
В компьютерах уже давно есть шина PCI Express v3.0 x16; Тесты современных видеоадаптеров показывают на этой шине скорость около 12 Гбайт/с. Хотелось бы сделать модуль на ПЛИС который обладает такой же скоростью. Однако доступные ПЛИС имеют HARDWARE контроллер только для PCIe v3.0 x8; Реализации SOFT IP Core есть, но очень дорогие. Но выход есть.
ПЛИС Virtex 7 VX330T имеет два контроллера PCI Express v3.0 x8; Очевидным решением является размещение коммутатора, который имеет на стороне разъёма x16 и две шины x8 которые подключены к ПЛИС. Получается вот такая структура:

По такой схеме построен модуль HTG-728 компании HighTechGlobal.
По другому пути идёт комания Alpha-Data. Модуль ADM-PCIE-KU3-X16 не имеет коммутатора. Но на разъём x16 выводятся две шины x8. В ПЛИС возможна реализация двух независимых контроллеров. Для этого на ПЛИС заведены два сигнала сброса и две опорных частоты. Но работать это модуль будет только в специальных системных платах, где так же на разъём x16 выводятся два x8. Таких системных плат я не встречал, но видимо они есть.
В нашей компании было принято решение по реализации модуля FMC122P с внутренним коммутатором. Главной задачей была проверка максимальной скорости обмена. Другой, не менее важной задачей, является достижение совместимости с существующим программным обеспечением и компонентами ПЛИС.
Контроллер PCI Express для Virtex 7 кардинально отличается от контроллеров для Virtex 6, Kintex 7. Он стал более удобным, но он другой. На рисунке представлена структурная схема контроллера:

Контроллер имеет две части Completer и Requester, каждая из которых имеет две шины AXI_Stream. Через узел Completer приходят запросы со стороны шины PCI Express. Эти запросы передаются на шину m_axis_cq. По шине s_axis_cc должен прийти ответ со стороны User компонента. Обычно это узел доступа к внутренним регистрам ПЛИС.
Через узел Requester по шине s_axis_rq контроллер DMA посылает запросы на шину PCI Express. Ответы приходят через шину m_axis_rc.
Моделирование шины
В состав IP Core входит example проект по которому можно понять как это работает. Проект написан на Verilog и, к сожалению, он также может служить примером того как не надо разрабатывать. Давайте рассмотрим структурную схему примера.
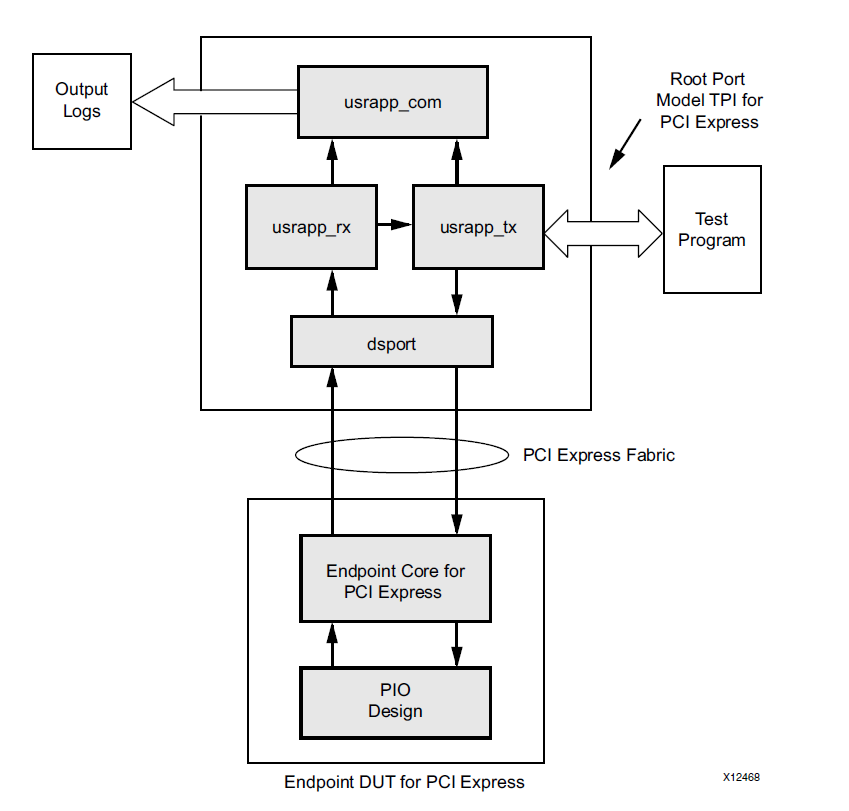
