
В первой части этой серии статей вы узнали о данных и о том, как можно использовать компьютеры чтобы добывать смысловое значение из крупных блоков таких данных. Вы даже видели что-то похожее на большие данные у Amazon.com середины девяностых, когда компания запустила технологию для наблюдения и записи в реальном времени всего, что многотысячная аудитория клиентов одновременно делала на их сайте. Довольно впечатляюще, но назвать это большими данными можно с натяжкой, пухлые данные — больше подойдёт. Организации вроде Агентства национальной безопасности США (NSA) и Центра правительственной связи Великобритании (GCHQ) уже собирали большие данные в то время в рамках шпионских операций, записывая цифровые сообщения, хотя у них и не было простого способа расшифровать их и найти в них смысл. Библиотеки правительственных записей были переполнены наборами бессвязных данных.
То, что сделал Amazon.com, было проще. Уровень удовлетворённости их клиентов мог быть легко определен, даже если он охватывал все десятки тысяч продуктов и миллионы потребителей. Действий, которые клиент может совершить в магазине, реальный он или виртуальный, не так уж много. Клиент может посмотреть что в доступе, запросить дополнительную информацию, сравнить продукты, положить что-то в корзину, купить или уйти. Всё это было в пределах возможностей реляционных баз данных, где отношения между всеми видами действий возможно задать заранее. И они должны быть заданы заранее, с чем у реляционных баз данных проблема — они не так легко расширяемы.
Заранее знать структуру такой базы данных — как составить список всех потенциальных друзей вашего неродившегося ребенка… на всю жизнь. В нём должны быть перечислены все неродившиеся друзья, потому что как только список будет составлен, любое добавление новой позиции потребует серьезного хирургического вмешательства.
Поиск связей и закономерностей в данных требует более гибких технологий.
Первая крупная технологическая задача интернета 90-х — справляться с неструктурированными данными. Простыми словами — с данными, которые окружают нас ежедневно и раньше не рассматривались как что-то, что можно хранить в виде базы данных. Вторая задача — очень дешёвая обработка таких данных, поскольку их объём был высоким, а информационный выхлоп — низким.
Если вам нужно прослушать миллион телефонных разговоров в надежде засечь хотя бы одно упоминание Аль-Каиды, вам потребуется либо весомый бюджет, либо новый, очень дешевый способ обработки всех этих данных.
Коммерческий интернет тогда имел две очень схожие задачи: поиск всякой всячины во Всемирной паутине и плата рекламой за возможность что-то найти.
 Задача поиска. К 1998 году общее число веб-сайтов достигло 30 миллионов (сегодня их более двух миллиардов). 30 миллионов мест, каждое из которых содержит множество веб-страниц. Pbs.org, например, это сайт, содержащий более 30 000 страниц. Каждая страница содержит сотни или тысячи слов, изображений и информационных блоков. Чтобы что-то найти в вебе, нужно было проиндексировать весь интернет. Вот это уже большие данные!
Задача поиска. К 1998 году общее число веб-сайтов достигло 30 миллионов (сегодня их более двух миллиардов). 30 миллионов мест, каждое из которых содержит множество веб-страниц. Pbs.org, например, это сайт, содержащий более 30 000 страниц. Каждая страница содержит сотни или тысячи слов, изображений и информационных блоков. Чтобы что-то найти в вебе, нужно было проиндексировать весь интернет. Вот это уже большие данные!
Для индексации сначала нужно было прочитать весь веб, все 30 миллионов хостов в 1998 году или 2 миллиарда сегодня. Это сделали с помощью так называемых пауков (spiders) или поисковых роботов — компьютерных программ, которые методично ищут в Интернете новые веб-страницы, читают их, а затем копируют и перетаскивают обратно в индекс их содержимое. Все поисковые системы используют поисковых роботов, и они должны работать непрерывно: обновлять индекс, содержать его в актуальном состоянии с появлением новых веб-страниц, их изменением или исчезновением. Большинство поисковых систем поддерживает индекс не только текущего веба, но, как правило, и всех старых версий, так что при поиске более ранних модификаций можно вернуться в прошлое.
