Представляю вам перевод моей статьи на Medium.com: часть 1, часть 2. Поскольку первая часть статьи содержит в основном уже изложенное в этом посте, то привожу перевод только второй части.

Худеем и переезжаем в контейнеры
В первой части статьи я рассказал о простых подходах, позволяющих построить масштабируемый кластер Selenium без написания кода. В этой части мы рассмотрим более тонкие вопросы работы с Selenium:
- Как создать легко масштабируемые рабочие ноды, используя стандартный Selenium Hub
- Почему можно и нужно запускать большинство браузеров в контейнерах и как это делается
- Какие open-source инструменты для этого существуют
Что внутри рабочей ноды
Все новые инструменты, описанные в первой части, на самом деле являются умными легковесными прокси, которые перенаправляют запросы пользователей в настоящие Selenium хабы и ноды. Если немного поразмышлять, то появляются вопросы:
- Как организовать хабы и ноды, чтобы эффективно потреблять аппаратные ресурсы и хорошо масштабироваться?
- Какую операционную систему использовать?
- Какие программы должны быть установлены?
- Можно ли работать без монитора?
Одним из способов может быть использование "железа" с одним Selenium хабом и множеством нод с различными браузерами. Выглядит разумно, но на самом деле неудобно:
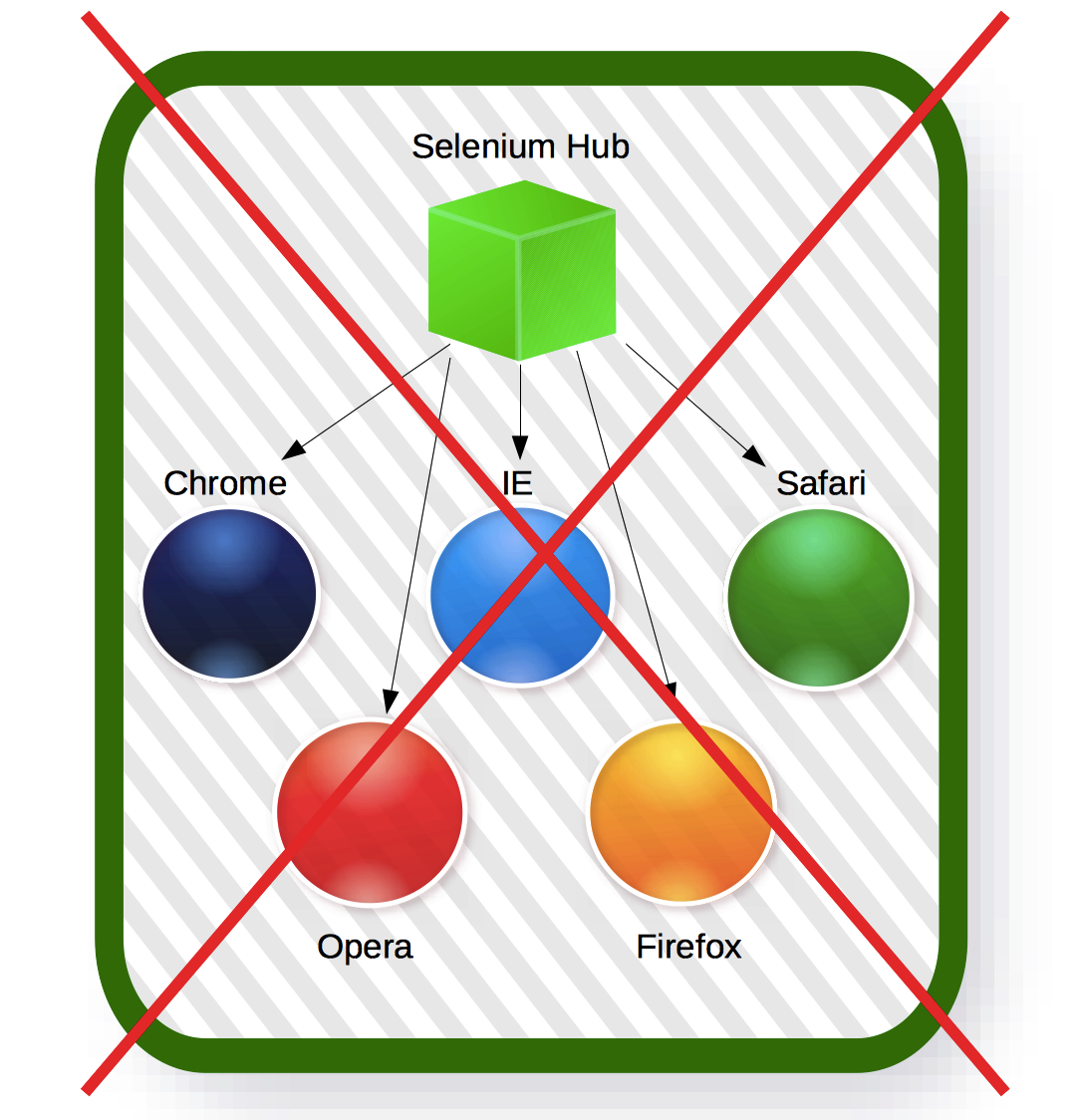
- Как было сказано Selenium хаб с большим числом нагруженных нод работает очень медленно. Не уверен насчет настоящих причин, но практика показывает именно это. Мой совет — не читайте исходники Selenium на ночь, если не хотите, чтобы вам снились кошмары. Таким образом мы не можем использовать десятки Selenium нод с одним и тем же хабом. Остается использовать один хаб и лишь несколько нод. Чтобы эффективно использовать железо нужно уменьшить общее число ядер на хаб — хорошая причина переехать в облака. Например, наш работающий грид длительное время использовал маленькие виртуальные машины с 2 ядрами и 4 Гб памяти.
- Непонятно как установить разные версии одного браузера простым способом (например, из пакетов).
- Непонятно как легко учитывать общее количество доступных браузеров одной версии.
- Разные версии Selenium-ноды совместимы с разными версиями браузеров, т.е. более новая Selenium нода может не поддерживать более старый браузер.
Наиболее простой способ иметь одинаковое количество нод на один хаб — это запускать их внутри одной виртуальной машины. Если каждая версия браузера — это отдельная виртуальная машины, то подсчет общего числа доступных браузеров становится задачей из начальной школы. Можно легко добавлять и удалять виртуальные машины, содержащие совместимые версии ноды и браузера. Мы рекомендуем такой подход при установке кластера Selenium в облако с постоянно доступным количеством каждой версии браузера.