Эта диаграмма взята из описания IP Core. На первый взгляд всё прекрасно – это замечательная картинка, её можно показать менеджерам, руководителям проектов, клиентам. Проблемы начинаются в реализации. В этой системе очень много мест где используется возможности Verilog для доступа к объектам по абсолютному пути. На мой взгляд, в данной системе это оправдано только в одном месте – это обход узлов GTP для моделирования на уровне PIPE. А вот делать связь между userapp_tx и userapp_rx с использованием абсолютных путей совершенно не нужно.
В проекте это выглядит так:
В компоненте pci_exp_usrapp_tx есть функция TSK_SYSTEM_INITIALIZATION которая вызывает через абсолютный путь функцию из pci_exp_userapp_cfg:
board.RP.cfg_usrapp.TSK_WRITE_CFG_DW (здесь и далее я называю функцией то что в Verilog описывается через task). Смотрим компонент pci_exp_userapp_cfg, что видим: cfg_ds_bus_number <= board.RP.tx_usrapp.RP_BUS_DEV_FNS[15:8];
Смотрим компонент pci_exp_userapp_rc, там тоже самое: board.RP.com_usrapp.TSK_PARSE_FRAME(`RX_LOG);
Это не только стилистически не правильно. Это мешает применить модель в своём проекте. Во первых совершенно не обязательно, что в собственном проекте файл верхнего уровня будет называться board и там останется та же самая иерархия. Во вторых может быть два компонента. У нас как раз произошли оба случая. Пришлось поработать с Verilog, хотя мне он совершенно не нравиться. Как оказалось, путём небольшой перестановки весь компонент root_port можно привести к полностью иерархическому виду. В итоге получились файлы компонентов:
- xilinx_pcie_3_0_7vx_rp_m2.v
- pci_exp_usrapp_tx_m2.v
- pci_exp_usrapp_cfg_m2.v
И файлы с функциями:
- task_bar.vh
- task_rd.vh
- task_s1.vh
- task_test.vh
Это позволило включить в модель два компонента root_port. В компоненте VHDL включение двух root_port выглядит так:
root_port
gen_rp0: if( is_rp0=1 ) generate
rp0: xilinx_pcie_3_0_7vx_rp_m2
generic map(
INST_NUM => 0
)
port map(
sys_clk_p => sys_clk_p,
sys_clk_n => sys_clk_n,
sys_rst_n => sys_rst_n,
-- Передача команд
cmd_rw => cmd_rw, -- Признак чтения-записи: 0 - чтение, 1 - запись
cmd_req => cmd_req, -- 1 - Запрос операции
cmd_ack => cmd_ack, -- 1 - подтверждение опреации
cmd_adr => cmd_adr, -- адрес для команды чтения-записи
cmd_data_i => cmd_data_i, -- данные для записи
cmd_data_o => cmd_data_o, -- прочитанные данные
cmd_init_done => cmd_init_done_0 -- 1 - инициализация завершена
);
end generate;
gen_rp1: if( is_rp1=1 ) generate
rp1: xilinx_pcie_3_0_7vx_rp_m2
generic map(
INST_NUM => 1
)
port map(
sys_clk_p => sys_clk_p,
sys_clk_n => sys_clk_n,
sys_rst_n => sys_rst_n,
cmd_init_done => cmd_init_done_1 -- 1 - инициализация завершена
);
end generate;
Через компонент rp0 производятся обращения по записи или чтению 32-х разрядных слов. Компонент rp1 только проводит инициализацию.
