В первой части этой серии статей, я создал хорошую функцию сохранения, равно как и другую функцию, позволяющую создавать изменяемые документо-ориентированные таблицы на лету. Они работают исправно и делают именно то, что надо, но мы можем сделать еще многое. Особенно: я хочу полнотекстовый поиск, индексируемый на лету и сохранение многих документов внутри транзакции.
Давайте сделаем это.
Наша документо-ориентированная таблица имеет поисковое поле типа tsvector, которое индексируется, используя GIN индекс для скорости. Я хочу обновлять это поле каждый раз, когда сохраняю документ, и не хочу много шума от API когда я это делаю.
В связи с этим, я прибегну к некоторой условности.
Обычно, при создании полнотекстового индекса, поля хранятся с довольно-таки специфическими именами. Такими как:
Я хотел бы проверить мой документ в момент сохранения на наличие каких-либо ключей, которые я хотел бы проиндексировать и после этого сохранить их в поле search. Это возможно сделать при помощи функции, которую я назвал update_search:
Я вновь использую javascript (PLV8) для этих целей, и вытягиваю документ, основанный на ID. После чего я прохожу по всем ключам, что проверить, есть ли среди них те, которые я мог бы захотеть хранить, и, если есть, помещаю их в массив.
Если в этот архив есть попадания, я конкатинирую эти объекты и сохраняю их в поле search документа, используя функцию to_tsvector, являющуюся встроенной в Postgres, которая берет обычный текст и превращает его в индексируемые величины.
Вот и оно! Выполняя этот скрипт, мы получаем следующее:
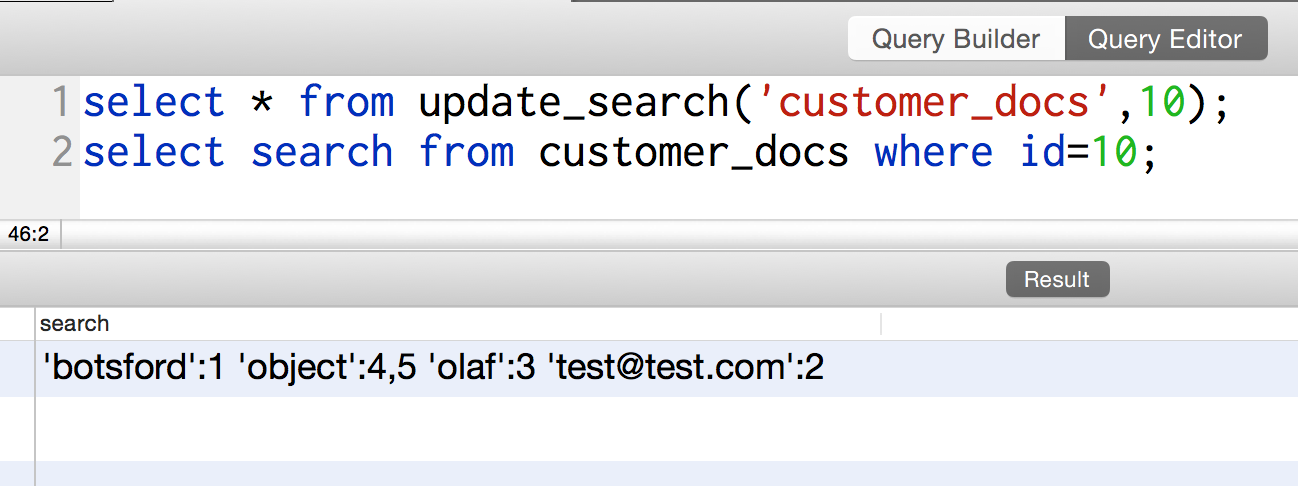
Идеально — теперь я просто могу вставить это в конец моей save_document функции и оно будет вызываться транзакционно каждый раз, когда я что-то сохраняю:
На данный момент, я могу передать единичный документ функции save_document, но я хотел бы иметь возможность передать ей массив. Я могу сделать это проверяя тип аргумента, после чего запускать цикл:
Хорошая сторона работы здесь с javascript'ом заключается в том, что логика, необходимая для такой рутины, достаточно проста (в противоположность PLPGSQL). Я выделил весь процесс сохранения в его отдельную функцию — которая является javascript'ом после всего — таким образом я могу избежать дублирования.
