Настраивая postgresql.conf, Вы могли заметить, что там есть параметр full_page_writes. Имеющийся рядом с ним комментарий гласит что-то о частичной записи страниц и люди, как правило, оставляют его в состоянии on — что не плохо, это я и объясню далее в данной статье. Тем не менее, очень полезно понимать что full_page_writes делает, так как влияние на работы системы может быть значительным.
В отличие от моего прошлого поста про настройку чекпоинтов, этот не является пособием о том, как надо настраивать сервер. Здесь не так много всего того, что Вы могли бы настроить, на самом деле, но я покажу Вам как некоторые решения на уровне приложения (к примеру, выбор типов данных) могут взаимодействовать с записью полных страниц.
Так что же такое полная запись страниц? Как говорит комментарий из postgresql.conf, это способ оправиться от частичной записи страниц — PostgreSQL использует страницы размера 8kB (по умолчанию), в то время как другие части стека используют отличные размеры кусков. Файловая система Linux как правило использует 4kB страницы (возможно использовать страницы меньшего размера, но 4kB является максимумом на x86), на аппаратном же уровне, старые приводы используют секторы 512B, в то время как новые пишут данные более большими кусками (обычно 4kB, или даже 8kB).
Таким образом, когда PostgreSQL записывает 8kB страницу, остальные слои хранилища могут разбивать ее на меньшие куски, обрабатываемые отдельно. Это представляет из себя проблему атомарности записи. 8ми килобайтная PostgreSQL'вская страница может быть разбита на две 4kB страницы файловой системы, а потом еще на 512B секторы. Теперь, что произойдет, если сервер выйдет из строя (сбой питания, ошибка ядра,...)?
Даже если сервер использует систему хранения, предназначенную для того, чтобы справляться с такими сбоями (SSD с конденсаторами, RAID контроллеры с батареями, ...), ядро уже разделяет данные на 4kB страницы. Существует возможность что база данных записала 8kB страницу с данными, но только часть от нее попала на диск до сбоя.
С этой точки зрения, Вы сейчас вероятно думаете что это именно то, ради чего мы имеем транзакционный лог (WAL) и Вы правы! Так что, после запуска сервера, база будет читать WAL (с последнего выполненного чекпоинта), и применит изменения опять, чтобы убедиться что файлы с данными верны. Просто.
Но есть уловка — восстановление не применяет изменения вслепую, зачастую ему необходимо прочитать страницы с данными и т.д., что подразумевает что страница уже не испорчена в некотором роде, к примеру в связи с частичной записью. Что кажется самую малость внутренне противоречивым, потому что для исправления порчи данных мы подразумеваем, что данные не были повреждены.
Полная запись страниц является чем-то вроде решения этой головоломки — при изменении страницы в первый раз после чекпоинта, целая страница будет записана в WAL. Это гарантирует что во время восстановления, первая запись в WAL'е, связанная с этой страницей, хранит в себе полную страницу, освобождая нас от необходимости чтения потенциально поврежденной страницы из файла с данными.
Конечно же, негативным последствием этого является увеличение размера WAL'а — изменение одного байта на 8kB странице приведет к ее полной записи в WAL. Полная запись страницы происходит только на первой записи после чекпоинта, то есть уменьшая частоту чекпоинтов — это один из способов улучшить ситуацию, на самом деле, существует небольшой «взрыв» полной записи страниц после чекпоинта, после чего относительно немного полных записей происходит до его окончания.
Все еще остаются некоторые неожиданные взаимодействия с проектными решениями, принятыми на уровне приложения. Давайте предположим, что мы имеем простую таблицу с первичным ключом, UUID или BIGSERIAL, и мы пишем в нее данные. Будет ли разница в размере генерируемого WAL'а (предполагая что мы пишем одинаковое количество строк)?