К сожалению это моделируется очень долго, даже если проводить моделирование на уровне PIPE. Типичный сеанс моделирования это около десяти минут (а может и больше, я уже не помню). Для оперативной работы с DMA каналом это не подходит. В данной ситуации было принято совершенно естественное решение это удалить из модели контроллер PCI Express. Тем более, что он уже был изучен.
Структурная схема контроллера
Обобщённая ��хема контроллера представлена на рисунке.
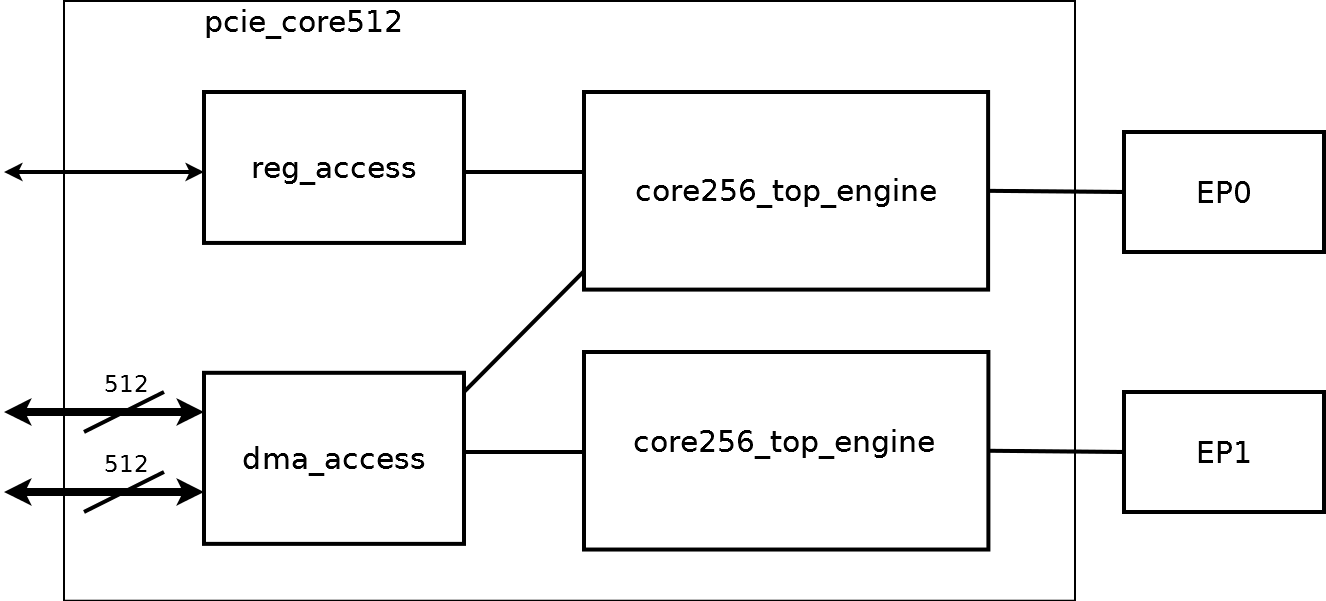
Два одинаковых компонента core256_top_engine обеспечивают доступ к двум контроллерам EP0, EP1. core256_top_engine обеспечивает обращение к регистрам со стороны PCI Express, для этого используется только EP0 и компонент reg_access. Компонент dma_access содержит главную логику управления контроллером. Его структурная схема на рисунке ниже:
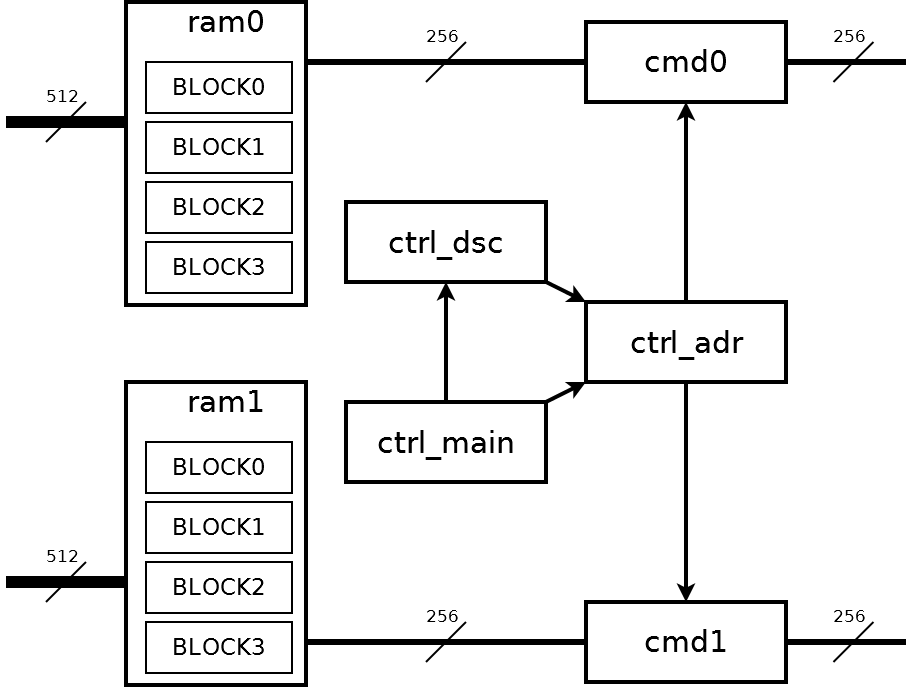
Всем управляет узел ctrl_main. Узел ctrl_dsc содержит блок дескрипторов. Узел ctrl_adr преобразует дескриптор в последовательность адресов четырёхкилобайтных блоков. Адреса поступают на узлы cmd0 и cmd1 для обмена с узлами core256_top_engine;
Со стороны пользовательской части ПЛИС есть две шины шириной 512 бит. Но данные по этим шинам должны передаваться блоками по 4 килобайта и строго по очереди. Это требуется для поочерёдного заполнения узлов памяти ram0, ram1. Каждый узел памяти содержит четыре блока по 4 килобайта. На этих узлах памяти происходит расщепление исходного потока шириной 512 бит на два потока по 256 бит. В дальнейшем два потока по 256 бит уже полностью независимы. Данные потоков встретятся только в оперативной памяти компьютера, где они окажутся по соседним адресам.
Моделирование dma_access
Узел dma_access является самой сложной частью контроллера. Соответственно, он должен быть промоделирован особенно тщательно. Как я уже написал выше, моделировать два ядра PCI Express очень долго. Для ускорения разработана модель которая подключается вместо core256_top_engine. Для dma_access остался тот же самый интерфейс, а скорость моделирования выросла на порядок. В этом проекте, так же как и в проекте PROTEQ используется автоматический запуск тестов через tcl файл.