Что же еще кроме Selenium хаба и ноды находится внутри виртуальной машины, чтобы все работало?
- Во-первых, мы рекомендуем использовать Linux в качестве основном операционной системы везде, где возможно. Используя Linux вы можете покрыть 80% потребности в браузерах. Легче перечислить то, что не покрыто:
- Internet Explorer и Microsoft Edge. Эти браузеры работают только под Windows и заслуживают отдельной статьи. Нет повести печальнее на свете...
- Desktop Safari. Кто-нибудь им вообще пользуется? Selenium довольно плохо поддерживает этот браузер.
- iOS и мобильные телефоны Apple. Для работы с этими устройствами нужно использовать железо от Apple, например, MacMini и Appium.
- Для запуска Selenium нужно установить Java (JDK или JRE), а также скачать нужную версию Selenium в виде JAR-архива.
Виртуальные машины не имеют монитора, поэтому Selenium должен быть запущен в особой версии X-сервера, которая эмулирует дисплей. Эта реализация называется Xvfb. Запускается это так:
xvfb-run -l -a -s '-screen 0 1600x1200x24 -noreset' \ java -jar /path/to/selenium-server-standalone.jar -role node <...другие аргументы>
Обратите внимание, что Xvfb нужно только для процесса Selenium-ноды.
- Вы также можете установить дополнительные пакеты со шрифтами, например, Microsoft True Type fonts.
- Если в ваших тестах требуется воспроизводить звук, то нужно настроить поддержку звуковой карты. Для Ubuntu это может сделать примерно так:
#!/bin/bash apt-get -y install linux-sound-base libasound2-dev alsa-utils alsa-oss apt-get -y install --reinstall linux-image-extra-`uname -r` modprobe snd-dummy if ! grep -Fxq "snd-dummy" /etc/modules; then echo "snd-dummy" >> /etc/modules fi adduser $(whoami) audio
Худеем
Как вы уже могли заметить, Selenium — это Java-приложение. Для запуска Selenium нужно установить Java Virtual Machine (JVM). Самый маленький установочный пакет Java, называемый JRE, имеет размер около 50 мегабайт. Selenium JAR самой последней версии 3.0.1 добавляет еще 20 мегабайт. Теперь добавим размер операционной системы, нужные шрифты, размер самого браузера и вы легко достигаете нескольких сотен мегабайт. И хотя жесткие диски сейчас стоят дешево, мы можем сделать лучше. Selenium версий 2.0 и 3.0 также называют Selenium Webdriver. Это связано с тем, что поддержка разных браузеров реализована при помощи отдельных приложений, называемых веб-драйверами.

