Как определить чиновников, наиболее подозрительных с точки зрения коррупции? Проще всего — сравнив их доходы и уровень жизни.
В этой статье я хочу показать возможности сайтов с открытой информацией о чиновниках, посмотреть на то, как эти чиновники живут и попытаться определить тех, кто наиболее подозрителен с точки зрения коррупции.
Почему открытая информация о доходах чиновников важна? Потому что это позволяет их контролировать.

Фото из инстаграмма дочери бывшего руководителя ГАИ Украины Александра Ершова. На фото дочь Ершова в Каннах рядом с Пэрис Хилтон. В результате скандала из-за несоответствия задекларированных доходов и образа жизни семьи Ершов подал в отставку.
Данные по декларациям чиновников взяты с сайта declarations.com.ua, а о владельцах элитной недвижимости — с сайта garnahata.in.ua. Оба сайта — проекты сообщества журналистов и волонтеров «Канцелярская сотня», изначально организованного для оцифровки документов из дома Януковича.
На данный момент на сайтах доступно около 11 тысяч деклараций чиновников из разных ведомств и около 9 тысяч записей о владельцах элитной недвижимости. Среди декларантов в основном представители разных министерств (включая службы на местах), работники судов и прокуратуры. Данные не претендуют на репрезентативность (чиновников в Украине около 400 тысяч), но покопаться в них все равно интересно.
У обоих сайтов есть открытый API, данные в формате JSON можно скачать с помощью скрипта на python. Схема объекта данных для деклараций есть на github тут, а схему объекта для данных о владельцах элитной недвижимости — тут. Для примера и понимания структуры данных — скан-копия одной из деклараций сайта.
Загрузив данные, я распарсила их в R, агрегировала некоторые и оставила только декларации за 2013 и 2014 годы.
Начнем с самого очевидного и простого — дохода.
Декларанты указывают свой доход и доход членов семьи. Для начала посмотрим на доход в расчете на одного члена семьи.
Беглый взгляд на 10%-процентили показывает, что в верхних 10% есть какие-то супер-богачи: средний доход для верхних 10% — 305,8 млн.грн. на члена семьи (около 12 млн.долларов), при этом на 90%-м процентиле значение всего 382 тыс.грн.

В разрезе ведомств:
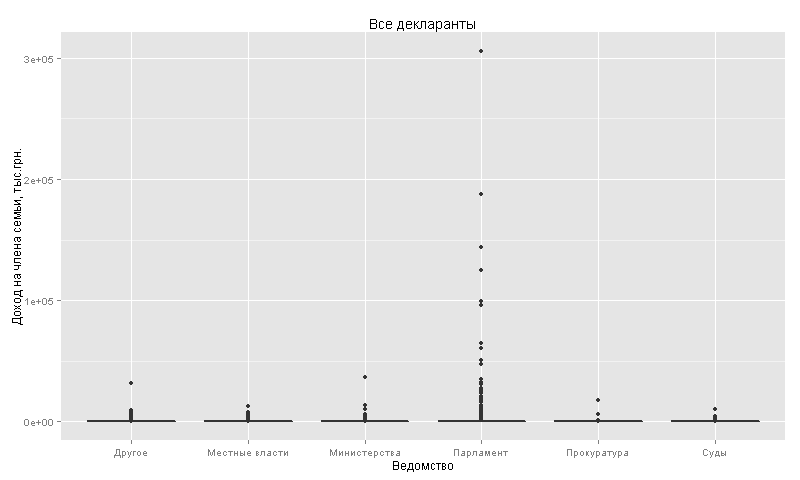
Внезапно парламент. По всем остальным ведомствам доход на члена семьи не превышает 50 млн.грн. в год. Отсеем аутлаеров с очень высоким доходом и посмотрим на чиновников с доходом до 1 млн.грн. на члена семьи в год (таких 97%):
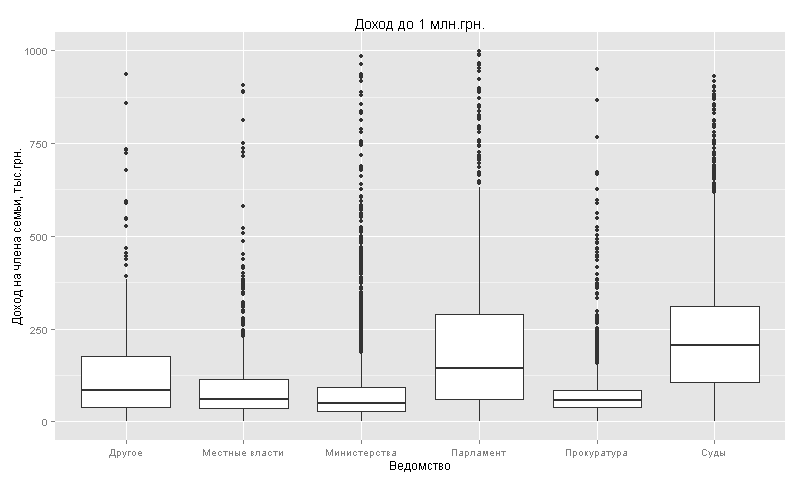
Видно, что средний доход выше в судах (231 тыс.) и в парламенте (209 тыс.). В остальных ведомствах средний доход около 75-100 тыс.грн. на члена семьи.
