Зачастую, когда разработчики сталкиваются с созданием модели данных, тип первичного ключа выбирается «по привычке», и чаще всего это автоинкрементное целочисленное поле. Но в реальности это не всегда является оптимальным решением, так как для некоторых ситуаций более предпочтительным может оказаться GUID. На практике возможны и другие, более редкие, типы ключа, но в данной статье мы их рассматривать не будем.
Ниже приведены преимущества каждого из вариантов.
Автоинкремент
GUID
Фраза «теоретически, более быстрая генерация нового значения» звучит неубедительно. Подобные соображения всегда лучше подкреплять практическими примерами. Но прежде чем писать программу для тестирования, рассмотрим, какие варианты реализации первичного ключа есть с каждым из этих двух типов.
GUID можно генерировать как на клиенте, так и самой базой данных — уже два варианта. К тому же, в MS SQL есть две функции для получения уникального идентификатора — NEWID и NEWSEQUENTIALID. Давайте разберемся, в чем их отличие и может ли оно быть существенным на практике.
Привычная генерация уникальных идентификаторов в том же .NET через Guid.NewGuid() дает множество значений, не связанных друг с другом никакой закономерностью. Если ряд GUID-ов, полученных из этой функции, держать в отсортированном списке, то каждое новое добавляемое значение может «попадать» в любую его часть. Функция NEWID() в MS SQL работает аналогично — ряд ее значений весьма хаотичен. В свою очередь, NEWSEQUENTIALID() дает те же уникальные идентификаторы, только каждое новое значение этой функции больше предыдущего, при этом идентификатор остается «глобально уникальным».
Если использовать Entity Framework Code First, и объявить первичный ключ вот таким образом
в базе данных будет создана таблица с первичным кластерным ключом, который имеет значение по умолчанию NEWSEQUENTIALID(). Сделано это из соображений производительности. Опять же, в теории, вставлять новое значение в середину списка более накладно, чем добавление в конец. База данных, конечно же, не массив в памяти, и вставка новой записи в середину списка строк не приведет к физическому сдвигу всех последующих. Тем не менее, дополнительные накладные расходы будут — разделение страниц (page split). По итогу также будет сильная фрагментация индексов, которая может отразиться на производительности выборки данных. Неплохое объяснение того, как происходит вставка данных в кластеризованую таблицу, можно найти в ответах форума по этой ссылке.
Таким образом, для GUID мы имеем 4 варианта, которые стоит проанализировать в плане производительности: последовательный и непоследовательный GUID с генерацией на клиенте, и та же пара вариантов, но с генерацией на стороне базы. Остается вопрос, как получать последовательные GUID на клиенте? К сожалению, стандартной функции в .NET для этих целей нет, но ее можно сделать, воспользовавшись P/Invoke:
Обратите внимание на то, что без специальной перестановки байт, GUID нельзя отдавать. Идентификаторы получатся корректные, но с точки зрения SQL сервера — непоследовательные, поэтому никакого выигрыша по сравнению с «обычным» GUID даже теоретически не получится. К сожалению, ошибочный код приведен во многих источниках.
К списку остается добавить пятый вариант — автоинкрементный первичный ключ. Других вариантов у него нет, так как на клиенте его генерировать нормально не получится.
С вариантами определились, но есть еще один параметр, который следует учесть при написании теста — физический размер строк таблицы. Размер страницы данных в MS SQL — 8 килобайт. Записи близкого или даже большего размера могут показать более сильный разброс производительности для каждого из вариантов ключа, чем на порядок меньшие записи. Чтобы обеспечить возможность варьировать размер записи, достаточно добавить в каждую из тестовых таблиц NVARCHAR поле, которое затем заполнять нужным количеством символов (один символ в NVARCHAR поле занимает 2 байта).
По этой ссылке находится проект с программой, которая была разработана с учетом указанных выше соображений.
