять разберем далее, а для начала познакомимся с нашим врагом в лицо.
Проблема
Для лучшего понимания проблемы сперва разберемся подробнее в основных моментах относительно того, как работает NGINX.
По принципу работы NGINX из себя представляет такой обработчик событий, контроллер, который получает из ядра информацию обо всех событиях, произошедших в соединениях, а затем отдает команды операционной системе, что же ей делать. Фактически NGINX решает самую сложную задачу по манипулированию ресурсами системы, а операционная система занимается всей рутиной, чтением и отправкой байт информации. Так очень большое значение имеет то, насколько быстро и своевременно рабочий процесс NGINX будет реагировать на события.
Такими событиями могут быть: события таймера, поступление новых данных или отправка ответа и освобождение места в буфере, уведомления об ошибках в соединении или его закрытие. NGINX получает пачку таких событий и начинает их по очереди обрабатывать, выполняя необходимые действия. Так вся обработка очереди событий происходит в простом цикле в одном потоке. NGINX извлекает из очереди события одно за другим и производит какие-то действия, например, пишет в сокет данные или читает. В большинстве случаев это происходит настолько быстро (чаще всего это просто копирования небольших объемов данных в памяти), что можно считать обработку всех событий мгновенной.
Но что произойдет, если попытаться выполнить какую-то долгую и тяжелую операцию? Весь цикл обработки событий остановится на ожидании завершения этой операции.
Так, под блокирующей операцией мы подразумеваем любую операцию, которая задерживает цикл обработки событий на существенное время. Операции можно назвать блокирующими по разным причинам. Например, NGINX может быть занят долгой ресурсоемкой вычислительной операцией, либо он может ожидать доступа к какому-то ресурсу (жесткому диску, мьютексу, библиотечному вызову, ожидающему ответа от базы данных в синхронном режиме, и т. д.). Ключевым моментом тут является то, что во время выполнения этих операций рабочий процесс не может делать более ничего полезного, не может обрабатывать другие события, хотя у нас зачастую есть еще свободные ресурсы, и события, ожидающие далее в очереди, могут их использовать.
Представьте себе продавца в магазине, к которому выстроилась огромная очередь из покупателей. И вот первый человек из очереди подходит к кассе и хочет купить товар, которого нет на витрине, но есть на дальнем складе. Продавец просит подождать пару часов и уезжает на склад за товаром. Можете себе вообразить реакцию остальных покупателей, стоящих в очереди? Теперь их время ожидания увеличилось на эти два часа, хотя для многих то, что им необходимо, лежит в нескольких метрах на прилавке.
Похожая ситуация происходит в NGINX, когда файл, который нужно отправить, находится не в памяти, а на жестком диске. Диски медленные (особенно те, что вращаются), а остальные запросы, которые ждут своей обработки в очереди, могут не требовать доступа к жестком диску, но все равно вынуждены ждать. В результате растут задержки и ресурсы системы могут не использоваться полностью.
Некоторые операционные системы предоставляют интерфейсы для асинхронного чтения файлов и NGINX умеет эффективно использовать их (см. описание директивы aio). Хорошим примером такой системы является FreeBSD. К сожалению, нельзя сказать того же о Linux. Хотя в Linux и существует некий асинхронный интерфейс для чтения файлов, но он обладает рядом существенных недостатков. Одним из таких является требования к выравниванию чтений и буферов. С этим NGINX успешно с справляется, но вторая проблема хуже. Для асинхронного чтения требуется установка флага
O_DIRECT на файловом дескрипторе. Это означает, что все данные будут читаться с диска минуя кэш страниц операционной системы (т. н. page cache), что во многих случаях не является оптимальным и существенно увеличивает нагрузку на дисковую подсистему.В частности для решения данной проблемы в NGINX 1.7.11 и был представлен новый механизм пулов потоков. Они пока не включены в NGINX Plus, но вы можете связаться с отделом продаж, если желаете испытать сборку NGINX Plus R6 с пулами потоков.
А теперь разберем подробнее, что же они из себя представляют и как функционируют.
