Всем привет и хорошего дня. 30 августа HPE официально анонсировали выход новой версии Вертики. Можно отметить, что продукт уже достиг той поры зрелости, когда вместо огромного перечня новой функциональности на первом месте присутствует расширение и оптимизация существующей. Так же четко наблюдается плотная интеграция с продуктами и сервисами в определенных направлениях.
Что же я имею ввиду?

Во-первых, это интеграция с MS Azure Cloud. Это позволит использовать Вертику в облаках MS. В последнее время я вижу большой задел дружбы HPE и MS. Помимо Azure, для Вертики расширили поддержку VS Studio и улучшили работу драйверов под ADO.NET.
Меня дружба между Вертикой и MS определенно радует, надеюсь она будет развиваться дальше.

Во-вторых, Вертика продолжает тесно вгрызаться в мир Hadoop-а. Если в более ранних версиях, Вертика могла только загружать данные с HDFS определенных форматов, то постепенно она научилась работать со всеми форматами файлов, таких как ORC и Parquet, подключать файлы как внешние таблицы, а потом и хранить свои данные в ROS контейнерах прямо на HDFS.
В новой версии была проведена значительная оптимизация скорости работы с HDFS, каталогом метаданных и парсингом этих форматов.
Мне кажется, чтобы Вертика могла стать частью Hadoop среды, этого мало. Именно поэтому в новой версии добавили новый тип лицензирования Вертики… по количеству нод хадупа и возможность строить кластер Вертики прямо на Hadoop кластере.
Как это выглядит:
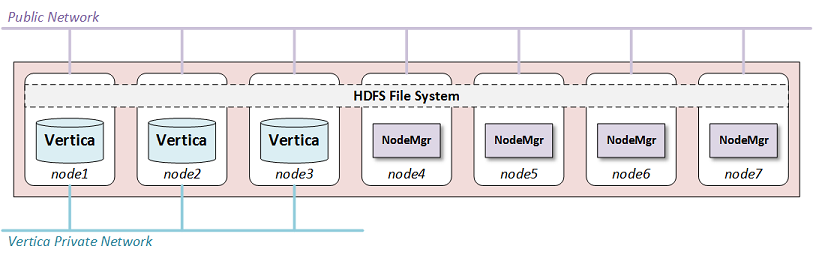
Идея состоит в том, что Вертика работает прямо в кластере Hadoop, имеет прямой доступ к данным на HDFS и так же хранит свои данные на HDFS. Лицензируется в таком случае кластер Вертики по количеству нод. Менеджеры HPE обещают, что стоимость лицензии будет вкуснее, однако пока мне цена лицензии не известна. Так что поживем, увидим.

Где Hadoop, там и Spark. В новой версии добавлена полноценная поддержка работы с Spark. Можно копировать данные из Спарка в таблицы Вертики, можно обратно из Вертики переносить данные в Спарк.

Интеграция с Apache Kafka уже была добавлена с версии 7.2. Однако выяснилось, что есть множество проблем, которые мешают полноценной работе коннектора Вертики с Кафкой. В 8 версии выложены обновленные версии библиотек работы с Кафкой. Я искренне надеюсь, что они закроют все найденные проблемы и народ перестанет открывать кейсы.

Поддержка машинного обучения появилась еще в версии 7.2. Однако оно было «сбоку» — лежало отдельной библиотекой и не интегрировалось полностью с метаданными Вертики. Видимо «тема пошла», так как в новой версии Machine Learning уже сразу интегрируется в сервер, доступно после инсталляции, наравне со всеми полноценно присутствует в слое метаданных, а функции входят в состав стандартных. Пожелаем же Вертике и дальше развиваться и обучаться в этом несомненно перспективном направлении.

Фишечек на удивление мало. Видимо фантазия инженеров Вертики наконец то выдохлась. С точки зрения оптимистов, наверное это не плохо — меньше новых фишечек, меньше багов.
Но все равно в новой версии появились такие интересные вещи, как:
• Функция копирования таблиц COPY_TABLE, которая позволяет зашарить данные одной таблице как часть в другой. Что интересно, потом при изменении данных у каждой таблицы появится разный набор данных. Достигается это за счет общего использования ROS контейнеров между 2 таблицами. Что не менее интересно, для лицензии Вертика посчитает объем для каждой таблицы, даже если данные у обеих таблиц физически хранятся только один раз.
• Для SELECT в секции FROM добавлено ключевое слово TABLESAMPLE, которое позволит вернуть указанный процент части данных в случайном порядке записей.
• Параметр IDLESESSIONTIMEOUT позволит отстреливать сессии, которые долго висят и ничего не делают. Давно мечтал о таком параметре.
• Выпущена новая версия Python API для доступа к Вертике. Это всегда приятно, народу на Питоне работает с Вертикой много.
• Добавлена поддержка мульти язычности для Text Search. Заявляют, что поддерживают разбор текстов даже на азиатских языках. Надеюсь кириллицу они тоже смогли победить.
Как и я писал в начале, могу тоже самое написать и в окончание моей статьи — поступательное движение наблюдается в основном на интеграцию с облаками и сервисами. Хочется более подробно узнать про лицензирование «Vertica on Hadoop». Мне кажется это интересным вариантом для задач, где первичная информация собирается на Hadoop, перемалывается и далее загружается в сервер Vertica для дальнейшей работы с помощью его аналитических функций и машинного обучения.
P.S. Очень приятно, что название новой версии FrontLoader созвучно названию нашего продукта доставки данных в Вертику EasyLoader. И не менее приятно, что именно сейчас, когда мы учим наш EasyLoader управлять загрузкой данных между HFDS и Vertica, восьмая версия расширила применение Вертики на Хадупе. Так сказать, вовремя.
Что же я имею ввиду?
Облака
Во-первых, это интеграция с MS Azure Cloud. Это позволит использовать Вертику в облаках MS. В последнее время я вижу большой задел дружбы HPE и MS. Помимо Azure, для Вертики расширили поддержку VS Studio и улучшили работу драйверов под ADO.NET.
Меня дружба между Вертикой и MS определенно радует, надеюсь она будет развиваться дальше.
Джунгли
Во-вторых, Вертика продолжает тесно вгрызаться в мир Hadoop-а. Если в более ранних версиях, Вертика могла только загружать данные с HDFS определенных форматов, то постепенно она научилась работать со всеми форматами файлов, таких как ORC и Parquet, подключать файлы как внешние таблицы, а потом и хранить свои данные в ROS контейнерах прямо на HDFS.
В новой версии была проведена значительная оптимизация скорости работы с HDFS, каталогом метаданных и парсингом этих форматов.
Мне кажется, чтобы Вертика могла стать частью Hadoop среды, этого мало. Именно поэтому в новой версии добавили новый тип лицензирования Вертики… по количеству нод хадупа и возможность строить кластер Вертики прямо на Hadoop кластере.
Как это выглядит:
Идея состоит в том, что Вертика работает прямо в кластере Hadoop, имеет прямой доступ к данным на HDFS и так же хранит свои данные на HDFS. Лицензируется в таком случае кластер Вертики по количеству нод. Менеджеры HPE обещают, что стоимость лицензии будет вкуснее, однако пока мне цена лицензии не известна. Так что поживем, увидим.
Где Hadoop, там и Spark. В новой версии добавлена полноценная поддержка работы с Spark. Можно копировать данные из Спарка в таблицы Вертики, можно обратно из Вертики переносить данные в Спарк.
Интеграция с Apache Kafka уже была добавлена с версии 7.2. Однако выяснилось, что есть множество проблем, которые мешают полноценной работе коннектора Вертики с Кафкой. В 8 версии выложены обновленные версии библиотек работы с Кафкой. Я искренне надеюсь, что они закроют все найденные проблемы и народ перестанет открывать кейсы.
Машинное обучение
Поддержка машинного обучения появилась еще в версии 7.2. Однако оно было «сбоку» — лежало отдельной библиотекой и не интегрировалось полностью с метаданными Вертики. Видимо «тема пошла», так как в новой версии Machine Learning уже сразу интегрируется в сервер, доступно после инсталляции, наравне со всеми полноценно присутствует в слое метаданных, а функции входят в состав стандартных. Пожелаем же Вертике и дальше развиваться и обучаться в этом несомненно перспективном направлении.
Всякие фишечки
Фишечек на удивление мало. Видимо фантазия инженеров Вертики наконец то выдохлась. С точки зрения оптимистов, наверное это не плохо — меньше новых фишечек, меньше багов.
Но все равно в новой версии появились такие интересные вещи, как:
• Функция копирования таблиц COPY_TABLE, которая позволяет зашарить данные одной таблице как часть в другой. Что интересно, потом при изменении данных у каждой таблицы появится разный набор данных. Достигается это за счет общего использования ROS контейнеров между 2 таблицами. Что не менее интересно, для лицензии Вертика посчитает объем для каждой таблицы, даже если данные у обеих таблиц физически хранятся только один раз.
• Для SELECT в секции FROM добавлено ключевое слово TABLESAMPLE, которое позволит вернуть указанный процент части данных в случайном порядке записей.
• Параметр IDLESESSIONTIMEOUT позволит отстреливать сессии, которые долго висят и ничего не делают. Давно мечтал о таком параметре.
• Выпущена новая версия Python API для доступа к Вертике. Это всегда приятно, народу на Питоне работает с Вертикой много.
• Добавлена поддержка мульти язычности для Text Search. Заявляют, что поддерживают разбор текстов даже на азиатских языках. Надеюсь кириллицу они тоже смогли победить.
В заключение
Как и я писал в начале, могу тоже самое написать и в окончание моей статьи — поступательное движение наблюдается в основном на интеграцию с облаками и сервисами. Хочется более подробно узнать про лицензирование «Vertica on Hadoop». Мне кажется это интересным вариантом для задач, где первичная информация собирается на Hadoop, перемалывается и далее загружается в сервер Vertica для дальнейшей работы с помощью его аналитических функций и машинного обучения.
P.S. Очень приятно, что название новой версии FrontLoader созвучно названию нашего продукта доставки данных в Вертику EasyLoader. И не менее приятно, что именно сейчас, когда мы учим наш EasyLoader управлять загрузкой данных между HFDS и Vertica, восьмая версия расширила применение Вертики на Хадупе. Так сказать, вовремя.

