В Apache Ignite можно определить именованный кеш данных для постоянного хранилища, загрузить в него данные и далее выполнять различные манипуляции с ними.
Можно выполнять операции get/put как c Map, например в java, эти операции имеют название сквозного чтения, записи в постоянное хранилище (write-through and read-through). Т.е. после того как кеш загружен при выполнении операции get объект будет взят их него, а не из базы, а при записи он изменится в кеше и будет записан в хранилище данных. Если при попытке взятия объекта его не будет в кеше он будет вначале в него записан. Понятно что операции чтения уже будут из памяти кеша и очень быстро. Все это актуально для операций get/put. Для других операций поиска, например для поиска объекта не по ключу есть — Query, как быстрее находить данные в кеше?, работа с транзакциями, все это ниже в статье…

В кеше данные записана по ключу который может например являться primary key из таблицы БД. Для своего примера я взял БД Oracle XE, по умолчанию Ignite предоставляет БД H2, но в жизни я думаю все таки придется иметь дело с другими БД. Итак берем сущность(таблицу) БД и готовим для нее класс в Java (в качестве источника данных для сущности может быть любой набор: view, function и др. тут полностью можем управлять).
Аннотациями показываем поля которые будут участвовать в Query операциях, а также поле индекса.
Теперь надо наследоваться от класса — CacheStoreAdapter и переопределить основные его методы:
Видно что в качестве ключа будет ИД, а элементом коллекции класс Kladr (<Long, Kladr> )
Примерно так выглядит
Первые тесты
загрузим массово кеш, 50 000 объектов (см. loadCache в CacheKladrStore выше)
Загрузка 50 000 тыс. объектов занимает несколько сек. Что грузим, сколько, все под нашим контролем — удобно.
Читаем данные из кеша, по тем тем ИД, что загрузили
читаем 20 000 тыс. объектов, здесь все хорошо, все берется теперь из кеша, в БД обращений нет.
Но если теперь вызвать чтение объектов которых нет в кеше
то теперь на каждый get будет вызван (см. CacheKladrStore)
объект будет прочитан из БД и помещен в кеш, операция у меня заняла для 1 000 объектов — уже несколько секунд. И уже при повторно чтении будут браться из кеша как и ранее в тесте (read-through в действии).
Операции в рамках транзакции
Да именно так как и должно быть (или почти), открываем транзакцию, модифицируем разные объекты и только в случае успеха они будут записаны в БД по commit(). Для каждого модифицированного объекта помещенного в кеш (put) будет вызван (см. CacheKladrStore)
т.е. после вызова commit, будут вызваны — write.
Вот вывод в консоль:

Видно, что считали из кеша (ранее из бызы), затем модифицировали, поместили в кеш, и уже после commit транзакции данные оказались в БД и кеше.
А что если после модификации в кеше, но перед записью в БД — Exception?, например здесь
. Commit не произойдет, но и в кеше данные откатятся — все Ок!

После Exception видим прежнее значение, что было до модификации.
Это были операции вида get/put, но известно этим логика приложений не ограничивается, и нужны разные поиски по разным критериям, получать коллекции и одиночные объекты.
С этим в кеше могут работать Query. Есть особенность запросы будут работать только с теми данными что уже есть в кеше.
Пример работы с кешем через запрос:
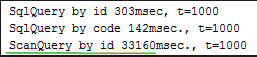
чтение 1000 объектов заняло 300 мсек. Но здесь было чтение по полю которое аннотировано как индекс.
И опять же в жизни нужны поиски и другим полям, проверим по полю «code» где нет индекса, результат печальный, как в БД (но на самом деле много хуже) full scan, поиск 1000 раз уже происходил 30 сек.

Я не хотел сравнивать, но этот случай мне стал интересен, перебор по всем значениям, данные в кеше (в памяти), вроде как условия достаточно привлекательные и как БД (Oracle XE) отработает это перебор. Вот результат, тот же поиск в БД дал 6 сек.

Видимо в БД более интелектуалльно обходится с кешем, хранением, поиском и прочее. Если по полю добавить индекс, поиск в БД 28мс. В Ignite можно тоже добавить индекс по еще одному полю и поиск — взлетел!