Посмотрим, как соотносится доход семьи и доход декларанта. Тут уже смотрим на абсолютные суммы без привязки к количеству членов семьи.
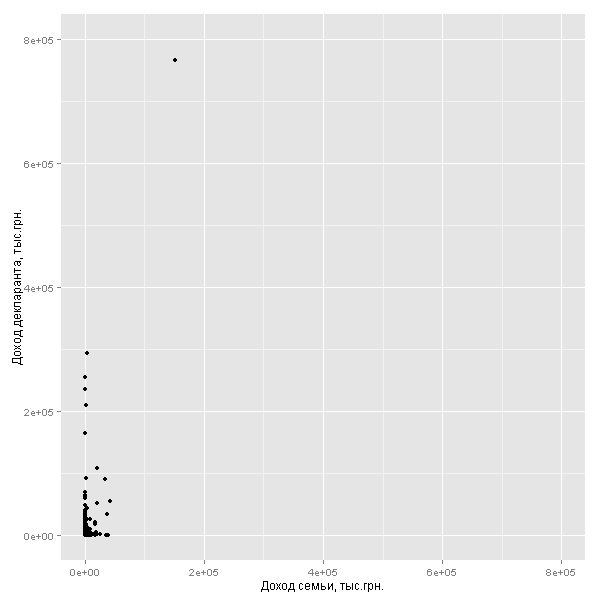
Те же парламентарии-аутлаеры мешают восприятию. Посмотрим, как соотносится доход декларантов и членов семей для основной массы чиновников (ограничимся 1 млн.грн. годового дохода и для декларанта, и для членов семей — среди семейных декларантов таких 94%):
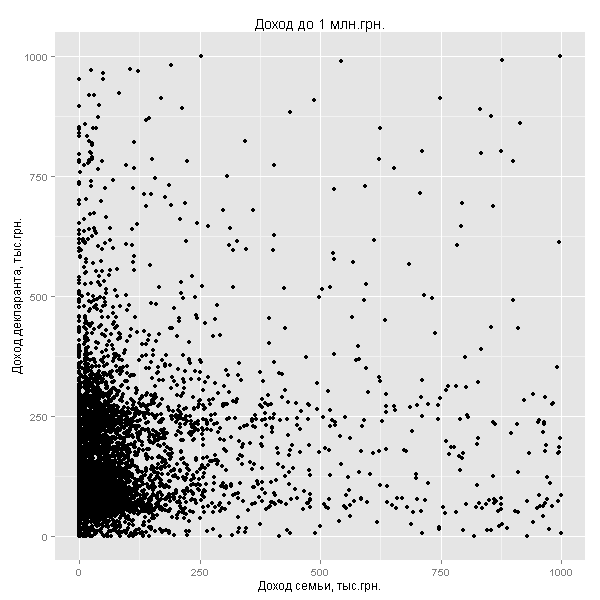
Видно, что доход декларанта чаще выше дохода семьи (скопление точек вдоль вертикальной оси), но это можно объяснить и тем, что 77% семейных декларантов — мужчины, а доходы мужчин в Украине выше доходов женщин в среднем на 30% (по данным International Labour Organization)
В разных ведомствах соотношение примерно одинаковое (см.график ниже). В парламенте несколько больше людей, семьи которых зарабатывают больше. В судах — наоборот (возможно, из-за относительно высокой зарплатой судей).


На первом месте дивиденды и проценты — но это только благодаря парламенту. Далее идут доходы от предпринимательской деятельности, причем этот тип более характерен для местной власти и прокуратуры, что навевает некоторые подозрения.
Зарплата в структуре доходов членов семьи чиновников только на третьем месте — хотя в целом по Украине она занимает первое место, составляя около 40% доходов населения (согласно Госкомстату).
Итак, краткий обзор доходов чиновников и их семей мы прошли.
Однако цель у нас другая — оценить вероятность того, что чиновник является коррупционером. Понятно, что только из данных деклараций этого сделать нельзя, даже несоответствие доходов и расходов не является доказательством взяточничества. Поэтому задача сейчас — определить некий индекс коррупционной подозрительности чиновника.