Индексация означает запись всех метаданных — данных о данных — слов, изображений, ссылок и других типов данных, таких как видео или аудио, встроенных в страницу. Теперь умножьте это на стопятьсот миллионов. Мы делаем это потому, что индекс занимает примерно один процент объёма сервера, который он представляет — эквивалент 300 тысяч страниц данных из 30 миллионов в 1998 году. Но индексация — это не поиск информации, а только запись метаданных. Поиск полезной информации из индекса еще сложнее.
В первое десятилетие интернета существовали десятки поисковых систем, но четыре были наиболее важными, и каждая имела свой технический подход по получению смыслового значения из их всех этих страниц. Альта-Виста была первым реальным поисковиком. Она появилась в лаборатории Digital Equipment Corporation, в Пало-Альто. Digital Equipment Corporation на самом деле была лабораторией информатики в XEROX PARC, перевезённой почти в полном объеме на расстояние двух миль Бобом Тейлором, который построил их обе и нанял большинство старых сотрудников.
 Альта-Виста использовала лингвистический инструмент для поиска по своему веб-индексу. А индексировала она все слова в документе, например, в веб-странице. Если вы давали ему запрос "поиск золотых дублонов", Альта-Виста сканировала свой индекс на наличие документов, содержащих слова "поиск", "золотых" и "дублонов", и выводила список страниц, упорядоченных по количеству упоминаний запрошенных слов.
Альта-Виста использовала лингвистический инструмент для поиска по своему веб-индексу. А индексировала она все слова в документе, например, в веб-странице. Если вы давали ему запрос "поиск золотых дублонов", Альта-Виста сканировала свой индекс на наличие документов, содержащих слова "поиск", "золотых" и "дублонов", и выводила список страниц, упорядоченных по количеству упоминаний запрошенных слов.
Но даже тогда дерьма в интернете было много, а значит Альта-Виста, индексировала всё это дерьмо и не умела отличать хорошее от плохого. Это были всего лишь слова, в конце концов. Естественно, плохие документы часто поднимались наверх, а систему было легко надуть, вставляя скрытые слова чтобы исказить поиск. Альта-Виста не могла отличить реальные слова от скрытых.
 В то время, как преимуществом Альта-Висты было использование мощных компьютеров DEC (что было важным моментом, так как DEC были ведущими производителями компьютерной техники), преимуществом Yahoo! было использование людей. Компания нанимала работников для того, чтобы они весь день буквально просматривали веб-страницы, индексировали их вручную (и не очень тщательно), а потом отмечали самые интересные по каждой теме. Если у вас есть тысяча человеко-индексаторов и каждый может индексировать 100 страниц в день, то Yahoo могла индексировать 100 000 страниц в день или около 30 миллионов в год — вся вселенная интернета в 1998. Это работало на ура во Всемирной паутине, пока веб не разросся до межгалактических масштабов и стал неподвластен Yahoo. Ранняя система Yahoo с их человеческими ресурсами не масштабировалась.
В то время, как преимуществом Альта-Висты было использование мощных компьютеров DEC (что было важным моментом, так как DEC были ведущими производителями компьютерной техники), преимуществом Yahoo! было использование людей. Компания нанимала работников для того, чтобы они весь день буквально просматривали веб-страницы, индексировали их вручную (и не очень тщательно), а потом отмечали самые интересные по каждой теме. Если у вас есть тысяча человеко-индексаторов и каждый может индексировать 100 страниц в день, то Yahoo могла индексировать 100 000 страниц в день или около 30 миллионов в год — вся вселенная интернета в 1998. Это работало на ура во Всемирной паутине, пока веб не разросся до межгалактических масштабов и стал неподвластен Yahoo. Ранняя система Yahoo с их человеческими ресурсами не масштабировалась.
 Вскоре появился Excite, он был основан на лингвистическом трюке. Трюк в том, что система искала не то, что человек написал, а то, что ему реально было нужно, потому что не каждый мог точно сформулировать запрос. Опять же, эта задача сформировалась в условиях дефицита вычислительных возможностей (это главный момент).
Вскоре появился Excite, он был основан на лингвистическом трюке. Трюк в том, что система искала не то, что человек написал, а то, что ему реально было нужно, потому что не каждый мог точно сформулировать запрос. Опять же, эта задача сформировалась в условиях дефицита вычислительных возможностей (это главный момент).