и составил — 160мс.
Правда в БД он с индексом прошел на порядок быстрее. Но не всегда это главное, вопрос масштабирования вычислительной системы (ранее рассмотренный) тоже очень важен.
Есть и другие типы запросов к кешу, например ScanQuery, вот тот же пример с ним:
Его результат такой:
Материал
Можно выполнять операции get/put как c Map, например в java, эти операции имеют название сквозного чтения, записи в постоянное хранилище (write-through and read-through). Т.е. после того как кеш загружен при выполнении операции get объект будет взят их него, а не из базы, а при записи он изменится в кеше и будет записан в хранилище данных. Если при попытке взятия объекта его не будет в кеше он будет вначале в него записан. Понятно что операции чтения уже будут из памяти кеша и очень быстро. Все это актуально для операций get/put. Для других операций поиска, например для поиска объекта не по ключу есть — Query, как быстрее находить данные в кеше?, работа с транзакциями, все это ниже в статье…
В кеше данные записана по ключу который может например являться primary key из таблицы БД. Для своего примера я взял БД Oracle XE, по умолчанию Ignite предоставляет БД H2, но в жизни я думаю все таки придется иметь дело с другими БД. Итак берем сущность(таблицу) БД и готовим для нее класс в Java (в качестве источника данных для сущности может быть любой набор: view, function и др. тут полностью можем управлять).
Таблица КЛАДР в качестве элемента для кеша
public class Kladr implements Serializable { @QuerySqlField(index = true) public Long id; @QuerySqlField public String code; @QuerySqlField public String name; @QuerySqlField public Timestamp upd_date; public Kladr(Long id, String code, String name, Timestamp upd_date) { this.code = code; this.name = name; this.id = id; this.upd_date = upd_date; } public Kladr() { // No-op. } @Override public String toString() { return id + "/"+ code + "/" + name + "/" + upd_date; } }
Аннотациями показываем поля которые будут участвовать в Query операциях, а также поле индекса.
Теперь надо наследоваться от класса — CacheStoreAdapter и переопределить основные его методы:
public class CacheKladrStore extends CacheStoreAdapter<Long, Kladr> { // Этот метод вызывается всякий раз, когда вызывается метод get (...) в Ignite Cache. @Override public Kladr load(Long key) { // Этот метод вызывается всякий раз, когда вызывается метод «put (...)» в Ignite Cache. @Override public void write(Cache.Entry<? extends Long, ? extends Kladr> entry) { // Этот метод вызывается всякий раз, когда вызывается метод «remove (...)» в Ignite Cache. @Override public void delete(Object key) { // Этот mehtod вызывается всякий раз, когда вызываем «loadCache ()» и «localLoadCache ()» // Он используется для массовой загрузки кеша. @Override public void loadCache(IgniteBiInClosure<Long, Kladr> clo, Object... args) {
Видно что в качестве ключа будет ИД, а элементом коллекции класс Kladr (<Long, Kladr> )
Примерно так выглядит
CacheKladrStore
public class CacheKladrStore extends CacheStoreAdapter<Long, Kladr> { // Этот метод вызывается всякий раз, когда вызывается метод get (...) в Ignite Cache. @Override public Kladr load(Long key) { try (Connection conn = connection()) { try (PreparedStatement st = conn.prepareStatement( "select id, code, name, upd_date from KLADR where id=?")) { st.setLong(1, key); ResultSet rs = st.executeQuery(); return rs.next() ? new Kladr(rs.getLong(1), rs.getString(2), rs.getString(3), rs.getTimestamp(4) ) : null; } } catch (SQLException e) { throw new CacheLoaderException("Failed to load: " + key, e); } } // Этот метод вызывается всякий раз, когда вызывается метод «put (...)» в Ignite Cache. @Override public void write(Cache.Entry<? extends Long, ? extends Kladr> entry) { Long key = entry.getKey(); Kladr val = entry.getValue(); try (Connection conn = connection()) { try (PreparedStatement stUpd = conn.prepareStatement( "update KLADR set upd_date = ? where id = ?")) { stUpd.setTimestamp(1, val.upd_date); stUpd.setLong(2, val.id); int updated = stUpd.executeUpdate(); if (updated == 0) { try (PreparedStatement stIns = conn.prepareStatement( "insert into KLADR (id, code, name, upd_date) values (?, ?, ?, ?)")) { stUpd.setLong(1, val.id); stUpd.setString(2, val.code); stUpd.setString(2, val.name); //... //stIns.executeUpdate(); } } } } catch (SQLException e) { throw new CacheWriterException("Failed to write [key=" + key + ", val=" + val + ']', e); } } // Этот метод вызывается всякий раз, когда вызывается метод «remove (...)» в Ignite Cache. @Override public void delete(Object key) { try (Connection conn = connection()) { try (PreparedStatement st = conn.prepareStatement("delete from KLADR where id=?")) { st.setLong(1, (Long)key); st.executeUpdate(); } } catch (SQLException e) { throw new CacheWriterException("Failed to delete: " + key, e); } } // Этот mehtod вызывается всякий раз, когда вызываем «loadCache ()» и «localLoadCache ()» // Он используется для массовой загрузки кеша. @Override public void loadCache(IgniteBiInClosure<Long, Kladr> clo, Object... args) { if (args == null || args.length == 0 || args[0] == null) throw new CacheLoaderException("Expected entry count parameter is not provided."); final int entryCnt = (Integer)args[0]; try (Connection conn = connection()) { try (PreparedStatement st = conn.prepareStatement( "select id, code, name, upd_date from KLADR where id between 100000 and 150000 and rownum <= " + entryCnt)) { try (ResultSet rs = st.executeQuery()) { int cnt = 0; while (cnt < entryCnt && rs.next()) { Kladr kladr = new Kladr(rs.getLong(1), rs.getString(2), rs.getString(3), rs.getTimestamp(4) ); clo.apply(kladr.id, kladr); cnt++; } } } } catch (SQLException e) { throw new CacheLoaderException("Failed to load values from cache store.", e); } } // Открывает соединение JDBC и присоединяет его к текущему // сеанс, если внутри транзакции. private Connection connection() throws SQLException { return openConnection(true); } // Открывает соединение JDBC private Connection openConnection(boolean autocommit) throws SQLException { //Открытое соединение с системами RDBMS (Oracle, MySQL, Postgres, DB2, Microsoft SQL и т. Д.) //В этом примере мы используем базу данных Oracle. Locale.setDefault(Locale.ENGLISH); Connection conn = DriverManager.getConnection("jdbc:oracle:thin:@localhost:1521:xe", "HR", "1"); conn.setAutoCommit(autocommit); return conn; } }
Первые тесты
Подготовка к старту
public class CacheKladrStoreExample { /** * Имя кеша. */ private static final String CACHE_NAME = CacheKladrStoreExample.class.getSimpleName(); /** * размер кеша, кол-во записей. */ private static final int ENTRY_COUNT = 50_000; public static void main(String[] args) throws IgniteException { // To start ignite try (Ignite ignite = Ignition.start("examples/config/example-ignite.xml")) { System.out.println(); System.out.println(">>> Cache store example started."); CacheConfiguration<Long, Kladr> cacheCfg = new CacheConfiguration<>(CACHE_NAME); // Set atomicity as transaction, since we are showing transactions in example. cacheCfg.setAtomicityMode(TRANSACTIONAL); // Configure Spring store. cacheCfg.setCacheStoreFactory(FactoryBuilder.factoryOf(CacheKladrStore.class)); cacheCfg.setReadThrough(true); cacheCfg.setWriteThrough(true); // для выполнения Query к кешу надо указать поля, типы и пр. QueryEntity qe = new QueryEntity(Long.class, Kladr.class); LinkedHashMap linkedHashMap = new LinkedHashMap(); linkedHashMap.put("code", "java.lang.String"); linkedHashMap.put("name", "java.lang.String"); linkedHashMap.put("id", "java.lang.Long"); linkedHashMap.put("upd_date", "java.sql.Timestamp"); qe.setFields(linkedHashMap); Collection<QueryEntity> collection = new ArrayList<>(); collection.add(qe); cacheCfg.setQueryEntities(collection); // авто закрытие кеша по окончании примера. try (IgniteCache<Long, Kladr> cache = ignite.getOrCreateCache(cacheCfg)) { // тут начнем
загрузим массово кеш, 50 000 объектов (см. loadCache в CacheKladrStore выше)
try (IgniteCache<Long, Kladr> cache = ignite.getOrCreateCache(cacheCfg)) { //Сделать начальную загрузку кеша из постоянного хранилища. // вызывается CacheStore.loadCache (...) loadCache(cache);
loadCache
private static void loadCache(IgniteCache<Long, Kladr> cache) { long start = System.currentTimeMillis(); // начало загрузки из хранилища. cache.loadCache(null, ENTRY_COUNT); long end = System.currentTimeMillis(); System.out.println(">>> Loaded size" + cache.size() + " " + (end - start) + "ms."); }
Загрузка 50 000 тыс. объектов занимает несколько сек. Что грузим, сколько, все под нашим контролем — удобно.