Вот как это работает:
- Разработчики браузера могут писать свой продукт, как им хочется. Чтобы браузер поддерживался в Selenium им нужно предоставить приложение веб-сервер, предоставляющее то же API, что и сам Selenium Server и поддерживающий протокол JSONWire. Это приложение должно уметь запускать процесс браузера, выполнять команды Selenium согласно спецификации и останавливать браузер по запросу. Любые детали взаимодействия драйвера с браузером могут быть реализованы по-усмотрению разработчиков. Единственное требование — поддержка одинакового Selenium API. Например, Chrome имеет Chromedriver, Opera Blink предоставляет OperaDriver и так далее.
- При установке Selenium требуется указать только путь до приложения-драйвера.
- Когда вы запрашиваете браузер у Selenium, он, на самом деле, запускает процесс драйвера и проксирует все запросы в драйвер. Драйвер выполняет всю остальную работу. Такой же результат вы можете получить, если вручную запустите процесс драйвера на требуемом порту и нацелите свои тесты на него.
Теперь, когда мы выяснили это, встает вопрос: не слишком ли дорого тратить сотни мегабайт для простого проксирования? Год назад ответ был определенно нет, потому что не существовало приложения-драйвера для Firefox — наиболее часто используемый браузер в Selenium. Ответственностью Selenium было запустить Firefox, загрузить в него специальное расширение и проксировать запросы в порт, открытый этим расширением. За последний год ситуация изменилась. Начиная с Firefox 48.0 Selenium взаимодействует с браузером, используя отдельный бинарный драйвер — Geckodriver. Это означает, что теперь для большинства настольных браузеров мы можем совсем удалить Selenium Server и проксировать запросы напрямую в драйверы.
Переезжаем в контейнеры
В предыдущих разделах я описал как можно построить кластер Selenium, используя виртуальные машины в облаке. В этом подходе виртуальные машины всегда запущены и постоянно тратят ваши деньги. Кроме того общее число доступных браузеров для каждой версии ограничено и может приводить к полному исчерпанию доступных браузеров во время пиковых нагрузок. Я слышал о работающих и даже запатентованных сложных решениях, которые запускают и прогревают пул виртуальных машин в зависимости от текущей нагрузки, чтобы всегда иметь доступные браузеры. Это работает, но можно ли сделать лучше? Основная проблема гипервизорной виртуализации — это скорость. Запуск новой виртуальной машины может занимать неколько минут. Но давайте немного подумаем — нужна ли нам отдельная операционная система для каждого браузера? — Нет, нужна только простая изоляция по диску и сети. Вот почему контейнерная виртуализация становится актуальной. На данный момент контейнеры работают в основном только под Linux, но, как я уже говорил, Linux покрывает 80% наиболее популярных браузеров. Контейнеры с браузерами стартуют за секунды и останавливаются еще быстрее.

Что же должно быть внутри контейнера? — Практически то же самое, что и внутри виртуальной машины: сам браузер, шрифты, Xvfb. Для старых версий Firefox (< 48.0) по-прежнему нужно установить Java и Selenium Server, но для Chrome, Opera и свежих версий Firefox мы можем использовать приложение-драйвер в качестве основного процесса контейнера. Если использовать легковесный Linux дистрибутив (например, Alpine), можно получить очень маленькие и легковесные контейнеры.