К сожалению, задача не может быть решена методами машинного обучения, так как информации о целевой переменной — является чиновник коррупционером или нет — у нас нет. Придется действовать экспертным путем.
Что может свидетельствовать о коррупции и может быть проверено на данных деклараций? Вот некоторые варианты. Для простоты расчетов за каждый пункт будет насчитываться 1 балл.
Штрафной балл присваивается тем, у кого сумма на счетах в пять или более раз превышает общий семейный годовой доход. Таких 294 человека.
Тут все просто. Таких оказалось 50 человек.
Штрафной балл присваивался тем, у кого семья владеет недвижимостью площадью больше средней по выборке, и при этом у самого декларанта недвижимости меньше, чем у семьи.
Таких получилось 478 человек. Если при этом доход семьи находился в нижних 25% доходов семей, то балл умножался на 2 — таких 49 человек.
Здесь я учитывала квартиры, дома, дачи, гаражи и т.п. — но не учитывала земельные участки, потому что из-за запрета на продажу с/х земли многие выходцы из сел имеют во владении паи бывших колхозных земель, и по сути человек может обладать гектарами земли, не имея возможности получить с нее выгоду.
Всего обнаружилось 128 человек, у которых были доходы из-за границы (личные или семейные). Из них у 44 человек эти доходы превышали доходы в Украине — их и признаем подозрительными.
Возьмем тех, у кого более двух авто и нет жилья. Таких 31 человек.
Я не нашла какой-либо утвержденной классификации автомобилей со списком марок и моделей, которые можно отнести к классу люкс. Поэтому пользовалась вики-статьей Luxury vehicle.
В итоге список получился таким: Acura, Alfa Romeo Giulia, Audi A4, Audi A6, Audi A7, Audi A8, Bentley, BMW 3, BMW 5, BMW 7, Cadillac, Ferrari, Hummer, Infinity, Jaguar, Lamborghini, Land Rover, Lexus, Maserati, Mercedes-Benz C, Mercedes-Benz E, Mercedes-Benz GL, Mercedes-Benz S, Porsche, Rolls-Royce, Saab 9-3, Saab 9-5, Volkswagen Phaeton, Volvo S60, Volvo S80.
Штраф начислялся тем, у кого есть хотя бы один из этих автомобилей, но не начислялся, если это единственное авто в семье (мало ли, вдруг копили всю жизнь). Всего таких 653 человека.
Штрафной балл начислялся тем, у кого соотношение доходов семьи от предпринимательской деятельности к общему доходу было выше среднего по выборке. Таких оказалось 419 человек.
Проект «ГарнаХата» собирает данные о собственниках дорогой недвижимости — это официальные данные на основе Государственного реестра имущественных прав.
Для наших целей я сравнила ФИО собственников с ФИО декларантов — при полном совпадении (таких было 80 человек) декларанту добавлялся 1 балл к подозрительности.
Кроме того, я сделала сверку только по фамилии (без имени и отчества) декларанта или фамилии родственников, которых он указал в декларациях. Поскольку фамилии бывают распространенные, то совпадений было много (более 2 тысяч), но и к показателю подозрительности добавлялось только 0,5 балла.
Сверка делалась в Excel, поэтому без кода
Сложив вместе баллы по всем подозрительным пунктам, я получила общий показатель подозрительности.
Из 10 346 декларантов он был больше нуля для 3971, но это в основном за счет совпадения фамилии из реестра недвижимости — показатель выше 0,5 зафиксирован для 1461 декларанта. Максимальное значение показателя — 5 (из теоретически возможного максимума 9,5).
Распределение по ведомствам снова указывает на парламент:
В этой статье я хочу показать возможности сайтов с открытой информацией о чиновниках, посмотреть на то, как эти чиновники живут и попытаться определить тех, кто наиболее подозрителен с точки зрения коррупции.
Почему открытая информация о доходах чиновников важна? Потому что это позволяет их контролировать.
Фото из инстаграмма дочери бывшего руководителя ГАИ Украины Александра Ершова. На фото дочь Ершова в Каннах рядом с Пэрис Хилтон. В результате скандала из-за несоответствия задекларированных доходов и образа жизни семьи Ершов подал в отставку.
Откуда данные?
Данные по декларациям чиновников взяты с сайта declarations.com.ua, а о владельцах элитной недвижимости — с сайта garnahata.in.ua. Оба сайта — проекты сообщества журналистов и волонтеров «Канцелярская сотня», изначально организованного для оцифровки документов из дома Януковича.
На данный момент на сайтах доступно около 11 тысяч деклараций чиновников из разных ведомств и около 9 тысяч записей о владельцах элитной недвижимости. Среди декларантов в основном представители разных министерств (включая службы на местах), работники судов и прокуратуры. Данные не претендуют на репрезентативность (чиновников в Украине около 400 тысяч), но покопаться в них все равно интересно.