Excite использовал тот же индекс, что и Альта-Виста, но вместо того, чтобы подсчитывать как часто встречаются слова "золотой" или "дублон", шесть работников Excite использовали подход, основанный на геометрии векторов, где каждый запрос определялся как вектор, состоящий из условий запросов и их частоты. Вектор — это просто стрелка в пространстве, с начальной точкой, направлением и длиной. Во вселенной Excite начальной точкой было полное отсутствие искомых слов (ноль "поиск," ноль "золотых" и ноль "дублонов"). Сам поисковый вектор начинался из точки ноль-ноль-ноль с этими тремя поисковыми условиями, а затем расширялся, скажем, до двух единиц "поиск", потому что столько раз слово "поиск" встречалось в целевом документе, тринадцать единиц "золотых" и может быть, пять — "дублонов". Это был новый способ индексирования индекса и лучший способ для описания хранимых данных, так как время от времени он приводил к результатам, которые не использовали ни одно из искомых слов напрямую — то, чего Альта-Виста не смогла сделать.
Веб-индекс Excite не был просто списком слов и частоты их использования, он был многомерным векторным пространством, в котором поиск рассматривался как направление. Каждый поиск был одной колючкой в еже данных и гениальной стратегией Excite (гением Грэма Спенсера) было захватить не одну, а все колючки по соседству. Охватывая не только полностью соответствовавшие условиям запроса документы (как Альта-Виста), но и все похожие по сформулированным условиям в многомерном векторном пространстве, Excite был более полезным инструментом поиска. Он работал по индексу, для обработки использовал математику векторов и, что более важно, почти не требовал вычислений для получения результата, поскольку вычисления уже были сделаны в процессе индексации. Excite давал результаты лучше и быстрее, используя примитивное железо.
Но Google был еще лучше.
 Google внёс два усовершенствования в поиск — PageRank и дешёвое железо.
Google внёс два усовершенствования в поиск — PageRank и дешёвое железо.
Продвинутый векторный подход Excite помогал выводить нужные искомые результаты, но даже его результаты часто были бесполезны. Ларри Пейдж из Google придумал способ оценки полезности с помощью идеи, основанной на доверии, который приводил к большей точности. Поиск Google в начале использовал лингвистические методы, подобные Альта-Виста, но затем добавил дополнительный фильтр PageRank (названо в честь Ларри Пейджа, заметили?), который обращался к первым результатам и выстраивал их по количеству страниц, с которым они были связаны.  Идея заключалась в том, что чем больше авторов страниц заморачивалось дать ссылку на данную страницу, тем более полезной (или, по крайней мере, интересной, пусть даже в плохом смысле) была страница. И они были правы. Другие подходы стали отмирать, а Google быстро вышел в тренд со своим патентом PageRank.
Идея заключалась в том, что чем больше авторов страниц заморачивалось дать ссылку на данную страницу, тем более полезной (или, по крайней мере, интересной, пусть даже в плохом смысле) была страница. И они были правы. Другие подходы стали отмирать, а Google быстро вышел в тренд со своим патентом PageRank.
 Но была еще одна деталь, которую Google реализовал иначе. Альта-Виста появилась из Digital Equipment и работала на огромном кластере миникомпьютеров VAX от DEC. Excite использовал не уступающее им по мощности железо UNIX от Sun Microsystems. А Google запускался всего лишь с помощью свободного программного обеспечения, с открытым исходным кодом, на компьютерах чуть более мощных, чем персональные. А вообще, они были меньше, чем ПК, потому что у самодельных компьютеров Google не было ни корпусов, ни источников питания (они питались, буквально, от автомобильных аккумуляторов и заряжались от автомобильных зарядных устройств). Первые модификации были прикручены к стенам, а позже ими фаршировали стеллажи, как противнями со свежей выпечкой в промышленных печах.
Но была еще одна деталь, которую Google реализовал иначе. Альта-Виста появилась из Digital Equipment и работала на огромном кластере миникомпьютеров VAX от DEC. Excite использовал не уступающее им по мощности железо UNIX от Sun Microsystems. А Google запускался всего лишь с помощью свободного программного обеспечения, с открытым исходным кодом, на компьютерах чуть более мощных, чем персональные. А вообще, они были меньше, чем ПК, потому что у самодельных компьютеров Google не было ни корпусов, ни источников питания (они питались, буквально, от автомобильных аккумуляторов и заряжались от автомобильных зарядных устройств). Первые модификации были прикручены к стенам, а позже ими фаршировали стеллажи, как противнями со свежей выпечкой в промышленных печах.