Представляется разумным ожидать приблизительно одинаково размера WAL'ов в обоих случаях, но следующие диаграммы наглядно демонстрируют, что существует огромная разница на практике:

Здесь показаны размеры WAL'ов, полученные в результате часового теста, разогнанного до 5000 инсертов в секунду. С BIGSERIAL'ом в качестве первичного ключа, это вылилось в ~2GB WAL'аЮ в то время как UUID выдал более 40GB. Разница более чем ощутима, и большая часть WAL'а связана с индексом, стоящим за первичным ключом. Давайте посмотрим на типы записей в WAL'е:
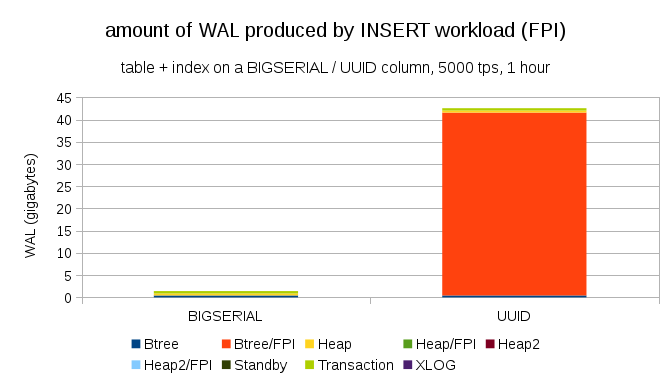
Очевидно, абсолютное большинство записей — это полностраничные образы (FPI), т.е. результат полной записи страниц. Но почему это происходит?
Конечно, это связано с присущей UUID'у случайностью. Новые BIGSERIAL'ы последовательны, в связи с чем и пишутся в те же ветви btree индекса. Так как только первое изменение страницы вызывает полную запись страницы, такое малое количество записей WAL'а являются FPI'ми. С UUID совсем другое дело, конечно же, значения совершенно не последовательны и каждый инсерт вполне вероятно попадет в новую ветвь индекса (предполагая что индекс является довольно большим).
База данных особо ничего не может сделать с этим — нагрузка носит случайных характер, что вызывает большое количество полных записей страниц.
Конечно же, не так уж и сложно добиться аналогичного увеличения записи даже с BIGSERIAL ключами. Просто это требует другого типа нагрузки, к примеру апдейты, случайные апдейты записей изменят распределение, диаграмма выглядит следующим образом:
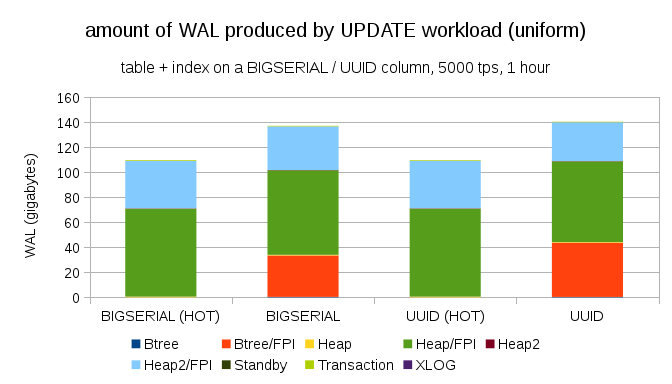
Внезапно разница между типами данных исчезла — доступ осуществляется случайно в обоих случаях, приводя приблизительно к идентичному размеру производимых WAL'ов. Другим отличием является то, что большая часть WAL'а ассоциируется с «heap», т.е. таблицами, а не индексами. «HOT» случаи были воспроизведены для возможности HOT UPDATE оптимизации (т.е. апдейты без необходимости трогать индекс), что практически полностью исключает весь связанный с индексами траффик WAL.
Но Вы можете протестовать что большая часть приложений не изменяет весь набор данных. Обычно, только малая часть данных «активна» — людей интересуют сообщения за последние несколько дней на форумах, нерешенные заказы в интернет-магазинах, и т.д. Как это влияет на результаты?
К счастью, pgbench поддерживает неравномерные распределения, и, к примеру, с экспоненциальным распределением, касающимся 1% набора данных ~25% времени, диаграммы будут выглядеть следующим образом:
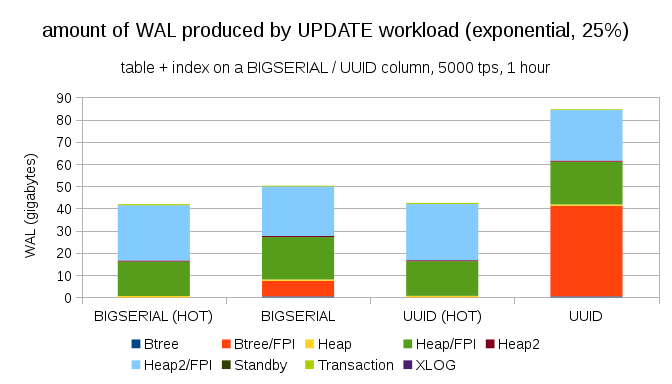
Если сделать распределение еще более ассиметричным, касающимся 1% данных ~75% времени:

Это в очередной раз показывает насколько большую разницу может вызвать выбор типов данных, и насколько важна настройка горячих апдейтов.