У обоих сайтов есть открытый API, данные в формате JSON можно скачать с помощью скрипта на python. Схема объекта данных для деклараций есть на github тут, а схему объекта для данных о владельцах элитной недвижимости — тут. Для примера и понимания структуры данных — скан-копия одной из деклараций сайта.
Загрузив данные, я распарсила их в R, агрегировала некоторые и оставила только декларации за 2013 и 2014 годы.
Пример кода для получения данных из JSON файла
#Загружаем в R данные из файла JSON — получаем объект типа list decl_raw<-rjson::fromJSON(file="feed.json") #Создаем dataframe с количеством строк, равным кол-ву деклараций decl_df<-data.frame(matrix(NA,nrow=length(decl_raw), ncol = 0)) # #Простой случай: должность и место работы декларанта # #Добавляем колонки decl_df$general.post.region<-“” decl_df$general.post.office<-“” decl_df$general.post.post<-“” #Считываем данные из списка for (i in 1:length(decl_raw)) { # #ДАННЫЕ О ДОЛЖНОСТИ # #Регион, в котором работает декларант decl_df$general.post.region[i]<-decl_raw[[i]]$general$post$region #Учреждение decl_df$general.post.office[i]<-decl_raw[[i]]$general$post$office #Должность decl_df$general.post.post[i]<-decl_raw[[i]]$general$post$post } # #Более сложный случай: подсчет кол-ва транспортных средств и считывание их названий # #Добавляем колонки decl_df$vehicle35<-0 decl_df$vehicle36<-0 decl_df$vehicle37<-0 decl_df$vehicle38<-0 decl_df$vehicle39<-0 decl_df$vehicle40<-0 decl_df$vehicle41<-0 decl_df$vehicle42<-0 decl_df$vehicle43<-0 decl_df$vehicle44<-0 #Считываем данные из списка for (i in 1:length(decl_raw)) { # #Кол-во транспортных средств по статьям декларации (пп.35-44) # for (unit in 35:44) { j = 0 col_name<-paste0("vehicle", unit) raw_col_name<-paste0("decl_raw[[",i,"]]$vehicle$`",unit,"`") if (length(eval(parse(text=raw_col_name)))!=0) { for (k in 1:length(eval(parse(text=raw_col_name)))) { if (length(eval(parse(text=paste0("decl_raw[[",i,"]]$vehicle$`",unit,"`[[",k, "]]$brand"))))!=0 && eval(parse(text=paste0("decl_raw[[",i,"]]$vehicle$`",unit,"`[[",k, "]]$brand")))!="") {j = j+1} } } decl_df[i, grep(col_name, colnames(decl_df))]<-j } } #Добавляем колонку для названия всех ТС decl_df_all$vehicle_names<-"" for (i in 1:length(decl_raw)) { vname<-"" for (unit in 35:44) { col_name<-paste0("vehicle", unit) raw_col_name<-paste0("decl_raw[[",i,"]]$vehicle$`",unit,"`") if (length(eval(parse(text=raw_col_name)))!=0) { for (k in 1:length(eval(parse(text=raw_col_name)))) { if (length(eval(parse(text=paste0("decl_raw[[",i,"]]$vehicle$`",unit,"`[[",k, "]]$brand"))))!=0 && eval(parse(text=paste0("decl_raw[[",i,"]]$vehicle$`",unit,"`[[",k, "]]$brand")))!="") { vname=paste(vname,eval(parse(text=paste0("decl_raw[[",i,"]]$vehicle$`",unit,"`[[",k, "]]$brand"))), sep=";") } } } } decl_df$vehicle_names[i]<-vname }
Начнем с самого очевидного и простого — дохода.
Доходы чиновников
Декларанты указывают свой доход и доход членов семьи. Для начала посмотрим на доход в расчете на одного члена семьи.
Код для подсчета дохода на члена семьи
#decl_df — это dataframe с данными деклараций из JSON файла #Тут и далее цифры в названии переменной обычно указывают на пункт декларации #Чтобы избежать ошибок, когда суммарный доход подсчитывается неправильно, #суммируем все статьи личного дохода декларанта decl_df$income.own<-decl_df$income.own.6+decl_df$income.own.7+decl_df$income.own.8+ decl_df$income.own.9+decl_df$income.own.10+decl_df$income.own.11+ decl_df$income.own.12+decl_df$income.own.13+decl_df$income.own.14+ decl_df$income.own.15+decl_df$income.own.16+decl_df$income.own.17+ decl_df$income.own.18+decl_df$income.own.19+decl_df$income.own.20+ decl_df$income.own.21 #Если декларант указал общую сумму, но не указал доход по статьям, считаем указанную общую сумму суммарным доходом #В иных случах считаем суммарным доходом подсчитанную сумму по статьям for (i in 1:nrow(decl_df)) { if (decl_df$income.own[i]==0 && decl_df$income.own.5[i]>0) {decl_df$income.own[i]<-decl_df$income.own.5[i]} } #Аналогично считаем общий доход семьи decl_df$income.family<-decl_df$income.family.6+decl_df$income.family.7+ decl_df$income.family.8+decl_df$income.family.9+decl_df$income.family.10+ decl_df$income.family.11+decl_df$income.family.12+ decl_df$income.family.13+decl_df$income.family.14+ decl_df$income.family.15+decl_df$income.family.16+ decl_df$income.family.17+decl_df$income.family.18+ decl_df$income.family.19+decl_df$income.family.20+ as.numeric(gsub(",", ".", decl_df$income.family.22)) for (i in 1:nrow(decl_df)) { if (decl_df$income.family[i]==0 && decl_df$income.family.5[i]>0) {decl_df$income.family[i]<-decl_df$income.family.5[i]} } #Считаем доход на одного члена семьи decl_df$income_per_member<-rowSums(cbind(decl_df$income.own,decl_df$income.family), na.rm=TRUE) decl_df$income_per_member<-decl_df$income_per_member/decl_df$number_of_family_members_incl_decl #Переводим его в тыс.грн. decl_df$income_per_member_ths<-decl_df$income_per_member/1000
Беглый взгляд на 10%-процентили показывает, что в верхних 10% есть какие-то супер-богачи: средний доход для верхних 10% — 305,8 млн.грн. на члена семьи (около 12 млн.долларов), при этом на 90%-м процентиле значение всего 382 тыс.грн.
quantile(decl_df$income_per_member_ths, probs=seq(0,1,0.1))
В разрезе ведомств:
Код для графика
qplot(data=decl_df, x=office_g, y = income_per_member_ths, geom="boxplot", xlab="Ведомство", ylab="Доход на члена семьи, тыс.грн.", main="Все декларанты")
Внезапно парламент. По всем остальным ведомствам доход на члена семьи не превышает 50 млн.грн. в год. Отсеем аутлаеров с очень высоким доходом и посмотрим на чиновников с доходом до 1 млн.грн. на члена семьи в год (таких 97%):
Код для графика
qplot(data=decl_df[decl_df$income_per_member_ths<1000,], x=office_g, y = income_per_member_ths, geom="boxplot", xlab="Ведомство", ylab="Доход на члена семьи, тыс.грн.", main="Доход до 1 млн.грн.")
Видно, что средний доход выше в судах (231 тыс.) и в парламенте (209 тыс.). В остальных ведомствах средний доход около 75-100 тыс.грн. на члена семьи.
Доходы чиновников vs доходы семей
Посмотрим, как соотносится доход семьи и доход декларанта. Тут уже смотрим на абсолютные суммы без привязки к количеству членов семьи.
Код для графика
#Создаем dataframe только семейных чиновников decl_family<-decl_df[decl_df$number_of_family_members_incl_decl>1,] qplot(data=decl_family, y=income.own/1000, x=income.family/1000, xlim=c(0,800000), ylim=c(0,800000), xlab="Доход семьи, тыс.грн.", ylab="Доход декларанта, тыс.грн.")
Те же парламентарии-аутлаеры мешают восприятию. Посмотрим, как соотносится доход декларантов и членов семей для основной массы чиновников (ограничимся 1 млн.грн. годового дохода и для декларанта, и для членов семей — среди семейных декларантов таких 94%):
Код для графика
nrow(decl_family[decl_family$income.own<1000000 & decl_family$income.family<1000000,])/nrow(decl_family) qplot(data=decl_family, y=income.own/1000, x=income.family/1000, xlim=c(0,1000), ylim=c(0,1000), xlab="Доход семьи, тыс.грн.", ylab="Доход декларанта, тыс.грн.", main="Доход до 1 млн.грн.")
Видно, что доход декларанта чаще выше дохода семьи (скопление точек вдоль вертикальной оси), но это можно объяснить и тем, что 77% семейных декларантов — мужчины, а доходы мужчин в Украине выше доходов женщин в среднем на 30% (по данным International Labour Organization)
В разных ведомствах соотношение примерно одинаковое (см.график ниже). В парламенте несколько больше людей, семьи которых зарабатывают больше. В судах — наоборот (возможно, из-за относительно высокой зарплатой судей).
Код для расчетов и графика
#Создаем переменную-фактор из 4 категорий: #1.Нет дохода у семьи #2.Доход семьи меньше 75% дохода декларанта #3.Доход семьи соизмерим с доходом декларанта (составляет от 75% до 150% дохода декларанта) #4.Доход семьи превышает доход декларанта в 1,5 и больше раза decl_family$family.own.income.ratio<-"" for (i in 1:nrow(decl_family)) { if (decl_family$income.family[i]==0) {decl_family$family.own.income.ratio[i]<-"1.Нет дохода у семьи"} else { if (decl_family$income.family[i]<=0.75*decl_family$income.own[i]) {decl_family$family.own.income.ratio[i]<-"2.Доход семьи меньше (<0.75x)"} else { if (decl_family$income.family[i]<=1.5*decl_family$income.own[i]) { decl_family$family.own.income.ratio[i]<-"3.Доход семьи соизмерим (0.75-1.5х)" } if (decl_family$income.family[i]>1.5*decl_family$income.own[i]) { decl_family$family.own.income.ratio[i]<-"4.Доход семьи больше, >1.5x" } } } } decl_family$family.own.income.ratio<-as.factor(decl_family$family.own.income.ratio) #Создаем таблицу с % по каждому ведомству y<-as.data.frame(100*prop.table(table(decl_family$family.own.income.ratio,decl_family$office_g), margin=2)) #Строим график ggplot(y, aes(x = Var2, y = Freq, fill = Var1)) + geom_bar(stat="identity")+ ylab("%") + xlab("")+ theme(text = element_text(size=14), legend.title=element_blank(),axis.text.x = element_text(angle=90, size=12,vjust=1,hjust=1))+ geom_text(aes(label = round(Freq,0),ymax=100),size=4,vjust=1.5,position="stack")+ scale_fill_brewer()
Из каких источников получают доход семьи чиновников?
На первом месте дивиденды и проценты — но это только благодаря парламенту. Далее идут доходы от предпринимательской деятельности, причем этот тип более характерен для местной власти и прокуратуры, что навевает некоторые подозрения.
Зарплата в структуре доходов членов семьи чиновников только на третьем месте — хотя в целом по Украине она занимает первое место, составляя около 40% доходов населения (согласно Госкомстату).
Индекс подозрительности чиновника
Итак, краткий обзор доходов чиновников и их семей мы прошли.
Однако цель у нас другая — оценить вероятность того, что чиновник является коррупционером. Понятно, что только из данных деклараций этого сделать нельзя, даже несоответствие доходов и расходов не является доказательством взяточничества. Поэтому задача сейчас — определить некий индекс коррупционной подозрительности чиновника.
К сожалению, задача не может быть решена методами машинного обучения, так как информации о целевой переменной — является чиновник коррупционером или нет — у нас нет. Придется действовать экспертным путем.
Что может свидетельствовать о коррупции и может быть проверено на данных деклараций? Вот некоторые варианты. Для простоты расчетов за каждый пункт будет насчитываться 1 балл.
- Крупные суммы на счетах в банках при низких доходах декларанта и членов семьи
Штрафной балл присваивается тем, у кого сумма на счетах в пять или более раз превышает общий семейный годовой доход. Таких 294 человека.
Код для расчетов
#Считаем суммарный доход (личный и семьи) decl_df$income.own.and.family<-decl_df$income.own+decl_df$income.family #Считаем суммы на счетах в банках (пп.45-53 декларации) decl_df$banks<-decl_df$banks45+decl_df$banks47+decl_df$banks49+ decl_df$banks51+decl_df$banks52+decl_df$banks53 #Делим суммы на счетах на доход decl_df$banks.income.ratio<-decl_df$banks/(decl_df$income.own.and.family+1) #Подсчитываем переменную подозрительности по этому пункту #Присваиваем ее единице в тех случаях, когда сумма на счетах #в 5 и более раз выше, чем суммарный годовой доход decl_df$susp1<-0 for (i in 1:nrow(decl_df)) { if (decl_df$banks[i]>5*decl_df$income.own.and.family[i]) {decl_df$susp1[i]<-1} }
- Нулевой доход семьи и декларанта. Он, конечно, может быть признаком неаккуратно заполненной декларации — но это, во-первых, тоже нехорошо, а во-вторых, может говорить о том, что чиновнику есть что скрывать.
Тут все просто. Таких оказалось 50 человек.
Код для расчетов
decl_df$susp2<-0 for (i in 1:nrow(decl_df)) { if (decl_df$income.own.and.family[i]==0) {decl_df$susp2[i]<-1} }
- Если имущество записано в основном на членов семьи, особенно если у них низкие доходы
Штрафной балл присваивался тем, у кого семья владеет недвижимостью площадью больше средней по выборке, и при этом у самого декларанта недвижимости меньше, чем у семьи.
Таких получилось 478 человек. Если при этом доход семьи находился в нижних 25% доходов семей, то балл умножался на 2 — таких 49 человек.
Здесь я учитывала квартиры, дома, дачи, гаражи и т.п. — но не учитывала земельные участки, потому что из-за запрета на продажу с/х земли многие выходцы из сел имеют во владении паи бывших колхозных земель, и по сути человек может обладать гектарами земли, не имея возможности получить с нее выгоду.
Код для расчетов
#Суммарная площадь недвижимости в собственности декларанта decl_df$estate.own<-decl_df$estate24+decl_df$estate25+ decl_df$estate26+decl_df$estate27+decl_df$estate28 #Суммарная площадь недвижимости в собственности семьи decl_df$estate.family<-decl_df$estate30+decl_df$estate31+ decl_df$estate32+decl_df$estate33+decl_df$estate34 #Считаем верхнюю границу первых 25% по семейному доходу x<-quantile(decl_df[decl_df$number_of_family_members>0,]$income.family, probs=seq(0,1,0.25))[2] #Считаем среднюю по выборке суммарную площадь недвижимости семьи y<-mean(decl_df[decl_df$number_of_family_members>0,]$estate.family) #Если недвижимости у семьи больше среднего по выборке и больше чем у декларанта #присваиваем штрафной балл decl_df$susp3<-0 for (i in 1:nrow(decl_df)) { if (decl_df$estate.family[i]>y & decl_df$estate.family[i]>decl_df$estate.own[i]) { #Если при этом доход семьи находится в нижнем квартиле, умножаем балл на два if (decl_df$income.family[i]<x) {decl_df$susp3[i]<-2} else {decl_df$susp3[i]<-1} } }
- Крупные суммы доходов из-за границы (может свидетельствовать об отмывании средств)
Всего обнаружилось 128 человек, у которых были доходы из-за границы (личные или семейные). Из них у 44 человек эти доходы превышали доходы в Украине — их и признаем подозрительными.
Код для расчетов
#Доходы из-за границы (декларанта и семьи) decl_df$income.from.abroad<-decl_df$income.own.21+as.double(decl_df$income.family.22) decl_df$susp4<-0 for (i in 1:nrow(decl_df)) { #Если доход из-за границы больше, чем доход внутри страны — присваиваем балл if (decl_df$income.from.abroad[i]> decl_df$income.own.and.family[i]-decl_df$income.from.abroad[i]) {decl_df$susp4[i]<-1} }
- Наличие нескольких автомобилей при отсутствии жилья
Возьмем тех, у кого более двух авто и нет жилья. Таких 31 человек.
Код для расчетов
#Количество авто (легковых и грузовых) в семье decl_df$vehicles<-decl_df$vehicle35+decl_df$vehicle36+ decl_df$vehicle40+decl_df$vehicle41 decl_df$susp5<-0 for (i in 1:nrow(decl_df)) { if (decl_df$vehicles[i]>2 & decl_df$estate.own[i]==0 & decl_df$estate.family[i]==0) {decl_df$susp5[i]<-1} }
- Наличие автомобилей класса люкс
Я не нашла какой-либо утвержденной классификации автомобилей со списком марок и моделей, которые можно отнести к классу люкс. Поэтому пользовалась вики-статьей Luxury vehicle.
В итоге список получился таким: Acura, Alfa Romeo Giulia, Audi A4, Audi A6, Audi A7, Audi A8, Bentley, BMW 3, BMW 5, BMW 7, Cadillac, Ferrari, Hummer, Infinity, Jaguar, Lamborghini, Land Rover, Lexus, Maserati, Mercedes-Benz C, Mercedes-Benz E, Mercedes-Benz GL, Mercedes-Benz S, Porsche, Rolls-Royce, Saab 9-3, Saab 9-5, Volkswagen Phaeton, Volvo S60, Volvo S80.
Штраф начислялся тем, у кого есть хотя бы один из этих автомобилей, но не начислялся, если это единственное авто в семье (мало ли, вдруг копили всю жизнь). Всего таких 653 человека.
Код для расчетов
#Вектор с названиями авто luxury_cars<-c('Acura', 'Lexus', 'Cadillac', 'Alfa Romeo Giulia', 'Jaguar', 'Volvo S60', 'Infinity', 'Saab 9-3', 'BMW 3', 'Audi A4', 'Mercedes-Benz C', 'Volvo S80', 'Audi A6', 'Audi A7', 'Mercedes-Benz E', 'Saab 9-5', 'Maserati', 'BMW 5', 'BMW 7', 'Audi A8', 'Mercedes-Benz S', 'Porsche', 'Volkswagen Phaeton', 'Rolls-Royce', 'Bentley', 'Ferrari', 'Lamborghini', 'Mercedes-Benz GL', 'Hummer', 'Land Rover') for (j in (1:nrow(decl_df))) { decl_df$susp5.1[j]<-0 for (i in (1:length(luxury_cars))) { #Если в списке машин встречается название из вектора if (grepl(luxury_cars[i], decl_df$vehicle_names[j], ignore.case=TRUE)==TRUE) { #Считаем кол-во таких машин decl_df$susp5.1[j]<-decl_df$susp5.1[j]+ length(gregexpr(luxury_cars[i], decl_df$vehicle_names[j],ignore.case=TRUE)[[1]]) } } } decl_df$susp5.2<-0 #Если есть элитные авто - присваиваем штрафной балл for (i in (1:nrow(decl_df))) {if (decl_df$susp5.1[i]>0) decl_df$susp5.2[i]<-1} #Если это единственное авто - снимаем штрафной балл for (i in (1:nrow(decl_df))) {if (decl_df$vehicles[i]==1) decl_df$susp5.2[i]<-0}
- Высокие доходы членов семьи от предпринимательской деятельности.
Штрафной балл начислялся тем, у кого соотношение доходов семьи от предпринимательской деятельности к общему доходу было выше среднего по выборке. Таких оказалось 419 человек.
Код для расчетов
#Изначально присваиваем коэффициенту значение 0 decl_df$familyPE.own.income.ratio<-0 #Для тех, у кого не нулевой доход, считаем соотношение дохода #семьи от предпринимательской деятельности к общему доходу семьи и декларанта decl_df[decl_df$income.own.and.family>0,]$familyPE.own.income.ratio<- decl_df[decl_df$income.own.and.family>0,]$income.family.17/decl_df[decl_df$income.own.and.family>0,]$income.own.and.family #Среднее по выборке соотношение дохода семьи от предпринимательской деятельности к общему доходу.Считаем только для тех, у кого в семье есть доход от предпринимательской деятельности x<-mean(decl_df[decl_df$income.family.17>0,]$familyPE.own.income.ratio) decl_df$susp6<-0 #Если соотношение больше среднего — присваиваем штрафной балл for (i in 1:nrow(decl_df)) { if (decl_df$familyPE.own.income.ratio[i]>x) {decl_df$susp6[i]<-1} }
- Владение элитной недвижимостью (на основе данных garnahata)
Проект «ГарнаХата» собирает данные о собственниках дорогой недвижимости — это официальные данные на основе Государственного реестра имущественных прав.
Для наших целей я сравнила ФИО собственников с ФИО декларантов — при полном совпадении (таких было 80 человек) декларанту добавлялся 1 балл к подозрительности.
Кроме того, я сделала сверку только по фамилии (без имени и отчества) декларанта или фамилии родственников, которых он указал в декларациях. Поскольку фамилии бывают распространенные, то совпадений было много (более 2 тысяч), но и к показателю подозрительности добавлялось только 0,5 балла.
Сверка делалась в Excel, поэтому без кода
Результаты
Сложив вместе баллы по всем подозрительным пунктам, я получила общий показатель подозрительности.
Код для расчетов
decl_df$suspicious<-decl_df$susp1+decl_df$susp2+ decl_df$susp3+decl_df$susp4+decl_df$susp5+decl_df$susp5.2+ decl_df$susp6+decl_df$hata_own+decl_df$hata_family*0.5
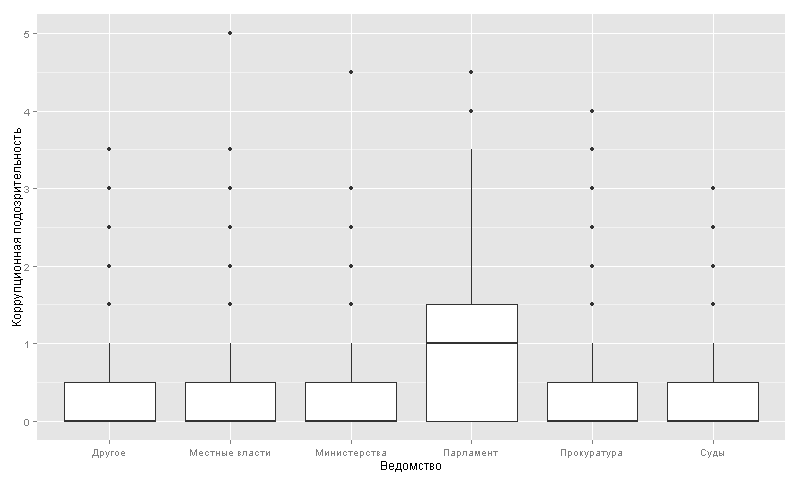
Из 10 346 декларантов он был больше нуля для 3971, но это в основном за счет совпадения фамилии из реестра недвижимости — показатель выше 0,5 зафиксирован для 1461 декларанта. Максимальное значение показателя — 5 (из теоретически возможного максимума 9,5).
Распределение по ведомствам снова указывает на парламент:

