Три переезда равно одному пожару. Выгребая старый ящик, пропахший ацетоном, с многослойной пылью на донышке (как хорошо, что жена не видела) я наткнулся на до боли знакомые мне компакт диски. Вот один из любимых фильмов детства… а вот моя когда-то любимая аркадная игрушка…
Странная вещь — любопытство. Вот на столе экземпляр CD — безнадёжно устаревшего в наш просвященный XXI век формата хранения данных; а все таки интересно, как же там хранятся данные?.. Каков сам стек хранения данных?.. Как исправляются ошибки?.. Какова избыточность кода?..
В детстве мне было достаточно знаний о лазерном луче, о какой-то головке, об «этой крутящийся штуки» и о таинственных питах.
Сказано — сделано. Проглядев стандарт ECMA-130 (есть, кстати и отечественный стандарт: ГОСТ 27667-88) обнаружил массу любопытных деталей. Например, я догадывался об избыточности, но я и подумать не мог, что для записи 700 Мб данных «в реальности» записывается 1943 Мб (То есть в 2.776 раз больше)…
Схематично весь стек можно представить картинкой:

Стек рассмотрим «сверху вниз».
То есть от момента передачи данных приводу до записи самих питов.
Следует сказать, что не вся область диска используется для записи/хранения/чтения информации.
Компакт диск разделен на зоны (areas):
Именно зона информации нам и интересна, поэтому о ней скажем более подробно. Information area разделяется на следующие «подзоны»:
Все три перевода сделаны ГОСТом… Так что от себя переводить не буду. При чем здесь «программа», когда речь идет о данных — ума приложить не могу. Если кто-то на Хабре сможет мне ответить, почему user data zone перевели как «зона программы» я буду крайне признателен!
Уф… С физическим ликбезом, надеюсь, покончили. Разумеется, я упустил многие моменты, связанные с ширинами и длинами; с методом покрытия; длиной волны луча; и прочими физическими свойствами. Однако, во-первых это не является целью данной статьи; во-вторых я и сам больше половины информации пока не разобрал. Да и нет желания, если честно… Мое любопытство чисто «программистской» направленности ;)
Первая фаза — это разбиение на «информационные дорожки». Уже тут есть два варианта записи, в цифровом виде (Digital Data Tracks, DDT) и аудиоданные (Audio Tracks).
В дальнейшем будем рассматривать только цифровые данные. Вся нижеследующая информация корректна только для DDT.
Данные разбиваются по 8 бит (по одному байту) и группируются в секторы.
Забавно, что количество секторов в диске не определено стандартом. Оно зависит от того, сколько данных «получиться» записать на диск…
Это кажется немного нелепым. Тем не менее эту нелепость в свою эпоху использовали различные компании по обнаружению контрафактных дисков. (Так как это «уход в сторону», то написал подробнее под спойлером чуть ниже, в конце главы.)
Разумеется, длина дорожки более-менее фиксирована и в целом QoS гарантировать можно.
Существует три способа (mode) записи данных в секторах:
Приведем картинки:
Полезная информация (User Mode) состоит из 2048 байт в режиме 01; или 2336 байт в режиме 02.
Какой режим выбрать? Все зависит от того, какое требование надежности вам требуется.
Sector Mode 01 надежнее, так как в нем используются дополнительно EDC проверка и P-Q кодирование.
Error Detection Code (EDC), как понятно по названию, предназначен только для обнаружения, но не для исправления ошибок.
Вот его полином: P(x)=(x16+x15+x2+1)(x16+x2+x+1)
Восемь байт поля Intermediate заполняются нулевыми байтами (0x00).
Вот уж не знаю зачем их оставили… Может «про запас» (в IT стандартах это любят),а может это коварный план стеганографической передачи данных.
Reed-Solomon Product-like Code (RSPC), оно же P+Q кодирование используется с 12 по 2075 байт данных в режиме 01. Подробности опущу, вы можете прочесть их в Annex A стандарта ECMA-130.