Пулы потоков
Вернемся к нашему незадачливому продавцу. Но на этот раз он оказался находчивее (или это после того, как его побили разъяренные покупатели?) и организовал курьерскую службу. Теперь, когда покупатель запрашивает товар, которого нет на прилавке, то вместо того, чтобы покидать прилавок, отправляясь за товаром самостоятельно и вынуждая всех остальных ждать, он отправляет запрос на доставку товара в курьерскую службу и продолжает обслуживать очередь покупателей. Таким образом только те покупатели, чьих заказов не оказалось в магазине, ожидают доставки, а продавец тем временем может без проблем обслуживать остальных.
В случае NGINX роль курьерской службы выполняет пул потоков. Он состоит из очереди заданий и набора отдельных легковесных потоков, которые обрабатывают эту очередь. Когда рабочему процессу требует выполнить какую-то потенциально долгую операцию, то он вместо того, чтобы заниматься этим самостоятельно, помещает задание на обработку в очередь пула, откуда его сразу же может забрать любой свободный поток в обработку.
Кажется, что тут у нас еще одна очередь образовалась. Так и есть. Но в данном случае эта очередь ограничена конкретным ресурсом. Мы не можем читать с диска быстрее, чем на это способен он сам, но по крайней мере ожидание чтения теперь не задерживает обработку других событий.
Чтение с диска взято, как наиболее частый пример блокирующей операции, но на самом деле пулы потоков в NGINX могут применяться и для любых других задач, которые нерационально выполнять внутри основного рабочего цикла.
В настоящий момент выгрузка операций в пул потоков реализована только для системного вызова read() на большинстве операционных систем, а также для sendfile() на Linux. Мы продолжим исследования данного вопроса и, вероятно, в будущем реализуем выполнение и других операций пулом потоков, если это даст выигрыш в производительности.
Тестируем производительность
Пора перейти от теории к практике. Для демонстрации эффекта от использования пулов потоков проведем небольшой эксперимент. А именно воссоздадим наиболее тяжелые условия, заставив NGINX выполнять смесь блокирующих и неблокирующих чтений, когда проблема блокировок на обращениях к диску проявит себя в полной мере.
Для это требуется набор данных, который гарантированно не поместится в кэш операционной системы. На машине с объемом оперативной памяти в 48 Гб было сгенерировано 256 Гб файлов по 4 Мб каждый, содержащих рандомные данные и запущен NGINX версии 1.9.0 для их раздачи.
Конфигурация достаточно проста:
worker_processes 16; events { accept_mutex off; } http { include mime.types; default_type application/octet-stream; access_log off; sendfile on; sendfile_max_chunk 512k; server { listen 8000; location / { root /storage; } } }
Как вы можете заметить, для получения лучших показателей произведен небольшой тюнинг: отключено логирование, отключен accept_mutex, включен sendfile и настроено значение sendfile_max_chunk. Последнее позволяет сократить время блокировки на вызове
sendfile(), поскольку в этом случае NGINX не станет пытаться прочесть и отправить весь файл за раз, а будет это делать частями по 512 килобайт.Машина снабжена двумя процессорами Intel Xeon E5645 (всего 12 ядер, 24 HyperThreading потока) и сетевым интерфейсом 10 ГБит. Дисковая подсистема представляет из себя 4 жестких диска Western Digital WD1003FBYX объединенных в RAID10 массив. Все это управляется операционной системой Ubuntu Server 14.04.1 LTS.
В качестве клиентов выступают две аналогичные по характеристикам машины. На одной из них запущен wrk, создающий постоянную нагрузку Lua-скриптом. Скрипт запрашивает файлы из хранилища в случайном порядке используя 200 параллельных соединений. Назовем данную нагрузку паразитной.