Еще один интересный вопрос — сколько WAL траффика можно сэкономить, используя меньшие страницы в PostgreSQL (что требует компиляции пользовательского пакета). В лучшем случае, это может сохранить до 50% WAL'а, благодаря логированию только 4kB, вместо 8kB страниц. Для нагрузки с равномерно распределенными апдейтами выглядит следующим образом:
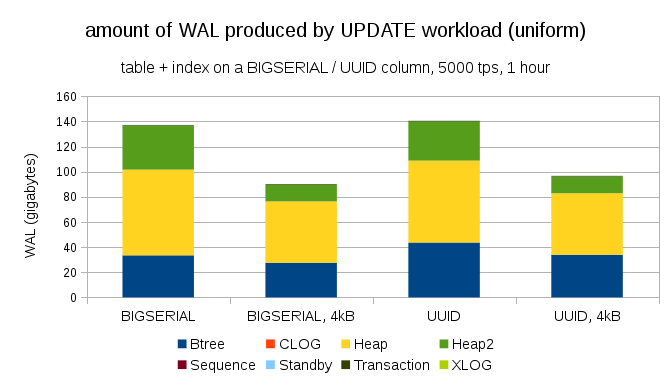
В общем экономия не совсем 50%, но уменьшение с ~140GB до ~90GB все-равно довольно ощутимо.
Это может показаться вопиющим после объяснения всех опасностей частичной записи, но, возможно выключение полной записи страниц может быть жизнеспособным вариантом, по крайней мере в некоторых случаях.
Во-первых, мне интересно, уязвимы ли до сих пор файловые системы на Linux для частичных записей? Параметр был представлен в PosqtgreSQL версии 8.1, вышедшей в 2005, так что, возможно, многие улучшения файловых систем с тех пор решили эту проблему. Вероятно это не универсальный подход для любых рабочих нагрузок, но, возможно, учитывая некоторые дополнительные условия (к примеру, использование 4kB страниц в PostgreSQL) его будет достаточно? К тому же, PostgreSQL никогда не перезаписывает только часть 8kB страницы, а только полную страницу.
Я провел множество тестов недавно, пытаясь вызвать частичную запись, но так и не мог вызвать даже единичного случая. Конечно же, это не является доказательством того, что проблемы не существует. Но даже если она есть, контрольные суммы могут быть достаточной защитой (это не исправит проблемы, но как минимум укажет на испорченную страницу).
Во-вторых, многие современные системы полагаются на реплики, использующие потоковую репликацию — вместо того, чтобы ожидать пока сервер перезагрузится после сбоя оборудования (что может длится довольно долго) и затем тратить еще больше времени на проведение восстановления, системы просто переключатся на hot standby. Если база данных на поврежденном мастере была убрана (и затем склонирована с нового мастера), частичные записи не являются проблемой.
Но, я боюсь, если мы начнем рекомендовать такой подход, тогда «Я не знаю каким образом данные были повреждены, я просто сделал full_page_writes=off на системах!» станет одним из самых распространенных предложений прямо перед гибелью DBA (вместе с «Я видел эту змею на reddit, она не ядовита»).
Не так уж и много можно сделать, чтобы настроить непосредственно полную запись страниц. Для большего числа нагрузок, большая часть полных записей происходит непосредственно после чекпоинта, после чего исчезают до следующего чекпоинта. Так что довольно важно настроить чекпоинты таким образом, чтобы они не следовали друг за другом слишком часто.
Некоторые решения на уровне приложения могут увеличить случайность записи в таблицы и индексы — к примеру UUID'ы по своей природе случайны, превращая даже обычную нагрузку от инсертов в случайные апдейты индексов. Схема, использованная в примерах была достаточно тривиальна — на практике же, там были бы вторичные индексы, внешние ключи и т.д. Использование же BIGSERIAL в качестве первичных ключей (и оставляя UUID в качестве побочных ключей) может как минимум уменьшит увеличение записи.
Я действительно заинтересован в обсуждении необходимости полной записи страниц на различных ядрах/файловых системах. К сожалению, я не нашел большого количества ресурсов, если вы обладаете какой-либо соответствующей информацией, дайте мне знать.
В отличие от моего прошлого поста про настройку чекпоинтов, этот не является пособием о том, как надо настраивать сервер. Здесь не так много всего того, что Вы могли бы настроить, на самом деле, но я покажу Вам как некоторые решения на уровне приложения (к примеру, выбор типов данных) могут взаимодействовать с записью полных страниц.