Байты с 12 по 2075 и проверочные с 2 076 по 2 351 составляют 2340 байт данных. Эти данные разбиваются на два блока по 1170 байт каждый. Разбиение происходит как в школьных уроках физкультуры. "На перррвый- вторрррой рассчитась!". То есть на нечетные и четные байты.
Дальше идет кодирование внешним и внутренними кодами. Внешний называется P-кодированием, внутренний Q-кодированием.
Самая сложная в понимании стека ECMA-130 пройдена. Теперь будет значительно проще.
Переходим к скремблированию. Вот так выглядит один сектор скремблирования:

Каждый такой сектор называют Scrambled Sector.
Каждый Scrambled Sector разбивается на frame'ы, длиной по 24 байта каждый.
Данные frame'ы имеют название: F1 frame.
Каждый Scrambled Sector у нас состоит из 2352 байт.
Соответственно каждый сектор разбивается на 98 frame'ов.
Cross Interleaved Reed-Solomon (CIRC) кодирование осуществляется для каждого F1 frame'а.
Это код, корректирующий ошибки с длиной входного слова в 24 байта, а длиной выходного слова в 32 байта.
Причем в отличие от EDC и RSPC кодирования, CIRC кодирование применяется для всех Sector Mode.
Полученную последовательность из 32 байт называют F2 frame'ами.
В начало каждого F2 frame'а добавляют один проверочный байт и получается F3 frame с длиной в 33 байта (32+1=33).
На этой стадии данные каждый байт (8 бит) преобразуется в 14 бит данных. Преобразование осуществляется по таблице.
Всю таблицу приводить не буду, вы можете найти её в Annex D стандарта ECMA-130.
Зачем необходимо 8-to-14 кодирование в стандарте не указано. (Стандарт и не обязан отвечать на вопросы ПОЧЕМУ, в стандарте должны быть ответы на вопросы КАКИМ ОБРАЗОМ)…
У меня есть одна гипотеза. Дело в том, что реальный мир не настолько «идеален», каким его видят программисты. Например, нарисованная точка — это маленькая «клякса», а нарисованная линия всегда имеет площадь; в противном случае наши бы глаза не видели бы точку и линию… По этой причине рискну высказать ряд предположений. Подчеркну, что я никогда не работал профессионально с изготовлением CD дисков. Это всего лишь предположения. (Дискуссия в коментариях категорически приветствуется!).
Гипотезы.
Посмотрим, насколько протокол CD избыточен:
Перемножая все, получаем: 1.148 ⋅ 1.005 ⋅ 1.375 ⋅ 1.750 = 2.776. Таким образом на сам диск в итоге записывается в 2.776 раз больше информации, чем «полезная информация».
Например при объеме «полезной информации» в 700Мб, реально на диск записывается 1943 Мб данных.
Для Sector Mode 02 не используется P-Q кодирование. Для этого режима избыточность равна: 1.007 ⋅ 1.005 ⋅ 1.375 ⋅ 1.750 = 2.435.
Есть стандарт SCSI Multimedia Commands. В нем дано описание команд «сырого» чтения данных. Команды READ CD и WRITE CD позволяют считывать 2352 байт данных со всего сектора. Однако команд для считывания F-fraim'ов я не нашел… В принципе если записывать избыточную информацию, для которой не страшны частичные потери (например видео, телематика)
можно обойтись без F1-F2-F3 фреймов увеличив «полезную нагрузку» в 1.375 раз.
Так же есть ряд неиспользуемых областей в компакт диске (например тот же Intermidiate), которыми так же можно воспользоваться. Например ради задач стеганографии.
К сожалению я не нашел OpenSource кода, реализующий данные возможности…
Если на хабре есть спецы по данному вопросу, буду рад получить ссылочку (с меня плюс в карму).
Странная вещь — любопытство. Вот на столе экземпляр CD — безнадёжно устаревшего в наш просвященный XXI век формата хранения данных; а все таки интересно, как же там хранятся данные?.. Каков сам стек хранения данных?.. Как исправляются ошибки?.. Какова избыточность кода?..
В детстве мне было достаточно знаний о лазерном луче, о какой-то головке, об «этой крутящийся штуки» и о таинственных питах.