Вот фрагмент tcl-файла:
run_test "stend_m4" "test_read_8kb " 6 "50 us"
run_test "stend_m4" "test_read_16kb " 7 "100 us"
run_test "stend_m4" "test_read_49blk " 8 "150 us"
run_test "stend_m4" "test_read_8x4_cont " 9 "150 us"
run_test "stend_m4" "test_read_128x1_cont " 12 "200 us"
run_test "stend_m4" "test_read_16kbx2 " 13 "150 us"
run_test "stend_m4" "test_read_step " 14 "200 us"
run_test "stend_m4" "test_read_8kb_sg_eot " 15 "100 us"
run_test "stend_m4" "test_read_64x1 " 16 "100 us"Это автоматический запуск девяти тестов. Для примера приведу код одного теста:
test_read_4kb
procedure test_read_4kb (
signal cmd: out bh_cmd; --! команда
signal ret: in bh_ret --! ответ
)
is
variable adr : std_logic_vector( 31 downto 0 );
variable data : std_logic_vector( 31 downto 0 );
variable str : line;
variable L : line;
variable error : integer:=0;
variable dma_complete : integer;
variable data_expect : std_logic_vector( 31 downto 0 );
begin
write( str, string'("TEST_READ_4KB" ));
writeline( log, str );
---- Формирование блока дескрипторов ---
for ii in 0 to 127 loop
adr:= x"00100000";
adr:=adr + ii*4;
int_mem_write( cmd, ret, adr, x"00000000" );
end loop;
int_mem_write( cmd, ret, x"00100000", x"00008000" );
int_mem_write( cmd, ret, x"00100004", x"00000100" );
-- int_mem_write( cmd, ret, x"00100080", x"00008000" );
-- int_mem_write( cmd, ret, x"00100084", x"00000100" );
int_mem_write( cmd, ret, x"001001F8", x"00000000" );
int_mem_write( cmd, ret, x"001001FC", x"762C4953" );
---- Программирование канала DMA ----
block_write( cmd, ret, 4, 8, x"00000025" ); -- DMA_MODE
block_write( cmd, ret, 4, 9, x"00000010" ); -- DMA_CTRL - RESET FIFO
block_write( cmd, ret, 4, 20, x"00100000" ); -- PCI_ADRL
block_write( cmd, ret, 4, 21, x"00100000" ); -- PCI_ADRH
block_write( cmd, ret, 4, 23, x"0000A400" ); -- LOCAL_ADR
block_write( cmd, ret, 4, 9, x"00000001" ); -- DMA_CTRL - START
wait for 20 us;
block_read( cmd, ret, 4, 16, data ); -- STATUS
write( str, string'("STATUS: " )); hwrite( str, data( 15 downto 0 ) );
if( data( 8 )='1' ) then
write( str, string'(" - Дескриптор правильный" ));
else
write( str, string'(" - Ошибка чтения дескриптора" ));
error := error + 1;
end if;
writeline( log, str );
if( error=0 ) then
---- Ожидание завершения DMA ----
dma_complete := 0;
for ii in 0 to 100 loop
block_read( cmd, ret, 4, 16, data ); -- STATUS
write( str, string'("STATUS: " )); hwrite( str, data( 15 downto 0 ) );
if( data(5)='1' ) then
write( str, string'(" - DMA завершён " ));
dma_complete := 1;
end if;
writeline( log, str );
if( dma_complete=1 ) then
exit;
end if;
wait for 1 us;
end loop;
writeline( log, str );
if( dma_complete=0 ) then
write( str, string'("Ошибка - DMA не завершён " ));
writeline( log, str );
error:=error+1;
end if;
end if;
for ii in 0 to 3 loop
block_read( cmd, ret, 4, 16, data ); -- STATUS
write( str, string'("STATUS: " )); hwrite( str, data( 15 downto 0 ) );
writeline( log, str );
wait for 500 ns;
end loop;
block_write( cmd, ret, 4, 9, x"00000000" ); -- DMA_CTRL - STOP
write( str, string'(" Прочитано: " ));
writeline( log, str );
data_expect := x"A0000000";
for ii in 0 to 1023 loop
adr:= x"00800000";
adr:=adr + ii*4;
int_mem_read( cmd, ret, adr, data );
if( data=data_expect ) then
fprint( output, L, "%r : %r - Ok\n", fo(ii), fo(data));
fprint( log, L, "%r : %r - Ok\n", fo(ii), fo(data));
else
fprint( output, L, "%r : %r Ожидается: %r - Error \n", fo(ii), fo(data), fo(data_expect));
fprint( log, L, "%r : %r Ожидается: %r - Error \n", fo(ii), fo(data), fo(data_expect));
error:=error+1;
end if;
data_expect := data_expect + 1;
end loop;
-- block_write( cmd, ret, 4, 9, x"00000010" ); -- DMA_CTRL - RESET FIFO
-- block_write( cmd, ret, 4, 9, x"00000000" ); -- DMA_CTRL
-- block_write( cmd, ret, 4, 9, x"00000001" ); -- DMA_CTRL - START
fprint( output, L, "\nTest time: %r \n", fo(now) );
fprint( log, L, "\nTest time: %r \n", fo(now) );
-- вывод в файл --
writeline( log, str );
if( error=0 ) then
write( str, string'("TEST finished successfully" ));
cnt_ok := cnt_ok + 1;
else
write( str, string'("TEST finished with ERR" ));
cnt_error := cnt_error + 1;
end if;
writeline( log, str );
writeline( log, str );
-- вывод в консоль --
writeline( output, str );
if( error=0 ) then
write( str, string'("TEST finished successfully" ));
else
write( str, string'("TEST finished with ERR" ));
end if;
writeline( output, str );
writeline( output, str );
end test_read_4kb
Команды int_mem_write обеспечивают запись в ОЗУ HOST компьютера. В данном тесте туда записывается блок дескрипторов. Команды block_write и block_read обеспечивают обращения к регистрам DMA контроллера. Производится программирование контроллераю, его запуск и завершение обмена. После этого командами int_mem_read производится считывание и проверка принятых данных. Код этого теста практически полностью совпадает с тестом от контроллера PCIe_DS_DMA, который я опубликовал как open source проект на opencores.org; По сравнению с оригиналом добавлена проверка принятых данных.
Логическая организация контроллера
На уровне регистров контроллер полностью повторяет наши предыдущие контроллеры для ПЛИС Virtex 4, Virtex 5, Virtex 6, Kintex 7; С организацией можно ознакомиться в проекте PCIe_DS_DMA.
Особенностью всех контроллеров является объединение одиночных дескрипторов в блок дескрипторов. Это даёт резкое увеличение скорости при использовании фрагментированной памяти.
Подключение к тетрадам
Для нас важно подключить данный контроллер к нашим тетрадам. Что такое тетрады я написал в предыдущей статье: «Интерфейс ADM: Что такое тетрада». Работа с шиной 512 бит потребовала изменение подхода. Для подключения тетрады пришлось использовать дополнительный узел перепаковщика. Структураная схема — на рисунке.
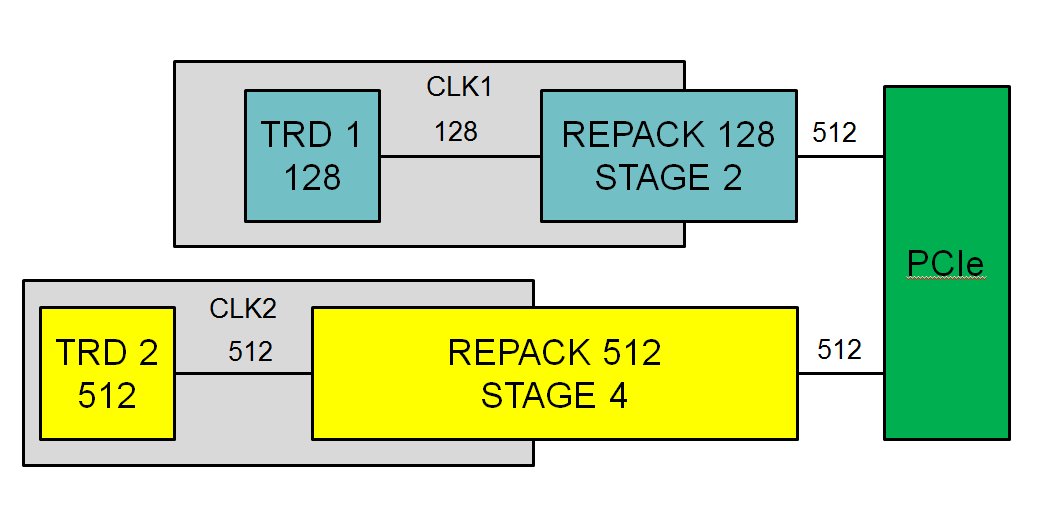
Перепаковщик решает две задачи:
- трассировку шины по кристаллу, для этого можно задать число дополнительных стадий конвейера
- подключение к тетрадам с шинами 64 и 128 разрядов
Использование памяти