Частичная запись / «Разорванные» страницы
Так что же такое полная запись страниц? Как говорит комментарий из postgresql.conf, это способ оправиться от частичной записи страниц — PostgreSQL использует страницы размера 8kB (по умолчанию), в то время как другие части стека используют отличные размеры кусков. Файловая система Linux как правило использует 4kB страницы (возможно использовать страницы меньшего размера, но 4kB является максимумом на x86), на аппаратном же уровне, старые приводы используют секторы 512B, в то время как новые пишут данные более большими кусками (обычно 4kB, или даже 8kB).
Таким образом, когда PostgreSQL записывает 8kB страницу, остальные слои хранилища могут разбивать ее на меньшие куски, обрабатываемые отдельно. Это представляет из себя проблему атомарности записи. 8ми килобайтная PostgreSQL'вская страница может быть разбита на две 4kB страницы файловой системы, а потом еще на 512B секторы. Теперь, что произойдет, если сервер выйдет из строя (сбой питания, ошибка ядра,...)?
Даже если сервер использует систему хранения, предназначенную для того, чтобы справляться с такими сбоями (SSD с конденсаторами, RAID контроллеры с батареями, ...), ядро уже разделяет данные на 4kB страницы. Существует возможность что база данных записала 8kB страницу с данными, но только часть от нее попала на диск до сбоя.
С этой точки зрения, Вы сейчас вероятно думаете что это именно то, ради чего мы имеем транзакционный лог (WAL) и Вы правы! Так что, после запуска сервера, база будет читать WAL (с последнего выполненного чекпоинта), и применит изменения опять, чтобы убедиться что файлы с данными верны. Просто.
Но есть уловка — восстановление не применяет изменения вслепую, зачастую ему необходимо прочитать страницы с данными и т.д., что подразумевает что страница уже не испорчена в некотором роде, к примеру в связи с частичной записью. Что кажется самую малость внутренне противоречивым, потому что для исправления порчи данных мы подразумеваем, что данные не были повреждены.
Полная запись страниц является чем-то вроде решения этой головоломки — при изменении страницы в первый раз после чекпоинта, целая страница будет записана в WAL. Это гарантирует что во время восстановления, первая запись в WAL'е, связанная с этой страницей, хранит в себе полную страницу, освобождая нас от необходимости чтения потенциально поврежденной страницы из файла с данными.
Увеличение записи
Конечно же, негативным последствием этого является увеличение размера WAL'а — изменение одного байта на 8kB странице приведет к ее полной записи в WAL. Полная запись страницы происходит только на первой записи после чекпоинта, то есть уменьшая частоту чекпоинтов — это один из способов улучшить ситуацию, на самом деле, существует небольшой «взрыв» полной записи страниц после чекпоинта, после чего относительно немного полных записей происходит до его окончания.
UUID против BIGSERIAL ключей
Все еще остаются некоторые неожиданные взаимодействия с проектными решениями, принятыми на уровне приложения. Давайте предположим, что мы имеем простую таблицу с первичным ключом, UUID или BIGSERIAL, и мы пишем в нее данные. Будет ли разница в размере генерируемого WAL'а (предполагая что мы пишем одинаковое количество строк)?
Представляется разумным ожидать приблизительно одинаково размера WAL'ов в обоих случаях, но следующие диаграммы наглядно демонстрируют, что существует огромная разница на практике:
Здесь показаны размеры WAL'ов, полученные в результате часового теста, разогнанного до 5000 инсертов в секунду. С BIGSERIAL'ом в качестве первичного ключа, это вылилось в ~2GB WAL'аЮ в то время как UUID выдал более 40GB. Разница более чем ощутима, и большая часть WAL'а связана с индексом, стоящим за первичным ключом. Давайте посмотрим на типы записей в WAL'е:
Очевидно, абсолютное большинство записей — это полностраничные образы (FPI), т.е. результат полной записи страниц. Но почему это происходит?
Конечно, это связано с присущей UUID'у случайностью. Новые BIGSERIAL'ы последовательны, в связи с чем и пишутся в те же ветви btree индекса. Так как только первое изменение страницы вызывает полную запись страницы, такое малое количество записей WAL'а являются FPI'ми. С UUID совсем другое дело, конечно же, значения совершенно не последовательны и каждый инсерт вполне вероятно попадет в новую ветвь индекса (предполагая что индекс является довольно большим).
База данных особо ничего не может сделать с этим — нагрузка носит случайных характер, что вызывает большое количество полных записей страниц.