Ниже приведены результаты тестов, которые выполнялись по такой схеме:
И результаты с разбивкой по каждому запуску:
Из результатов сразу видно, что:
Над последним пунктом стоит задуматься. Из-за чего может происходить замедление работы при использовании непоследовательных GUID-ов, кроме как частого разделения страниц? Скорее всего — из-за частого чтения «случайных» страниц с диска. При использовании последовательного GUID, нужная страница всегда будет в памяти, так как добавление идет только в конец индекса. С непоследовательным будет много вставок в произвольные места индекса, и не во всех случаях нужные страницы будут находиться в памяти. Чтобы проверить, насколько такое случайное чтение влияет на результаты тестов, искусственно ограничим объем памяти SQL Server так, чтобы ни одна таблица не могла полностью уместиться в памяти.
Грубый расчет показывает, что в тесте с длиной строки 4000 символов (8000 байт) при количестве записей 50000 тысяч, размер таблицы будет не менее 400Мб. Ограничим допустимый объем памяти SQL Server до 256Мб и повторим этот тест.
Как и следовало ожидать, вставка в таблицы с непоследовательными GUID-ами в ключах заметно замедлилась, и замедление увеличивается с ростом количества строк в таблице. В то же время, производительность вставки для последовательных GUID-ов и автоинкремента остается стабильной.
Когда Entity Framework выполняет вставку в таблицу с автоинкрементным ключем, SQL команды выглядит примерно следующим образом:
В случае с GUID, сгенерированным на стороне сервера, получаем более сложный вариант:
Таким образом, чтобы клиент мог получить ключ только что добавленной строки, создается табличная переменная, в которую заносится значение ключа при вставке, а потом из этой табличной переменной идет выборка для возврата полученного значения на клиент.
Краткий тест показывает, что такой набор команд выполняется в среднем почти в три раза медленнее, чем просто INSERT на той же таблице. В случае автоинкремента не используется никаких дополнительных табличных переменных, поэтому и оверхед меньше.
Ниже приведены преимущества каждого из вариантов.
Автоинкремент
- Занимает меньший объем
- Теоретически, более быстрая генерация нового значения
- Более быстрая десериализация
- Проще оперировать при отладке, поддержке, так как число гораздо легче запомнить
GUID
- При репликации между несколькими экземплярами базы, где добавление новых записей происходит более, чем в одну реплику, GUID гарантирует отсутствие коллизий
- Позволяет генерировать идентификатор записи на клиенте, до сохранения ее в базу
- Обобщение первого пункта — обеспечивает уникальность идентификаторов не только в пределах одной таблицы, что для некоторых решений может быть важно
- Делает практически невозможным «угадывание» ключа в случаях, когда запись можно получить, передав ее идентификатор в какой-нибудь публичный API
Фраза «теоретически, более быстрая генерация нового значения» звучит неубедительно. Подобные соображения всегда лучше подкреплять практическими примерами. Но прежде чем писать программу для тестирования, рассмотрим, какие варианты реализации первичного ключа есть с каждым из этих двух типов.
GUID можно генерировать как на клиенте, так и самой базой данных — уже два варианта. К тому же, в MS SQL есть две функции для получения уникального идентификатора — NEWID и NEWSEQUENTIALID. Давайте разберемся, в чем их отличие и может ли оно быть существенным на практике.
Привычная генерация уникальных идентификаторов в том же .NET через Guid.NewGuid() дает множество значений, не связанных друг с другом никакой закономерностью. Если ряд GUID-ов, полученных из этой функции, держать в отсортированном списке, то каждое новое добавляемое значение может «попадать» в любую его часть. Функция NEWID() в MS SQL работает аналогично — ряд ее значений весьма хаотичен. В свою очередь, NEWSEQUENTIALID() дает те же уникальные идентификаторы, только каждое новое значение этой функции больше предыдущего, при этом идентификатор остается «глобально уникальным».