Конечной целью разработки контроллера и подключения к тетрадам является получение непрерывного потока данных от АЦП на компьютер. И здесь мы сталкиваемся с тем, что шина PCI Express не обеспечивает стабильной скорости. На шине возможны задержки. Это особенно заметно проявляется на высоких скоростях обмена. Задержки возникают из-за работы других устройств. Величина задержки может быть разной, это может быть 5 – 10 мкс, а может и больше. Задержка в 10 мкс на скорости 11 Гбайт/с соответствует блоку памяти в 110 килобайт. Для внутренней памяти даже современных ПЛИС это очень много. А ведь задержка может быть и больше. Если поток данных нельзя приостановить, а это как раз тот случай, когда используются АЦП, то единственным выходом является буферизация во внешней памяти. Причём память должна уметь работать на скорости 22 Гбайта/с. У нас на модуле установлены два SODIMM DDR3-1600. Память работает на частоте 800 МГц. Это с��ответствует непрерывному потоку данных 8400 Мбайт/с. Это цифра подтверждена экспериментом. Хочу заметить, что скорость 8400 Мбайт/с превосходит скорость выдачи данных от нашего самого быстрого субмодуля в котором установлены два АЦП на 1800 МГц.
Трассировка
На скриншоте представлен результат трассировки в программе PlanAhead:

На картинке видно два контроллера PCI Express (подсвечены жёлтым и зелёным) и два контроллера памяти (рядом с PCI Express).
Как оказалась, такой проект является очень сложным для Vivado, она с ним справляется очень плохо. Проект в Vivado разводится плохо и часто просто не работает. ISE показывает гораздо более стабильные результаты. Узлы PCI Express разведены в соответствии с рекомендациями Xilinx, при этом оказалось что они разнесены по кристаллу. А это уже создаёт проблему для совместного использования остальных мультигигабитных линий.
Результаты
Работа модуля проверялась на нескольких компьютерах. Результаты довольно интересные.
| Intel Core i7 4820K | P9X79 WS | DDR3-1866 | 11140 МБайт/с |
|---|---|---|---|
| Intel Core i7 5820K | X99-A | DDR4-2400 | 11128 МБайт/с |
| Intel Core i7 3820K | P9X79 | DDR3-1600 | 11120 МБайт/с |
Это скорость ввода данных без проверки. Производится непрерывный ввод данных в буфер размером 1 Гбайт выделенный в системной области памяти, т. е. непрерывный по физическим адресам. Измеряется средняя скорость ввода на интервале не менее 1 минуты.
На компьютере с памятью DDR3-1600 при включении проверки скорость падает до 8500 Мбайт/с.
На компьютере с DDR3-1866 скорость при одном модуле и включённой проверке скорость не уменьшается.
Два модуля FMC122P в компьютере с DDR3-1866 без проверки также показывают максимальную скорость около 11000 Мбайт/с для каждого модуля. Но при включении проверки скорость падает.
При данных измерениях принято что 1 Мбайт это 1024 кбайт, а 1 кбайт это 1024 байта.
Я бы хотел отметить, что в данной работе я представляю результат работы большого коллектива. Особая благодарность — Дмитрию Авдееву, который проделал огромную работу в этом проекте.
P.S. Пока шла разработка Virtex 7 успел устареть. Kintex Ultrascale уже удобнее в работе. А Kintex Ultrascale+ уже имеет HARD блок PCI Express v3.0 x16 – так что такое разделение уже не нужно.
P.S.S. Но Kintex Ultrascale+ также имеет HARD блок PCI Express v4.0 x8 – может всё таки разделение пригодится?