Читаем данные из кеша, по тем тем ИД, что загрузили
// Данные из кеша getFromCache(cache, 100_000L, 120_000L);
getFromCache
private static void getFromCache(IgniteCache<Long, Kladr> cache, Long i1, Long i2) { long millis = System.currentTimeMillis(); for (long i = i1; i < i2; i++) { Kladr kladr = cache.get(i); kladr.upd_date = new Timestamp(new java.util.Date().getTime()); } System.out.println("getFromCache еotal get values msec.:" + (System.currentTimeMillis() - millis)); }
читаем 20 000 тыс. объектов, здесь все хорошо, все берется теперь из кеша, в БД обращений нет.
Но если теперь вызвать чтение объектов которых нет в кеше
// Данные НЕ из кеша getFromCache(cache, 10_000L, 11_000L);
то теперь на каждый get будет вызван (см. CacheKladrStore)
// Этот метод вызывается всякий раз, когда вызывается метод get (...) в Ignite Cache. @Override public Kladr load(Long key) {
объект будет прочитан из БД и помещен в кеш, операция у меня заняла для 1 000 объектов — уже несколько секунд. И уже при повторно чтении будут браться из кеша как и ранее в тесте (read-through в действии).
Операции в рамках транзакции
executeTransaction
private static void executeTransaction(IgniteCache<Long, Kladr> cache) { final Long id1 = 100_001L; final Long id2 = 100_009L; try (Transaction tx = Ignition.ignite().transactions().txStart()) { // читаем из кеша первый объект ИД1 Kladr val = cache.get(id1); System.out.println("Read value first id1: " + val); Kladr newKladr = new Kladr(id1, val.code, val.name, new Timestamp(new java.util.Date().getTime())); // запись в кеш измененого, в БД здесь не пишется cache.put(id1, newKladr); // проверяем измененный объект из кеша для ИД1 val = cache.get(id1); System.out.println("Read value after id1: " + val); // // второй объект из кеша ИД2 val = cache.get(id2); System.out.println("Read value first id2: " + val); newKladr = new Kladr(id2, val.code, val.name, new Timestamp(new java.util.Date().getTime())); cache.put(id2, newKladr); // проверяем измененный объект из кеша для ИД2 val = cache.get(id2); System.out.println("Read value after id2: " + val); // теперь все ихменения будут записаны в БД. // будет вызван ДВА РАЗА в CacheKladrStore write(Cache.Entry<? extends Long, ? extends Kladr> entry) tx.commit(); } System.out.println("Read value id1 after commit: " + cache.get(id1)); }
Да именно так как и должно быть (или почти), открываем транзакцию, модифицируем разные объекты и только в случае успеха они будут записаны в БД по commit(). Для каждого модифицированного объекта помещенного в кеш (put) будет вызван (см. CacheKladrStore)
// Этот метод вызывается всякий раз, когда вызывается метод «put (...)» в Ignite Cache. @Override public void write(Cache.Entry<? extends Long, ? extends Kladr> entry) {
т.е. после вызова commit, будут вызваны — write.
Вот вывод в консоль:
Видно, что считали из кеша (ранее из бызы), затем модифицировали, поместили в кеш, и уже после commit транзакции данные оказались в БД и кеше.