Конечно же, не так уж и сложно добиться аналогичного увеличения записи даже с BIGSERIAL ключами. Просто это требует другого типа нагрузки, к примеру апдейты, случайные апдейты записей изменят распределение, диаграмма выглядит следующим образом:
Внезапно разница между типами данных исчезла — доступ осуществляется случайно в обоих случаях, приводя приблизительно к идентичному размеру производимых WAL'ов. Другим отличием является то, что большая часть WAL'а ассоциируется с «heap», т.е. таблицами, а не индексами. «HOT» случаи были воспроизведены для возможности HOT UPDATE оптимизации (т.е. апдейты без необходимости трогать индекс), что практически полностью исключает весь связанный с индексами траффик WAL.
Но Вы можете протестовать что большая часть приложений не изменяет весь набор данных. Обычно, только малая часть данных «активна» — людей интересуют сообщения за последние несколько дней на форумах, нерешенные заказы в интернет-магазинах, и т.д. Как это влияет на результаты?
К счастью, pgbench поддерживает неравномерные распределения, и, к примеру, с экспоненциальным распределением, касающимся 1% набора данных ~25% времени, диаграммы будут выглядеть следующим образом:
Если сделать распределение еще более ассиметричным, касающимся 1% данных ~75% времени:
Это в очередной раз показывает насколько большую разницу может вызвать выбор типов данных, и насколько важна настройка горячих апдейтов.
8kB и 4kB страницы
Еще один интересный вопрос — сколько WAL траффика можно сэкономить, используя меньшие страницы в PostgreSQL (что требует компиляции пользовательского пакета). В лучшем случае, это может сохранить до 50% WAL'а, благодаря логированию только 4kB, вместо 8kB страниц. Для нагрузки с равномерно распределенными апдейтами выглядит следующим образом:
В общем экономия не совсем 50%, но уменьшение с ~140GB до ~90GB все-равно довольно ощутимо.
Нужна ли нам полная запись страниц?
Это может показаться вопиющим после объяснения всех опасностей частичной записи, но, возможно выключение полной записи страниц может быть жизнеспособным вариантом, по крайней мере в некоторых случаях.
Во-первых, мне интересно, уязвимы ли до сих пор файловые системы на Linux для частичных записей? Параметр был представлен в PosqtgreSQL версии 8.1, вышедшей в 2005, так что, возможно, многие улучшения файловых систем с тех пор решили эту проблему. Вероятно это не универсальный подход для любых рабочих нагрузок, но, возможно, учитывая некоторые дополнительные условия (к примеру, использование 4kB страниц в PostgreSQL) его будет достаточно? К тому же, PostgreSQL никогда не перезаписывает только часть 8kB страницы, а только полную страницу.
Я провел множество тестов недавно, пытаясь вызвать частичную запись, но так и не мог вызвать даже единичного случая. Конечно же, это не является доказательством того, что проблемы не существует. Но даже если она есть, контрольные суммы могут быть достаточной защитой (это не исправит проблемы, но как минимум укажет на испорченную страницу).
Во-вторых, многие современные системы полагаются на реплики, использующие потоковую репликацию — вместо того, чтобы ожидать пока сервер перезагрузится после сбоя оборудования (что может длится довольно долго) и затем тратить еще больше времени на проведение восстановления, системы просто переключатся на hot standby. Если база данных на поврежденном мастере была убрана (и затем склонирована с нового мастера), частичные записи не являются проблемой.
Но, я боюсь, если мы начнем рекомендовать такой подход, тогда «Я не знаю каким образом данные были повреждены, я просто сделал full_page_writes=off на системах!» станет одним из самых распространенных предложений прямо перед гибелью DBA (вместе с «Я видел эту змею на reddit, она не ядовита»).
Вывод
Не так уж и много можно сделать, чтобы настроить непосредственно полную запись страниц. Для большего числа нагрузок, большая часть полных записей происходит непосредственно после чекпоинта, после чего исчезают до следующего чекпоинта. Так что довольно важно настроить чекпоинты таким образом, чтобы они не следовали друг за другом слишком часто.
Некоторые решения на уровне приложения могут увеличить случайность записи в таблицы и индексы — к примеру UUID'ы по своей природе случайны, превращая даже обычную нагрузку от инсертов в случайные апдейты индексов. Схема, использованная в примерах была достаточно тривиальна — на практике же, там были бы вторичные индексы, внешние ключи и т.д. Использование же BIGSERIAL в качестве первичных ключей (и оставляя UUID в качестве побочных ключей) может как минимум уменьшит увеличение записи.
Я действительно заинтересован в обсуждении необходимости полной записи страниц на различных ядрах/файловых системах. К сожалению, я не нашел большого количества ресурсов, если вы обладаете какой-либо соответствующей информацией, дайте мне знать.