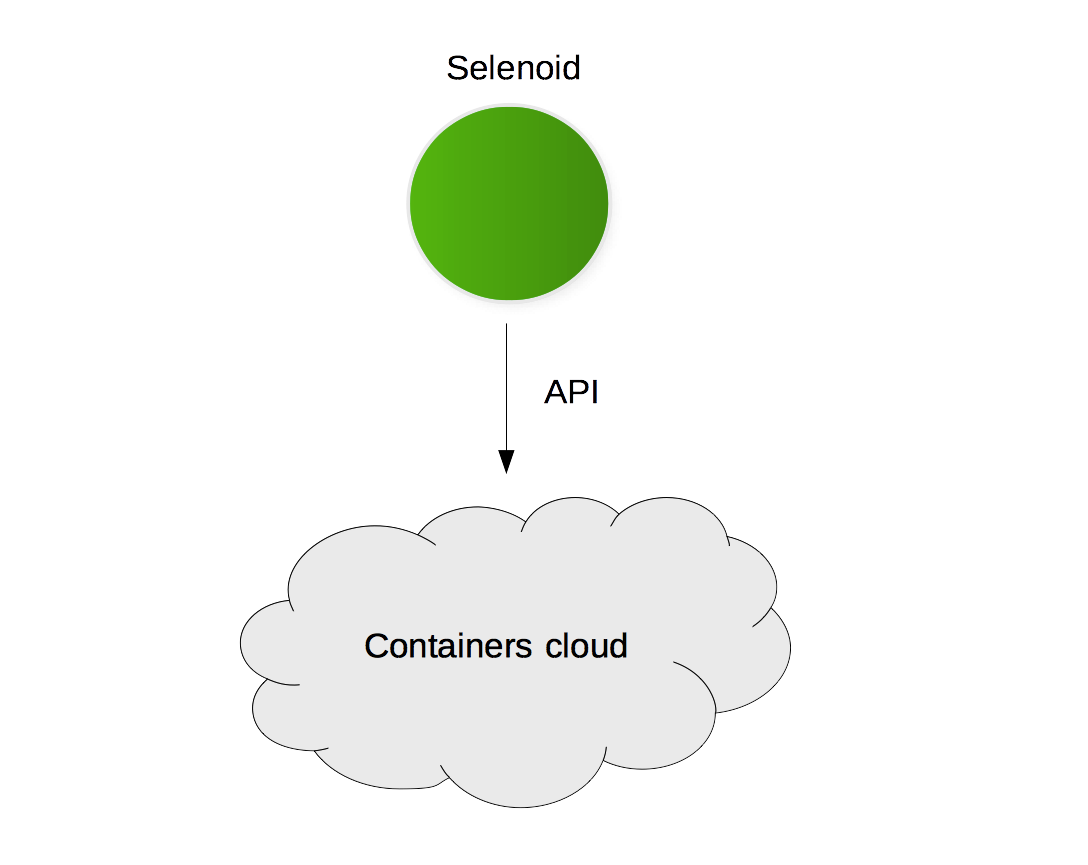
Selenoid
На данный момент наиболее популярной и известной контейнерной платформой является Docker. Разработчики Selenium предоставляют набор готовых Docker контейнеров для запуска Selenium в режиме Standalone или Grid в Docker. Для того, чтобы запустить кластер из таких образов, нужно запускать и останавливать контейнеры вручную или при помощи инструментов наподобие Docker Compose. Такой подход уже намного лучше, чем установка Selenium из пакетов, но было бы еще лучше, если бы существовал сервер со следующим поведением:
- Администратор стартует демон сервера вместо обычного Selenium хаба.
- Демон "знает" (из конфигурации), что, например, для запуска Firefox 48.0 нужно скачать и запустить контейнер Х, а для Chrome 53 — контейнер Y.
- Пользователь запрашивает Selenium сессию обычным способом, но у этого нового демона.
- Демон анализирует капабилити (desired capabilities), стартует нужный контейнер и затем проксирует запросы в основной процесс контейнера (Selenium server или веб-драйвер).
Мы сделали такой демон… и даже больше.
За годы использования Selenium server в больших масштабах мы поняли, что очень неэффективно использовать JVM и "толстый" Selenium JAR для простого проксирования запросов. Поэтому мы искали более легковесную технологию. Наш выбор остановился на языке программирования Go также известном как Golang. Почему для наших целей Go подходит лучше?
- Статическая линковка. Результатом компиляции становится один файл — бинарник, который можно скопировать на сервер и сразу запустить. Для запуска не нужно устанавливать зависимости и дополнительные программы наподобие JVM для Java.
- Кросс компиляция. На одной и той же машине одним и тем же компилятором мы можем собрать бинарники под разные операционные системы.
- Богатая стандартная библиотека. Для нас наиболее важной была поддержка из коробки reverse-проксирования и HTTP/2.
- Большое сообщество разработчиков. Язык уже становится одним из наиболее популярных для определенного класса задач.
- Хорошо поддерживается в IDE. Для Go существует хороший плагин для IntellijIDEA и альфа-версия полноценной IDE Goglang от тех же разработчиков.