А что если после модификации в кеше, но перед записью в БД — Exception?, например здесь
System.out.println("Read value after id2: " + val); try { throw new RuntimeException("RuntimeException"); tx.commit(); } catch (Exception e) { e.printStackTrace(); } } System.out.println("Read value id1 after commit: " + cache.get(id1));
. Commit не произойдет, но и в кеше данные откатятся — все Ок!
После Exception видим прежнее значение, что было до модификации.
Это были операции вида get/put, но известно этим логика приложений не ограничивается, и нужны разные поиски по разным критериям, получать коллекции и одиночные объекты.
С этим в кеше могут работать Query. Есть особенность запросы будут работать только с теми данными что уже есть в кеше.
Пример работы с кешем через запрос:
SqlQuery sql = new SqlQuery(Kladr.class, "id = ?"); long start = System.currentTimeMillis(); int t = 0; for (int i = 100_000; i < 101_000; i++) { try (QueryCursor<Cache.Entry<Long, Kladr>> cursor = cache.query(sql.setArgs(i))) { for (Cache.Entry<Long, Kladr> e : cursor) { e.getValue().upd_date = new Timestamp(new java.util.Date().getTime()); t++; } } } System.out.println("SqlQuery by id " + (System.currentTimeMillis() - start) + "msec, t=" + t);
чтение 1000 объектов заняло 300 мсек. Но здесь было чтение по полю которое аннотировано как индекс.
@QuerySqlField(index = true) public Long id;
И опять же в жизни нужны поиски и другим полям, проверим по полю «code» где нет индекса, результат печальный, как в БД (но на самом деле много хуже) full scan, поиск 1000 раз уже происходил 30 сек.
Поиск по полю 'code'
String[] codes = new String[]{"4401300010999", "4401300011700"}; sql = new SqlQuery(Kladr.class, "code = ?"); start = System.currentTimeMillis(); t = 0; for (int i = 100_000; i < 101_000; i++) { try (QueryCursor<Cache.Entry<Long, Kladr>> cursor = cache.query(sql.setArgs(codes[i % 2]))) { for (Cache.Entry<Long, Kladr> e : cursor) { e.getValue().upd_date = new Timestamp(new java.util.Date().getTime()); t++; } } } System.out.println("SqlQuery by code " + (System.currentTimeMillis() - start) + "msec., t=" +t);
Я не хотел сравнивать, но этот случай мне стал интересен, перебор по всем значениям, данные в кеше (в памяти), вроде как условия достаточно привлекательные и как БД (Oracle XE) отработает это перебор. Вот результат, тот же поиск в БД дал 6 сек.
declare TYPE code_type IS TABLE OF VARCHAR2(30); v_codes code_type; v_code varchar2(30); v_t number :=0; v_ts timestamp; v_id number; begin v_codes := code_type('4401300010999', '4401300011700'); v_ts := systimestamp; for i in 1..1000 loop v_code := v_codes((i mod 2)+1); select id into v_id from kladr k where k.code = v_code; v_t := v_t + 1; end loop; dbms_output.put_line('query by code ' || to_char(systimestamp - v_ts) || ', t=' || v_t); end;
Видимо в БД более интелектуалльно обходится с кешем, хранением, поиском и прочее. Если по полю добавить индекс, поиск в БД 28мс. В Ignite можно тоже добавить индекс по еще одному полю и поиск — взлетел!
@QuerySqlField(index = true) public String code;
и составил — 160мс.
Правда в БД он с индексом прошел на порядок быстрее. Но не всегда это главное, вопрос масштабирования вычислительной системы (ранее рассмотренный) тоже очень важен.
Есть и другие типы запросов к кешу, например ScanQuery, вот тот же пример с ним:
ScanQuery
for (int i = 100_000; i < 101_000; i++) { int id = i; try (QueryCursor<Cache.Entry<Long, Kladr>> cursor = cache.query(new ScanQuery<Long, Kladr>((k, v) -> v.id == id))) { for (Cache.Entry<Long, Kladr> e : cursor) e.getValue().upd_date = new Timestamp(new java.util.Date().getTime()); t++; } } System.out.println("ScanQuery by id " + (System.currentTimeMillis() - start) + "msec., t=" +t);
Его результат такой:
Материал