Сказано — сделано. Проглядев стандарт ECMA-130 (есть, кстати и отечественный стандарт: ГОСТ 27667-88) обнаружил массу любопытных деталей. Например, я догадывался об избыточности, но я и подумать не мог, что для записи 700 Мб данных «в реальности» записывается 1943 Мб (То есть в 2.776 раз больше)…
Схематично весь стек можно представить картинкой:
Стек рассмотрим «сверху вниз».
То есть от момента передачи данных приводу до записи самих питов.
Следует сказать, что не вся область диска используется для записи/хранения/чтения информации.
Компакт диск разделен на зоны (areas):
- Centre Hole (Центральное отверстие ) — это «та самая дырочка» диаметром 15 мм (±0.1 мм), за которую прикрепляется сам диск.
- First transition area (Первая переходная зона) — «кольцо», между 15 и 20 мм от центра диска.
- Сlamping area (Зона зажима) — как понятно из названия это область необходима, чтобы диск «не скакал» при чтении / записи. (26-33 мм)
- Second transition area (Вторая переходная зона) — «второе кольцо», между 33 и 44 мм от центра диска.
- Information area (Зона информации) — это «информационно полезная» часть компакт диска. Находится на расстоянии от 44 мм до 118 мм от центра.
- Rim area (обод) — последняя область. Представляет собой кольцо от 118 мм до 120 мм от центра.
Именно зона информации нам и интересна, поэтому о ней скажем более подробно. Information area разделяется на следующие «подзоны»:
- inner buffer zone (зона ввода)
- user data zone (зона программы)
- outer buffer zone (зона вывода)
Все три перевода сделаны ГОСТом… Так что от себя переводить не буду. При чем здесь «программа», когда речь идет о данных — ума приложить не могу. Если кто-то на Хабре сможет мне ответить, почему user data zone перевели как «зона программы» я буду крайне признателен!
Уф… С физическим ликбезом, надеюсь, покончили. Разумеется, я упустил многие моменты, связанные с ширинами и длинами; с методом покрытия; длиной волны луча; и прочими физическими свойствами. Однако, во-первых это не является целью данной статьи; во-вторых я и сам больше половины информации пока не разобрал. Да и нет желания, если честно… Мое любопытство чисто «программистской» направленности ;)
Information Tracks («Информационные дорожки»)
Первая фаза — это разбиение на «информационные дорожки». Уже тут есть два варианта записи, в цифровом виде (Digital Data Tracks, DDT) и аудиоданные (Audio Tracks).
В дальнейшем будем рассматривать только цифровые данные. Вся нижеследующая информация корректна только для DDT.
Sector (Сектор)
Данные разбиваются по 8 бит (по одному байту) и группируются в секторы.
Забавно, что количество секторов в диске не определено стандартом. Оно зависит от того, сколько данных «получиться» записать на диск…
Это кажется немного нелепым. Тем не менее эту нелепость в свою эпоху использовали различные компании по обнаружению контрафактных дисков. (Так как это «уход в сторону», то написал подробнее под спойлером чуть ниже, в конце главы.)
Разумеется, длина дорожки более-менее фиксирована и в целом QoS гарантировать можно.
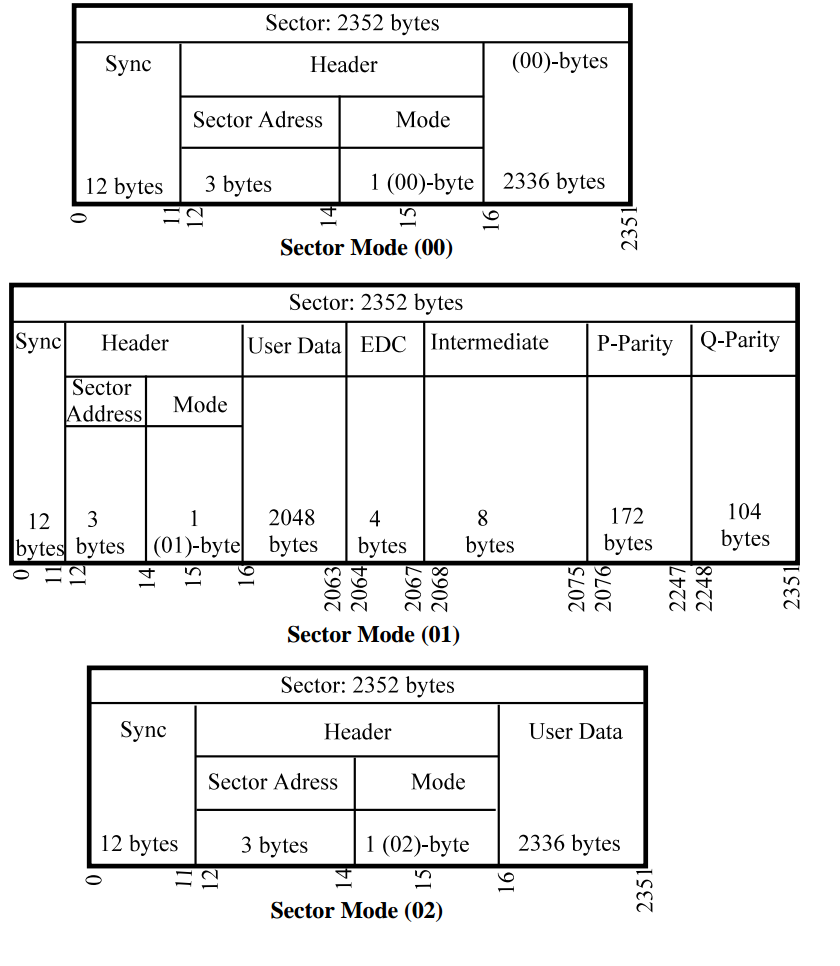
Существует три способа (mode) записи данных в секторах:
- Sector Mode (00) — это пустой сектор, заполняемый данными, состоящие из 0x00 байтов.
- Sector Mode (01) — использование EDC, P-Q и CIRC кодирование. (об этом чуть ниже)
- Sector Mode (02) — отсутствие P и Q кодирования, только CIRC кодирование
Приведем картинки:
Метод определения контрафактного диска
Метод, как и все гениальное, прост.
Запись лицензионного ключа.
Процедура проверки лицензионного ключа.
Запись лицензионного ключа.
- Следует сначала записать всю необходимую информацию на диск.
- Затем мы выбраем 2 сектора. Например 103123 и 120234 сектора. Обозначим эти сектора как A и Б.
- Выбираем два байта: по одному байту на каждом секторе. Например 4й байт первого сектора и 8й байт второго
- Затем следует подсчитать угол между этими байтами на секторе. Как это сделать? Предположим, у вас есть доступ к низкоуровневому драйверу чтения и вы знаете время одного оборота.Тогда следует вычислить время, потраченное на считывание между А и Б. Поделив это время на время одного оборота можно с определенной погрешностью вычислить угол.
- Зачение угла, округленное до определенного знака, подается на вход хеш-функции. У хеш-значения берутся несколько символов, например последние 3 символа.
- Эти три символа записываются в лицензионный ключ.
Процедура проверки лицензионного ключа.
- У пользователя просят ввести лицензионный ключ.
- Вычисляем угол между выбранными байтами A и Б секторами
- Вычисляем проверяемый список углов. Например мы вычислили угол 33,343°. Предположим, что округление происходит с точностью до градуса. Округляем и получаем 33°. Предположим, что погрешность ±2°. Список углов: [31°, 32°, 33°, 34°, 35°].
- Для каждого угла из списка вычисляем хеш. Берем несколько символов из хеша. Для примера — последние 3 символа
Если хотя бы один хеш из списка совпал с хешем из лицензионного ключа, то делаем вывод, что диск лицензионный. Иначе диск контрафактный
Коррекция ошибок (только Sector Mode 01)
Полезная информация (User Mode) состоит из 2048 байт в режиме 01; или 2336 байт в режиме 02.
Какой режим выбрать? Все зависит от того, какое требование надежности вам требуется.
Sector Mode 01 надежнее, так как в нем используются дополнительно EDC проверка и P-Q кодирование.
EDC
Error Detection Code (EDC), как понятно по названию, предназначен только для обнаружения, но не для исправления ошибок.
Вот его полином: P(x)=(x16+x15+x2+1)(x16+x2+x+1)
Intermediate
Восемь байт поля Intermediate заполняются нулевыми байтами (0x00).
Вот уж не знаю зачем их оставили… Может «про запас» (в IT стандартах это любят),
P и Q кодирование (RSPC)
Reed-Solomon Product-like Code (RSPC), оно же P+Q кодирование используется с 12 по 2075 байт данных в режиме 01. Подробности опущу, вы можете прочесть их в Annex A стандарта ECMA-130.
Байты с 12 по 2075 и проверочные с 2 076 по 2 351 составляют 2340 байт данных. Эти данные разбиваются на два блока по 1170 байт каждый. Разбиение происходит как в школьных уроках физкультуры. "На перррвый- вторрррой рассчитась!". То есть на нечетные и четные байты.
Дальше идет кодирование внешним и внутренними кодами. Внешний называется P-кодированием, внутренний Q-кодированием.
Картинка с P и Q кодированием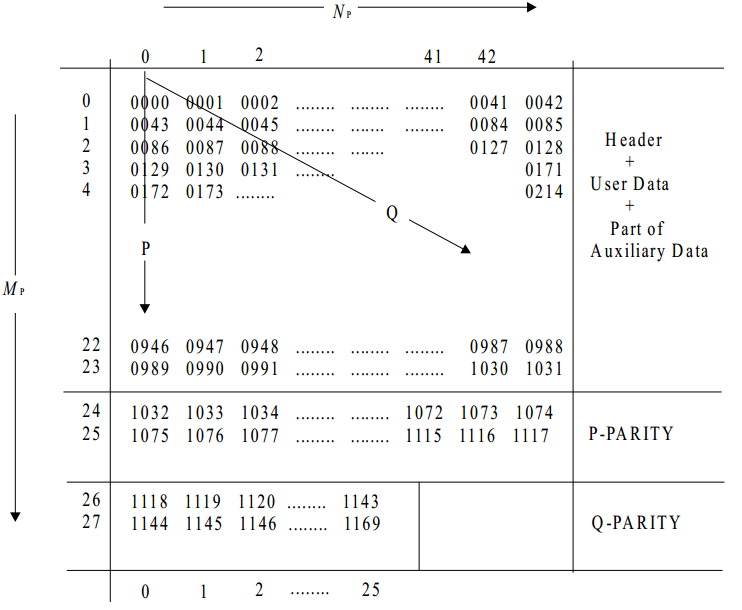
Для большего понимания: картинка только с Q кодированием
Самая сложная в понимании стека ECMA-130 пройдена. Теперь будет значительно проще.
Скремблирование
Переходим к скремблированию. Вот так выглядит один сектор скремблирования:
Каждый такой сектор называют Scrambled Sector.
А что такое ''скремблирование'' и зачем это нужно?
О смысле скремблирования кратко и емко в комментарии к одному из моих постов написал snapdragon
Скремблер нужен для того, чтобы сделать спектр сигнала равномерным. Иначе, при однородных данных (например, много повторяющихся единиц или нулей) энергия сигнала будет сосредоточена в узком диапазоне.
F1, F2 и F3 frame'ы
Каждый Scrambled Sector разбивается на frame'ы, длиной по 24 байта каждый.
Данные frame'ы имеют название: F1 frame.
Каждый Scrambled Sector у нас состоит из 2352 байт.
Соответственно каждый сектор разбивается на 98 frame'ов.
CIRC кодирование (F2 frame)
Cross Interleaved Reed-Solomon (CIRC) кодирование осуществляется для каждого F1 frame'а.
Это код, корректирующий ошибки с длиной входного слова в 24 байта, а длиной выходного слова в 32 байта.
