Введение
Когда-то давно я написал для себя ежедневник для ведения дел, заметок и фиксации движения по разным задачам. Сделан он был изначально на связке PHP + Kohana 2 + PostgreSQL. Со временем я переписал все на Yii (первой и тогда единственной версии). Для полнотекстового поиска был задействован встроенный в PostgreSQL движок tsearch2. Много лет я пользовался системой, понемногу ее развивал и пришел к тому, что объем текстов в ней накопился приличный. Поиском приходится пользоваться весьма часто и для повышения его удобства я задумал прикрутить к нему autocomplete из состава пакета JQuery UI.
Реализация
Чтобы все было правильно, выбор подсказок должен основываться на том же индексе, что и сам поиск. Все тексты у меня хранятся в отдельной таблице под названием «texts». Вот ее структура:
Table "public.texts" Column | Type | Modifiers -------------+-----------------------------+---------------------------------------------------------- txt_id | bigint | not null default nextval(('gen_txt_id'::text)::regclass) user_id | integer | not null txt | text | not null fti_txt | tsvector | last_update | timestamp without time zone | default now() format | textformat | default 'wiki'::textformat Indexes: "texts_pkey" PRIMARY KEY, btree (txt_id) "texts_txt_id_key" UNIQUE CONSTRAINT, btree (txt_id) "fti_texts_idx" gist (fti_txt) "last_update_idx" btree (last_update) "texts_uid_idx" btree (user_id)
Для реализации задачи формирования списка подсказок по текущей строке поиска был написан Action в виде отдельного, подключаемого действия. Исходник protected/extensions/actions/SearchAutocompleteAction.php:
<?php class SearchAutocompleteAction extends CAction { public $model; public $attribute; public $fts_field; public function run() { // Инициализируем переменные $_uid = Yii::app()->user->id; $_model = new $this->model; $_tableName = $_model->tableName(); // Разбиваем поисковый запрос на слова, отделяем от него последнее слово // и сохраняем отдельно это слово и остальной запрос $_query_array = explode(' ', trim(Yii::app()->db->quoteValue($_GET['term']), " '\t\n\r\0\x0B")); $_word = array_pop($_query_array); $_preQuery = implode(' ', $_query_array); $_suggestions = array(); /* * Запрос получения tsvector из нужных нам записей. Набор записей должен принадлежать текущему пользователю * и в него входят только записи, соответствующие первой части запроса (без последнего слова). */ $_sub_sql = "SELECT $this->fts_field FROM $_tableName WHERE user_id=''$_uid''"; if (count($_query_array) > 0) $_sub_sql .= " AND $this->fts_field @@ to_tsquery(''russian'', ''$_preQuery'')"; /* * Окончательный запрос, возвращающий список слов, для дополнения последнего слова запроса. * Используется функция ts_stat из tsearch2. Она возвращает список слов в записях, выбранных подзапросом выше, * отсортированный по убыванию частоты появления слов в текстах. Можно добавить в сортировку аттрибут ndoc, описывающий * количество документов, где встречается слово. */ $_sql = "SELECT word AS $this->attribute FROM ts_stat('$_sub_sql') WHERE word LIKE '$_word%' ORDER BY nentry DESC LIMIT 15;"; foreach(Yii::app()->db->createCommand($_sql)->query() as $_m) $_suggestions[] = count($_query_array) > 0 ? $_preQuery.' '.$_m[$this->attribute] : $_m[$this->attribute]; echo CJSON::encode($_suggestions); } }
Для разбора алгоритма действий привожу пример SQL запроса по строке поиска «привет хаб», формируемого Action-ом:
SELECT word AS txt FROM ts_stat('SELECT fti_txt FROM texts WHERE user_id=''1'' AND fti_txt @@ to_tsquery(''russian'', ''привет'')') WHERE word LIKE 'хаб%' ORDER BY nentry DESC LIMIT 15;
Суть работы tsearch2 в общем заключается в формировании записи типа tsvector в добавок к текстовой, в нашем примере это поле fti_txt. В нее записываются слова текста с указанием их позиций и числа их появления в тексте. По этой записи строится индекс (gin или gist) и в дальнейшем выполняется поиск. Для отладки и мониторинга состояния индекса в tsearch2 есть функция ts_stat. В качестве параметра она принимает текст SQL запроса, возвращающего набор полей типа tsvector. По этому набору строится статистика в виде списка слов с указанием количества вхождений (nentry) и количества документов (записей) где слово встречается (ndoc).
В моем примере если слово в поисковом запросе одно — выполняется поиск похожих на него во всех записях пользователя. Если слов в запросе несколько — последнее слово изымается из запроса, набор записей ограничивается полнотекстовым поиском по первой части запроса (без последнего слова).
Подключение к проекту
Эта часть является Yii 1 специфичной, никакой магии тут нет. Приводится для целостности заметки. Всего будет два шага. Шаг первый — подключение Action-а к контроллеру, в моем случае DiaryController. Для этого в его метод actions() добавляем строки:
public function actions() { return array( ... 'acsearch' => array( 'class' => 'application.extensions.actions.SearchAutocompleteAction', 'model' => 'Texts', 'attribute' => 'txt', 'fts_field' => 'fti_txt', ), ... ); }
Теперь в соответствующем view заменяем старое текстовое поле поиска:
<?php echo CHtml::textField('sh', $search->sh, array('size' => 60,'maxlength' => 255)); ?>
на JQuery UI виджет:
<?php $this->widget('zii.widgets.jui.CJuiAutoComplete', array( 'attribute'=> 'sh', 'sourceUrl' => array('acsearch'), 'name' => 'sh', 'value' => $search->sh, 'options' => array( 'minLength' => '2', ), 'htmlOptions' => array( 'size' => 60, 'maxlength' => 255, ), )); ?>
В результате получим нечто, похожее на картинку:
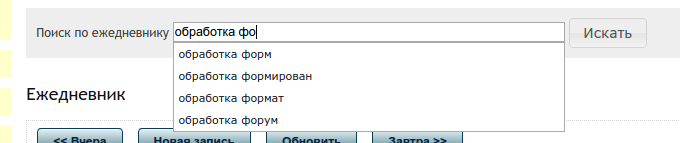
Недостатки
У всей системы есть один крупный недостаток — слова в поле типа tsvector записываются после стемминга. Проще говоря у большинства слов «отрезаются» окончания для учета в поиске их различных форм. Посмотрите на картинку выше и обратите внимание на слово «формирован». Таким образом данное решение применимо в проектах для личного/внутреннего использования. Без решения данной проблемы показывать такое людям нельзя. Возможно у кого-нибудь найдется достойное решение или хотя бы мысль. Добро пожаловать в комментарии.