С другой машины-клиента мы будем запускать
wrk, который будет запрашивать один и тот же файл в 50 потоков. Поскольку к данному файлу идет постоянное обращение, то, в отличие от файлов, запрашиваемых в случайном порядке, он не будет успевать вымываться из кэша операционной системы и его чтение всегда будет происходить из памяти. Назовем такую нагрузку тестовой.Производительность мы будем измерять по показателям
ifstat на сервере и статистике wrk со второй машины-клиента.Итак, первый запуск без использования пулов потоков показывает очень скромные результаты:
% ifstat -bi eth2 eth2 Kbps in Kbps out 5531.24 1.03e+06 4855.23 812922.7 5994.66 1.07e+06 5476.27 981529.3 6353.62 1.12e+06 5166.17 892770.3 5522.81 978540.8 6208.10 985466.7 6370.79 1.12e+06 6123.33 1.07e+06
Как видно с данной конфигурацией и под такой нагрузкой сервер способен выдавать порядка одного гигабита в секунду. При этом в top-е можно наблюдать, что все рабочие процессы NGINX находятся большую часть времени в состоянии блокировки на I/O (помечены буквой
D):top - 10:40:47 up 11 days, 1:32, 1 user, load average: 49.61, 45.77 62.89 Tasks: 375 total, 2 running, 373 sleeping, 0 stopped, 0 zombie %Cpu(s): 0.0 us, 0.3 sy, 0.0 ni, 67.7 id, 31.9 wa, 0.0 hi, 0.0 si, 0.0 st KiB Mem: 49453440 total, 49149308 used, 304132 free, 98780 buffers KiB Swap: 10474236 total, 20124 used, 10454112 free, 46903412 cached Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 4639 vbart 20 0 47180 28152 496 D 0.7 0.1 0:00.17 nginx 4632 vbart 20 0 47180 28196 536 D 0.3 0.1 0:00.11 nginx 4633 vbart 20 0 47180 28324 540 D 0.3 0.1 0:00.11 nginx 4635 vbart 20 0 47180 28136 480 D 0.3 0.1 0:00.12 nginx 4636 vbart 20 0 47180 28208 536 D 0.3 0.1 0:00.14 nginx 4637 vbart 20 0 47180 28208 536 D 0.3 0.1 0:00.10 nginx 4638 vbart 20 0 47180 28204 536 D 0.3 0.1 0:00.12 nginx 4640 vbart 20 0 47180 28324 540 D 0.3 0.1 0:00.13 nginx 4641 vbart 20 0 47180 28324 540 D 0.3 0.1 0:00.13 nginx 4642 vbart 20 0 47180 28208 536 D 0.3 0.1 0:00.11 nginx 4643 vbart 20 0 47180 28276 536 D 0.3 0.1 0:00.29 nginx 4644 vbart 20 0 47180 28204 536 D 0.3 0.1 0:00.11 nginx 4645 vbart 20 0 47180 28204 536 D 0.3 0.1 0:00.17 nginx 4646 vbart 20 0 47180 28204 536 D 0.3 0.1 0:00.12 nginx 4647 vbart 20 0 47180 28208 532 D 0.3 0.1 0:00.17 nginx 4631 vbart 20 0 47180 756 252 S 0.0 0.1 0:00.00 nginx 4634 vbart 20 0 47180 28208 536 D 0.0 0.1 0:00.11 nginx 4648 vbart 20 0 25232 1956 1160 R 0.0 0.0 0:00.08 top 25921 vbart 20 0 121956 2232 1056 S 0.0 0.0 0:01.97 sshd 25923 vbart 20 0 40304 4160 2208 S 0.0 0.0 0:00.53 zsh
В данном случае все упирается в производительность дисковой подсистемы, при этом процессор большую часть времени простаивает. Результаты
wrk также неутешительны: Running 1m test @ http://192.0.2.1:8000/1/1/1 12 threads and 50 connections Thread Stats Avg Stdev Max +/- Stdev Latency 7.42s 5.31s 24.41s 74.73% Req/Sec 0.15 0.36 1.00 84.62% 488 requests in 1.01m, 2.01GB read Requests/sec: 8.08 Transfer/sec: 34.07MB
Достаточно существенные задержки даже на раздаче всего одного файла из памяти. Все рабочие процессы заняты чтением с диска для обслуживания 200 соединений с первой машины, создающей паразитную нагрузку, и не могут своевременно обработать данные тестовые запросы.
А теперь подключим пул потоков, для чего добавим директиву
aio threads в блок location с хранилищем:location / { root /storage; aio threads; }
и попросим наш NGINX перезагрузить конфигурацию.
Повторим тест:
% ifstat -bi eth2 eth2 Kbps in Kbps out 60915.19 9.51e+06 59978.89 9.51e+06 60122.38 9.51e+06 61179.06 9.51e+06 61798.40 9.51e+06 57072.97 9.50e+06 56072.61 9.51e+06 61279.63 9.51e+06 61243.54 9.51e+06 59632.50 9.50e+06
Теперь наш сервер выдает 9,5 ГБит/сек (против ~1 ГБит/сек без пулов потоков)!
Вероятно он мог бы отдавать и больше, но это является практическим пределом для данного сетевого интерфейса и NGINX упирается в пропускную способность сети. Рабочие процессы большую часть времени спят в ожидании событий (находятся в состоянии
S):top - 10:43:17 up 11 days, 1:35, 1 user, load average: 172.71, 93.84, 77.90 Tasks: 376 total, 1 running, 375 sleeping, 0 stopped, 0 zombie %Cpu(s): 0.2 us, 1.2 sy, 0.0 ni, 34.8 id, 61.5 wa, 0.0 hi, 2.3 si, 0.0 st KiB Mem: 49453440 total, 49096836 used, 356604 free, 97236 buffers KiB Swap: 10474236 total, 22860 used, 10451376 free, 46836580 cached Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 4654 vbart 20 0 309708 28844 596 S 9.0 0.1 0:08.65 nginx 4660 vbart 20 0 309748 28920 596 S 6.6 0.1 0:14.82 nginx 4658 vbart 20 0 309452 28424 520 S 4.3 0.1 0:01.40 nginx 4663 vbart 20 0 309452 28476 572 S 4.3 0.1 0:01.32 nginx 4667 vbart 20 0 309584 28712 588 S 3.7 0.1 0:05.19 nginx 4656 vbart 20 0 309452 28476 572 S 3.3 0.1 0:01.84 nginx 4664 vbart 20 0 309452 28428 524 S 3.3 0.1 0:01.29 nginx 4652 vbart 20 0 309452 28476 572 S 3.0 0.1 0:01.46 nginx 4662 vbart 20 0 309552 28700 596 S 2.7 0.1 0:05.92 nginx 4661 vbart 20 0 309464 28636 596 S 2.3 0.1 0:01.59 nginx 4653 vbart 20 0 309452 28476 572 S 1.7 0.1 0:01.70 nginx 4666 vbart 20 0 309452 28428 524 S 1.3 0.1 0:01.63 nginx 4657 vbart 20 0 309584 28696 592 S 1.0 0.1 0:00.64 nginx 4655 vbart 20 0 30958 28476 572 S 0.7 0.1 0:02.81 nginx 4659 vbart 20 0 309452 28468 564 S 0.3 0.1 0:01.20 nginx 4665 vbart 20 0 309452 28476 572 S 0.3 0.1 0:00.71 nginx 5180 vbart 20 0 25232 1952 1156 R 0.0 0.0 0:00.45 top 4651 vbart 20 0 20032 752 252 S 0.0 0.0 0:00.00 nginx 25921 vbart 20 0 121956 2176 1000 S 0.0 0.0 0:01.98 sshd 25923 vbart 20 0 40304 3840 2208 S 0.0 0.0 0:00.54 zsh
И у нас еще есть солидный запас по ресурсам процессора.
Результаты
wrk со второй машины:Running 1m test @ http://192.0.2.1:8000/1/1/1 12 threads and 50 connections Thread Stats Avg Stdev Max +/- Stdev Latency 226.32ms 392.76ms 1.72s 93.48% Req/Sec 20.02 10.84 59.00 65.91% 15045 requests in 1.00m, 58.86GB read Requests/sec: 250.57 Transfer/sec: 0.98GB
Среднее время отдачи 4 Мб файла сократилось с 7.42 секунд до 226.32 миллисекунд, т.е. в ~33 раза, а количество обрабатываемых запросов в секунду возросло в 31 раз (250 против 8)!
Объясняется все это тем, что теперь запросы более не ждут в очереди на обработку, пока рабочие процессы заблокированы на чтении с диска, а обслуживаются свободными потоками. И пока дисковая подсистема делает свою работу как может, обслуживая наш “паразитный” трафик с первой машины, NGINX использует оставшиеся ресурсы процессора и пропускную способность сети, чтобы обслужить второго клиента из памяти.
Серебряной пули не существует
После всех страшилок про блокирующие операции и таких потрясающих результатов, многие из вас захотят скорее включит пулы потоков на своих серверах. Не спешите.
Правда в том, что, к счастью, в большинстве случаев операции с файлами не приводят к чтению с медленного жесткого диска. Если у вас хватает оперативной памяти, то современные операционные системы достаточно умны, чтобы закэшировать файлы, к которым часто происходит обращение в так называемом кэше страниц (page cache).
Кэш страниц справляется достаточно хорошо и это всегда позволяло NGINX демонстрировать высокую производительность в наиболее распространенных ситуациях. Чтения из кэша страниц происходят очень быстро и такую операцию нельзя назвать блокирующей. В то же время, взаимодействие с пулом потоков несет дополнительные издержки на синхронизацию.
Так что если у вас достаточно оперативной памяти и небольшой объем горячих данных, то у вас уже все хорошо и NGINX работает наиболее оптимальным образом без использования пулов потоков.
В действительности выгрузка операций чтения в отдельный пул потоков решает довольно узкий спектр задач. Он ограничен ситуациями, когда объем регулярно запрашиваемых данных не помещается в оперативной памяти, что делает кэш страниц операционной системы неэффективным. Таким примером может являться высоконагруженный сервис раздачи медиаданных. Данную ситуацию мы и симулировали в нашем тесте.
Выгрузку операций чтения в пулы потоков можно было бы сделать более универсальной для операций чтения и снизить задержки, если бы существовал эффективный способ узнать заранее, находятся ли необходимые данные в памяти или нет, и только в последнем случае выгружать операцию в отдельный поток.
Возвращаясь к аналогии с магазином и дальним складом, сейчас у продавца нет возможности узнать, что товар находится на витрине и он вынужден всегда работать посредством курьерской службы.
Дело в том, что отсутствует соответствующая поддержка со стороны ядра операционной системы. Первые попытки добавить такую возможность в Linux в виде системного вызова fincore() относятся к 2010 году, но «воз и ныне там». Позже были попытки в виде системного вызова
preadv2() и флага RWF_NONBLOCK (подробности можно узнать из статей Non-blocking buffered file read operations и Asynchronous buffered read operations на LWN.net) — но судьба и этих патчей по прежнему под вопросом. Печально, что виной всему этому похоже является пресловутый байкшединг (споры о том, какого цвета фломастеры лучше пахнут).В то время, как пользователям FreeBSD не о чем беспокоиться, у них есть неплохо работающий механизм асинхронного чтения, реализованный в ядре. Именно его и рекомендуется использовать вместо пулов потоков.
Конфигурация
Итак, если вы твердо уверены, что сможете извлечь выгоду из пула потоков для ваших задач, то непременно встает вопрос, как его включить и настроить.
Конфигурация достаточно простая и вместе с тем очень гибкая. Для начала вам потребуется NGINX версии 1.7.11 или выше, собранный с флагом
--with-threads. В простейшим случае настройка выглядит элементарно. Все, что необходимо для включения выгрузки операций чтения и отправки файлов в пул потоков, это директива aio на уровне http, server или location, установленная в значение threads:aio threads;
Это минимально возможный вариант настройки пулов потоков. На самом деле он является сокращенной версией такой конфигурации:
thread_pool default threads=32 max_queue=65536; aio threads=default;
Она задает пул потоков
default, в котором будут работать 32 потока и максимально допустимый размер очереди заданий составляет 65536. Если очередь заданий переполняется, то NGINX отклоняет запрос и логирует ошибку:thread pool "NAME" queue overflow: N tasks waiting
Такое возможно, если ваши потоки не справляются с объемом работы и очередь заполняется быстрее, чем обрабатывается. В этом случае вы можете попробовать увеличить максимальной размер очереди и если это не помогает, то значит ваша система просто не в состоянии обработать такое большое количество запросов.
Как можно заметить, с помощью директивы thread_pool у вас есть возможность задавать количество потоков, максимальный размер очереди, а также имя данного пула потоков. Последнее предполагает возможность сконфигурировать несколько независимых пулов и использовать их в разных частях конфигурации для разных задач:
thread_pool one threads=128 max_queue=0; thread_pool two threads=32; http { server { location /one { aio threads=one; } location /two { aio threads=two; } } … }
Если параметр
max_queue не указан явно, как в пуле two, то используется значение по умолчанию, равное 65536. Как видно из примера, можно задать нулевой размер очереди. Тогда пул сможет одновременно принимать в обработку только такое количество заданий, сколько у него имеется свободных потоков и не будет ожидающих в очереди заданий.А теперь представьте, что у вас есть сервер с тремя жесткими дисками, который должен выполнять роль кеширующего прокси для ваших бэкендов. При этом предполагаемый размер кэша многократно превосходит объем доступной оперативной памяти. По сути это что-то вроде кэш-ноды в вашей личной сети раздачи контента (CDN). В этом случае основная нагрузка по отдачи кэшированных данных будет ложиться на дисковую подсистему. Разумеется вы хотите извлечь максимум производительности из тех трех дисков, что имеются в наличии.
Одним из решений тут может стать организация RAID массива. У такого подхода конечно же есть свои плюсы и минусы. Но сегодня NGINX готов предложить вам другой подход:
# В нашей системе каждый из жестких дисков примонтирован в одну из следующих директорий: # /mnt/disk1, /mnt/disk2 или /mnt/disk3 соответственно thread_pool pool_1 threads=16; thread_pool pool_2 threads=16; thread_pool pool_3 threads=16; http { proxy_cache_path /mnt/disk1 levels=1:2 keys_zone=cache_1:256m max_size=1024G use_temp_path=off; proxy_cache_path /mnt/disk2 levels=1:2 keys_zone=cache_2:256m max_size=1024G use_temp_path=off; proxy_cache_path /mnt/disk3 levels=1:2 keys_zone=cache_3:256m max_size=1024G use_temp_path=off; split_clients $request_uri $disk { 33.3% 1; 33.3% 2; * 3; } server { … location / { proxy_pass http://backend; proxy_cache_key $request_uri; proxy_cache cache_$disk; aio threads=pool_$disk; sendfile on; } } }
В данной конфигурации используется три независимых кэша — по одному на каждый жесткий диск, и три независимых пула потоков, также по одному на диск.
Для равномерного распределения нагрузки между кэшами (а соответственно и жесткими дисками) используется модуль split_clients, который прекрасно для этого подходит.
Параметр
use_temp_path=off у директивы proxy_cache_path инструктирует NGINX сохранять временные файлы в той же директории, где находятся данные кэша. Это необходимо во избежание копирования данных с одного диска на другой при сохранении ответа в кэш.Все это вместе позволяет выжать максимум производительности из данной дисковой подсистемы, поскольку NGINX посредством отдельных пулов потоков взаимодействует с каждым диском параллельно и независимо. Каждый диск обслуживают 16 независимых потоков и для него формируется отдельная очередь заданий на чтение и отправку файлов.
Ведь ваши клиенты любят индивидуальных подход? Будьте уверены ваши жесткие диски тоже. ;)
Данный пример является демонстрацией огромной гибкости NGINX в конфигурировании непосредственно под ваше железо. Вы как бы инструктируете NGINX, каким образом лучше всего взаимодействовать с дисковой подсистемой на данном сервере и вашими данными. И такая тонкая настройка, когда программное обеспечение вплоть до пользовательского уровня работает с оборудованием самым оптимальным образом, обеспечивает наиболее эффективное использование всех ресурсов конкретной системы.
Выводы
Пулы потоков — это замечательный механизм, который борется с основным и хорошо известным врагом асинхронного подхода — блокирующими операциями, и тем самым позволяет вывести NGINX на новый уровень производительности, особенно если мы говорим об очень больших объемах данных.
Как уже упоминалось ранее, пулы потоков могут быть использованы и для любых других операций и работы с библиотеками, не имеющими асинхронного интерфейса. Потенциально это открывает новые возможности для реализации модулей и функциональности, реализация которой без ущерба для производительности ранее была неосуществимой в разумные сроки. Можно потратить много усилий и времени на написание асинхронного варианта имеющийся библиотеки или в попытках добавить такой интерфейс, но возникал вопрос: «стоит ли игра свеч»? С пулами потоков данную задачу можно решить гораздо проще, создавая модули, работающие с блокирующими вызовами, и при этом не мешая NGINX выполнять свою основную задачу обрабатывая остальные запросы.
Так что много нового и интересного ждет NGINX в будущем. Оставайтесь с нами!