Amazon создал бизнес-кейс для больших данных и разработал неуклюжий способ реализовать его на железе и софте, ещё не приспособленных для больших данных. Поисковые компании сильно расширили размер практических наборов данных, пока осваивали индексацию. Но настоящие большие данные не могли работать с помощью индекса, им были нужны фактические данные, а для этого требовались либо очень крупные и дорогие компьютеры, как в Amazon, или способ использовать дешевые ПК, которые выглядят как гигантский компьютер в Google.
Пузырь доткомов. Давайте представим эйфорию и ребячество интернета конца 1990-х годов в период так называемого пузыря доткомов. Всем было ясно, начиная от Билла Гейтса, что будущим персональных компьютеров и, возможно, бизнеса был интернет. Поэтому венчурные капиталисты инвестировали миллиарды долларов в интернет-стартапы, не сильно задумываясь над тем, как эти компании на самом деле будут зарабатывать деньги.
Интернет рассматривался как гигантская территория, где было важно создавать настолько крупные компании, насколько возможно, настолько быстро, насколько возможно, и захватывать и сохранять долю в бизнесе независимо от того, есть у компании прибыль или нет. Впервые в истории компании стали выходить на фондовый рынок, не заработав ни копейки прибыли за всё время их существования. Но это воспринималось как норма — прибыль появится в процессе.
Результатом всего этого иррационального изобилия было возрождение идей, большинство из которых не реализовалось бы в другие времена. Broadcast.com, например, задумывался для транслирования телевидения через dial-up на огромную аудиторию. Идея не сработала, но Yahoo! все-таки купил его за $5,7 миллиардов в 1999 году, что сделало Марка Кубана миллиардером, которым он и сегодня остаётся.
Мы считаем, что Кремниевая долина построена по закону Мура, благодаря чему компьютеры постоянно дешевели и становились более мощными, но эра доткомов только притворялась, что использовала этот закон. На самом деле она строилась на шумихе.
Шумиха и закон Мура. Чтобы многие из этих махинаций интернета 90-х могли преуспеть, стоимость обработки данных должна была сильно упасть ниже той, что была возможна в реальности, согласно закону Мура. Всё потому, что бизнес-модель большинства доткомовских стартапов была основана на рекламе, и у суммы, которую рекламодатели были готовы заплатить, был строгий лимит.
Какое-то время это не имело значения, потому что венчурные капиталисты, а затем инвесторы с Уолл-стрит были готовы компенсировать разницу, но в конце концов стало очевидным, что Альта-Виста с его огромными центрами обработки данных не сможет получать прибыль только от поиска. Как и Excite, и любой другой поисковик того времени.
Доткомы в 2001 развалились из-за того, что у стартапов закончились деньги доверчивых инвесторов, поддерживавших их рекламные компании на Суперкубке. Когда последний доллар последнего дурака был потрачен на последнее офисное кресло от Herman Miller, почти все инвесторы уже продали свои доли и ушли. Тысячи компаний рухнули, некоторые из них за ночь. Amazon, Google и несколько других выжили благодаря тому, что поняли как зарабатывать деньги в интернете.
Amazon.com отличался тем, что бизнес Джеффа Безоса был электронной коммерцией. И это был новый вид торговли, который должен был заменить кирпичи электронами. Для Amazon экономия на недвижимости и зарплате сыграли большую роль, так как прибыль компании измеряется в долларах за одну транзакцию. А для поисковика — первого применения больших данных и реального инструмента интернета — рекламный рынок окупался стоимостью меньше цента за транзакцию. Единственным способом осуществить такое было понять, как нарушить закон Мура и сильнее снизить стоимость обработки данных, и в то же время связать поисковик с рекламой и увеличить этим продажи. Google справился с обеими задачами.
Пришло время для Второго Чудесного Пришествия больших данных, которое полностью объясняет, почему Google сегодня стоит $479 миллиардов, а большинство остальных поисковых компаний давно мертвы.
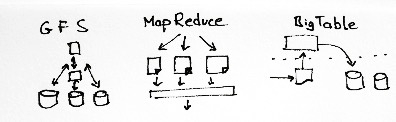
GFS, Map Reduce и BigTable. Поскольку Пейдж и Брин были первыми, кто понял, что создавать собственные супер-дешевые серверы — это ключ к выживанию компании, Google пришлось построить новую инфраструктуру обработки данных, чтобы заставить тысячи дешевых ПК выглядеть и работать как один суперкомпьютер.
Когда другие компании, кажется, свыклись с убытками в надежде на то, что закон Мура в какой-то момент сработает и превратит их в прибыльные, Google нашел способ сделать прибыльным свой поисковик уже в конце 90-х. Сюда входило изобретение новых машинных, программных и рекламных технологий. Деятельность Google в этих областях непосредственно и привела нас в мир тех больших данных, формирование которого можно наблюдать сегодня.
Давайте вначале взглянем на масштабы сегодняшнего Google. Когда вы ищете что-то через их поисковик, вы сначала взаимодействуете с тремя миллионами веб-серверов в сотнях центров обработки данных по всему миру. Всё, что делают эти серверы — посылают образы страниц на экран вашего компьютера, в среднем, 12 миллиардов страниц в день. Веб-индекс хранится дополнительно на двух миллионах серверов, а еще три миллиона серверов содержат фактические документы, объединённые в систему. Всё вместе — восемь миллионов серверов, без учёта YouTube.
Три ключевых компонента в "копеечной" архитектуре Google, это их файловая система или GFS, которая позволяет всем этим миллионам серверов обращаться к тому, что они считают обычной памятью. Конечно, это не просто память, а её дроблёные копии, называемые фрагментами, но вся фишка в их общности. Если изменить файл, он должен быть изменен на всех серверах одновременно, даже на тех, которые находятся за тысячи километров друг от друга.
Получается, огромная проблема для Google — это скорость света.
MapReduce распределяет крупную задачу по сотням или тысячам серверов. Он отдаёт задачу нескольким серверам, а затем собирает множество их ответов в один.
BigTable — это база данных компании Google, которая содержит все данные. Она не реляционная, потому что реляционная не сможет работать в таком масштабе. Это старомодная плоская база данных, которая, как и GFS, должна быть когерентной.
Перед тем, как были разработаны эти технологии, компьютеры функционировали как люди, работая над одной задачей с ограниченным количеством информации в один момент времени. Возможность заставить тысячи компьютеров выполнять совместную работу над огромным объемом данных стала мощным прорывом.
Но Google для достижения своих финансовых целей этого было недостаточно.
 Большой брат начинал как рекламщик. Google было достаточно просто сделать обработку данных дешевле, чтобы приблизиться к размерам прибыли Amazon.com. Оставшуюся разницу между центом и долларом за транзакцию можно было покрыть, если найти более прибыльный способ продажи интернет-рекламы. Google это сделал через эффективную индексацию пользователей, как ранее он это сделал с интернетом.
Большой брат начинал как рекламщик. Google было достаточно просто сделать обработку данных дешевле, чтобы приблизиться к размерам прибыли Amazon.com. Оставшуюся разницу между центом и долларом за транзакцию можно было покрыть, если найти более прибыльный способ продажи интернет-рекламы. Google это сделал через эффективную индексацию пользователей, как ранее он это сделал с интернетом.
Изучая наше поведение и предвидя наши потребительские потребности, Google предлагал нам рекламу, по которой мы бы кликнули с вероятностью в 10 или 100 раз больше, что увеличивало вероятный доход Google с такого клика в 10 или 100 раз.
Теперь мы, наконец, говорим в масштабах больших данных.
Работали ли инструменты Googlе с внутренним или внешним миром — не важно, все работало одинаково. И в отличие от системы SABRE, например, это были инструменты общего назначения — они могли быть использованы практически для любого рода задачи, применены к почти любому виду данных.
GFS и MapReduce первыми не накладывали никаких ограничений на размер базы данных или масштабируемость поиска. Все, что было нужно — это больше усреднённого железа, которое постепенно привело бы к миллионам дешевых серверов, делящих задачу между собой. Google постоянно добавляет серверы в свою сеть, но делает это разумно, потому что, если только центр обработки данных не отключится целиком, серверы после поломки не заменят. Это слишком сложно. Их просто оставят мертвыми в стойках, а MapReduce будет заниматься обработкой данных, избегая нерабочие серверы и используя действующие поблизости.
Google опубликовал статью о GFS в 2003 году и о MapReduce в 2004. Один из волшебных моментов этого бизнеса: они даже не пытались хранить в тайне свои методы, хотя, вполне вероятно, что остальные когда-нибудь дошли бы до подобных решений сами.
Yahoo!, Facebook и другие быстро воспроизвели открытую версию Map Reduce, которая называется Hadoop (в честь игрушечного слона — слоны ничего не забывают). Это и позволило появиться тому, что мы сегодня называем облачными вычислениями. Это просто платная услуга: распределение вашей задачи между десятками или сотнями арендованных компьютеров, иногда арендованных на несколько секунд, а затем объединение нескольких ответов в одно логически связанное решение.
Большие данные превратили облачные вычисления в необходимость. Сегодня трудно их разделить эти два понятия.
Не только большие данные, но и социальные сети стали возможными благодаря MapReduce и Hadoop, поскольку они сделали экономически обоснованным возможность миллиарду пользователей Facebook создавать свои динамические веб-страницы бесплатно, а компании получать прибыль только от рекламы.
Даже Amazon перешел на Hadoop, и сегодня нет практически никаких ограничений для роста их сети.
Amazon, Facebook, Google и NSA не могут функционировать сегодня без MapReduce или Hadoop, которые, кстати, навсегда уничтожили необходимость индекса. Поиск сегодня производится не по индексу, а по сырым данным, которые меняются от минуты к минуте. Точнее, индекс обновляется от минуты к минуте. Не суть важно.
Благодаря этим инструментам Amazon и другие компании предоставляют услуги облачных вычислений. Вооруженные только кредитной картой умные программисты могут в пределах нескольких минут использовать мощность одного, тысячи или десяти тысяч компьютеров, и применить их для решения какой-нибудь задачи. Именно поэтому интернет-стартапы больше не покупают серверы. Если хотите ненадолго заполучить вычислительные ресурсы более крупные, чем у всей России, вам понадобится лишь карта для оплаты.
Если Россия захочет заполучить больше вычислительных ресурсов, чем у России, она тоже может воспользоваться своей пластиковой картой.
Большой вопрос без ответа: почему Google поделился своими секретами с конкурентами и сделал публичными свои исследования? Было ли это глупым высокомерием со стороны основателей Google, которые в то время ещё защищали докторские диссертации в Стенфорде? Нет. Google поделился своими секретами, чтобы создать отрасль. Ему было нужно не выглядеть в глазах конкурентов монополией. Но что еще более важно, позволяя тысячам других цветов зацвести, Google способствовал росту интернет-индустрии, чем увеличил свой доход на 30-40 процентов.
Поделившись своими секретами, Google получил меньший кусок большего пирога.
Вот так, в двух словах, и появились Большие Данные. Google отслеживает каждый ваш щелчок мышью, и миллиард или больше щелчков других людей. Так же и Facebook, и Amazon, когда вы находитесь на их сайте или пользуетесь Amazon Web Services на любом другом сайте. А они охватывают треть обработки данных всего интернета.
Задумайтесь на минуту, какое значение это имеет для общества. Если в прошлом бизнесы использовали маркетинговые исследования и думали, как продать товары потребителям, то теперь они могут использовать большие данные чтобы знать о ваших желаниях и о том, как вам продать это. Именно поэтому я продолжительное время видел объявления в интернете о дорогих эспрессо-машинах. А когда я наконец-то купил ее, реклама почти мгновенно прекратилась, потому что система узнала о моём приобретении. Она перешла к попытке продать мне кофейные зерна и, почему-то, подгузники для взрослых.
Когда-то у Google будет сервер на каждого интернет-пользователя. Они и другие компании будут собирать больше типов данных о нас и лучше предсказывать наше поведение. К чему это приведёт, зависит от того, кто будет пользоваться этими данными. Это может превратить нас в идеальных потребителей или пойманных террористов (или в более успешных террористов — это еще один аргумент).
Нет задачи, которая была бы непреодолимо большой.
И в первый раз, благодаря Google, у NSA и GCHQ, наконец, есть инструменты поиска по хранимым данным разведки, и они могут отыскать всех нехороших ребят. Или, может быть, навсегда поработить нас.
(Перевод Наталии Басс)