Мы так и не придумали хорошего имени для описанного выше демона. Поэтому мы назвали его просто Selenoid. Чтобы попробовать Selenoid нужно выполнить 3 простых шага:
- Создать JSON-файл, содержащий информацию о том какой контейнер нужно запустить для каждой версии браузера:
{ "firefox": { "default": "latest", "versions": { "49.0": { "image": "selenoid/firefox:49.0", "port": "4444" }, "latest": { "image": "selenoid/firefox:latest", "port": "4444" } } }, "chrome": { "default": "54.0", "versions": { "54.0": { "image": "selenoid/chrome:54.0", "port": "4444" } } } }
Как и в XML файле для Gridrouter указан список доступных версий браузеров. Поскольку Selenoid запускает контейнеры на той же машине или через Docker API, нет необходимости указывать имена хостов и регионы. Для каждой версии браузера нужно указать имя контейнера, его версию и порт, на котором слушает основной процесс контейнера.
- Запустить Selenoid:
$ selenoid -limit 10 -conf /etc/selenoid/browsers.json
По-умолчанию Selenoid стартует на порту 4444, как обычный Selenium хаб.
- Запустить свои тесты на хост Selenoid, как будто это обычный Selenium хаб.
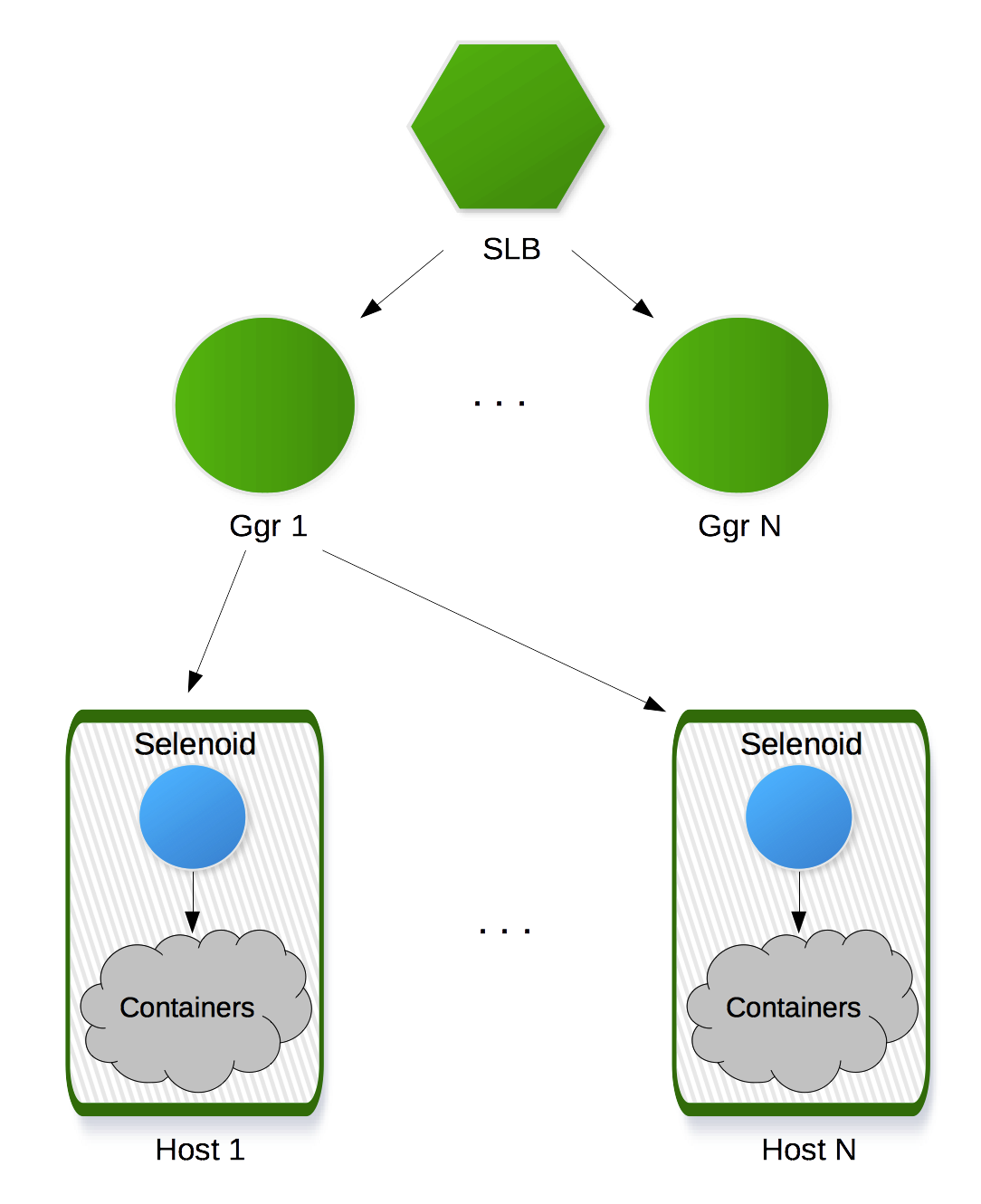
Наши эксперименты показывают, что даже контейнеры со стандартным Selenium сервером внутри стартуют за несколько секунд. Взамен вы получаете гарантированное состояние диска и памяти. Браузер всегда находится в состоянии как после установки на чистую операционную систему. Кроме того вы можете установить Selenoid на большой кластер из хостов имеющих одинаковый набор поддерживаемых браузеров, сохраненных в виде Docker образов. Это дает вам большой кластер Selenium, который автоматически масштабируется в зависимости от потребления браузеров. Например, если текущие запросы пользователей требуют больше Chrome — автоматически запускается больше контейнеров. Когда запросов на Chrome не поступает — контейнеры с Chrome останавливаются и освободившиеся хосты могут использоваться для других браузеров.
Чтобы обеспечить лучшее распределение нагрузки по кластеру, Selenoid ограничивает общее число параллельных сессий на хосте и ставит в очередь все превышающие лимит запросы. Запросы из очереди обрабатываются по мере того, как завершаются более ранние сессии на том же хосте.
Но Selenoid позволяет запускать не только контейнеры. Он также умеет запускать по требованию процессы веб-драйвера. Основное применение этой функциональности — замена Selenium Server на Windows. В этом случае Selenoid стартует процесс IEDriverServer, что позволяет экономить память и избегать ошибок проксирования в самом Selenium.
Go Grid Router (также известный как ggr)
Возможно, вы помните, что оригинальный GridRouter — это Java приложение. Мы написали с нуля легковесную реализацию этого прокси на Go и назвали просто Go Grid Router (или ggr). В чем преимущества новой версии по сравнению со старой?
- Увеличенная производительность. Может обслуживать минимум на 25% больше запросов.
- Меньшее потребление памяти. При нагрузке в 150 rps потребляет всего 100-200 мегабайт памяти и это число не меняется.
- Отслеживается отсоединение клиента. Если клиент отсоединяется (например, из-за таймаута) Java-версия GridRouter продолжает перебирать хосты, пытаясь создать сессию. Это забивает сеть ненужными пакетами и уменьшает производительность GridRouter, когда много хабов становятся недоступны. Новая реализация на Go перестает пытаться получить браузер как только клиент отключается.
- Перезагрузка сервера без потери соединений (graceful restart). Если сервер используется вне Docker контейнера, то можно перезагрузить его без потери соединений, послав процессу сигнал SIGUSR2.
- Перезагрузка квот по запросу. Когда используется несколько инстансов GridRouter за балансером важно обновлять квоты одновременно. Когда в XML файлы квот добавляются новые хосты и квоты обновляются не одновременно на работающем кластере Selenium может произойти ситуация, когда одна "голова" GridRouter уже знает про новые хосты и перенаправляет туда запросы, а другая еще не знает об этих хостах и возвращает ошибку 404. Реализация на Go перезагружает квоты по сигналу SIGHUP, а не автоматически, как это происходит в Java версии. Эта функциональность работает как в Docker, так и без него.
- Зашифрованные пароли. Ggr использует текстовые файлы формата Apache htpasswd для хранения логинов и паролей. Логины хранятся в открытом виде, а пароли зашифрованы.
- Маленький размер исполняемого файла. Всего 6 мегабайт. Не требует установки Java. Если устанавливать в Docker, то контейнер на основе Alpine Linux занимает всего 11 мегабайт.
В связке с Selenoid, позволяет создавать масштабируемый, надежный кластер Selenium:
Заключение
В этой части я рассказал о самых последних технологиях, которые могут быть использованы для организации современного кластера Selenium:
- Почему Selenium хорошо упаковывается и запускается в контейнерах
- Что должно быть внутри контейнера
- Какие open-source инструменты для работы Selenium в контейнерах существуют
Ссылки
В заключение в одном месте собраны ссылки на упомянутые в статье продукты:

