
У меня есть подборка простеньких вопросов, которые я люблю задавать при собеседовании. Например, как посчитать общее число записей к таблице? Вроде бы ничего сложного, но если копнуть глубже, то можно много интересных нюансов рассказать собеседнику.
Давайте начнем с простого… Эти запросы отличаются чем-то друг от друга с точки зрения конечного результата?
SELECT COUNT(*) FROM Sales.SalesOrderDetail SELECT COUNT_BIG(*) FROM Sales.SalesOrderDetail
Большинство отвечали: «Нет».
Реже старались долее детально формировать ответ: «Запросы вернут идентичный результат, но COUNT вернет значение типа INT, а COUNT_BIG – тип BIGINT».
Если проанализировать план выполнения, то можно заметить различия, которые многие упускают из вида. При использовании COUNT на плане будет операция Compute Scalar:
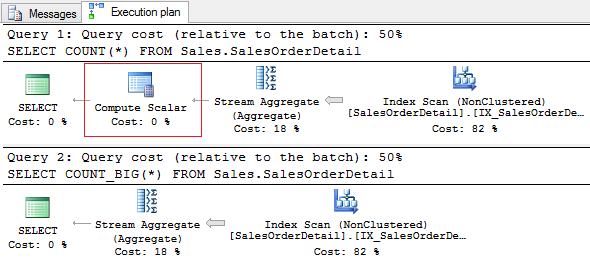
Если посмотреть в свойства оператора, то мы увидим там:
[Expr1003] = Scalar Operator(CONVERT_IMPLICIT(int,[Expr1004],0))
Это происходит потому, что при вызове COUNT неявно используется COUNT_BIG после чего результат преобразуется в INT.
Не сказал бы, что существенно, но преобразования типов увеличивает нагрузку на процессор. Многие, конечно, могут сказать, что этот оператор ничего не стоит при выполнении, но нужно отметить простой факт – SQL Server очень часто недооценивает Compute Scalar операторы.
Еще я знаю людей, которые любят использовать SUM вместо COUNT:
SELECT SUM(1) FROM Sales.SalesOrderDetail
Такой вариант примерно равнозначен COUNT. Мы также получим лишний Compute Scalar на плане выполнения:
[Expr1003] = Scalar Operator(CASE WHEN [Expr1004]=(0) THEN NULL ELSE [Expr1005] END)
Теперь более детально затронем вопросы производительности.…
Если использовать запросы выше, то чтобы посчитать количество записей SQL Server необходимо выполнить Full Index Scan (или Full Table Scan если таблица является кучей). В любом случае, эти операции далеко не самые быстрые. Лучше всего для получения количества записей использовать системные представления: sys.dm_db_partition_stats или sys.partitions (есть еще sysindexes, но оставлен для обратной совместимости с SQL Server 2000).
USE AdventureWorks2012 GO SET STATISTICS IO ON SET STATISTICS TIME ON GO SELECT COUNT_BIG(*) FROM Sales.SalesOrderDetail SELECT SUM(p.[rows]) FROM sys.partitions p WHERE p.[object_id] = OBJECT_ID('Sales.SalesOrderDetail') AND p.index_id < 2 SELECT SUM(s.row_count) FROM sys.dm_db_partition_stats s WHERE s.[object_id] = OBJECT_ID('Sales.SalesOrderDetail') AND s.index_id < 2
Если сравнить планы выполнения, то доступ к системным представлениям менее затратный:
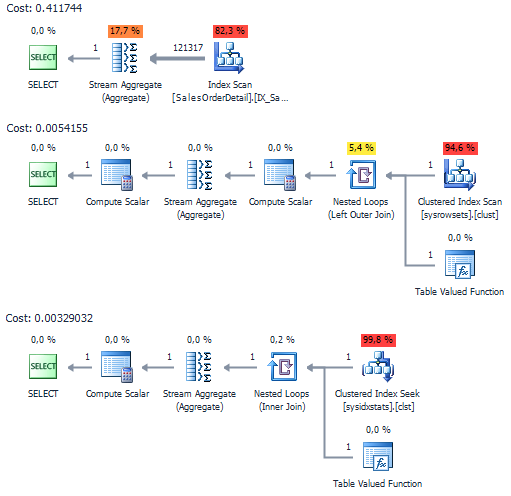
На AdventureWorks преимущество от применения системных представлений явно не проявляется:
Table 'SalesOrderDetail'. Scan count 1, logical reads 276, ... SQL Server Execution Times: CPU time = 12 ms, elapsed time = 26 ms. Table 'sysrowsets'. Scan count 1, logical reads 5, ... SQL Server Execution Times: CPU time = 4 ms, elapsed time = 4 ms. Table 'sysidxstats'. Scan count 1, logical reads 2, ... SQL Server Execution Times: CPU time = 2 ms, elapsed time = 1 ms.
Время выполнения на секционированной таблице с 30 миллионами записей:
Table 'big_test'. Scan count 6, logical reads 114911, ... SQL Server Execution Times: CPU time = 4859 ms, elapsed time = 5079 ms. Table 'sysrowsets'. Scan count 1, logical reads 25, ... SQL Server Execution Times: CPU time = 0 ms, elapsed time = 2 ms. Table 'sysidxstats'. Scan count 1, logical reads 2, ... SQL Server Execution Times: CPU time = 0 ms, elapsed time = 2 ms.
В случае если нужно проверить наличие записей в таблице, то использование метаданных как было показано выше не даст особых преимуществ…
IF EXISTS(SELECT * FROM Sales.SalesOrderDetail) PRINT 1 IF EXISTS( SELECT * FROM sys.dm_db_partition_stats WHERE [object_id] = OBJECT_ID('Sales.SalesOrderDetail') AND row_count > 0 ) PRINT 1
Table 'SalesOrderDetail'. Scan count 1, logical reads 2,... SQL Server Execution Times: CPU time = 1 ms, elapsed time = 3 ms. Table 'sysidxstats'. Scan count 1, logical reads 2,... SQL Server Execution Times: CPU time = 4 ms, elapsed time = 5 ms.
И на практике будет даже капельку медленнее, поскольку SQL Server генерирует более сложный план выполнения для выборки из метаданных.
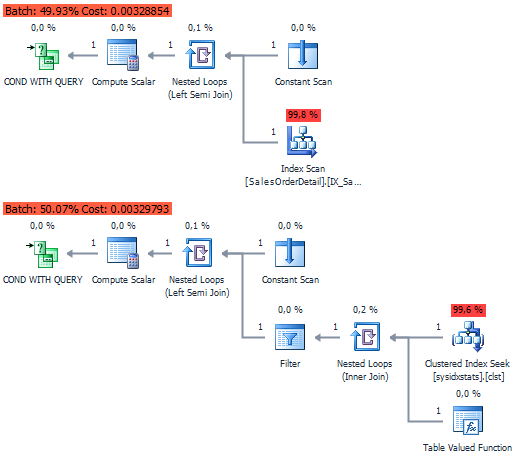
Еще интереснее становиться, когда нужно посчитать количество записей по всем таблицам сразу. На практике встречал несколько вариантов, которые можно обобщить.
Вариант #1 с применением недокументированной процедуры, которая курсором обходит все пользовательские таблицы:
IF OBJECT_ID('tempdb.dbo.#temp') IS NOT NULL DROP TABLE #temp GO CREATE TABLE #temp (obj SYSNAME, row_count BIGINT) GO EXEC sys.sp_MSForEachTable @command1 = 'INSERT #temp SELECT ''?'', COUNT_BIG(*) FROM ?' SELECT * FROM #temp ORDER BY row_count DESC
Вариант #2 – динамический SQL которые генерирует запросы SELECT COUNT(*):
DECLARE @SQL NVARCHAR(MAX) SELECT @SQL = STUFF(( SELECT 'UNION ALL SELECT ''' + SCHEMA_NAME(o.[schema_id]) + '.' + o.name + ''', COUNT_BIG(*) FROM [' + SCHEMA_NAME(o.[schema_id]) + '].[' + o.name + ']' FROM sys.objects o WHERE o.[type] = 'U' AND o.is_ms_shipped = 0 FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)'), 1, 10, '') + ' ORDER BY 2 DESC' PRINT @SQL EXEC sys.sp_executesql @SQL
Вариант #3 – быстрый вариант на каждый день:
SELECT SCHEMA_NAME(o.[schema_id]), o.name, t.row_count FROM sys.objects o JOIN ( SELECT p.[object_id], row_count = SUM(p.row_count) FROM sys.dm_db_partition_stats p WHERE p.index_id < 2 GROUP BY p.[object_id] ) t ON t.[object_id] = o.[object_id] WHERE o.[type] = 'U' AND o.is_ms_shipped = 0 ORDER BY t.row_count DESC
Уж очень много я выдал дифирамбов, что системные представления такие хорошие. Однако, при работе с ними нас могут подстерегать «приятные» неожиданности.
Помнится, был такой веселый баг, когда при миграции с SQL Server 2000 на 2005 некоторые системные представления некорректно обновлялись. Особо везучим людям, в таком случае, из метаданных возвращались неверные значения о количестве записей в таблицах. Лечилось это все командой DBCC UPDATEUSAGE.
Вместе с SQL Server 2005 SP1 этот баг исправили и все бы ничего… Но подобную ситуацию я наблюдал еще один раз, когда восстановил бекап с SQL Server 2005 SP4 на SQL Server 2012 SP2. Воспроизвести проблему на реальном окружении увы не смогу, поэтому немного обманув оптимизатор:
UPDATE STATISTICS Person.Person WITH ROWCOUNT = 1000000000000000000
расскажу на простом примере.
Самый безобидный запрос начал выполняться дольше чем обычно:
SELECT FirstName, COUNT(*) FROM Person.Person GROUP BY FirstName
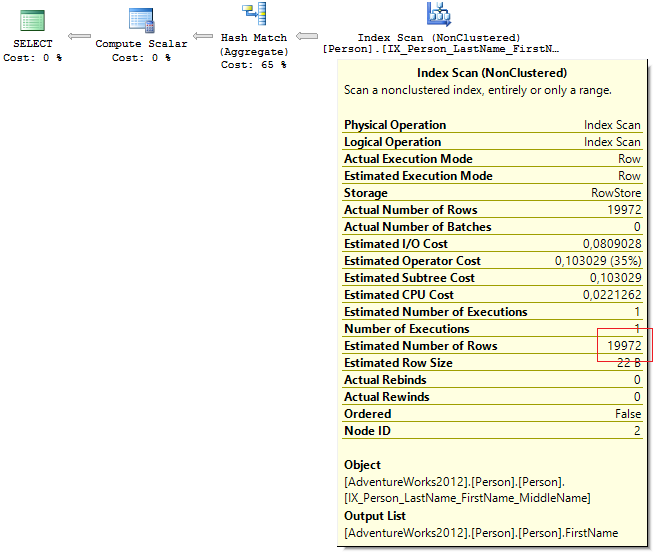
Посмотрел на план запроса и увидел там явно неадекватное значение Estimated number of rows:
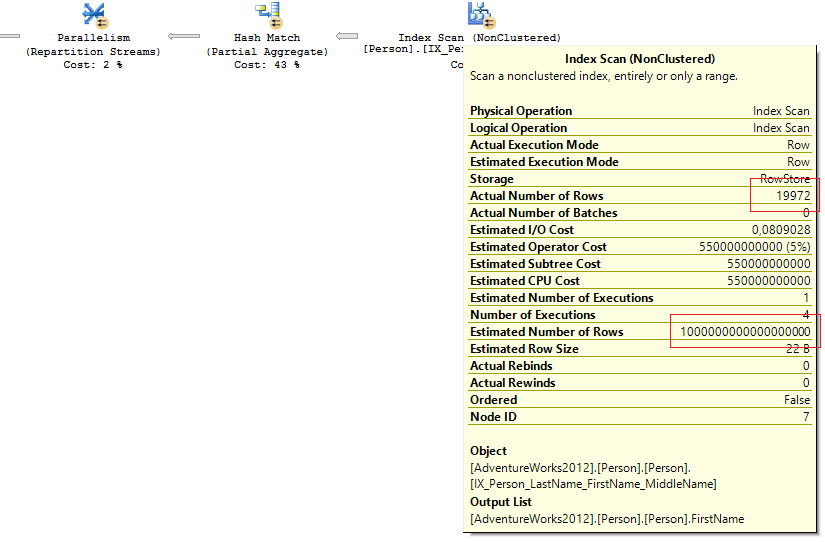
Заглянул в статистику по кластерному индексу:
DECLARE @SQL NVARCHAR(MAX) DECLARE @obj SYSNAME = 'Person.Person' SELECT @SQL = 'DBCC SHOW_STATISTICS(''' + @obj + ''', ' + name + ') WITH STAT_HEADER' FROM sys.stats WHERE [object_id] = OBJECT_ID(@obj) AND stats_id < 2 EXEC sys.sp_executesql @SQL
Все было в норме:

Но в системных представления о которых мы говорили ранее:
SELECT rowcnt FROM sys.sysindexes WHERE id = OBJECT_ID('Person.Person') AND indid < 2 SELECT SUM([rows]) FROM sys.partitions p WHERE p.[object_id] = OBJECT_ID('Person.Person') AND p.index_id < 2
была печаль:
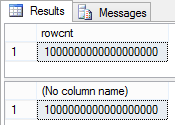
В запросе не было предикатов для фильтрации и оптимизатор выбрал Full Index Scan. При Full Index/Table Scan ожидаемое количество строк оптимизатор не берет из статистики, а обращается к метаданным (точно не уверен всегда ли это происходит).
Не секрет, что на основе Estimated number of rows SQL Server генерирует план выполнения и вычисляет сколько нужно памяти чтобы его выполнить. Если оценка будет неверной, то может быть выделено больше памяти на выполнение запроса, чем нужно на самом деле.
SELECT session_id, query_cost, requested_memory_kb, granted_memory_kb, required_memory_kb, used_memory_kb FROM sys.dm_exec_query_memory_grants
Вот к чему приводит неверная оценка количества строк:
query_cost requested_memory_kb granted_memory_kb required_memory_kb used_memory_kb ----------- -------------------- -------------------- -------------------- -------------- 1133156839 769552 769552 6504 6026
Проблема решилась достаточно просто:
DBCC UPDATEUSAGE(AdventureWorks2012, 'Person.Person') WITH COUNT_ROWS DBCC FREEPROCCACHE
После рекомпиляции запроса все пришло в норму:
query_cost requested_memory_kb granted_memory_kb required_memory_kb used_memory_kb ----------- -------------------- -------------------- -------------------- -------------- 0,2919 1168 1168 1024 952
Если системные представления уже не кажутся «спасительной палочкой», то какие варианты у нас остаются? Можно делать все по-старинке:
SELECT COUNT_BIG(*) FROM ...
Но при интенсивной вставке в таблицу я бы не доверял результатам. «Волшебный» хинт NOLOCK тем более не гарантирует правильного значения:
SELECT COUNT_BIG(*) FROM ... WITH(NOLOCK)
По сути, чтобы получить правильное значение количества строк в таблице, нужно выполнять запрос под уровнем изоляции SERIALIZABLE либо используя хинт TABLOCKX:
SELECT COUNT_BIG(*) FROM ... WITH(TABLOCKX)
И что мы получаем в итоге… монопольную блокировку таблицы на период выполнении запроса. И тут каждый должен решать сам, что ему лучше использовать. Мой выбор — метаданные.
Еще интереснее, когда нужно быстро подсчитать число строк по условию:
SELECT City, COUNT_BIG(*) FROM Person.[Address] --WHERE City = N'London' GROUP BY City
Если в таблице не происходят частые операции вставки-удаления, то можно создать индексированное представление:
IF OBJECT_ID('dbo.CityAddress', 'V') IS NOT NULL DROP VIEW dbo.CityAddress GO CREATE VIEW dbo.CityAddress WITH SCHEMABINDING AS SELECT City, [Rows] = COUNT_BIG(*) FROM Person.[Address] GROUP BY City GO CREATE UNIQUE CLUSTERED INDEX IX ON dbo.CityAddress (City)
Для этих запросов оптимизатор будет генерировать идентичный план на основе кластерного индекса вьюхи:
SELECT City, COUNT_BIG(*) FROM Person.[Address] WHERE City = N'London' GROUP BY City SELECT * FROM dbo.CityAddress WHERE City = N'London'
План выполнения с индексным представлением и без:
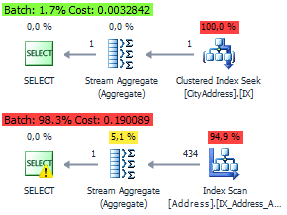
Этим постом я хотел показать, что идеальных решений на все случаи жизни не бывает. И в каждом конкретной ситуации нужно действовать с индивидуальным подходом.
Все тестировалось на SQL Server 2012 SP3 (11.00.6020).
В качестве выводов… Когда нужно подсчитать общее число строк по таблице, то я использую метаданные — это самый быстрый способ. И пусть Вас не пугает ситуация с старым багом, который я привел выше.
Если нужно быстро подсчитать количество строк в разрезе какого-то поля или по условию — то я стараюсь использовать индексированные представления либо фильтрованные индексы. Все зависит от ситуации.
Когда таблица маленькая или вопросы с производительностью не стоят так остро, то проще уж действительно по-старинке написать SELECT COUNT(*)…
Если хотите поделиться этой статьей с англоязычной аудиторией:
What is the fastest way to calculate the record COUNT?