Затем я хочу проверить, что подаваемый на вход аргумент — массив. Если это так, то я иду по его членам и вызываю executeSql, возвращая все, что накопилось при выполнении.
Если это не массив, я просто выполняю все так же, как и было, возвращая документ целиком. Результат:

Прекрасно! Лучшее в этом то, что это все происходит внутри транзакции. Мне это нравится!
Если бы только это могло работать идеально из Node! Я пробовал и в .NET, и в Node, с .NET все просто работает (странно) используя библиотеку Npgsql. Из Node, не то чтобы.
Короче говоря: node_pg драйвер делает очень странное преобразование, когда он видит объект массива в качестве входного параметра. Обратим внимание на следующее:
Это обычный Node/PG код. В самом конце, функция run настроена чтобы вызывать мою save_document функцию и передавать некоторые данные. Когда PG видит входной объект, он превращает его в строку и сохранение пройдет нормально.
В случае же, если послать массив…
Я получаю обратно ошибку, сообщающую мне, что это некорректный JSON. Сообщение об ошибке (из Postgres) сообщит, что это связано со скудно отформатированным JSON:
Что… да, это ужасно. Я пытался сформулировать что происходит, но это просто-напросто выглядит так, что node_pg драйвер разбирает внешний массив — возможно вызывая метод flatten библиотеки Underscores. Я не знаю. Чтобы это обойти, вам необходимо изменить ваш вызов на следующее:
Процедура сохранения довольна гладкая и это меня радует. В следующей статье я настрою поисковики, а также создам функцию полнотекстового поиска.
Давайте сделаем это.
Полнотекстовый поиск
Наша документо-ориентированная таблица имеет поисковое поле типа tsvector, которое индексируется, используя GIN индекс для скорости. Я хочу обновлять это поле каждый раз, когда сохраняю документ, и не хочу много шума от API когда я это делаю.
В связи с этим, я прибегну к некоторой условности.
Обычно, при создании полнотекстового индекса, поля хранятся с довольно-таки специфическими именами. Такими как:
- Имя, или фамилия, возможно адрес электронной почты
- Название, или описание чего-то
- Адресная информация
Я хотел бы проверить мой документ в момент сохранения на наличие каких-либо ключей, которые я хотел бы проиндексировать и после этого сохранить их в поле search. Это возможно сделать при помощи функции, которую я назвал update_search:
create function update_search(tbl varchar, id int) returns boolean as $$ //get the record var found = plv8.execute("select body from " + tbl + " where id=$1",id)[0]; if(found){ var doc = JSON.parse(found.body); var searchFields = ["name","email","first","first_name", "last","last_name","description","title", "street", "city", "state", "zip", ]; var searchVals = []; for(var key in doc){ if(searchFields.indexOf(key.toLowerCase()) > -1){ searchVals.push(doc[key]); } }; if(searchVals.length > 0){ var updateSql = "update " + tbl + " set search = to_tsvector($1) where id =$2"; plv8.execute(updateSql, searchVals.join(" "), id); } return true; }else{ return false; } $$ language plv8;
Я вновь использую javascript (PLV8) для этих целей, и вытягиваю документ, основанный на ID. После чего я прохожу по всем ключам, что проверить, есть ли среди них те, которые я мог бы захотеть хранить, и, если есть, помещаю их в массив.
Если в этот архив есть попадания, я конкатинирую эти объекты и сохраняю их в поле search документа, используя функцию to_tsvector, являющуюся встроенной в Postgres, которая берет обычный текст и превращает его в индексируемые величины.
Вот и оно! Выполняя этот скрипт, мы получаем следующее:
Идеально — теперь я просто могу вставить это в конец моей save_document функции и оно будет вызываться транзакционно каждый раз, когда я что-то сохраняю:
create function save_document(tbl varchar, doc_string jsonb) returns jsonb as $$ var doc = JSON.parse(doc_string); var result = null; var id = doc.id; var exists = plv8.execute("select table_name from information_schema.tables where table_name = $1", tbl)[0]; if(!exists){ plv8.execute("select create_document_table('" + tbl + "');"); } if(id){ result = plv8.execute("update " + tbl + " set body=$1, updated_at = now() where id=$2 returning *;",doc_string,id); }else{ result = plv8.execute("insert into " + tbl + "(body) values($1) returning *;", doc_string); id = result[0].id; doc.id = id; result = plv8.execute("update " + tbl + " set body=$1 where id=$2 returning *",JSON.stringify(doc),id); } //run the search indexer plv8.execute("perform update_search($1, $2)", tbl,id); return result[0] ? result[0].body : null; $$ language plv8;
Сохранение многих документов
На данный момент, я могу передать единичный документ функции save_document, но я хотел бы иметь возможность передать ей массив. Я могу сделать это проверяя тип аргумента, после чего запускать цикл:
create function save_document(tbl varchar, doc_string jsonb) returns jsonb as $$ var doc = JSON.parse(doc_string); var exists = plv8.execute("select table_name from information_schema.tables where table_name = $1", tbl)[0]; if(!exists){ plv8.execute("select create_document_table('" + tbl + "');"); } //function that executes our SQL statement var executeSql = function(theDoc){ var result = null; var id = theDoc.id; var toSave = JSON.stringify(theDoc); if(id){ result=plv8.execute("update " + tbl + " set body=$1, updated_at = now() where id=$2 returning *;",toSave, id); }else{ result=plv8.execute("insert into " + tbl + "(body) values($1) returning *;", toSave); id = result[0].id; //put the id back on the document theDoc.id = id; //resave it result = plv8.execute("update " + tbl + " set body=$1 where id=$2 returning *;",JSON.stringify(theDoc),id); } plv8.execute("select update_search($1,$2)", tbl, id); return result ? result[0].body : null; } var out = null; //was an array passed in? if(doc instanceof Array){ for(var i = 0; i < doc.length;i++){ executeSql(doc[i]); } //just report back how many documents were saved out = JSON.stringify({count : i, success : true}); }else{ out = executeSql(doc); } return out; $$ language plv8;
Хорошая сторона работы здесь с javascript'ом заключается в том, что логика, необходимая для такой рутины, достаточно проста (в противоположность PLPGSQL). Я выделил весь процесс сохранения в его отдельную функцию — которая является javascript'ом после всего — таким образом я могу избежать дублирования.
Затем я хочу проверить, что подаваемый на вход аргумент — массив. Если это так, то я иду по его членам и вызываю executeSql, возвращая все, что накопилось при выполнении.
Если это не массив, я просто выполняю все так же, как и было, возвращая документ целиком. Результат:
Прекрасно! Лучшее в этом то, что это все происходит внутри транзакции. Мне это нравится!
Странности Node
Если бы только это могло работать идеально из Node! Я пробовал и в .NET, и в Node, с .NET все просто работает (странно) используя библиотеку Npgsql. Из Node, не то чтобы.
Короче говоря: node_pg драйвер делает очень странное преобразование, когда он видит объект массива в качестве входного параметра. Обратим внимание на следующее:
var pg = require("pg"); var run = function (sql, params, next) { pg.connect(args.connectionString, function (err, db, done) { //throw if there's a connection error assert.ok(err === null, err); db.query(sql, params, function (err, result) { //we have the results, release the connection done(); pg.end(); if(err){ next(err,null); }else{ next(null, result.rows); } }); }); }; run("select * from save_document($1, $2)", ['customer_docs', {name : "Larry"}], function(err,res){ //works just fine }
Это обычный Node/PG код. В самом конце, функция run настроена чтобы вызывать мою save_document функцию и передавать некоторые данные. Когда PG видит входной объект, он превращает его в строку и сохранение пройдет нормально.
В случае же, если послать массив…
run("select * from save_document($1, $2)", ['customer_docs', [{name : "Larry"}, {name : "Susie"}], function(err,res){ //crashes hard }
Я получаю обратно ошибку, сообщающую мне, что это некорректный JSON. Сообщение об ошибке (из Postgres) сообщит, что это связано со скудно отформатированным JSON:
{"{name : "Larry"}, ...}
Что… да, это ужасно. Я пытался сформулировать что происходит, но это просто-напросто выглядит так, что node_pg драйвер разбирает внешний массив — возможно вызывая метод flatten библиотеки Underscores. Я не знаю. Чтобы это обойти, вам необходимо изменить ваш вызов на следующее:
run("select * from save_document($1, $2)", ['customer_docs', JSON.stringify([{name : "Larry"}, {name : "Susie"}]), function(err,res){ //Works fine }
Вперед!
Процедура сохранения довольна гладкая и это меня радует. В следующей статье я настрою поисковики, а также создам функцию полнотекстового поиска.