Причем в отличие от EDC и RSPC кодирования, CIRC кодирование применяется для всех Sector Mode.
Полученную последовательность из 32 байт называют F2 frame'ами.
Контрольный байт
В начало каждого F2 frame'а добавляют один проверочный байт и получается F3 frame с длиной в 33 байта (32+1=33).
8-to-14 кодирование
На этой стадии данные каждый байт (8 бит) преобразуется в 14 бит данных. Преобразование осуществляется по таблице.
Всю таблицу приводить не буду, вы можете найти её в Annex D стандарта ECMA-130.
... ... 00010000 10000000100000 00010001 10000010000000 00010010 10010010000000 00010011 00100000100000 00010100 01000010000000 00010101 00000010000000 00010110 00010010000000 ... ...
Зачем необходимо 8-to-14 кодирование в стандарте не указано. (Стандарт и не обязан отвечать на вопросы ПОЧЕМУ, в стандарте должны быть ответы на вопросы КАКИМ ОБРАЗОМ)…
У меня есть одна гипотеза. Дело в том, что реальный мир не настолько «идеален», каким его видят программисты. Например, нарисованная точка — это маленькая «клякса», а нарисованная линия всегда имеет площадь; в противном случае наши бы глаза не видели бы точку и линию… По этой причине рискну высказать ряд предположений. Подчеркну, что я никогда не работал профессионально с изготовлением CD дисков. Это всего лишь предположения. (Дискуссия в коментариях категорически приветствуется!).
Гипотезы.
- Пит не «идеально» выжигается на поверхности диска, поэтому необходимо некое пространство рядом с питом, т.к. за это пространство выжженный пит может «заскочить».
- Скорее всего, есть определенные проблемы с синхронизацией самой головки.Слишком большое количество подряд идущих нулей — это плохо.
- Возможно большое количество единиц это дополнительная «нагрузка» на считывающую головку. Поэтому их уменьшение позволит существенно увеличить срок эксплуатации CD привода. В среднем на 8 бит данных мы имеети 4 единицы. В 8-to-14 кодировании в кодовом слове у нас 1 или 2 единицы. То есть в два раза меньше.
Подсчитываем избыточность
Посмотрим, насколько протокол CD избыточен:
- В зависимости от Sector Mode:
- Sector Mode 01 (P-Q кодирование) — На входе блок из 2048 байт, на выходе 2352. Следовательно избыточность равна: 2352/2048=1.148
- Sector Mode 02 (без P-Q кодирования) — 2352/2336=1.007
- Скремблирование — мелочь, но для порядка учтем: (12+2340)/2340=1.005
- F1-F2-F3 фреймы — 33/24=1.375
- 8-to-14 кодирование — 14/8=1.750
Перемножая все, получаем: 1.148 ⋅ 1.005 ⋅ 1.375 ⋅ 1.750 = 2.776. Таким образом на сам диск в итоге записывается в 2.776 раз больше информации, чем «полезная информация».
Например при объеме «полезной информации» в 700Мб, реально на диск записывается 1943 Мб данных.
Для Sector Mode 02 не используется P-Q кодирование. Для этого режима избыточность равна: 1.007 ⋅ 1.005 ⋅ 1.375 ⋅ 1.750 = 2.435.
Бонус: SCSI Multimedia Commands
Есть стандарт SCSI Multimedia Commands. В нем дано описание команд «сырого» чтения данных. Команды READ CD и WRITE CD позволяют считывать 2352 байт данных со всего сектора. Однако команд для считывания F-fraim'ов я не нашел… В принципе если записывать избыточную информацию, для которой не страшны частичные потери (например видео, телематика)
можно обойтись без F1-F2-F3 фреймов увеличив «полезную нагрузку» в 1.375 раз.
Так же есть ряд неиспользуемых областей в компакт диске (например тот же Intermidiate), которыми так же можно воспользоваться. Например ради задач стеганографии.
К сожалению я не нашел OpenSource кода, реализующий данные возможности…
Если на хабре есть спецы по данному вопросу, буду рад получить ссылочку (с меня плюс в карму).