Если использовать Entity Framework Code First, и объявить первичный ключ вот таким образом
[Key, DatabaseGenerated(DatabaseGeneratedOption.Identity)] public Guid Id { get; set; }
в базе данных будет создана таблица с первичным кластерным ключом, который имеет значение по умолчанию NEWSEQUENTIALID(). Сделано это из соображений производительности. Опять же, в теории, вставлять новое значение в середину списка более накладно, чем добавление в конец. База данных, конечно же, не массив в памяти, и вставка новой записи в середину списка строк не приведет к физическому сдвигу всех последующих. Тем не менее, дополнительные накладные расходы будут — разделение страниц (page split). По итогу также будет сильная фрагментация индексов, которая может отразиться на производительности выборки данных. Неплохое объяснение того, как происходит вставка данных в кластеризованую таблицу, можно найти в ответах форума по этой ссылке.
Таким образом, для GUID мы имеем 4 варианта, которые стоит проанализировать в плане производительности: последовательный и непоследовательный GUID с генерацией на клиенте, и та же пара вариантов, но с генерацией на стороне базы. Остается вопрос, как получать последовательные GUID на клиенте? К сожалению, стандартной функции в .NET для этих целей нет, но ее можно сделать, воспользовавшись P/Invoke:
internal static class SequentialGuidUtils { public static Guid CreateGuid() { Guid guid; int result = NativeMethods.UuidCreateSequential(out guid); if (result == 0) { var bytes = guid.ToByteArray(); var indexes = new int[] { 3, 2, 1, 0, 5, 4, 7, 6, 8, 9, 10, 11, 12, 13, 14, 15 }; return new Guid(indexes.Select(i => bytes[i]).ToArray()); } else throw new Exception("Error generating sequential GUID"); } } internal static class NativeMethods { [DllImport("rpcrt4.dll", SetLastError = true)] public static extern int UuidCreateSequential(out Guid guid); }
Обратите внимание на то, что без специальной перестановки байт, GUID нельзя отдавать. Идентификаторы получатся корректные, но с точки зрения SQL сервера — непоследовательные, поэтому никакого выигрыша по сравнению с «обычным» GUID даже теоретически не получится. К сожалению, ошибочный код приведен во многих источниках.
К списку остается добавить пятый вариант — автоинкрементный первичный ключ. Других вариантов у него нет, так как на клиенте его генерировать нормально не получится.
С вариантами определились, но есть еще один параметр, который следует учесть при написании теста — физический размер строк таблицы. Размер страницы данных в MS SQL — 8 килобайт. Записи близкого или даже большего размера могут показать более сильный разброс производительности для каждого из вариантов ключа, чем на порядок меньшие записи. Чтобы обеспечить возможность варьировать размер записи, достаточно добавить в каждую из тестовых таблиц NVARCHAR поле, которое затем заполнять нужным количеством символов (один символ в NVARCHAR поле занимает 2 байта).
Тестирование
По этой ссылке находится проект с программой, которая была разработана с учетом указанных выше соображений.
Ниже приведены результаты тестов, которые выполнялись по такой схеме:
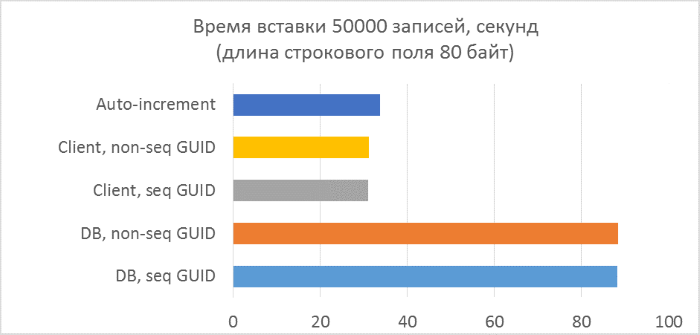
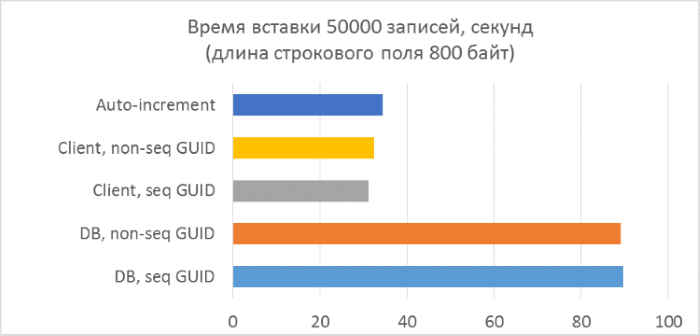
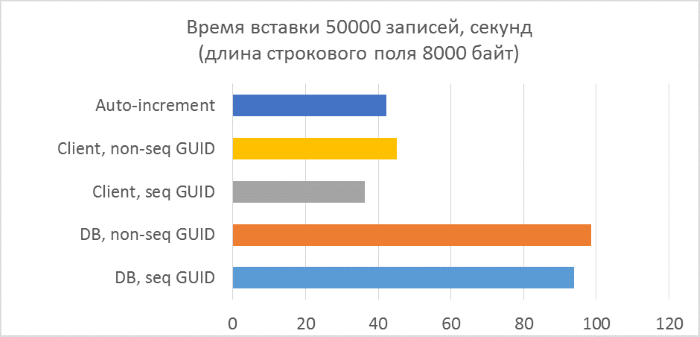
- Всего три серии тестов с длиной текстового поля в записи 80, 800 и 8000 байт соответственно (количество символов в тестовой программе будет в два раза меньше в каждом из случаев, так как один символ в NVARCHAR занимает два байта).
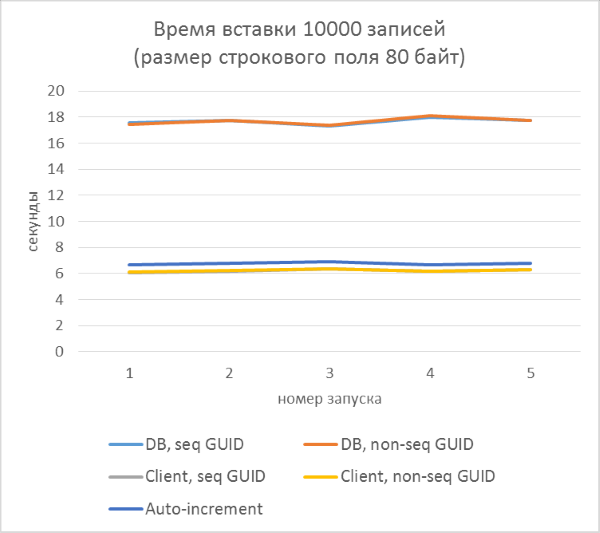
- В каждой из серий — по 5 запусков, каждый из которых добавляет по 10000 записей в каждую из таблиц. По результатам каждого из запусков можно будет проследить зависимость времени вставки от количества строк, уже находящихся в таблице.
- Перед началом каждой из серий таблицы полностью очищаются.
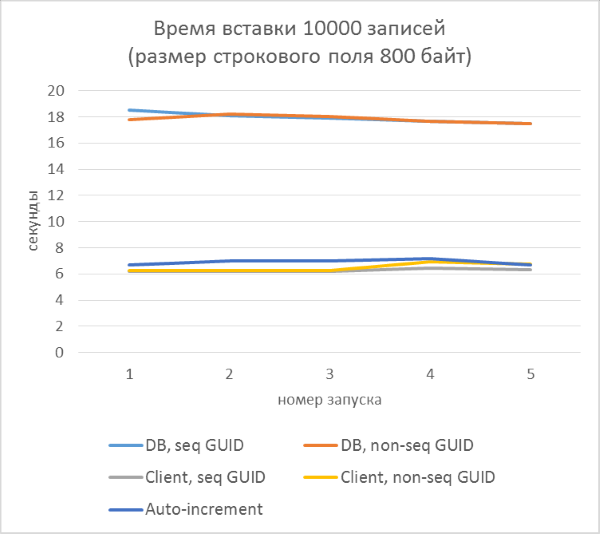
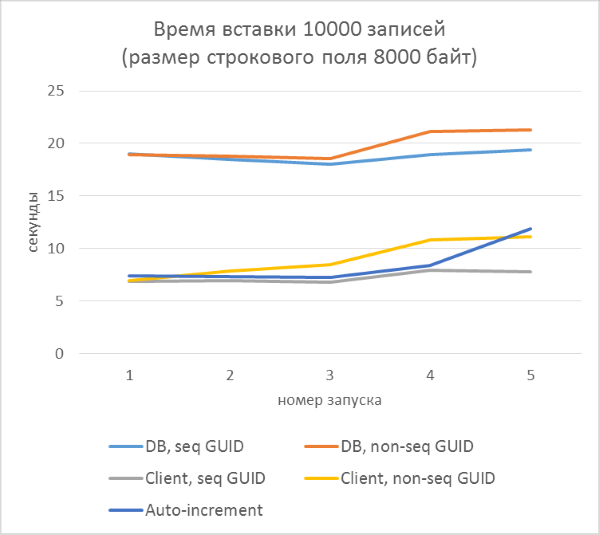
И результаты с разбивкой по каждому запуску:
Из результатов сразу видно, что:
- Использование генерации GUID на стороне базы данных в разы медленнее, чем генерации на стороне клиента. Это связано с затратами на чтение только что добавленного идентификатора. Детали этой проблемы рассмотрены в конце статьи.
- Вставка записей с автоинкрементным ключом даже немного медленнее, чем с GUID-ом, присвоенным на клиенте.
- Разницы между последовательным и непоследовательным GUID практически не видно на небольших записях. На больших записях разница появляется с ростом количества строк в таблице, но она не выглядит существенной.
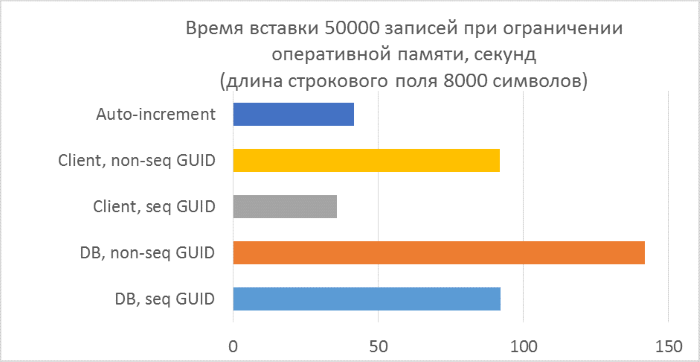
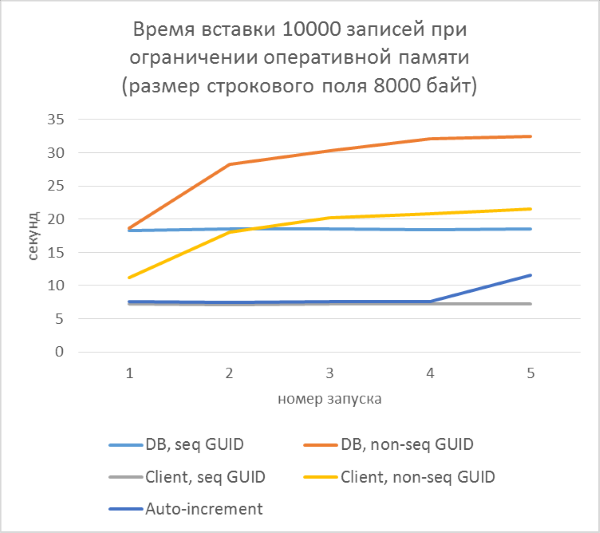
Над последним пунктом стоит задуматься. Из-за чего может происходить замедление работы при использовании непоследовательных GUID-ов, кроме как частого разделения страниц? Скорее всего — из-за частого чтения «случайных» страниц с диска. При использовании последовательного GUID, нужная страница всегда будет в памяти, так как добавление идет только в конец индекса. С непоследовательным будет много вставок в произвольные места индекса, и не во всех случаях нужные страницы будут находиться в памяти. Чтобы проверить, насколько такое случайное чтение влияет на результаты тестов, искусственно ограничим объем памяти SQL Server так, чтобы ни одна таблица не могла полностью уместиться в памяти.
Грубый расчет показывает, что в тесте с длиной строки 4000 символов (8000 байт) при количестве записей 50000 тысяч, размер таблицы будет не менее 400Мб. Ограничим допустимый объем памяти SQL Server до 256Мб и повторим этот тест.
Как и следовало ожидать, вставка в таблицы с непоследовательными GUID-ами в ключах заметно замедлилась, и замедление увеличивается с ростом количества строк в таблице. В то же время, производительность вставки для последовательных GUID-ов и автоинкремента остается стабильной.
Выводы
- Если по каким-либо критериям, указанным в начале статьи, возникла надобность использовать GUID в качестве первичного ключа — наилучшим вариантом в плане производительности будет последовательный GUID, сгенерированный для каждой записи на клиенте.
- Если создание GUID на клиенте по каким-либо причинам неприемлемо — можно воспользоваться генерацией идентификатора на стороне базы через NEWSEQUENTIALID(). Entity Framework делает это по умолчанию для GUID ключей, генерируемых на стороне базы. Но следует учесть, что производительность вставки будет заметно меньше по сравнению с созданием идентификатора на стороне клиента. Для проектов, где количество вставок в таблицы невелико, эта разница не будет критична. Еще, скорее всего, этот оверхед можно избежать в сценариях, где не нужно сразу же получать идентификатор вставленной записи, но такое решение не будет универсальным.
- Если в вашем проекте уже используются непоследовательные GUID, то следует задуматься об исправлении, если количество вставок в таблицы велико и размер базы значительно больше, чем размер доступной оперативной памяти.
- У других СУБД разница в производительности может быть совершенно другой, поэтому полученные результаты можно рассматривать только применительно к Microsoft SQL Server. В то время как базовые критерии, указанные в начале статьи, справедливы независимо от конкретной СУБД.
UPD: Почему вариант с генерацией GUID ключа на стороне базы работает медленно
Когда Entity Framework выполняет вставку в таблицу с автоинкрементным ключем, SQL команды выглядит примерно следующим образом:
INSERT [dbo].[AutoIncrementIntKeyEntities]([Name], [Count]) VALUES (@0, @1) SELECT [Id] FROM [dbo].[AutoIncrementIntKeyEntities] WHERE @@ROWCOUNT > 0 AND [Id] = scope_identity()
В случае с GUID, сгенерированным на стороне сервера, получаем более сложный вариант:
DECLARE @generated_keys table([Id] uniqueidentifier) INSERT [dbo].[GuidKeyDbNonSequentialEntities]([Name], [Count]) OUTPUT inserted.[Id] INTO @generated_keys VALUES (@name, @count) SELECT t.[Id] FROM @generated_keys AS g JOIN [dbo].[GuidKeyDbNonSequentialEntities] AS t ON g.[Id] = t.[Id] WHERE @@ROWCOUNT > 0
Таким образом, чтобы клиент мог получить ключ только что добавленной строки, создается табличная переменная, в которую заносится значение ключа при вставке, а потом из этой табличной переменной идет выборка для возврата полученного значения на клиент.
Краткий тест показывает, что такой набор команд выполняется в среднем почти в три раза медленнее, чем просто INSERT на той же таблице. В случае автоинкремента не используется никаких дополнительных табличных переменных, поэтому и оверхед меньше.

